重塑优化建模与算法设计:2025年大模型(LLM)在优化领域的应用盘点 - 2
本笔记汇集了该方向在2025年3月至4月期间涌现的十篇关键研究论文,系统性地展现了从“可行性验证”到“框架深化与理论探索”的快速演进脉络。以下,我们将按照发表时间的顺序,逐一梳理这些代表性研究的核心内容。
2025.03
(01) Leveraging Large Language Models to Develop Heuristics for Emerging Optimization Problems
arXiv
-
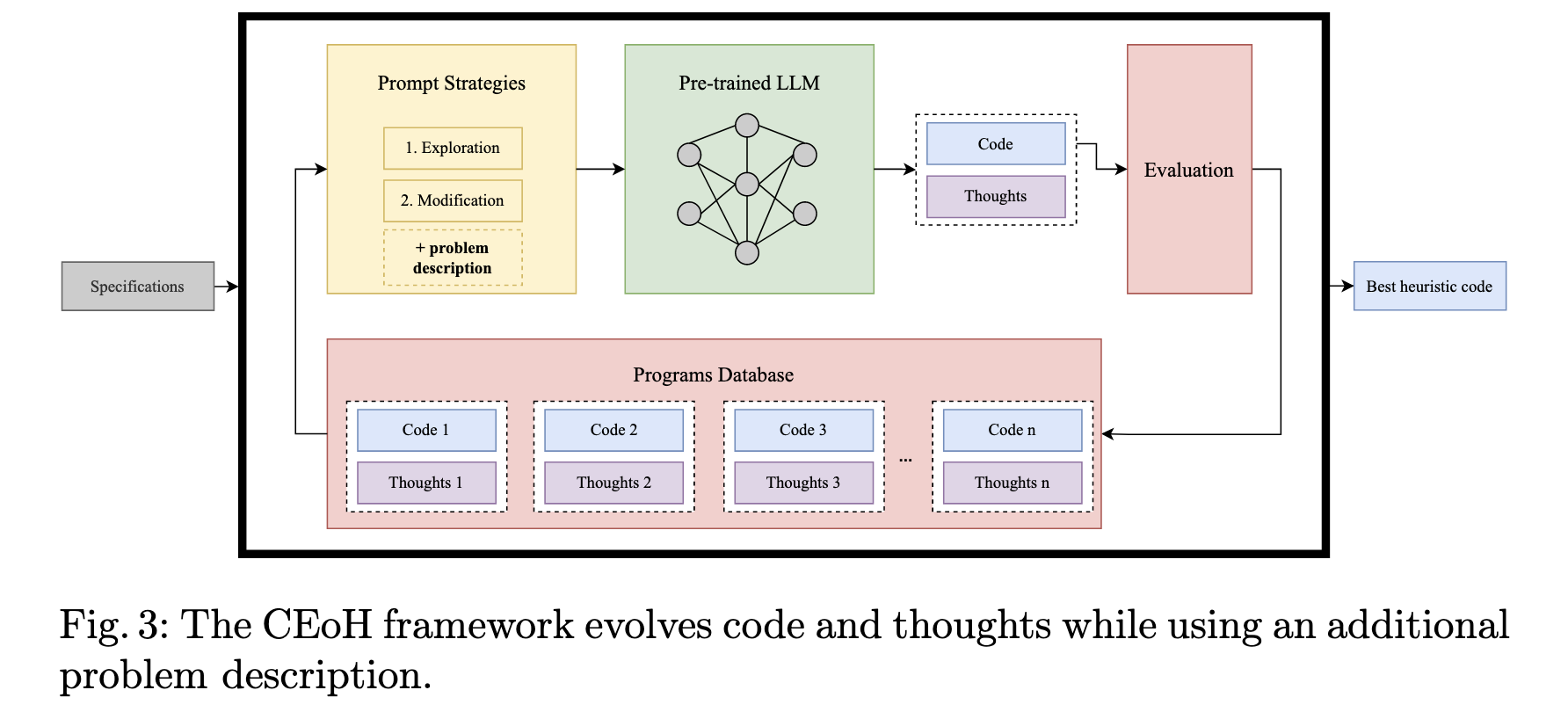
问题:当前的大语言模型(LLM)虽然能为经典的优化问题(如旅行商问题)自动设计启发式算法,但尚不清楚它们是否能为训练数据中很少见的“小众”或新兴优化问题(本文以单元货物预调度问题 UPMP 为例)生成有效的算法。
-
方法:提出了一个名为“启发式算法的上下文演化”(CEoH)的框架。 其核心创新点在于,在向大语言模型(LLM)发出指令(Prompt)时,额外注入一段关于“小众”问题的详细描述和背景信息,通过“情境学习”(In-context Learning)的方式,弥补模型在训练数据中对该问题知识的缺失。
-
效果:该方法使得一些规模较小、更易获取的开源模型也能为“小众”问题生成高质量且表现稳定的启发式算法,其性能甚至优于某些更大规模的模型 ;其中最好的算法在测试实例上与理论最优解的差距仅为4.35%。
(02) OR-LLM-Agent: Automating Modeling and Solving of Operations Research Optimization Problem with Reasoning Large Language Model
arXiv
-
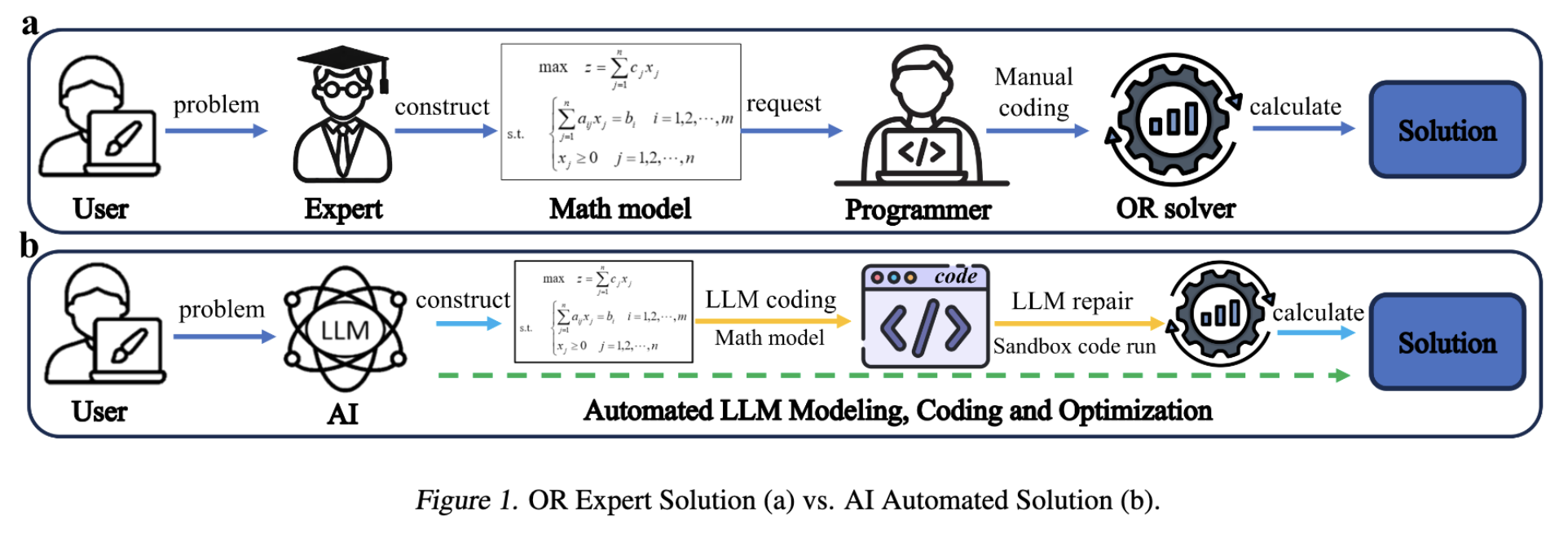
问题:解决运筹学(OR)问题需要昂贵的领域专家进行数学建模,再由程序员编写代码求解,整个过程成本高、周期长,限制了运筹优化技术的普及。
-
方法:提出了一个名为 OR-LLM-Agent 的人工智能代理框架 。它利用具备推理能力的大语言模型(LLM),将自然语言描述的运筹学问题,分两步进行:
- 第一步,自动构建数学模型;
- 第二步,基于该模型生成求解代码 。该框架还包含一个代码代理(OR-CodeAgent),能在一个隔离的“沙盒”环境中自动执行、调试修复代码,甚至在无解时触发对数学模型的“自我验证”和修正,从而实现从问题描述到求解答案的全自动化流程 。
-
效果:在一个包含83个真实世界运筹学问题的基准数据集上,该方法取得了100%的代码执行成功率和85%的求解准确率 。
(03) Combinatorial Optimization for All: Using LLMs to Aid Non-Experts in Improving Optimization Algorithms
arXiv
-
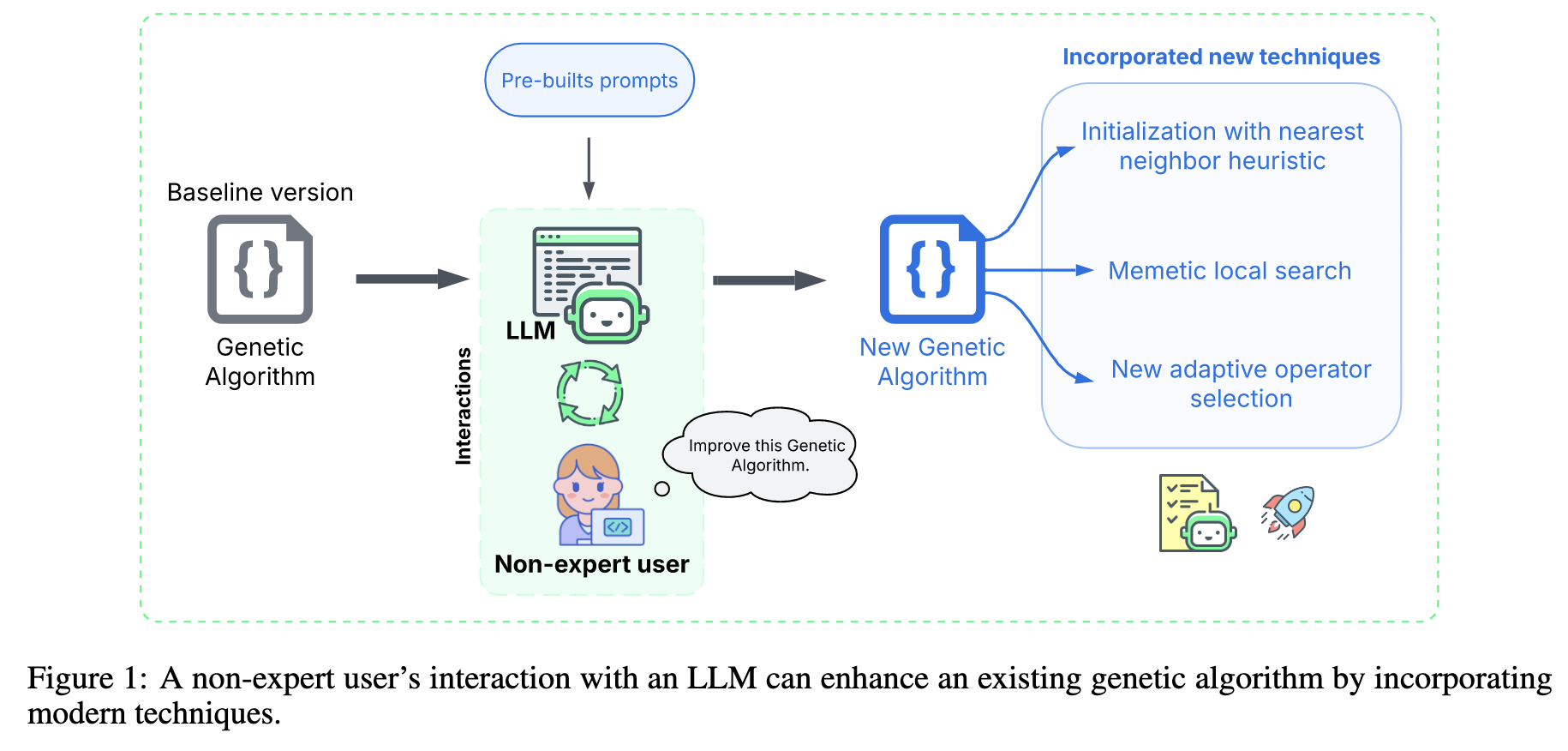
问题:非优化领域的程序员如何利用大语言模型(LLM)来提升现有复杂优化算法的性能?
-
方法:提出一种极其简单且标准化的提示词(Prompt)策略 。用户只需将完整的算法源代码、函数签名和算法名称填入一个固定模板,然后直接将这个长提示词交给一个通用的大语言模型(如GPT、Gemini等),指令其以“优化专家”的身份,结合其知识库对整个算法代码进行全方位的改进。 该方法的核心是让不具备专业优化理论和复杂提示词工程技能的用户也能操作。
-
效果:该方法在旅行商问题(TSP)上测试了10种经典的基准算法,结果显示,由LLM生成的代码在9种算法上都超越了原始版本,显著提升了求解质量、计算速度,甚至在某些情况下降低了代码的复杂度。
(04) Automatic MILP Model Construction for Multi-Robot Task Allocation and Scheduling Based on Large Language Models
arXiv
-
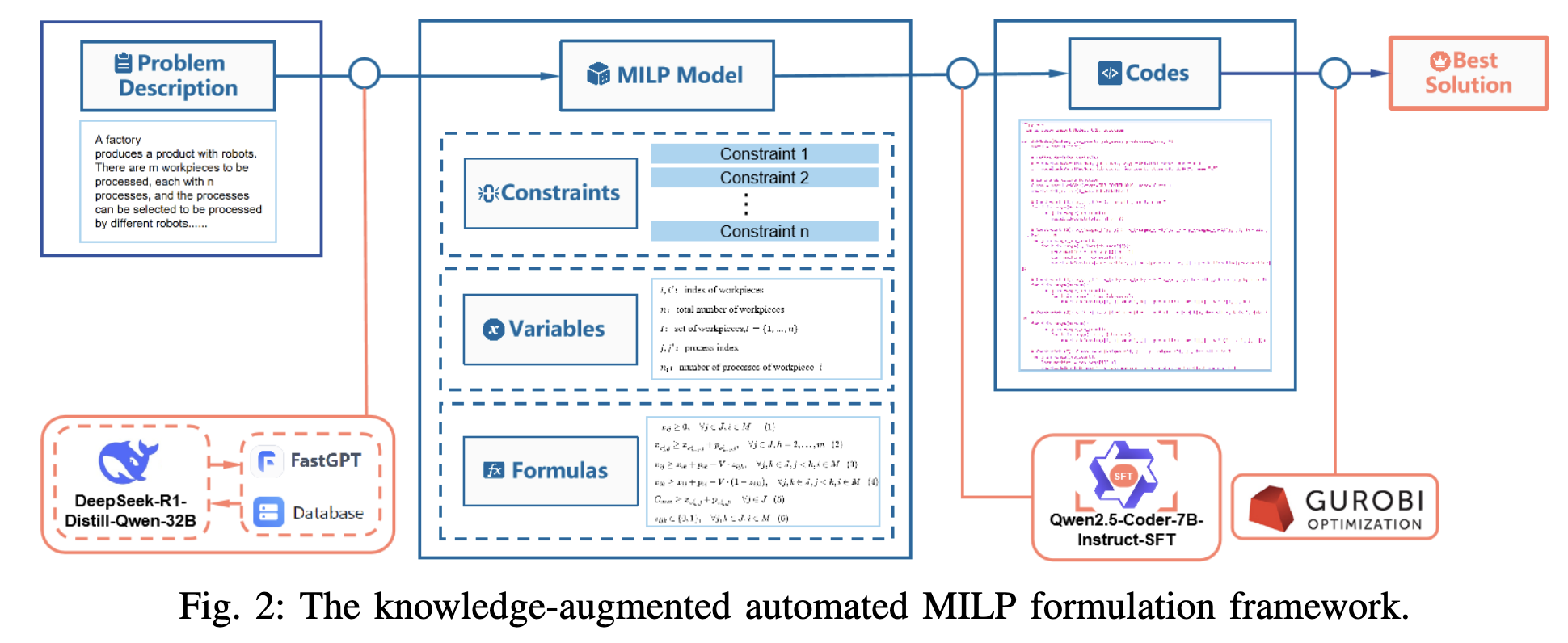
问题:在制造业中为多机器人系统进行任务规划时,需要领域专家手动构建复杂的数学模型,且由于生产数据高度敏感,无法使用云端的大语言模型(LLM)来自动完成此过程,存在数据隐私泄露的风险。
-
方法:提出了一个完全在本地部署的两阶段自动化建模框架:
- 自然语言到数学模型: 首先,使用一个集成了领域知识库的本地大语言模型(DeepSeek-R1-Distill-Qwen-32B),将用户用自然语言描述的生产问题,自动翻译成一个精确的混合整数线性规划(MILP)数学模型。
- 数学模型到可执行代码: 接着,使用另一个经过监督微调的本地代码模型(Qwen2.5-Coder-7B-Instruct),将上一步生成的数学模型,自动转换成可直接求解的代码。
-
效果:该框架在确保数据隐私的同时,实现了高效的自动化建模,其中第一阶段模型识别复杂约束的平均准确率为82%,第二阶段模型生成代码的平均准确率从微调前的约5%大幅提升至90%。
(05) Code Evolution Graphs: Understanding Large Language Model Driven Design of Algorithms
arXiv
-
问题:当使用大语言模型(LLM)通过进化框架自动设计算法时,我们对代码的生成和演变过程缺乏理解,导致在优化停滞或失败时难以分析和改进。
-
方法:提出了一种名为“代码演化图”(Code Evolution Graphs, CEGs)的分析方法。 该方法的核心是:首先,通过分析代码的抽象语法树(AST)来提取和量化每个算法的结构与复杂度特征(如代码行数、节点数、圈复杂度等) ;然后,将每个生成的算法视作一个节点,并根据其在进化过程中的“父子”派生关系连接这些节点,从而构建出一个可视化图谱,直观地展现代码的演化路径和趋势。
-
效果:该方法通过可视化分析,揭示了不同LLM具有独特的编码“风格”且生成的代码复杂度会随迭代增加,并发现代码复杂度与算法最终性能的关系因具体问题而异,并非越复杂越好。
2025.04
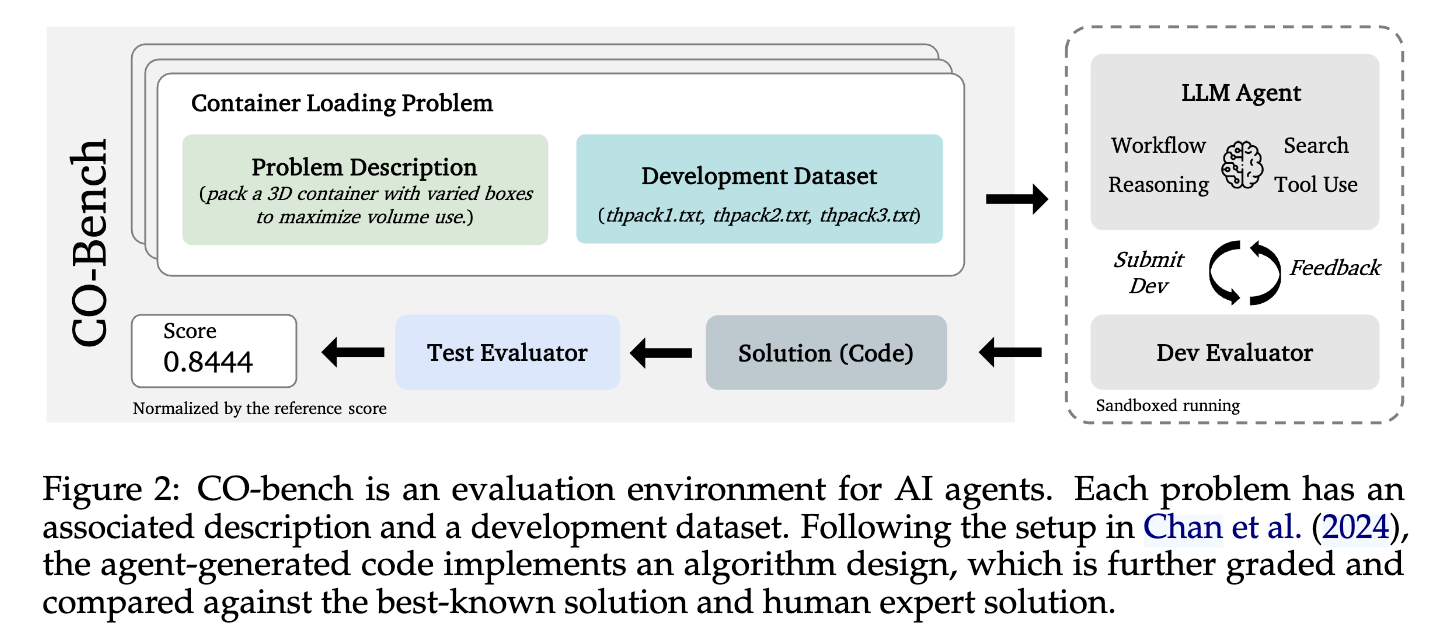
(06) CO-Bench: Benchmarking Language Model Agents in Algorithm Search for Combinatorial Optimization
arXiv
-
问题:当前缺乏一个标准且全面的基准,用来系统性地评估大语言模型(LLM)智能体为各种现实世界中的组合优化(CO)问题自动设计高效算法的能力。
-
方法:提出一个名为 CO-Bench 的新基准测试套件,其核心是提供一个包含36个真实世界问题的标准化评估环境 ,专注于衡量LLM智能体从问题描述开始,端到端地生成高效、甚至全新算法的综合研发能力,并引入了在同等时间限制下与人类专家的表现进行直接比较的基线。
-
效果:实验证明,最优的LLM智能体在该基准上生成的算法,在固定的30分钟研究预算内,于25个问题上(总计36个)超越了人类专家的表现。
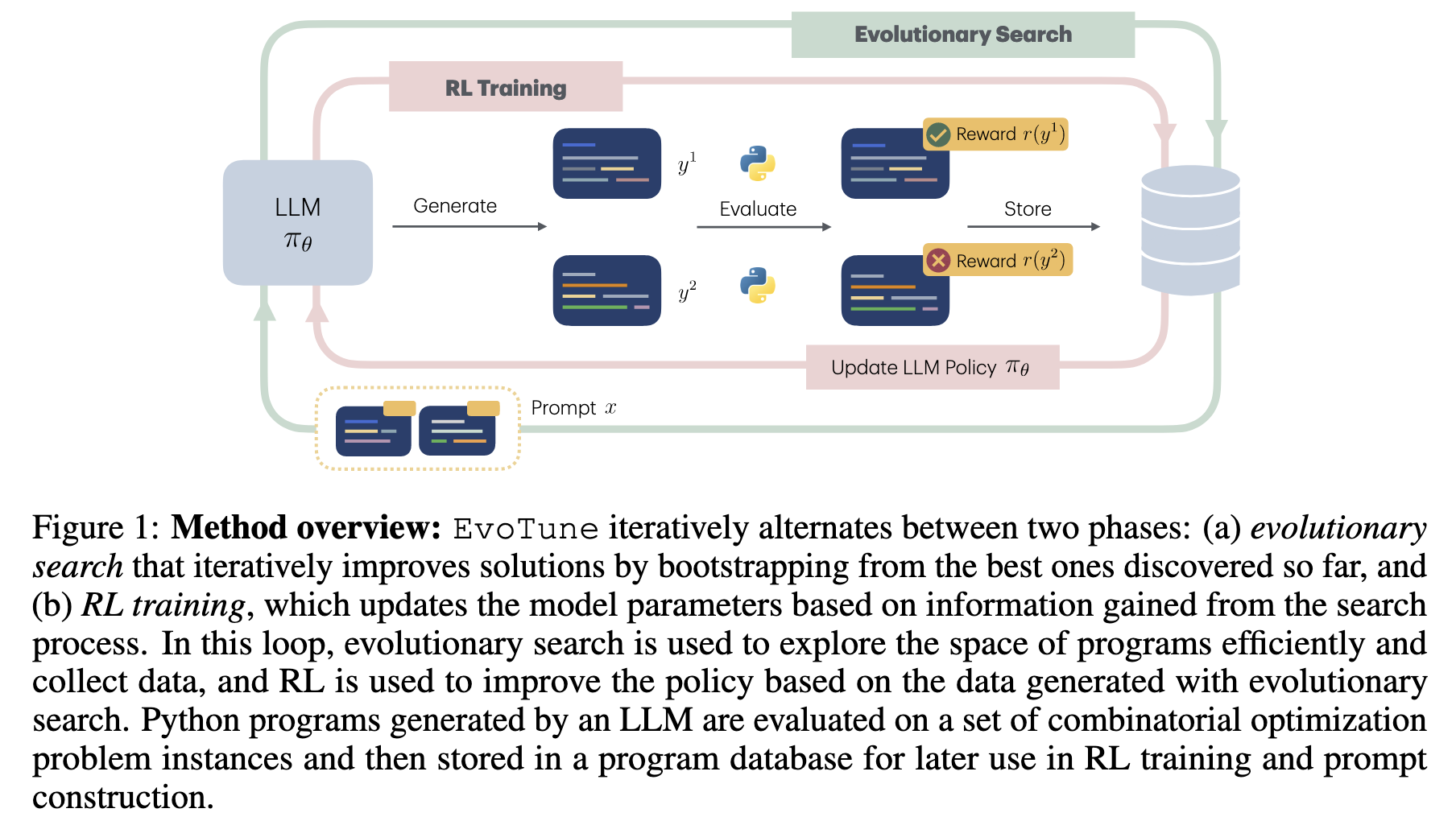
(07) Algorithm Discovery With LLMs: Evolutionary Search Meets Reinforcement Learning
arXiv
-
问题:现有的使用大语言模型(LLM)进行算法发现的方法(如 FunSearch),将 LLM 视作一个固定的、静态的程序生成器 。它在整个搜索过程中不会从发现的好坏算法中学习,因此其自身发现新算法的能力无法得到提升。
-
方法:提出了 EvoTune 方法,其核心创新在于将强化学习(RL)引入到基于 LLM 的演化搜索循环中,形成了一个反馈闭环 。具体来说,系统首先通过演化搜索来探索和评估 LLM 生成的算法程序 ;然后,将这些程序的表现好坏构造成偏好数据对(即“更优”与“次优”的程序配对) ,并利用这些数据通过强化学习(具体为直接偏好优化 DPO)来微调和更新 LLM 模型本身 。这个经过优化的 LLM 因此能“学会”生成更好的算法,从而在后续的搜索中表现更佳。
-
效果:在装箱问题(Bin Packing)、旅行商问题(TSP)和 Flatpack 问题这三个组合优化任务上,EvoTune 方法在固定的计算预算内,比纯演化搜索的基线方法(FunSearch)更高效地发现了性能更好、最优性差距更低的算法。
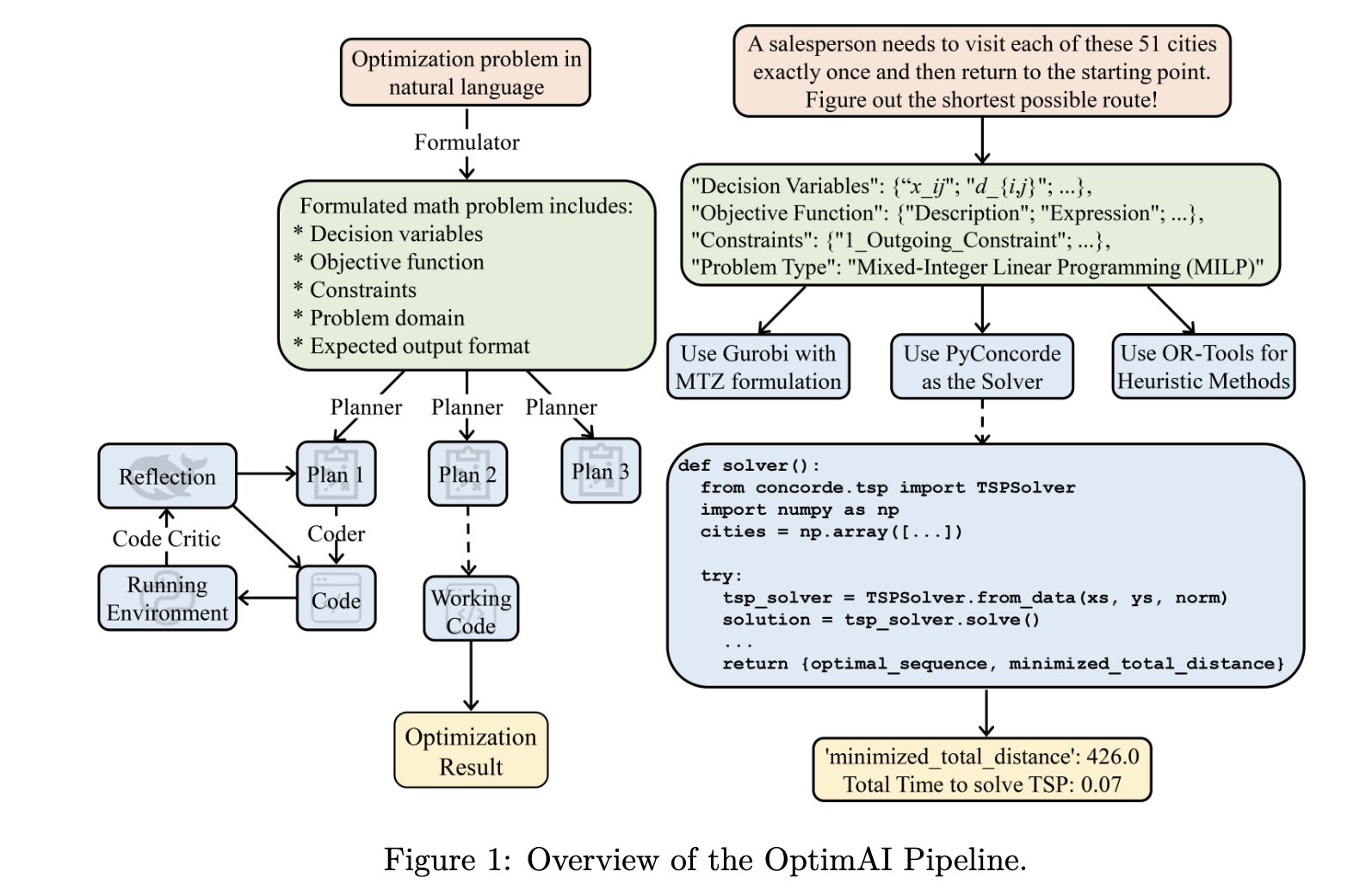
(08) OptimAI: Optimization from Natural Language Using LLM-Powered AI Agents
arXiv
-
问题:非专业人士很难将用自然语言描述的实际优化问题,转化为精确的数学模型并选择合适的求解器来解决。
-
方法:提出了一个名为 OptimAI 的框架,其核心是利用多个大型语言模型(LLM)驱动的 AI 智能体(Agent)协同解决问题。关键思想包括:
- 角色分工:设立了四个关键角色——表述器(Formulator)、规划师(Planner)、编码员(Coder)和代码评论员(Code Critic),将问题分解为数学建模、策略规划、代码生成和反思调试四个阶段。
- 规划优于编码:在编写代码前,由规划师生成多种备选解题策略。
- 动态决策:引入了基于 UCB(Upper Confidence Bound)算法的调试调度机制,当一个计划在调试中反复失败时,系统可以动态切换到更有希望的备用计划。
- 异构协作:允许为不同角色分配不同的 LLM 模型,通过组合不同模型的优势来提升整体性能。
-
效果:该方法在 NLP4LP 和 Optibench 两个标准优化问题数据集上分别实现了 88.1% 和 82.3% 的准确率,相较于之前的最佳方法,错误率分别降低了 58% 和 52%。
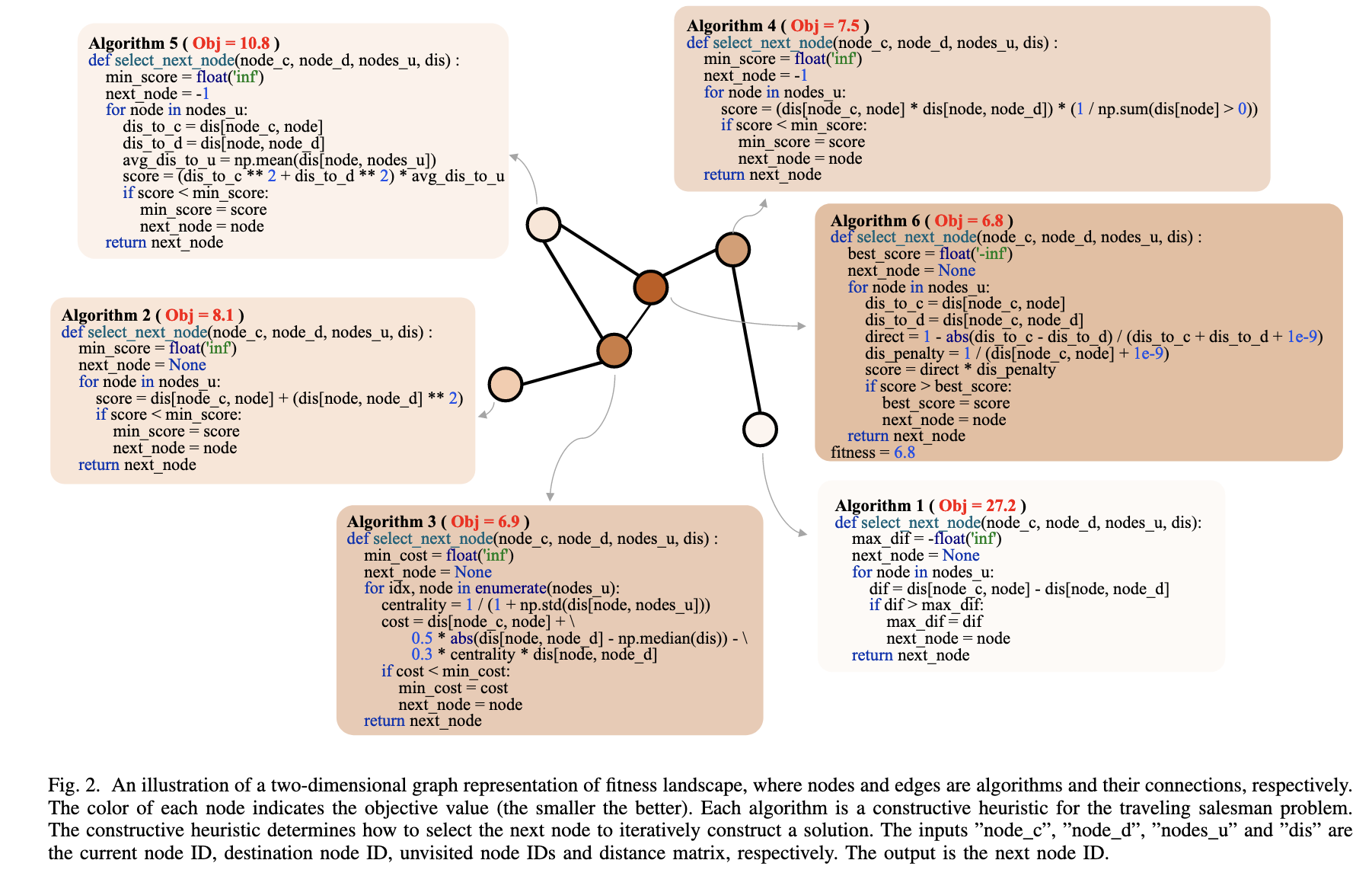
(09) Fitness Landscape of Large Language Model-Assisted Automated Algorithm Search
arXiv
-
问题:当使用大语言模型(LLM)来自动搜索和设计新算法时,我们对这个搜索过程的“优劣性地图”(即“适应度景观”)几乎一无所知,不清楚它长什么样,也不知道为何有时成功有时失败。
-
方法:提出了一个基于图(Graph-based)的可视化分析方法。 在这个方法中,搜索过程中产生的每一个算法都变成一个“节点”,如果一个算法(子代)是由另一个算法(亲代)通过LLM生成的,就在它们之间连接一条有向的“边”。 这样,抽象的算法搜索过程就被转换成了一个可供分析的具体网络结构。
-
效果:揭示了LLM辅助算法搜索的“地图”通常是崎岖且有多个“高峰”(多模态)的 ,并且地图的形态会因不同的设计任务和所使用的大语言模型而显著不同 ,从而为如何更有效地设计搜索框架提供了指导。
(10) Large Language Models powered Neural Solvers for Generalized Vehicle Routing Problems
ICLR 2025
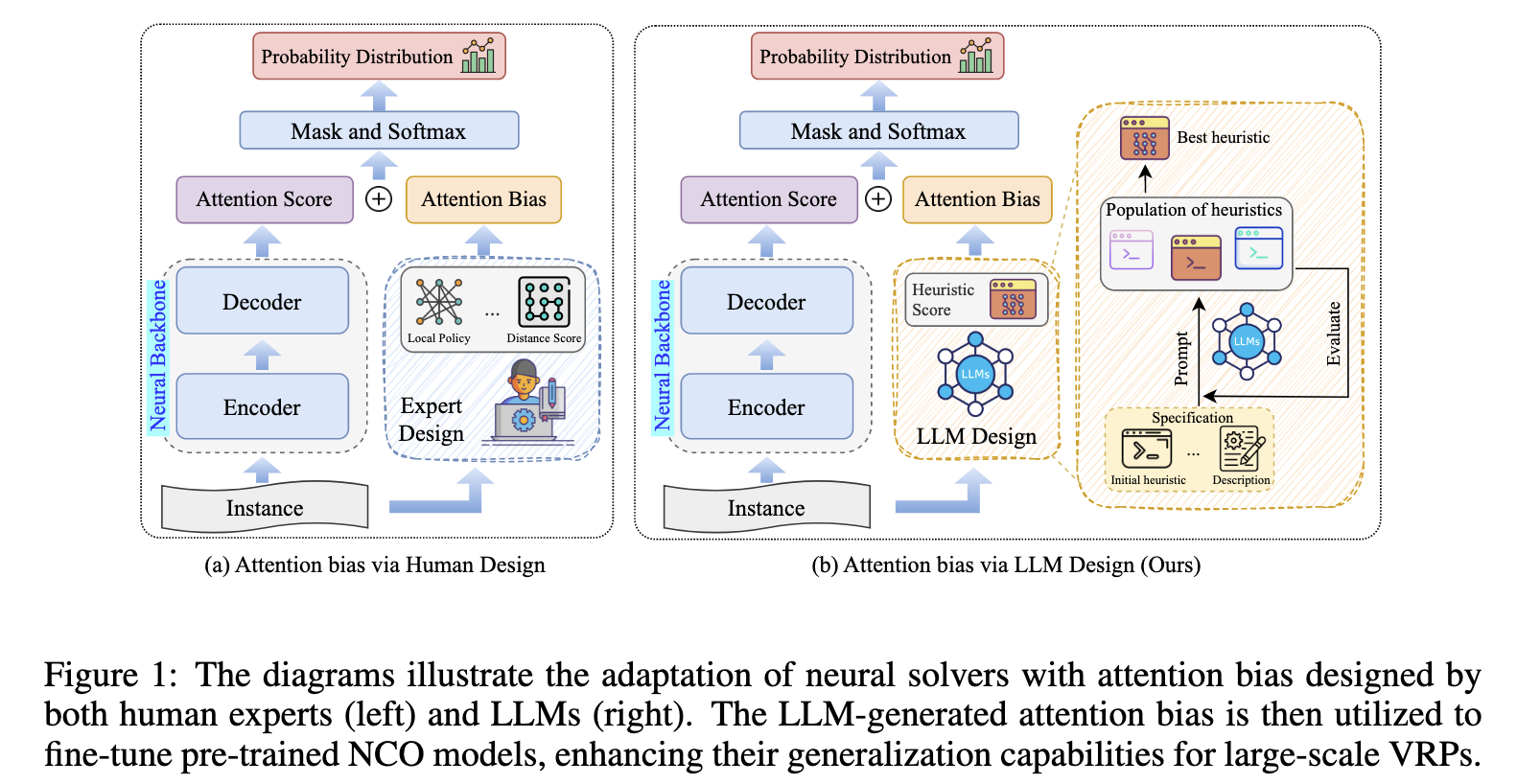
-
问题:现有的神经网络求解器在解决车辆路径规划问题(VRP)时,对于训练时未见过的大规模、复杂实例的泛化能力很差,难以扩展到真实世界的应用中。
-
方法:利用大型语言模型(LLM)在一个演化框架中自动设计和优化启发式算法,将生成的最佳策略转化为一个“注意力偏差”信号,并将其注入到预训练神经网络求解器的决策过程中,最后通过少量多样化的大尺寸实例对模型进行微调,从而高效地将LLM生成的策略知识迁移给求解器。
-
效果:在旅行商问题(TSP)和车辆路径问题(CVRP)的合成及真实世界数据集上均取得了当前最优的性能,显著提升了模型面对包含数千个节点的大规模问题时的泛化能力与求解质量。
更早
https://zhuanlan.zhihu.com/p/1930614603429183884
https://zhuanlan.zhihu.com/p/1930301683642119468
https://zhuanlan.zhihu.com/p/1931111568445248832