从云端到指尖:MNN实现端侧大模型“量子压缩”
引言:
如果把今天的生成式 AI 比作一场席卷全球的“算力风暴”,那么移动端与 IoT 设备就是这场风暴最边缘、却也最广阔的“登陆点”。
云端的大模型像远洋巨轮,吞吐着千亿级参数,却始终受限于延迟、带宽与隐私;而端侧场景需要的,是一艘能驶入每一条毛细血管的“快艇”——既要轻盈,又要保留巨轮的远航能力。
在参数规模以“月翻倍”的速度野蛮生长的今天,大模型已成为 AI 洪流的新常态。然而,这股洪流的出口——推理侧——却正面临前所未有的瓶颈:当千亿级参数从 GPU 集群涌向终端,延迟、隐私、成本和无处不在的网络依赖,像四座闸门同时落下,将用户体验拦在“可用”与“好用”之间。
正是端侧 AI 的“逆行者”角色,为这场僵局撕开一道裂缝:毫秒级实时响应、数据全生命周期不出设备、毫瓦级低功耗、以及真正的离线能力,让模型第一次拥有了“贴身”的温度。
于是,问题被赤裸裸地摆上桌面:百亿参数的庞然大物,如何在一部只有几 GB 内存、几瓦功耗的手机、手表甚至耳机里活蹦乱跳?传统“砍层、剪枝、量化”三板斧,面对 100× 的体积鸿沟显得像钝刀切钢——越砍越失真,越省越难用。
1:MNN不是魔法,而是系统级创新
那么MNN到底是什么呢?
MNN (Mobile Neural Network) 是阿里巴巴内部自己研发的推理引擎。在它研发之初,TFLite刚刚发布,而且由于TFLite最初版有很多问题,为了快速响应业务的变化,阿里巴巴决定内部自己研究推理引擎MNN。MNN技术在2019年5月初在Github开源。开源至今,受益于阿里巴巴内部的用户和开源社区用户的反馈,MNN逐渐成长为一个优秀的、成熟稳定的推理引擎。目前,在阿里巴巴内部,MNN是端上推理引擎的事实标准。
MNN主要解决的是现在端智能的两大问题:1. 底层的硬件、操作系统碎片化 (CPU、GPU、NPU, Android/iOS, Mobile/IOT) 2. 机器学习的框架复杂(TFLite,PyTorch, ONNX, etc.)。为了能够在不同的硬件、操作系统里发挥最好的功能,MNN会在运行时根据运行环境寻找出最快的算子实现算法(我们称这个过程为“半自动搜索”)。
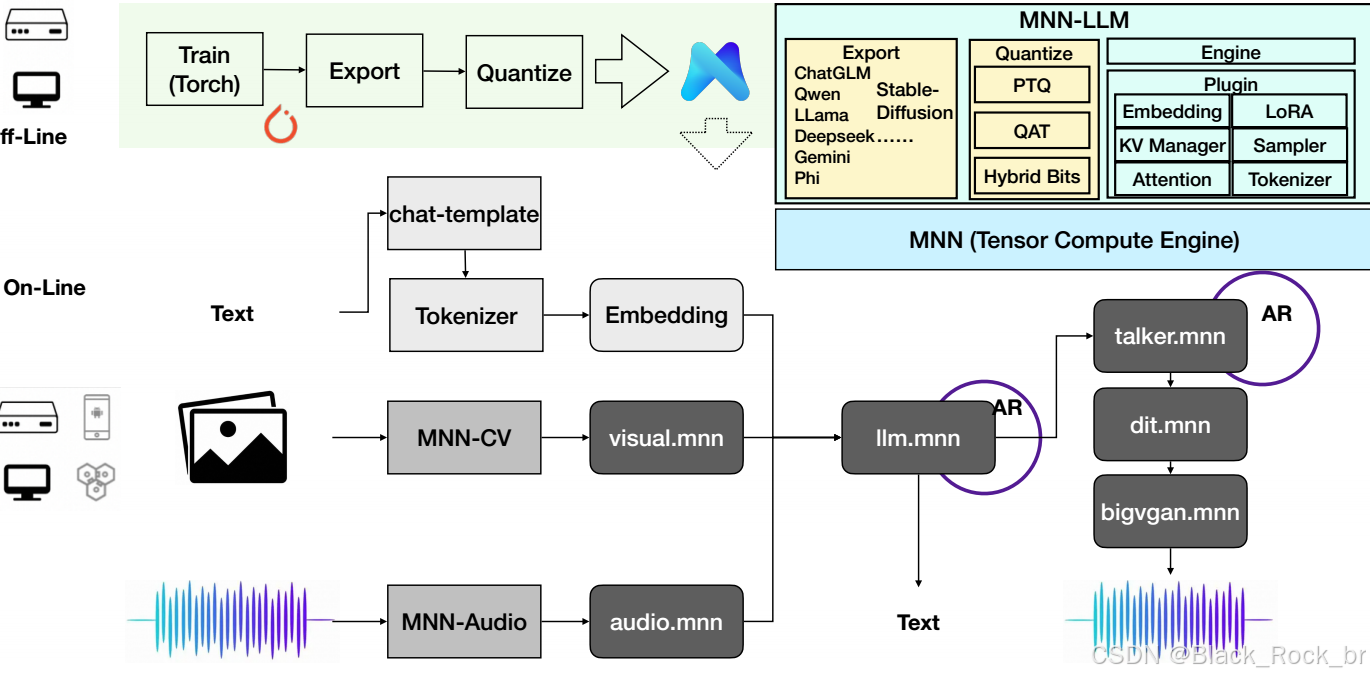
MNN-LLM 架构图
第一:MNN 的性能是领先于业界的。2024年9月的数据:
ARM 端:单线程 MobileNet V3-large MNN ≈ 1.8× TFLite;4 线程 MNN ≈ 3.5× TFLite。
x86 端(AVX-512 实测):单精度矩阵乘 MNN 再快 60 %;INT8 直接翻 2×。
GPU 端(OpenCL/Vulkan/Metal):主流视觉模型 延时最低,比 CoreML / TFLite-GPU 再省 10–30 %
第二:体积:依旧“袖珍”
Android so:≈ 3 MB(含全部 CPU+GPU backend);
iOS 静态库:< 5 MB(arm64+armv7 合并,含 Metal);
量化工具链:仅权重量化 8-bit 模型大小 ↓4×,精度无损
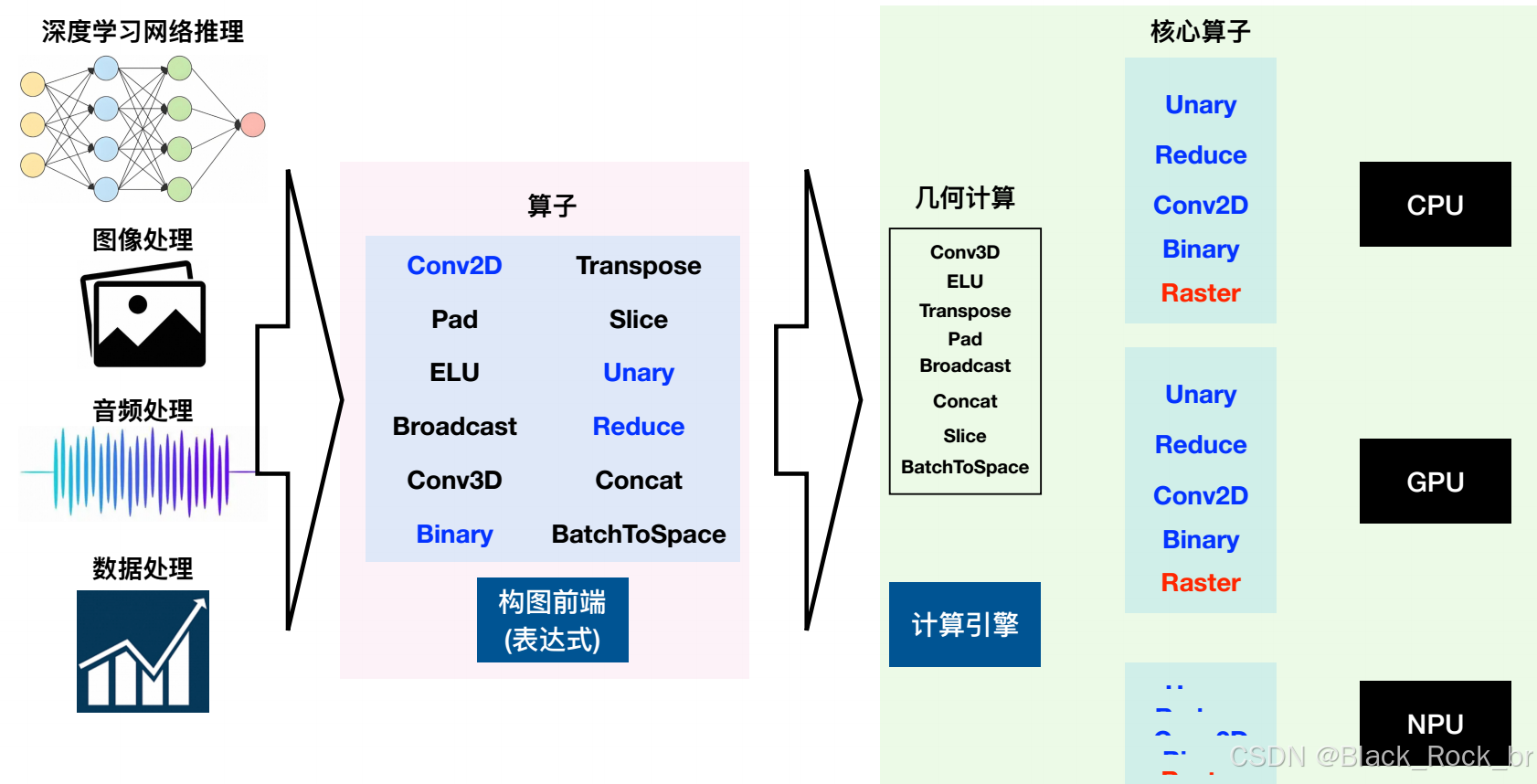
第三:MNN 支持多种异构设备。CPU方面,MNN 支持了X86,ArmV7, V8。GPU 方面,MNN 支持了 OpenCL, OpenGL, Vulkan, Metal。NPU方面,MNN 支持了华为的 NPU ,并用在手淘的拍立淘场景中。
第四:算子与生态:从“够用”到“全覆盖”
算子总量 > 700 个(含 Transformer、Diffusion、LLM 所需全部核心 OP);
一键转换:TensorFlow / PyTorch / ONNX → MNN,零失败率;
Python 调试桥 + Netron 可视化 + Profiler,算法同学 5 分钟可上手
一句话总结
当别人还在为“跑得快”或“装得下”二选一时,MNN 已把“跑得快 + 装得下 + 跑得广”做成默认配置。
在 2024 年的端侧战场,选 MNN 就是选 性能上限、体积下限、生态全覆盖。
2:MNN 的主要模块-技术突破:如何实现“压缩不减智”?
MNN 能在端侧把“大模型”变“小模型”,再把“小模型”跑得飞快,靠的是一条端到端流水线。它由三大核心模块——模型转换器(Converter)、模型量化工具链(Quantization Suite)、推理引擎(Runtime)——层层接力,把 PyTorch / TF / ONNX 训练好的“庞然大物”一步步压缩成能在手机、手表、车机里毫秒级响应的“袖珍战士”。下面按“输入 → 输出”拆开细看:
模型转换器(MNN-Converter)
任务:把任何训练框架的模型一次性翻译成 MNN 统一 IR,后续无论跑 Android、iOS 还是 MCU,都用同一份 .mnn 文件。
• 支持格式
‑ PyTorch (TorchScript / ExportedProgram)
‑ TensorFlow (SavedModel / GraphDef)
‑ ONNX opset 7–19
‑ Caffe, TFLite(历史遗留)
• 转换功能
‑ 算子融合:Conv+BN+ReLU → 单算子,减少 30 % Kernel 调用
‑ Shape 推断:提前把静态 shape 写进模型,推理零开销
‑ 子图切分:自动把 Conv 留给 NPU,把 Softmax 留给 CPU,实现异构最优
• 输出产物
‑ .mnn 文件:跨平台、可加密、可增量热更新
‑ 可视化 JSON:丢进 Netron 直接看拓扑
‑ 兼容性报告:告诉你哪些算子不被目标设备支持,一键给出替换方案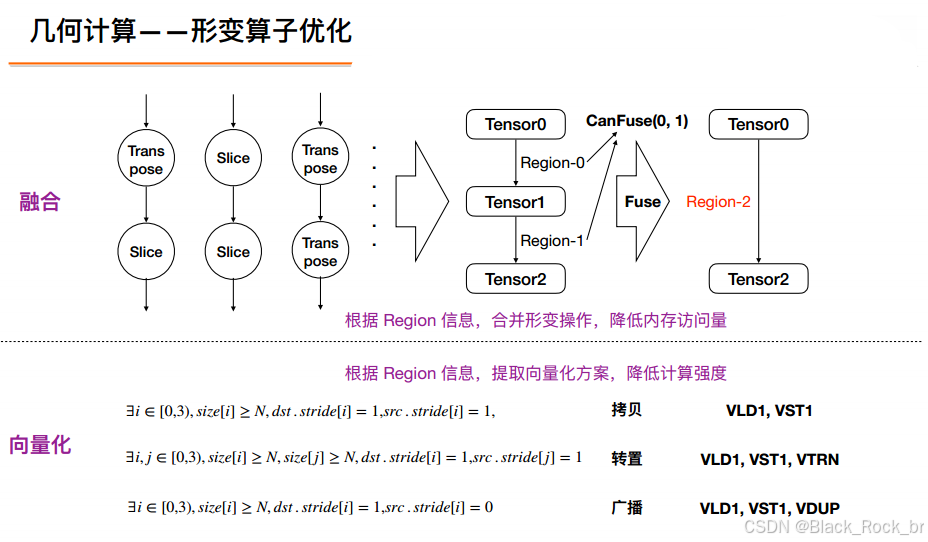
─────────────────
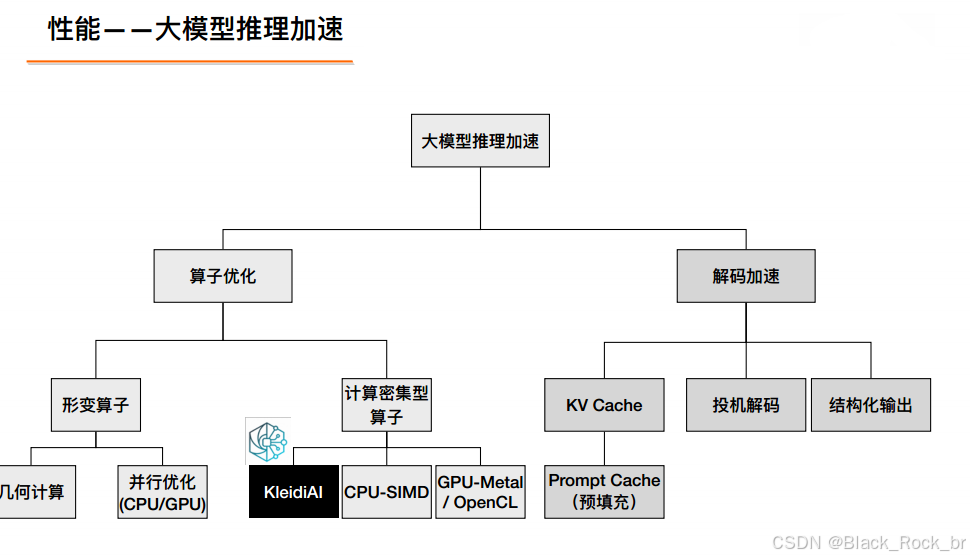
2. 模型量化工具链(MNN-Quant / Compress / Calibrate)
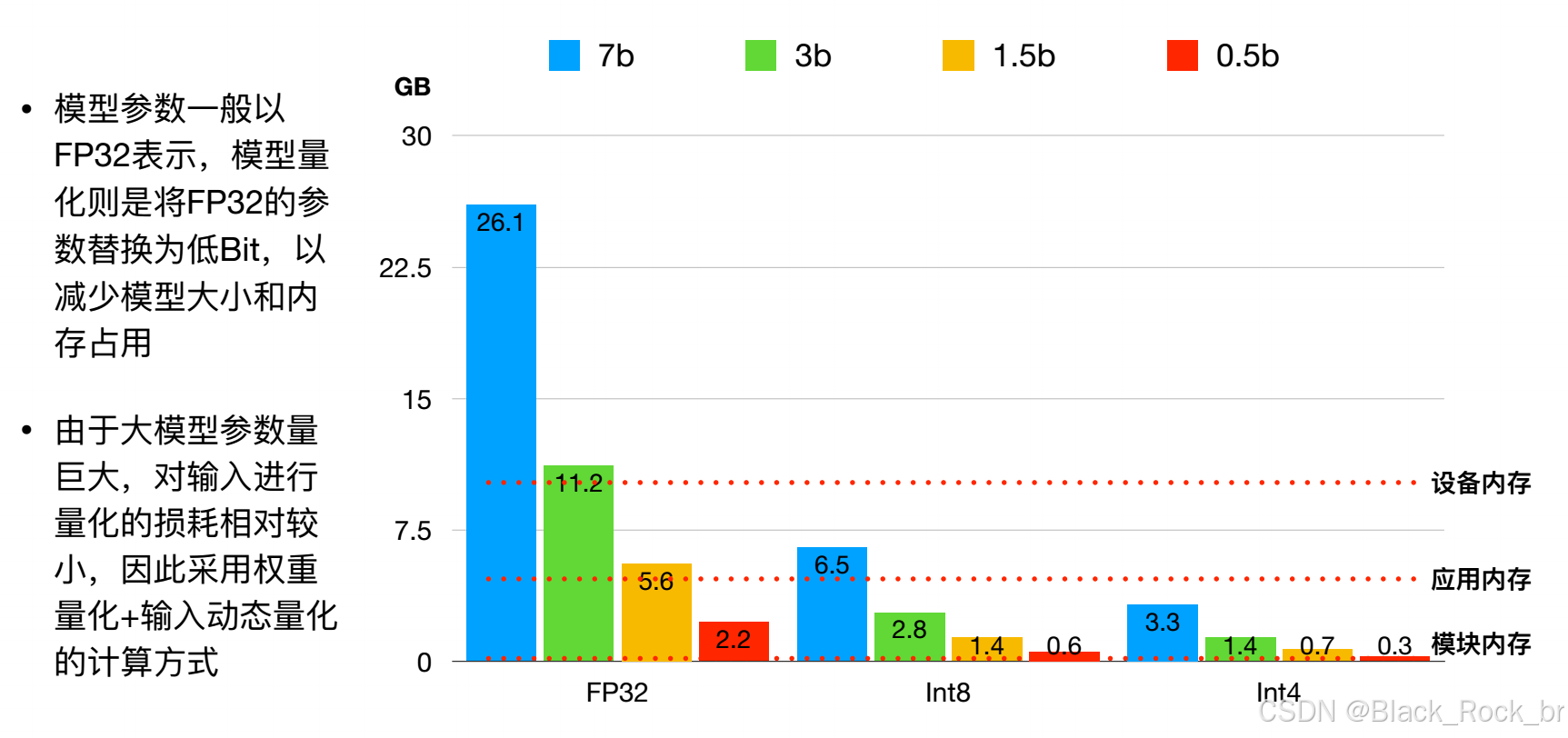
任务:在精度几乎不掉点的前提下,把 FP32 权重和激活值压到 INT8、INT4 甚至 2-bit,连带把 KV-Cache 也“瘦身”。
• 量化模式
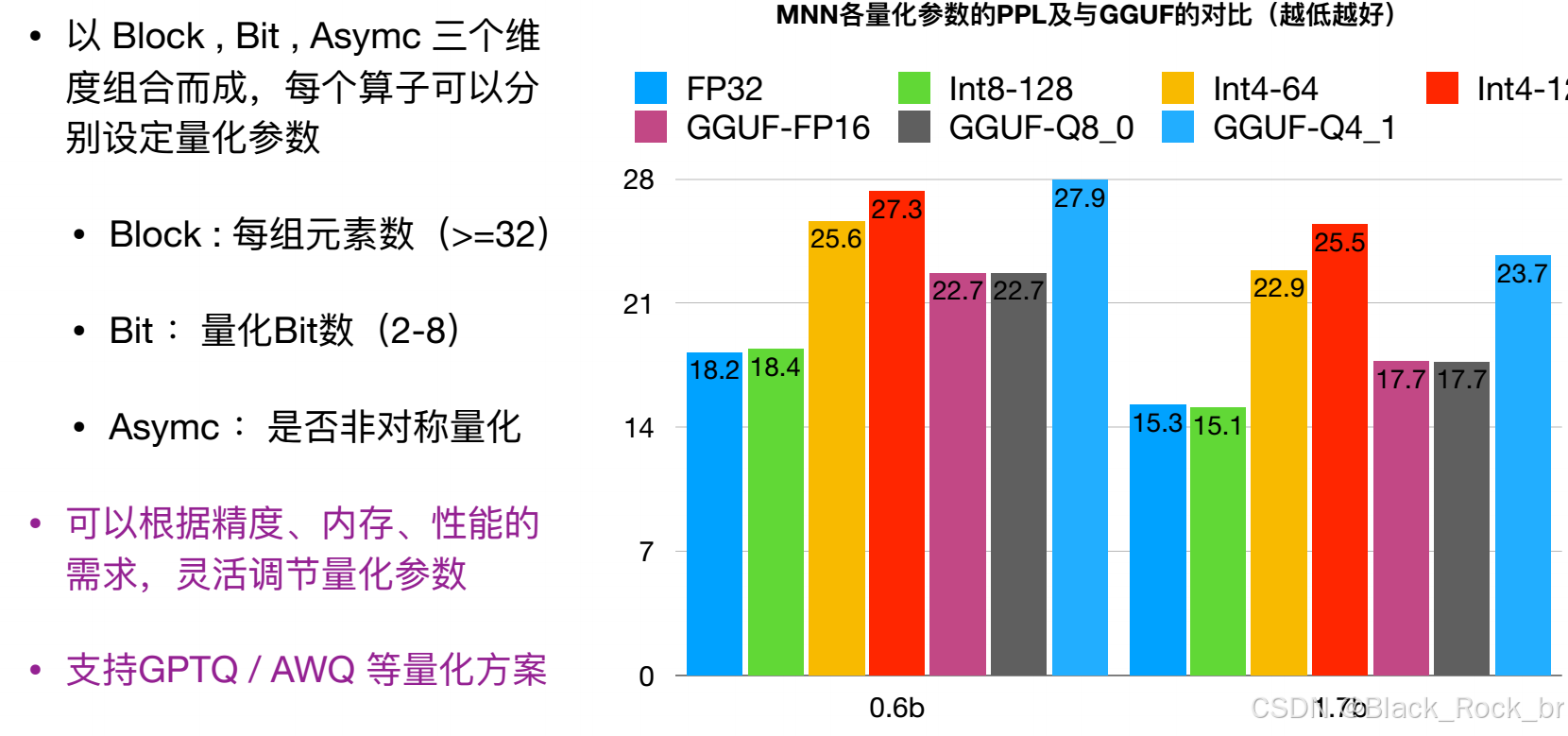
‑ PTQ 离线量化:无需重训练,支持 KL、MSE、Percentile 校准策略
‑ QAT 量化感知训练:训练时插入伪量化节点,精度可保持 FP32 的 99 %
‑ Weight-Only 4-bit:专供 LLM,70 B 模型 → 6 GB 端侧可跑
‑ KV-Cache 8-bit 动态量化:首 token 延迟再降 25 %
• 压缩工具
‑ 稀疏化:结构化稀疏 50 %,配合 NPU Sparse Tensor 指令提速 2×
‑ 低秩分解:把大矩阵拆成两个小矩阵,内存峰值 ↓40 %
‑ LoRA 打包:导出 30 MB 增量包,端侧 OTA 热插拔
• 验证与调试
‑ 误差计算器:逐层输出余弦相似度、SNR,一键定位掉点层
‑ Golden 对比:自动与 FP32 结果逐 Pixel 对齐,CI 直接跑回归
─────────────────
3. 推理引擎(MNN Runtime)
任务:把转换 + 量化后的模型在目标设备上跑到极限。
• 多后端
‑ CPU:ARMv7/v8/v9、x86-64(AVX2/AVX-512/SSE)、RISC-V;自研 NEON/AVX 汇编 Kernel,单线程速度常年霸榜
‑ GPU:OpenCL、Vulkan、Metal、CUDA,支持 Winograd / TensorCore / FP16 / INT8
‑ NPU:华为 Ascend、高通 Hexagon、联发科 APU、瑞芯微 NPU,零拷贝执行
‑ 异构调度器:运行时根据算力、功耗、温度自动把子图分派到最优后端
• 内存与线程
‑ Memory Pool:推理全程零 malloc/free,最大内存峰值可预估
‑ Thread Pool:可绑定大核 / 小核,支持优先级抢占,4 线程扩展比 > 3.5
• LLM 专属优化
‑ Paged KV-Cache:分块换入换出,14 B 模型在手机 6 GB RAM 稳跑
‑ 投机解码(Speculative Decoding):小模型草稿 + 大模型验证,吞吐再提 2×
‑ 量化缓存:INT4 权重常驻显存,FP16 激活值动态解压,带宽减半
• 部署与集成
‑ C/C++/Java/Python/OC/Swift 多语言 API,一行代码即可推理
‑ 模型加密:AES-128 流式解密,防止反编译
‑ AAR / XCFramework / npm 包:Android Studio / Xcode / Node 一键集成
3:下一站,MNN 的“两张地图”
——既要修好脚下的路,也要把未来的桥搭好。
开箱即用的 MNN-Toolbox
‑ 一条命令mnn init、mnn quant、mnn bench,模型转换→量化→跑分全搞定。在线文档 + 交互式 Notebook
‑ 像查字典一样查 API,像写 Python 一样改模型。预编译包全家桶
‑ Android AAR、iOS XCFramework、HarmonyOS hap、Linux deb、Windows NuGet,全部 CI 每日构建,拿来即跑。迁移学习“零门槛”
-2025 年春节前上线 MNN-Train Lite:3 行代码就能把 MobileNet 换成你的分类任务,端侧直接训练,10 分钟出模型。
NPU 统一战线
‑ 华为 Ascend、高通 Hexagon、联发科 APU、瑞芯微 NPU、三星 NPU… 全部塞进 MNN-NPU Hub,一套 C++/Java/Kotlin API 打天下。
‑ 2025 Q3 起,开发者无需关心芯片型号,MNN 自动“嗅”出最优后端。
MNN × 小程序 2.0
‑ 今年双 11,ModiFace 小程序用 MNN 跑 3D 试妆,比 TFJS 提速 8×、内存降 60 %。
‑ 2025 年开放 MNN-Miniprogram SDK,外部开发者像调 JS 函数一样调 AI
模型压缩进入“分子级”时代
‑ 2025 Q4 上线 MNN-Quantum:
‑ 支持 2-bit 权重 + 4-bit KV-Cache,Llama-7B 再缩 50 %,精度掉点 < 1 %。
‑ 端侧 LoRA 增量包可压缩到 10 MB,大模型 OTA 像换壁纸一样简单。
端云协同 Runtime
‑ 2026 路线图:手机端跑 7 B“草稿机”,云端跑 70 B“精修机”,MNN 内置 投机解码 + 动态蒸馏 协议,首 token 延迟 < 50 ms,全程 0 流量泄露。
今天的 MNN 把“难”留给自己,把“易”交给开发者;明天的 MNN 把“大”留在云端,把“小”塞进终端,让 AI 像空气一样无处不在,却看不见摸不着。