我的第一个开源项目 -- 实时语音识别工具
这是我的第一个开源项目,是我一直想做的一个小工具:
端到端实时语音转文字系统。
通过小程序和H5页面,用户可以实时采录音频,通过ws上传到java的netty server。
Java在经过权限验证、流量控制等操作之后,通过gRPC流式发送给python服务。
python项目通过开源的 speech_paraformer 模型实时识别文字结果,然后发送给java,java 发给客户端实时展示。
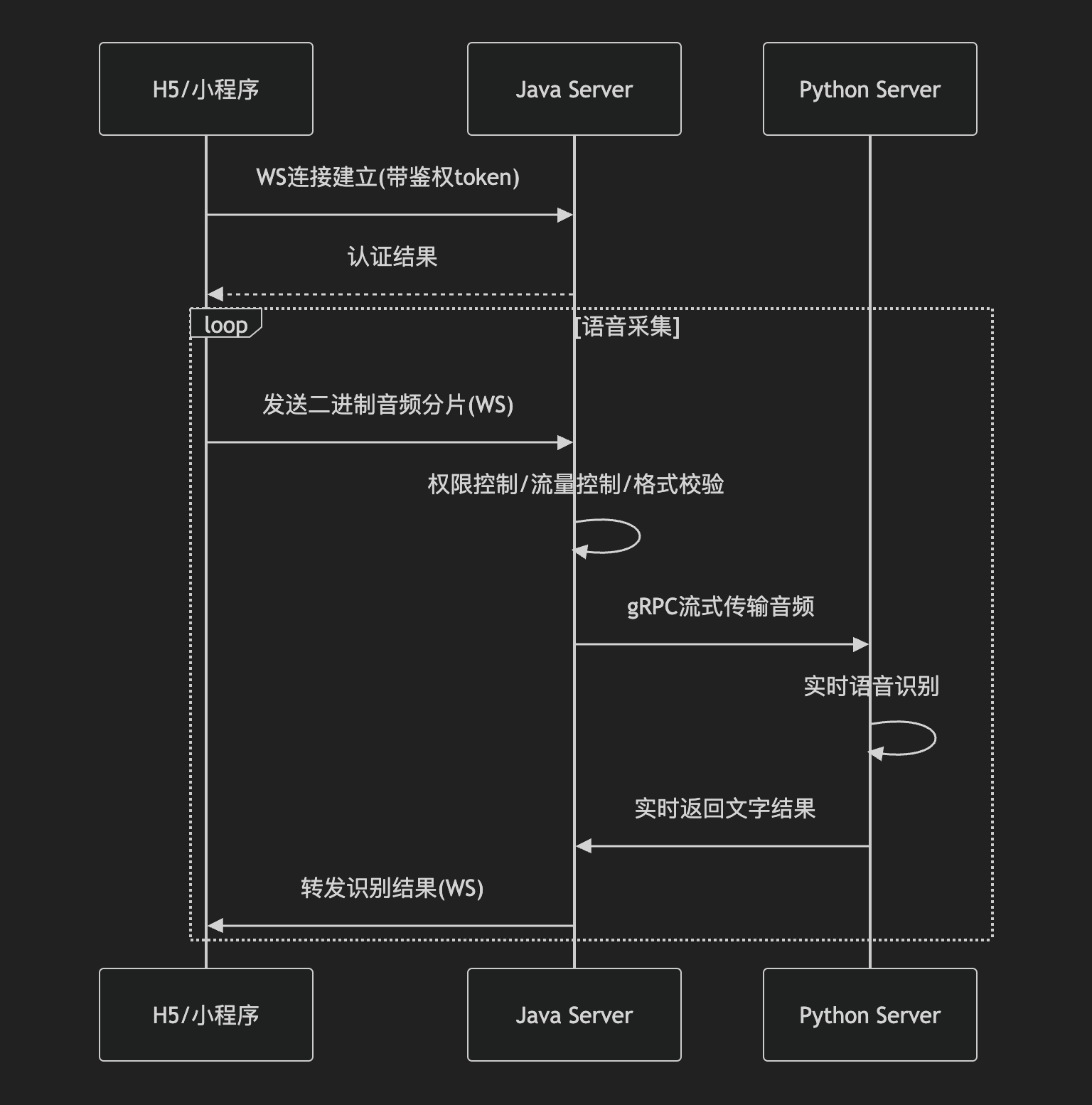
系统架构
1. 前端采集层(开发中)
- 小程序/H5页面:提供用户友好的录音界面
- 实时音频采集:使用Web Audio API实现高质量音频捕获
- WebSocket传输:建立低延迟的双向通信通道
2. Java中间层(初版)
- Netty服务器:处理高并发的WebSocket连接
- 安全验证:实现基于JWT的权限控制
- 流量管理:采用令牌桶算法进行请求限流
- gRPC网关:与Python服务进行高效通信
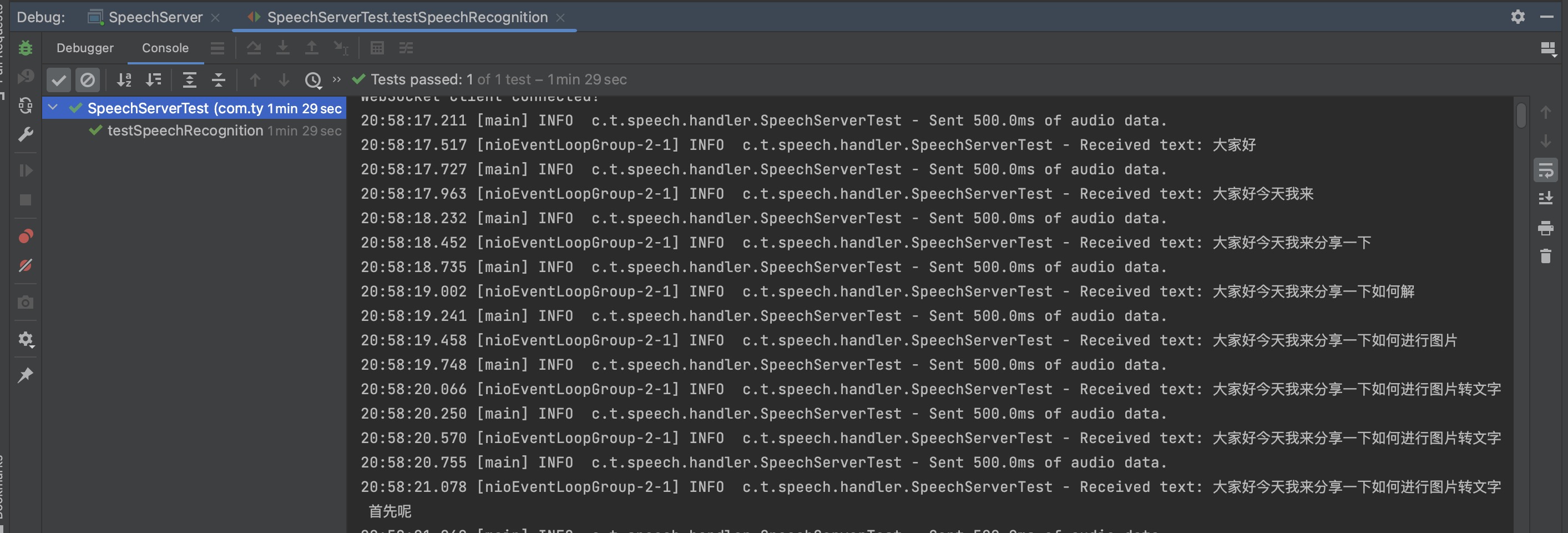
3. Python识别层(初版)
- speech_paraformer模型:使用这个开源的语音识别模型进行实时转写
- 流式处理:支持边录音边识别的实时模式
- 结果优化:对识别结果进行后处理,提高准确率
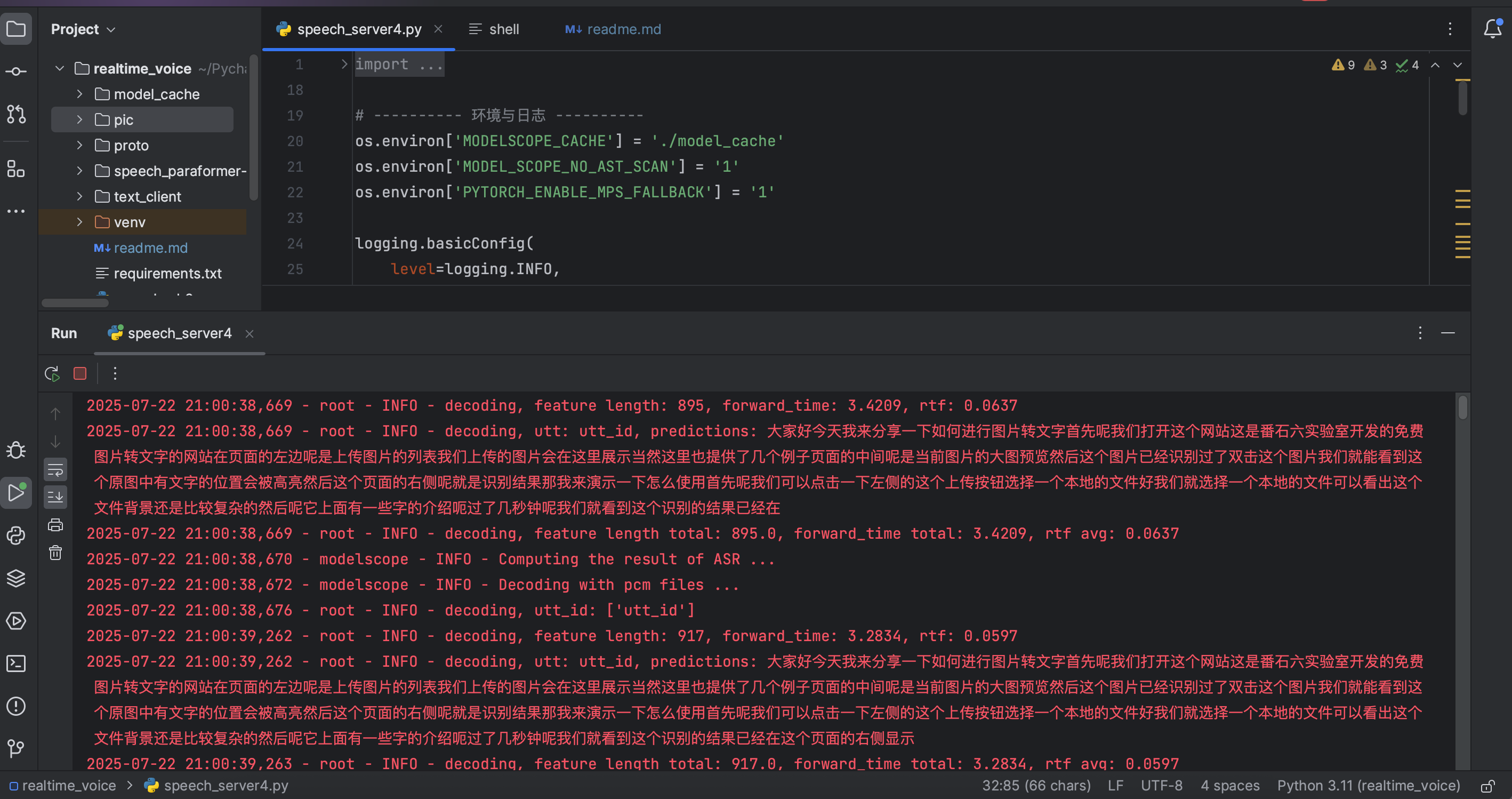
技术亮点
- 全流程实时处理:从录音到文字展示,延迟目标控制在毫秒级
- 高性能架构:Netty+gRPC的组合确保系统的高吞吐量
- 开源模型集成:使用speech_paraformer提供高质量的识别效果
- 完善的权限控制:从客户端到服务端的多层安全验证
应用场景
这个系统可广泛应用于:
- 在线会议实时字幕
- 语音笔记自动转写
- 直播场景的字幕生成
- 语音交互应用的开发基础
开源计划
我已经将项目完整代码开源在GitHub上
h5:
TBD
mini program
TBD
java 项目地址:https://github.com/TongDaxia/realtime_voice_to_text
python 项目地址:https://github.com/TongDaxia/realtime_voice_to_text_engine
欢迎大家:
- 试用并提出改进建议
- 参与代码贡献
- 基于此项目进行二次开发