新版Qwen3深夜突袭:性能超越Kimi-K2、DeepSeek-V3
今天凌晨,阿里巴巴通义千问团队在魔搭社区和Hugging Face发布了一个新模型——Qwen3-235B-A22B-Instruct-2507-FP8。
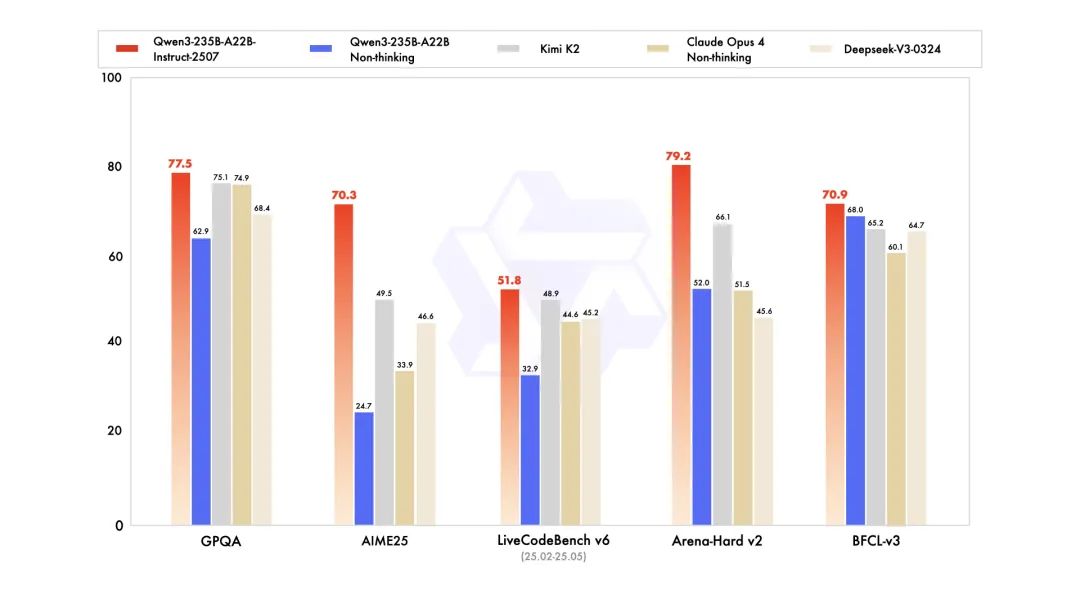
在官方公布的测评数据中,新版Qwen3在GQPA知识测试得分77.5(DeepSeek-V3仅68.4)、数学竞赛AIME25得分70.3(Kimi-K2为49.5)、编程测试LiveCodeBench达51.8(超过Kimi-K2的48.9)。更令人意外的是,它在人类偏好对齐测试Arena-Hard v2中甚至以79.2分超越了闭源巨头Claude-Opus4的51.5分。
此次升级最核心的转变,是阿里放弃了混合思考模式。此前同时处理“快思考”(指令执行)和“慢思考”(深度推理)的设计被拆解,转而分别训练Instruct和Thinking模型。
这种架构分离让新版Qwen3在指令响应速度上大幅提升,同时通过分层知识蒸馏技术压缩了模型体积。
据介绍,升级后的Qwen3在一般能力方面有显著提高,包括遵循指令、逻辑推理、文本理解、数学、科学、编码和工具使用等功能。
同时,跨多种语言的长尾知识覆盖率也大幅提升;还增强了256k长上下文理解能力。
有用户要求“用HTML制作完整的手机端POS系统”,结果Qwen3生成的界面让评测者直言“比Kimi-K2更令人印象深刻”。
阿里云智能总裁张建锋表示,新模型将很快接入钉钉智能助理和天猫精灵。Qwen3在BFCL智能体能力测试中取得70.9分(DeepSeek-V3为64.7),已经逼近人类专业助手水平。这意味着该模型在企业服务以及科研等领域将实现更广泛的应用。
阿里此次同步开源了中文强化训练数据集和企业级部署工具包,这恰是许多中小企业的痛点。
而Qwen3的FP8混合精度框架降低显存占用,让百亿模型在工业场景落地成为可能。这种从实验室到车间的能力迁移,正是中国AI产业化最需要的助推器。
值得注意的是,通义千问团队已在更新公告埋下彩蛋:“这只是一次小更新,还有大招即将到来!”专攻复杂推理的Thinking模型,或许正在赶来的路上。