LSTM+Transformer炸裂创新 精准度至95.65%
探索深度学习的新境界LSTM与Transformer的融合创新 在深度学习的广阔天地中,LSTM与Transformer的结合如同一场科技的盛宴,它们各自的优势在这一融合中得到了完美的展现。
LSTM以其在时序数据分析上的卓越表现而闻名,而Transformer则以其在捕捉长距离依赖关系上的非凡能力著称。这种创新的结合,不仅在学术界引起了轰动,更在工业界掀起了一场技术革命。
这种混合模型的诞生,标志着我们在文本生成、机器翻译、时间序列预测等领域取得了前所未有的成就。它的出现,不仅极大提升了模型的预测精度,还显著优化了性能和训练效率,使得序列分析任务变得更加高效和准确。 为了进一步推动这一领域的研究,精心挑选了过去两年内发表的17篇顶尖论文,这些论文代表了LSTM与Transformer融合技术的最新研究成果。
每一篇论文都是该领域的精华,不仅包含了论文的全文,还提供了发表的期刊信息和相关代码资源,为研究人员和实践者提供了宝贵的参考和灵感。 深入探索这一领域的最新进展,激发新的研究思路,推动深度学习技术的发展。我给大家准备了10种创新思路和源码,一起来看有需要的搜索人人人人人人人工重号(AI科技探寻)免费领取
论文1
标题:
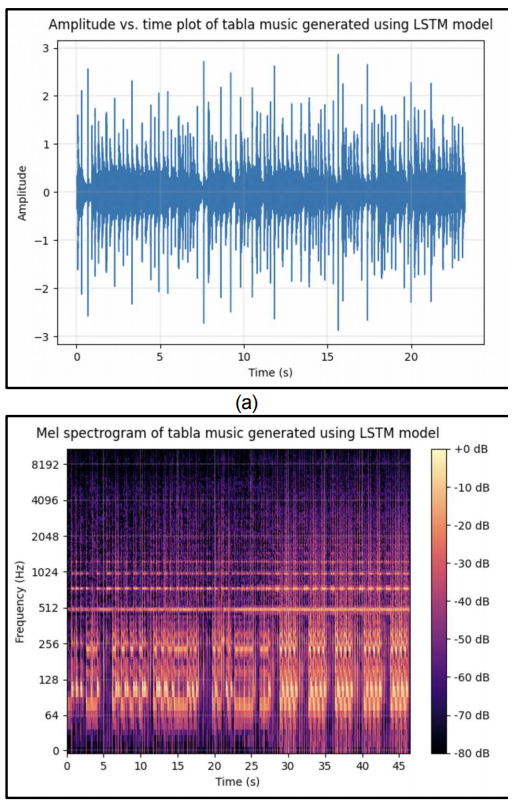
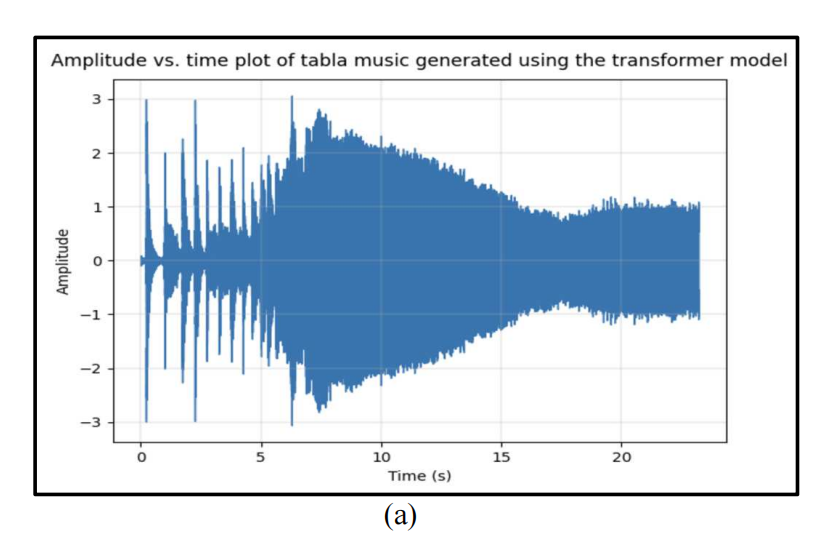
A Novel Bi-LSTM And Transformer Architecture For Generating Tabla Music
一种新颖的 Bi-LSTM 和 Transformer 架构用于生成印度鼓(Tabla)音乐
方法:
Bi-LSTM + Attention 模型:使用双向长短期记忆网络(Bi-LSTM)结合注意力机制,通过编码器-解码器架构捕捉音乐序列中的双向依赖关系。
Transformer 模型:引入 Transformer 架构,利用多头自注意力机制处理音乐序列,能够捕捉长距离依赖关系。
特征提取:使用 Python 的
librosa库对音频数据进行预处理,提取音频的时域信号、短时傅里叶变换(STFT)以及梅尔频谱图等特征。训练与优化:采用均方误差(MSE)和平均绝对误差(MAE)作为损失函数,使用 Adam 优化器进行训练。
创新点:
Bi-LSTM + Attention 模型:通过引入注意力机制,显著提高了音乐生成的质量,最终的均方误差为 4.042,平均绝对误差为 1.0814。
Transformer 模型:首次将 Transformer 架构应用于印度鼓音乐生成,尽管在生成效果上略逊于 Bi-LSTM 模型,但仍然能够生成具有节奏感的音乐序列,均方误差为 55.9278,平均绝对误差为 3.5173。
跨文化音乐生成:将深度学习技术应用于印度古典音乐生成,填补了该领域的研究空白,为跨文化音乐生成提供了新的思路。
论文2
标题:
Ball Trajectory Inference from Multi-Agent Sports Contexts Using Set Transformer and Hierarchical Bi-LSTM
基于集合变换器和层次化双向 LSTM 的多智能体运动场景中的球轨迹推断
方法:
集合变换器(Set Transformer):用于建模多智能体场景中的排列不变性和等变性,能够处理玩家轨迹的排列问题。
层次化双向 LSTM(Hierarchical Bi-LSTM):通过层次化架构,首先预测球员的球权,然后基于此预测最终的球轨迹。
现实损失(Reality Loss):引入现实损失项,确保预测的球轨迹在物理上是合理的,只有在球员触球时才会改变方向。
后处理算法:通过基于规则的后处理算法,进一步调整预测的球轨迹,使其更加符合实际比赛情况。
创新点:
集合变换器的应用:首次将集合变换器应用于球轨迹推断任务,能够有效处理多智能体场景中的排列问题,提高了模型的泛化能力。
层次化架构:通过引入层次化架构,先预测球员的球权,再预测球轨迹,显著提高了预测的准确性和现实性。最终的平均位置误差小于 37 米,球权预测准确率为 64.7%。
现实损失项:通过引入现实损失项,确保预测的球轨迹在物理上是合理的,减少了不合理的轨迹变化,提高了模型的实用性。
后处理算法:通过后处理算法,进一步优化了预测的球轨迹,使其更加符合实际比赛情况,为后续的事件检测和分析提供了更准确的数据。
论文3
标题:
DepGraph: Towards Any Structural Pruning
DepGraph:迈向任意结构剪枝
方法:
依赖图(Dependency Graph):提出了一种通用的依赖图方法,用于显式建模神经网络层之间的依赖关系,从而实现任意架构的结构化剪枝。
分层剪枝(Group-level Pruning):通过依赖图,将耦合的层分组为一个整体进行剪枝,确保剪枝后的网络结构仍然保持一致性和有效性。
稀疏训练(Sparse Training):引入稀疏训练方法,通过正则化项强制参数在组内稀疏化,使得剪枝后的网络能够更好地保持性能。
多架构支持:在多种架构(CNN、Transformer、RNN、GNN)上验证了方法的有效性,展示了其广泛的适用性
创新点:
依赖图的提出:首次提出依赖图方法,能够自动建模和处理神经网络中复杂的层间依赖关系,显著提高了结构化剪枝的自动化程度和泛化能力。
组级剪枝:通过依赖图实现组级剪枝,确保剪枝后的网络在去除冗余参数的同时,保持了网络的结构完整性和性能。例如,在 ResNet-56 上,剪枝后的模型加速比达到 2.57 倍,准确率从 93.53% 提升到 93.77%。
稀疏训练的改进:通过稀疏训练方法,使得剪枝后的网络能够更好地保持性能,减少了剪枝对模型性能的影响。
多架构适用性:在多种架构上验证了方法的有效性,包括 CNN、Transformer、RNN 和 GNN,展示了其广泛的适用性和优越性。
论文4
标题:
Rewiring the Transformer with Depth-Wise LSTMs
用深度 LSTM 重写 Transformer
方法:
深度 LSTM(Depth-Wise LSTM):提出了一种深度 LSTM 方法,将 Transformer 层的输出视为时间序列的步骤,通过 LSTM 管理层间的信息聚合。
层归一化和前馈计算的整合:将 Transformer 层归一化和前馈计算整合到深度 LSTM 中,连接纯 Transformer 注意力层,替代了传统的残差连接。
编码器和解码器的连接:在编码器和解码器中分别引入深度 LSTM,通过 LSTM 单元连接多头注意力层的输出,提高了模型的收敛性和性能。
实验验证:在 WMT 14 英德/英法翻译任务和 OPUS-100 多语言翻译任务上验证了深度 LSTM 的有效性。
创新点
深度 LSTM 的引入:首次将深度 LSTM 引入 Transformer 架构,显著提高了模型的性能和收敛性。在 WMT 14 英德任务中,深度 LSTM 的 BLEU 分数从 27.55 提升到 28.53,英法任务从 39.54 提升到 40.10。
层间信息管理:通过深度 LSTM 的门控机制,能够更好地管理层间的信息聚合,避免了传统残差连接可能导致的梯度消失和爆炸问题。
参数效率:深度 LSTM 方法在减少参数数量的同时,仍然能够实现与传统 Transformer 相当甚至更好的性能。例如,在 12 层 Transformer 上,深度 LSTM 方法的参数数量为 70.25M,而传统 Transformer 为 111M。
多语言翻译任务:在 OPUS-100 多语言翻译任务中,深度 LSTM 方法平均 BLEU 分数提高了 2.57,显著提升了多语言翻译的性能。