Monkey OCR简单介绍
前言
最近看论文看到一篇多模态大模型相关的,《MonkeyOCR: Document Parsing with a
Structure-Recognition-Relation Triplet Paradigm》是一种基于构造-识别-关系三元组范式的文档分析模型。
基本结构
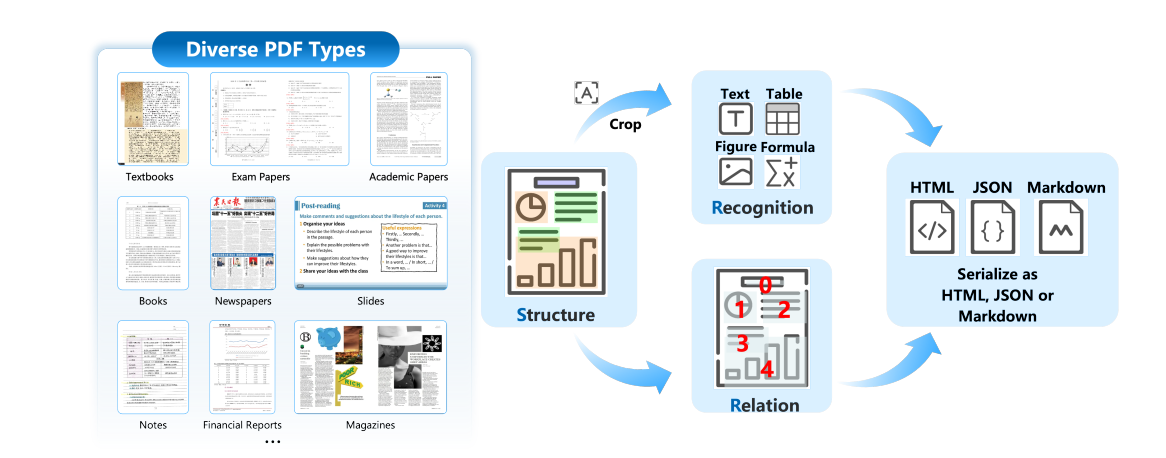
系统采用结构识别关系框架,包括结构检测,定位和分类语义区域;块级内容识别,并行提取每个区域的结构化信息;和关系预测,确定检测到的元素的逻辑阅读顺序。
实验效果
无论是得分还是推理速度还是杠杠的,优于不少当前的模型,并且模型可以在3090上推理。
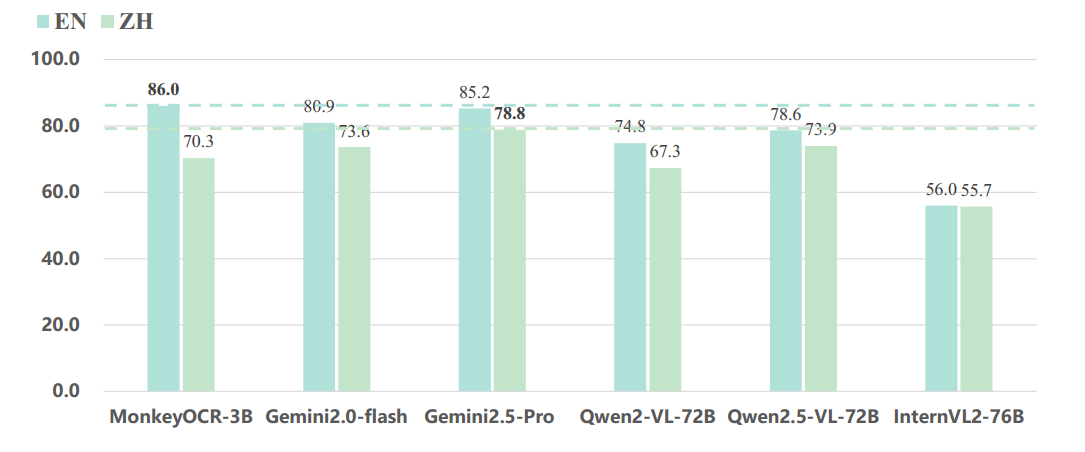
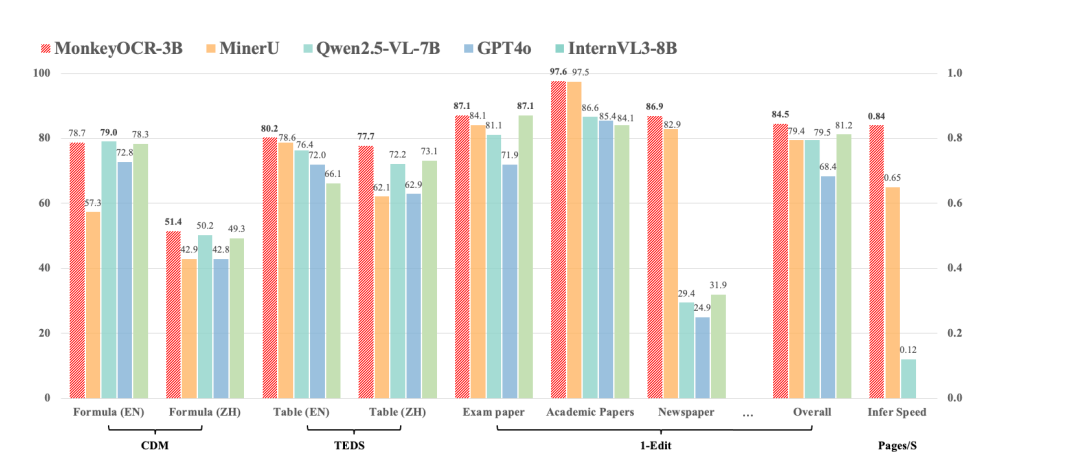
个人实验的效果
一个双栏13页的论文,一分钟OCR就将所有东西识别保存下来。
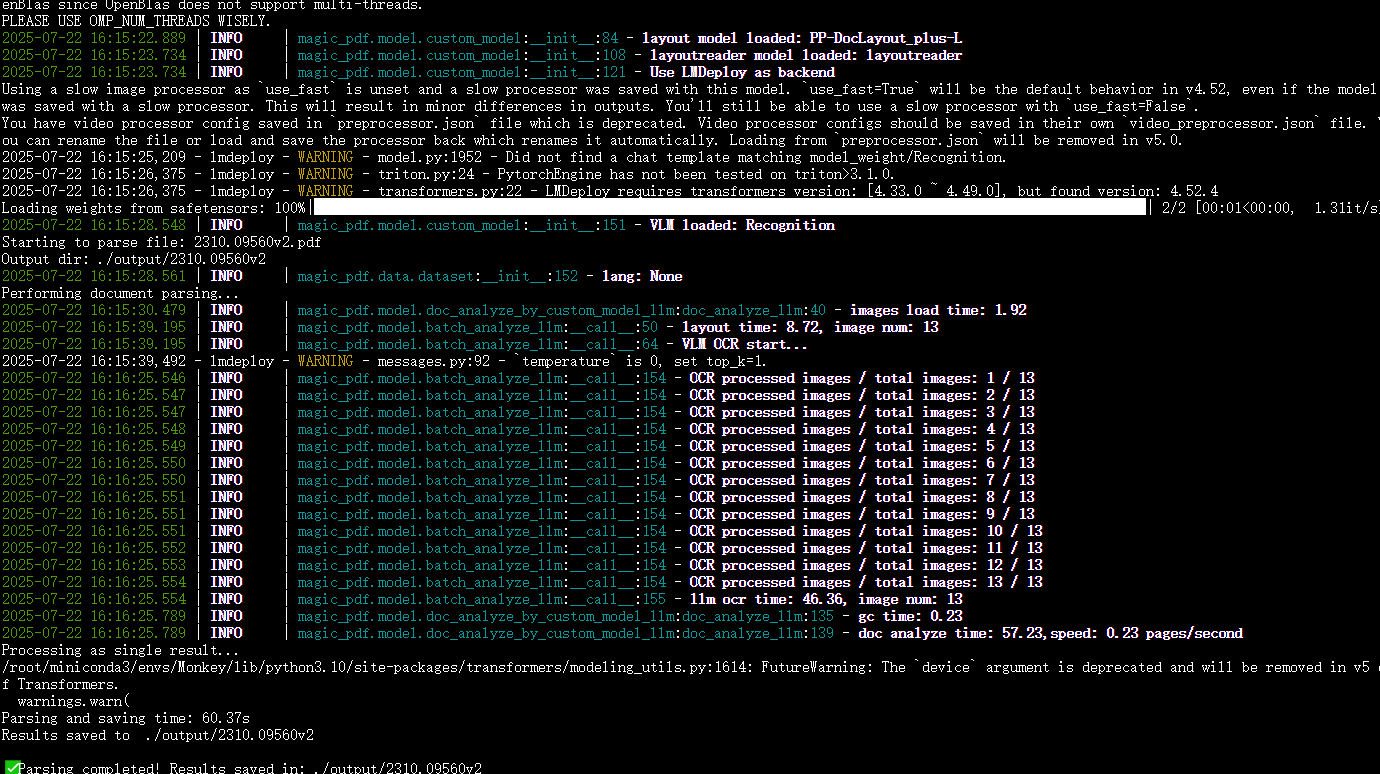
图片以及识别的内容均保存下来,并且公式可以以latex公式的出来
