【MySQL】MySQL基本概念
一、MySQL 基本概念
1.1 数据库
按照数据结构来组织、存储和管理数据的仓库;是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合
1.2 OLTP
- OLTP(On-Line transaction processing)翻译为联机事务处理;主要对数据库增删改查;
- OLTP 主要用来记录某类业务事件的发生;数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功;
1.3 OLAP
- OLAP(On-Line Analytical Processing)翻译为联机分析处理;主要对数据库查询;
- 当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做 OLAP 了;
1.4 SQL
- 结构化查询语言(Structured Query Language) 简称 SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
- SQL 是关系数据库系统的标准语言。
- 关系型数据库包括:MySQL, SQL Server, Oracle, Sybase,postgreSQL 以及 MS Access等;
- SQL 命令包括:DQL、DML、DDL、DCL以及TCL;
1.4.1 DQL
Data Query Language- 数据查询语言,对应着SQL语言中的select
1.4.2 DML
Data Manipulate Language- 数据操作语言,对应着SQL语言中的insert、update、delete
1.4.3 DDL
Data Define Language- 数据定义语言,对应着SQL语言中的create、alter、drop
1.4.4 DCL
Data Control Language- 数据控制语言,对应着SQL语言中的grant、revoke
1.4.5 TCL
Transaction Control language- 事务控制语言,对应着SQL语言中的commit、rollback
1.5 其他概念
- 数据库:数据库是一些关联表的集合;
- 数据表:表是数据的矩阵;
- 列:一列包含相同类型的数据;
- 行:或者称为记录是一组相关的数据;
- 主键:主键是唯一的;一个数据表只能包含一个主键;
- 外键:外键用来关联两个表,来保证参照完整性;MyISAM 存储引擎本身并不支持外键,只起到注释作用;而 innoDB 完整支持外键;
- 复合键:或称组合键;将多个列作为一个索引键;
- 索引:用于快速访问数据表的数据;索引是对表中的一列或者多列的值进行排序的一种结构;
二、MySQL 整体架构
MySQL 由以下几部分组成:
- 连接池组件、管理服务和工具组件、SQL 接口组件、查询分析器组件、优化器组件、缓冲组件、插件式存储引擎、物理文件。
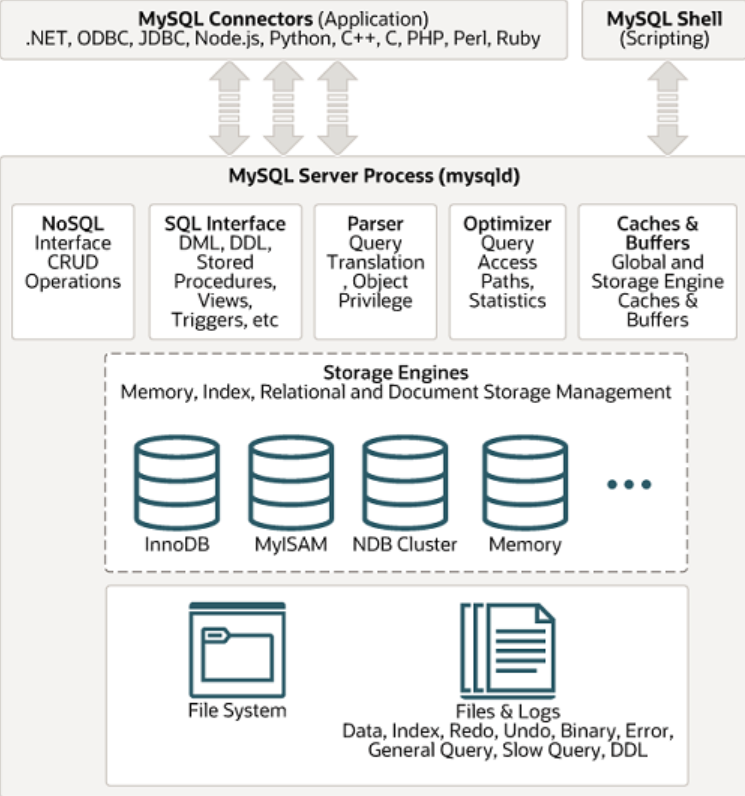
2.1 连接者
不同语言的代码程序和 MySQL 的交互(SQL交互)
2.2 MySQL内部连接池
- 管理缓冲用户连接、用户名、密码、权限校验、线程处理等需要缓存的需求;
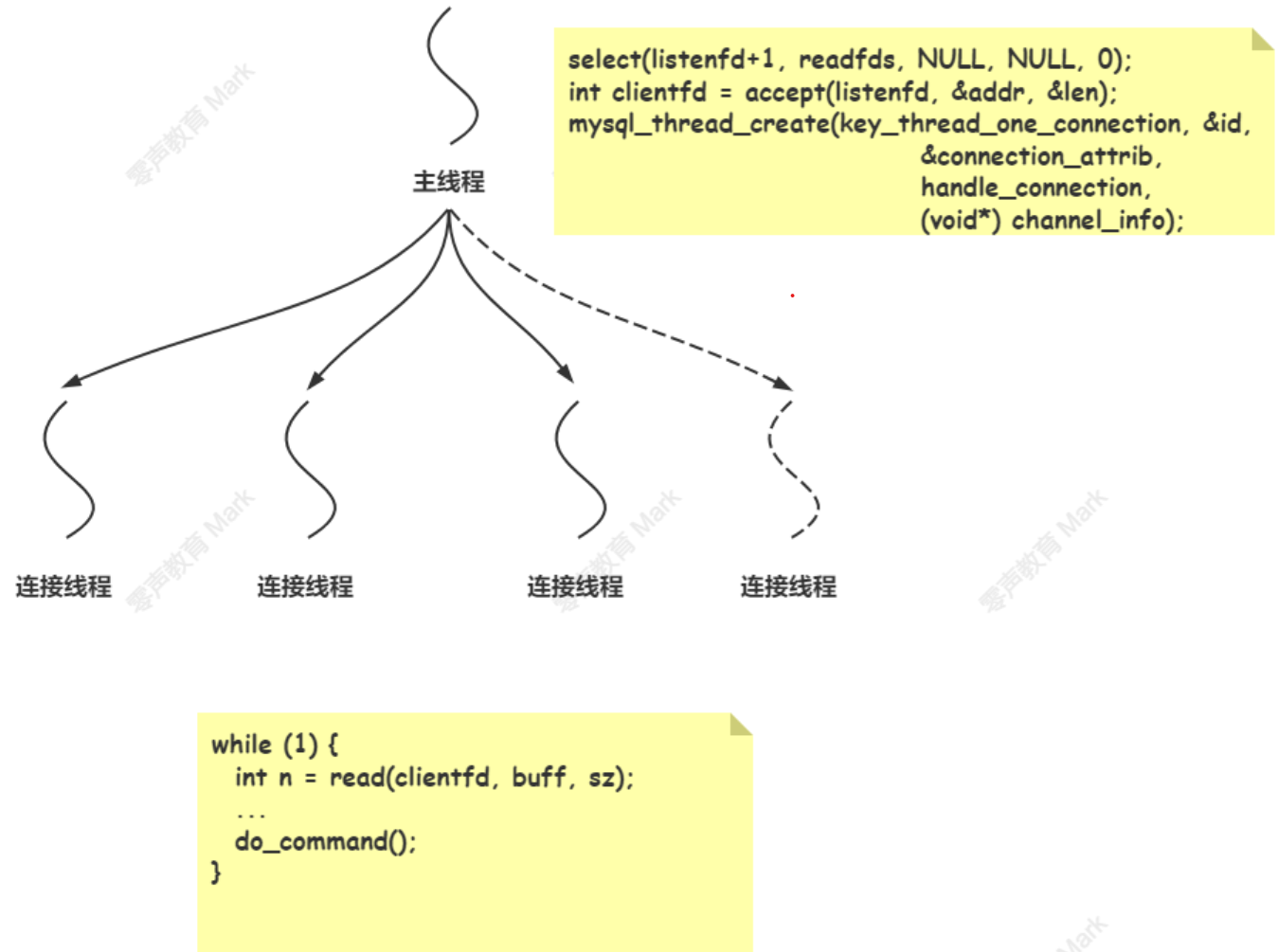
- 网络处理流程:主线程接收连接,接收连接交由连接池处理;
- 主要处理方式:IO多路复用 select + 阻塞的 io;
MySQL 命令处理是多线程并发处理的,主线程负责接收客户端连接,然后为每个客户端 fd 分配一个连接线程,负责处理该客户端的 sql 命令处理;
2.3 管理服务和工具组件
系统管理和控制工具,例如备份恢复、MySQL 复制、集群等;
2.4 SQL接口
将 SQL 语句解析生成相应对象;DML,DDL,存储过程,视图,触发器等;
2.5 查询解析器
将 SQL 对象交由解析器验证和解析,并生成语法树;
2.6 查询优化器
SQL 语句执行前使用查询优化器进行优化;
2.7 缓冲组件
-
是一块内存区域,用来弥补磁盘速度较慢对数据库性能的影响;
-
在数据库进行读取页操作,首先将从磁盘读到的页存放在缓冲池中,下一次再读相同的页时,首先判断该页是否在缓冲池中,若在缓冲池命中,直接读取;否则读取磁盘中的页,说明该页被 LRU 淘汰了;缓冲池中 LRU 采用最近最少使用算法来进行管理;
-
缓冲池缓存的数据类型有:索引页、数据页、以及与存储引擎缓存相关的数据(比如innoDB 引擎:undo 页、插入缓冲、自适应 hash 索引、innoDB 相关锁信息、数据字典信息等);
三、数据库设计三范式
-
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则,在关系型数据库中这种规则就称为范式。
-
范式是符合某一种设计要求的总结,要想设计一个结构合理的关系型数据库,必须满足一定的范式。
3.1 范式一
确保每列保持原子性;数据库表中的所有字段都是不可分解的原子值
- 例如:某表中有一个地址字段,如果经常需要访问地址字段中的城市属性,则需要将该字段拆分为多个字段,省份、城市、详细地址等;
3.2 范式二
确保表中的每列都和主键相关,而不能只与主键的某一部分相关(组合索引);
-
假设我们有一个 “学生选课” 表,存储学生选课后的成绩,设计如下:
- 组合主键:(学生 ID,课程 ID)(因为一个学生可以选多门课,一门课有多个学生选,只有两者结合才能唯一确定一条选课记录)
- 其他列:学生姓名、课程名称、成绩
-
问题分析:
- “成绩” 列:依赖整个组合主键(学生 ID + 课程 ID)—— 正确。因为一个学生的某门课成绩,必须由 “哪个学生” 和 “哪门课” 共同确定。
- “学生姓名” 列:只依赖组合主键中的 “学生 ID”(只要知道学生 ID,就能确定姓名)—— 错误。这就是 “只与主键的某一部分相关”。
- “课程名称” 列:只依赖组合主键中的 “课程 ID”—— 错误。同样属于 “只依赖主键的一部分”。
-
这样的设计会导致数据冗余和更新异常:
- 冗余:同一个学生选 10 门课,“学生姓名” 会重复存储 10 次;
- 更新异常:如果学生改名字,需要修改所有包含该学生的选课记录,容易遗漏或出错。
-
正确的设计:
- “学生选课” 表:仅保留(学生 ID,课程 ID,成绩)—— 成绩完全依赖组合主键;
- 新增 “学生” 表:(学生 ID,学生姓名)—— 姓名依赖单一主键 “学生 ID”;
- 新增 “课程” 表:(课程 ID,课程名称)—— 课程名称依赖单一主键 “课程 ID”。
这样,每个表的非主键列都完全依赖于自身表的主键(单一主键或组合主键的全部),避免了部分依赖问题
3.3 范式三
确保每列都和主键直接相关,而不是间接相关;减少数据冗余;
-
假设有一个 “学生信息表”:
- 主键:学生 ID
- 其他列:姓名、班级 ID、班级名称、班主任
-
这里的问题在于:
- “班级名称” 和 “班主任” 并不直接依赖于 “学生 ID”,而是依赖于 “班级 ID”(先通过学生 ID 找到班级 ID,再通过班级 ID 找到班级名称)。
- 这就是 “间接依赖”(传递依赖:学生 ID → 班级 ID → 班级名称)。
-
改进方案:
- 学生表:保留(学生 ID,姓名,班级 ID)—— 所有列直接依赖学生 ID;
- 班级表:新增(班级 ID,班级名称,班主任)—— 所有列直接依赖班级 ID。
这样,每列都只直接依赖于所在表的主键,消除了传递依赖。
3.4 反范式
-
范式可以避免数据冗余,减少数据库的空间,减小维护数据完整性的麻烦;
-
但是采用数据库范式化设计,可能导致数据库业务涉及的表变多,并且造成更多的联表查询,将导致整个系统的性能降低;因此基于性能考虑,可能需要进行反范式设计;
更多资料:https://github.com/0voice