SHAP的升级版:可解释性框架Alibi的相关介绍(一)
shap理论的升级框架,涵盖更广泛,其中反事实部分是笔者比较感兴趣想细究的。
github地址:
https://github.com/SeldonIO/alibi?tab=readme-ov-file
文档地址:
https://docs.seldon.io/projects/alibi/en/stable/index.html
文章目录
- 1 Alibi 0.9.5 文档译文
- 1.1 Alibi的可解释性
- 1.2 全局与局部洞察
- 1.3 洞察类型
- 1.3.1 全局特征归因
- 1.3.2 累积局部效应
- 1.3.3 部分依赖
- 1.3.4 部分依赖方差
- 1.3.5 排列重要性
- 1.3.6 局部必要特征
- 1.3.7 对比解释方法(相关正例)
- 1.3.8 局部特征归因LFA
- 1.3.9 核SHAP
- 1.3.10 路径依赖树SHAP
- 1.3.11 干预树SHAP
- 1.4 反事实实例(Counterfactual instances)
- 1.5 相似性解释(Similarity explanations)
1 Alibi 0.9.5 文档译文
翻译地址:
https://docs.seldon.io/projects/alibi/en/stable/overview/high_level.html
与文章【不仅仅是 SHAP,使用 ALIBI 在 Python 中获得更多可解释性】
1.1 Alibi的可解释性
可解释性为我们提供了一组算法,这些算法能够对训练模型的预测提供洞察。它使我们能够回答以下问题:
- 预测如何根据特征输入而变化?
- 对于给定的预测,哪些特征是重要的,哪些不是?
- 需要最小改变哪些特征才能获得你选择的新预测?
- 每个特征如何贡献于模型的预测?
Alibi 提供了一组称为解释器的算法或方法。每个解释器提供某种关于模型的洞察。给定训练模型可用的洞察集依赖于多个因素。
例如,如果模型是回归模型,询问预测如何随某个回归特征变化是有意义的。而询问获得新类别预测所需的最小变化则没有意义。一般来说,给定模型,Alibi 提供的解释器受到以下限制:
- 模型处理的数据类型。每个洞察适用于以下某些或所有数据类型:图像、表格或文本。
- 模型执行的任务。Alibi 为回归或分类模型提供解释器。
- 使用的模型类型。模型类型的示例包括神经网络和随机森林。
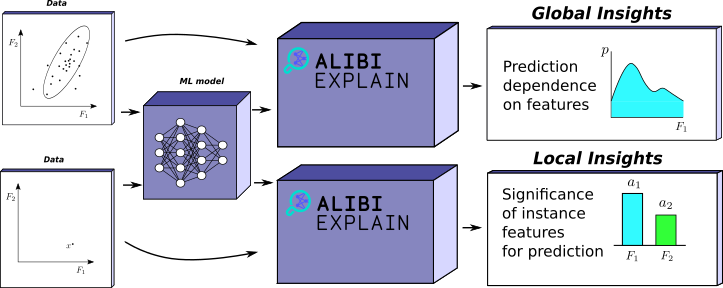
1.2 全局与局部洞察
洞察可以分为两类——局部和全局。直观地说,局部洞察描述模型所做的单个预测。例如,给定一张被模型分类为猫的图像,局部洞察可能给出需要保持不变的特征(像素),以便该图像仍被分类为猫。
另一方面,全局洞察指的是模型在一系列输入上的行为。例如,显示回归预测如何随特定特征变化的图表。这些洞察提供了输入与模型预测之间关系的更一般理解。
可解释性也存在重大偏差:可解释性 ≠ 客观性
虽然解释器增强了理解,但它们并不免于偏见:
- 数据偏见:如果您的数据包含偏见(例如,种族或性别偏差),模型及其解释将反映这些偏见。
- 人类偏见:解释可能会受到我们自身期望的影响。如果模型的推理与我们预期的不一致,我们可能会不信任它,即使它是正确的。
- 复杂性 ≠ 错误性:某些解释(例如,接近决策边界的锚点)可能很复杂。不要将复杂性误认为是错误。
🧠 示例:风险分析师使用 SHAP 值来验证模型时,可能会确认它“是合理的”——但仅在他们自己(可能有偏见的)期望的范围内。
1.3 洞察类型
Alibi 提供了几种局部和全局洞察,以便探索和理解模型。以下内容使从业者了解在何种情况下哪些解释器是合适的。
| 解释器 | 范围 | 模型类型 | 任务类型 | 数据类型 | 用途 | 资源 |
|---|---|---|---|---|---|---|
| 累积局部效应 | 全局 | 黑箱 | 分类、回归 | 表格(数值) | 模型预测如何随感兴趣特征变化? | docs, paper |
| 部分依赖 | 全局 | 黑箱、白箱(scikit-learn) | 分类、回归 | 表格(数值、分类) | 模型预测如何随感兴趣特征变化? | docs, paper |
| 部分依赖方差 | 全局 | 黑箱、白箱(scikit-learn) | 分类、回归 | 表格(数值、分类) | 哪些特征在全局上最重要?特征之间的交互程度如何? | docs, paper |
| 排列重要性 | 全局 | 黑箱 | 分类、回归 | 表格(数值、分类) | 哪些特征在全局上最重要? | docs, paper |
| 锚点 | 局部 | 黑箱 | 分类 | 表格(数值、分类)、文本和图像 | 确保预测保持不变的特征集是什么? | docs, paper |
| 相关正例 | 局部 | 黑箱、白箱(TensorFlow) | 分类 | 表格(数值)、图像 | “” | docs, paper |
| 集成梯度 | 局部 | 白箱(TensorFlow) | 分类、回归 | 表格(数值、分类)、文本和图像 | 每个特征对模型预测的贡献是什么? | docs, paper |
| 核SHAP | 局部 | 黑箱 | 分类、回归 | 表格(数值、分类) | “” | docs, paper |
| 路径依赖树SHAP | 局部 | 白箱(XGBoost, LightGBM, CatBoost, scikit-learn 和 pyspark 树模型) | 分类、回归 | 表格(数值、分类) | “” | docs, paper |
| 干预树SHAP | 局部 | 白箱(XGBoost, LightGBM, CatBoost, scikit-learn 和 pyspark 树模型) | 分类、回归 | 表格(数值、分类) | “” | docs, paper |
| 反事实实例 | 局部 | 黑箱(可微分)、白箱(TensorFlow) | 分类 | 表格(数值)、图像 | 重新分类当前预测需要哪些特征的最小变化? | docs, paper |
| 对比解释方法 | 局部 | 黑箱(可微分)、白箱(TensorFlow) | 分类 | 表格(数值)、图像 | “” | docs, paper |
| 基于原型的反事实 | 局部 | 黑箱(可微分)、白箱(TensorFlow) | 分类 | 表格(数值、分类)、图像 | “” | docs, paper |
| 强化学习反事实 | 局部 | 黑箱 | 分类 | 表格(数值、分类)、图像 | “” | docs, paper |
| 相似性解释 | 局部 | 白箱 | 分类、回归 | 表格(数值、分类)、文本和图像 | 根据模型,训练集中与感兴趣实例最相似的实例是什么? | docs, paper |
1.3.1 全局特征归因
全局特征归因方法旨在显示模型输出对输入特征子集的依赖关系。它们提供全局洞察,描述模型在输入空间上的行为。例如,累积局部效应图获得直接可视化特征与预测之间关系的图形。
假设一个训练好的回归模型,根据温度、湿度和风速预测某一天租用的自行车数量。温度特征的全局特征归因图可能是绘制的线图,显示租用的自行车数量与温度之间的关系。可以预期,在特定温度之前,租用量会增加,然后在温度过高后减少。
1.3.2 累积局部效应
Alibi 提供累积局部效应(ALE)图,因为它们提供了最准确的洞察。
我们在葡萄酒质量数据集上说明 ALE 的使用,该数据集是一个以葡萄酒质量为目标变量的表格数值数据集。由于我们希望进行分类任务,因此使用 5 作为阈值将数据分为好和坏类别。我们可以通过简单地使用 Alibi 计算 ALE(请参见笔记本):
from alibi.explainers import ALE, plot_ale# 模型是二分类器,因此我们只取第一个模型输出,对应于“好”类概率。
predict_fn = lambda x: model(scaler.transform(x)).numpy()[:, 0]
ale = ALE(predict_fn, feature_names=features)
exp = ale.explain(X_train)# 绘制“酒精特征”的解释
plot_ale(exp, features=['alcohol'], line_kw={'label': 'Probability of "good" class'})
因此,我们看到模型预测较高酒精含量的葡萄酒为更好的葡萄酒。
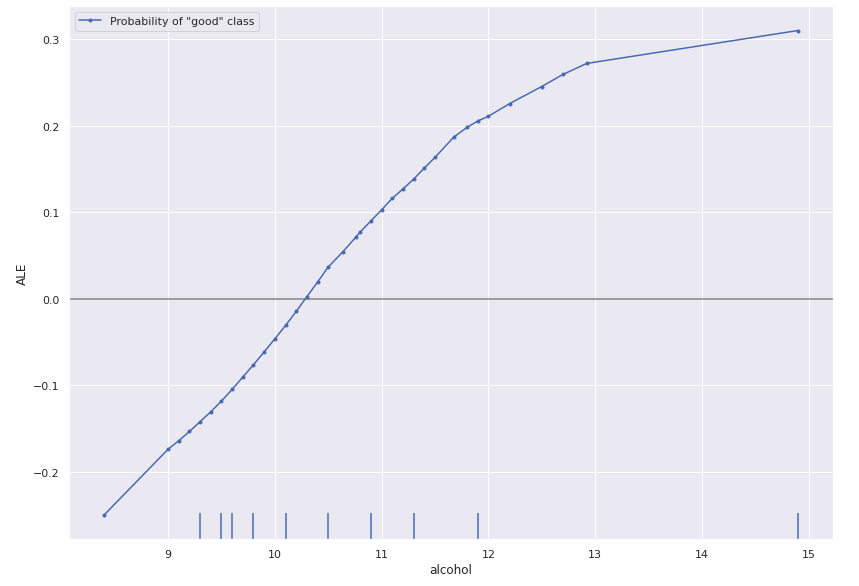
请注意,虽然 ALE 在数值表格数据上是明确定义的,但在分类数据上并不明确。这是因为不清楚两个分类值之间的差异应该是什么。请注意,如果数据集中有混合的分类和数值特征,我们始终可以计算数值特征的 ALE。
优缺点
| 优点 | 缺点 |
|---|---|
| ALE 图易于可视化并直观理解 | 比起 PDP 图或 M 图,解释该方法背后的动机更困难 |
| 作为黑箱算法非常通用 | 需要访问训练数据集 |
| 不会像 PD 图那样在基础特征中挣扎于依赖性 | 分类变量的 ALE 定义不明确 |
| ALE 图计算速度快 |
1.3.3 部分依赖
Alibi 提供部分依赖(PD)图作为 ALE 的替代方案。
优缺点
| 优点 | 缺点 |
|---|---|
| PD 图易于可视化并直观理解(比 ALE 更容易) | 在基础特征中挣扎于依赖性。在不相关的情况下,解释可能不明确。 |
| 作为黑箱算法非常通用 | 可能隐藏异质效应(ICE 来拯救)。 |
| PD 图通常计算速度快。对于基于 scikit-learn 的树模型更快的实现 | |
| PD 图具有因果解释。该关系对模型是因果的,但不一定对现实世界是因果的 | |
| 对分类特征的自然扩展 |
1.3.4 部分依赖方差
Alibi 提供部分依赖方差作为一种方式,以全局衡量特征重要性及特征对之间的交互强度。由于该方法基于部分依赖,因此从业者应注意该方法继承的主要限制(请参见上述讨论)。
优缺点
| 优点 | 缺点 |
|---|---|
| 对特征重要性的计算具有直观的动机 | 特征重要性仅捕获主要效应,忽略可能的特征交互 |
| 作为黑箱算法非常通用 | 即使存在特征交互,也可能无法检测到 |
| 一般计算速度快。对于基于 scikit-learn 的树模型更快的实现 | |
| 提供标准化程序来量化特征重要性(即,与某些树模型的内部特征重要性形成对比) | |
| 支持数值和分类特征 | |
| 可以量化潜在的交互效应的强度 |
1.3.5 排列重要性
Alibi 提供排列重要性作为一种全局特征重要性度量方式。特征重要性的计算基于当特征列中的特征值被打乱时模型性能下降的程度。实践者应注意的一个重要行为是,相关特征的重要性可能在它们之间分配。
优缺点
| 优点 | 缺点 |
|---|---|
| 解释简单明了——特征重要性是当特征变为噪声时模型损失/分数的增加/减少。 | 需要真实标签 |
| 作为黑箱算法非常通用 | 可能对不现实的数据实例产生偏见 |
| 特征重要性考虑所有特征交互 | 重要性度量与损失/分数函数相关 |
| 不需要重新训练模型 |
1.3.6 局部必要特征
局部必要特征告诉我们,为了使模型给出相同的分类,特定实例的哪些特征需要保持不变。在训练好的图像分类模型的情况下,给定实例的局部必要特征将是模型用于做出决策的图像的最小子集。Alibi 提供两种计算局部必要特征的解释器:锚点和相关正例。
1.3.7 对比解释方法(相关正例)
相关正例是实例的特征子集,即使去掉这些特征,分类仍然保持不变。与锚点不同,它们的构建并不旨在最大化覆盖率。创建它们的方法也有很大不同。粗略的想法是定义特征的缺失,然后扰动实例,尽可能多地去除信息,同时保留原始分类。请注意,这些是 CEM 方法的子集,该方法也用于构造相关负例/反事实。
优缺点
| 优点 | 缺点 |
|---|---|
| 可以与白箱(TensorFlow)和某些黑箱模型一起使用 | 找到要从实例中去除的非信息特征值通常并不简单,且需要领域知识 |
| 自编码器损失需要访问原始数据集 | |
| 需要调整超参数 ( betabetabeta ) 和 ( gammagammagamma ) | |
| 洞察并未告知我们相关正例的覆盖率 | |
| 对于黑箱模型,由于必须数值评估梯度,因此速度较慢 | |
| 仅适用于可微的黑箱模型 |
1.3.8 局部特征归因LFA
局部特征归因(LFA)询问在给定实例中每个特征对其预测的贡献。在图像的情况下,这将突出显示对模型预测最负责任的像素。请注意,这与局部必要特征略有不同,后者寻找保持相同预测所需的最小特征子集。局部特征归因则给每个特征分配一个分数。
局部特征归因的一个良好示例是检测图像分类器是否关注图像的正确特征以推断类别。在他们的论文《我为什么应该信任你?:解释任何分类器的预测》中,Marco Tulio Ribeiro 等人对一小部分狼和哈士奇图像数据集训练了一个逻辑回归分类器。该数据集经过精心挑选,以便只有狼的图片有雪地背景,而哈士奇则没有。LFA 方法揭示了哈士奇在雪地中的错误分类为狼的原因是网络错误地关注了那些有雪地背景的图像。
Alibi 提供四种解释器来计算 LFA:集成梯度、核SHAP、路径依赖树SHAP 和 干预树SHAP。
后面三种在 SHAP 库中实现,Alibi 作为包装器。
对于归因方法的相关性,我们期望属性在某些情况下表现一致。因此,它们应满足以下属性:
- 效率/完整性:归因之和应等于预测与基线之间的差异。
- 对称性:对模型有相同影响的变量应具有相等的归因。
- 虚拟/敏感性:不改变模型输出的变量应具有零归因。
- 可加性/线性:对两个模型的线性组合的特征归因应等于对每个模型的该特征归因的线性组合。
并非所有 LFA 方法都满足这些方法(例如 LIME),但 Alibi 提供的方法(集成梯度、核SHAP、路径依赖和干预树SHAP)都满足。
1.3.9 核SHAP
核SHAP 是计算模型在实例周围的 Shapley 值的方法。Shapley 值是一种博弈论方法,根据对整体目标的贡献分配奖励。在我们的案例中,特征就是玩家,奖励就是归因。
给定任何特征子集,我们可以询问特征在该集合中的存在如何影响模型输出。我们通过计算包含和不包含特定特征的集合的模型输出来做到这一点。通过考虑所有可能的特征子集的有无,获得该特征的 Shapley 值。
两个问题出现。大多数模型并不是训练为接受可变数量的输入特征。其次,考虑所有可能的缺失特征集合会导致考虑幂集,这在特征数量较多时是不可行的。
为了解决前者,我们从干预条件期望中进行采样。这将缺失特征替换为从训练分布中采样的值。为了解决后者,核SHAP 方法在子集空间上进行采样以获得估计。
Alibi 提供对 SHAP 库的包装器。我们可以使用此解释器计算 sklearn 随机森林模型的 Shapley 值,方法如下(请参见notebook):
from alibi.explainers import KernelShap# 黑箱模型
predict_fn = lambda x: rfc.predict_proba(scaler.transform(x))
explainer = KernelShap(predict_fn, task='classification')
explainer.fit(X_train[0:100])
result = explainer.explain(x)plot_importance(result.shap_values[1], features, 1)
这给出了以下输出:
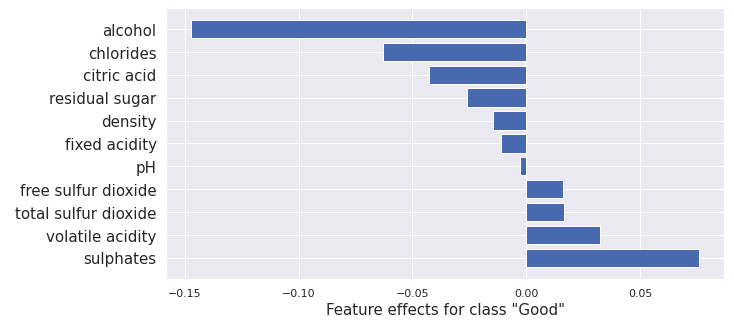
该结果与集成梯度的结果相似,尽管由于使用不同的方法和模型,二者之间存在差异。
优缺点
| 优点 | 缺点 |
|---|---|
| 满足多个期望属性 | 核SHAP 由于所需样本数量多而较慢 |
| Shapley 值易于解释和可视化 | 干预条件概率引入不现实的数据点 |
| 作为黑箱方法非常通用 | 需要访问训练数据集 |
1.3.10 路径依赖树SHAP
计算模型的 Shapley 值需要为每个实例特征的幂集计算干预条件期望。对于基于树的模型,我们可以通过通常应用树来近似此分布。然而,对于缺失特征,我们同时沿着树的两个路径进行处理,按训练数据集中经过每条路径的样本比例加权。
树 SHAP 方法同时为所有特征幂集的成员执行此操作,从而实现显著的加速。
使用 Alibi 计算随机森林的路径依赖树SHAP 解释器(请参见notebook),我们使用:
from alibi.explainers import TreeShap# rfc is a random forest model
path_dependent_explainer = TreeShap(rfc)
path_dependent_explainer.fit() # path dependent Tree SHAP doesn't need any dataresult = path_dependent_explainer.explain(scaler.transform(x)) # explain the scaled instance
plot_importance(result.shap_values[1], features, '"Good"')
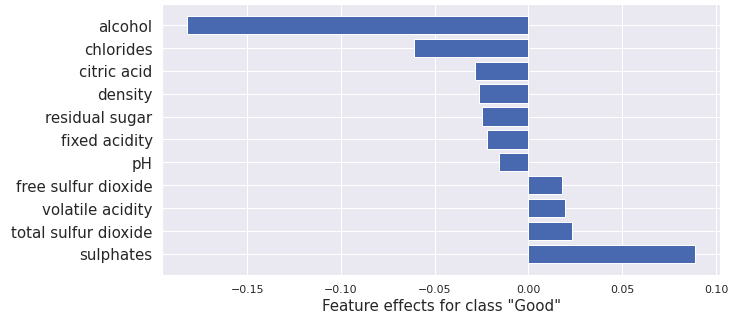
路径依赖树SHAP的输出通常与核SHAP和集成梯度的结果相似,但由于利用了树模型结构,计算效率更高。
优缺点
| 优点 | 缺点 |
|---|---|
| 计算速度快,适合基于树的模型 | 仅适用于基于树的模型 |
| 满足多个期望属性 | 需要访问模型内部结构 |
| 结果易于解释和可视化 | |
| 不需要训练数据集 |
1.3.11 干预树SHAP
干预树SHAP方法与路径依赖树SHAP类似,但它使用训练数据的干预分布来计算条件期望,而不是路径依赖的近似。这样可以更准确地反映特征之间的依赖关系。
Alibi同样支持干预树SHAP,使用方式与路径依赖树SHAP类似。
优缺点
| 优点 | 缺点 |
|---|---|
| 更准确地考虑特征之间的依赖 | 计算成本较高 |
| 结果易于解释和可视化 | 仅适用于基于树的模型 |
| 满足多个期望属性 | 需要训练数据集和模型内部结构 |
1.4 反事实实例(Counterfactual instances)
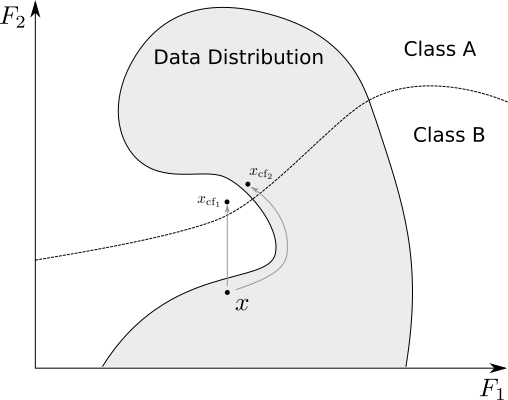
给定数据集中的一个实例和模型的预测,自然会产生一个问题:该实例需要发生怎样的最小改变,才能得到不同的预测结果?
这样的生成实例被称为反事实。
反事实解释属于局部解释,因为它们针对单个实例和模型预测。
例如,给定一个在 MNIST 数据集上训练的分类模型和一个数据样本,一个反事实可能是一个与原始图像非常相似但经过修改后被模型分类为不同数字的图像。

图片来源:Samoilescu RF 等人,《通过强化学习实现模型无关且可扩展的反事实解释》,2021年
反事实不仅可以用于调试模型,也可以增强模型功能。举例来说,假设一个模型基于表格数据对客户的财务决策做出判断,一个反事实可以告诉客户需要如何调整行为以获得不同的决策结果。
或者,它可以告诉机器学习工程师,如果推荐的改变涉及无关特征,则模型可能存在错误假设。但实践者仍需警惕偏差问题。
反事实 xcfx_{cf}xcf需要满足:
- 模型对 xcfx_{cf}xcf的预测应接近预定目标输出(例如,期望的类别标签)。
- 反事实 xcfx_{cf}xcf应具有可解释性。
第一个要求很明确,但第二个则需要对“可解释性”有一定定义。
Alibi 提供了四种寻找反事实的方法:
反事实实例(CFI)、对比解释方法(CEM)、基于原型的反事实(CFP)和基于强化学习的反事实(CFRL)。
这些方法对可解释性的定义略有不同,但都强调解的稀疏性,即希望仅改变少量特征,从而限制解决方案的复杂度,使其更易理解。
需要注意的是,仅仅稀疏的特征变化并不能保证生成的反事实看起来像数据分布中的真实样本。
CEM、CFP和CFRL方法还要求反事实必须符合数据分布,以保证其可解释性。
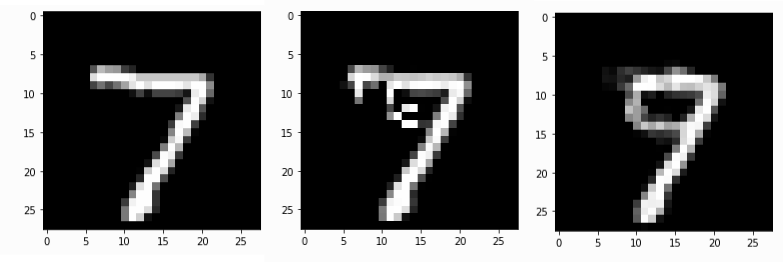
原始MNIST数字7实例,以及使用1)反事实实例方法和2)基于原型的反事实方法生成的反事实
前三种方法(CFI、CEM、CFP)构造反事实的方式非常相似:它们定义一个损失函数,鼓励生成既可解释又属于目标类别的反事实实例,然后通过梯度下降在特征空间中搜索满足条件的反事实。
主要差别在于,CEM和CFP方法还训练了自编码器来确保生成的反事实符合数据分布。
使用和不使用训练数据自编码器的梯度下降反事实生成过程
这三种方法实际只适用于单通道灰度图像,对于多通道图像效果不佳。若要获得多通道图像的高质量反事实,建议使用CFRL。
CFRL方法与上述三种方法不同,它通过强化学习训练一个模型(称为“actor”),该模型接收实例并生成反事实。
强化学习中,actor根据奖励函数学习采取行动;在这里,actor尝试生成被正确分类且符合数据分布且稀疏的反事实。训练过程不需要访问模型内部,只需通过采样获得预测结果。最终得到的模型可以实时生成满足约束的可解释反事实。
此外,CFRL支持在生成反事实时考虑约束条件(如不可变特征),这对于建议用户可执行的改变非常重要。例如,建议贷款申请者年龄变小显然不现实。
后续会着重研究这一个模块。
1.5 相似性解释(Similarity explanations)
| 解释器 | 范围 | 模型类型 | 任务类型 | 数据类型 | 用途 | 资源 |
|---|---|---|---|---|---|---|
| 相似性解释 | 局部 | 白箱 | 分类、回归 | 表格(数值、分类)、文本和图像 | 找出训练集中与待解释实例最相似的样本,用以解释模型的预测 | 文档, 论文 |
相似性解释是一种基于实例的解释方法,通过查找训练集中与测试实例最相似的数据点来解释模型对该测试实例的预测。该解释类型可以被理解为模型通过引用训练集中相似且具有相同预测的实例来“证明”其预测——例如,“我之所以将这张图片分类为‘金毛寻回犬’,是因为它与训练集中我也分类为‘金毛寻回犬’的图片最为相似。”

相似性解释说明模型为何将图像分类为‘金毛寻回犬’,因为训练集中最相似的实例也被归为‘金毛寻回犬’。