LLaMA-Mesh:语言模型驱动的3D内容生成革命
一、项目定位
由清华大学与英伟达联合开源的突破性框架,首次实现大型语言模型(LLM)与3D网格生成的统一。通过纯文本指令生成高质量3D模型,同时保留自然语言对话能力,重塑数字内容创作范式。

二、核心技术突破
- 跨模态统一表示
- 文本化3D数据:将顶点坐标(
v x y z)与面定义(f v1 v2 v3)直接编码为纯文本序列,无缝集成至LLM词汇表,无需离散化或扩展标记器。 - 知识迁移高效性:复用预训练LLM(如LLaMA-3)中嵌入的空间知识(源自3D教程等文本资源),显著降低训练成本。
- 文本化3D数据:将顶点坐标(
- 双向理解与生成
- 支持文本→3D生成(如输入“设计一把现代风格椅子”输出网格)与3D→文本解析(模型可解释网格结构)。
- 实现对话式交互:用户通过自然语言实时调整模型输出(如“增加曲面细节”)。
三、关键优势
| 维度 | 表现 |
|---|---|
| 生成质量 | 拓扑结构媲美专业工具,支持同一提示生成多样变体 |
| 计算效率 | 端到端微调保持文本能力无损,推理资源需求低(如消费级GPU可部署) |
| 应用覆盖 | 游戏/VR(角色场景生成)、工业设计(快速原型迭代)、教育(概念可视化) |
四、行业意义
- 开创性验证:首次证明LLM可通过微调掌握复杂空间建模能力,为AI+3D创作开辟新路径。
- 开源生态:代码与模型已在GitHub 及Hugging Face 开源,推动技术普惠
特点
数据表示统一
-
文本与 3D 网格统一:将 3D 网格的顶点坐标和面部定义的数值表示为纯文本,使得文本和 3D 网格能够在一种统一的格式中进行处理。这种统一的表示方式为模型的训练和推理带来了便利,使得模型可以同时处理文本和 3D 网格数据。端到端训练
-
使用交错数据训练:模型采用文本和 3D 交错数据进行端到端的训练。这种训练方式使得模型能够学习到文本和 3D 网格之间的关联,从而更好地根据文本输入生成相应的 3D 网格,同时也能进行自然的文本交互。
-
灵活性和可扩展性
-
参数可调整:在推理过程中,用户可以调整一些参数来控制生成结果,如温度(Temperature)和最大新生成令牌数(Max new tokens)。温度参数可以控制生成的随机性,最大新生成令牌数可以控制生成结果的长度。
-
支持不同格式输出:虽然主要以 OBJ 格式输出 3D 网格,但可以通过代码中的转换函数将其转换为其他格式,如 GLB 格式,方便进行可视化展示。
-
集成现有技术
-
集成 Llama 3.1 技术:该模型集成了 Llama 3.1 技术,遵循 Llama 3.1 社区许可协议。借助 Llama 3.1 的强大语言处理能力,提升了模型在文本理解和生成方面的性能。
-
开源与易用性
-
开源代码和模型:项目开放了代码和模型权重,用户可以在 GitHub 上获取代码,在 Hugging Face 上下载模型权重。这使得研究人员和开发者可以方便地使用和扩展该模型。
-
提供示例和文档:代码库中提供了丰富的示例,如不同的文本提示示例,方便用户快速上手。同时,README 文件中详细介绍了项目的方法、推理步骤等信息,为用户提供了清晰的使用指南。
具体操作
1.星海官网已经部署了镜像(打开就能用)星海智算-GPU算力云平台 https://www.spacehpc.com/user/register?inviteCode=29460209
https://www.spacehpc.com/user/register?inviteCode=29460209
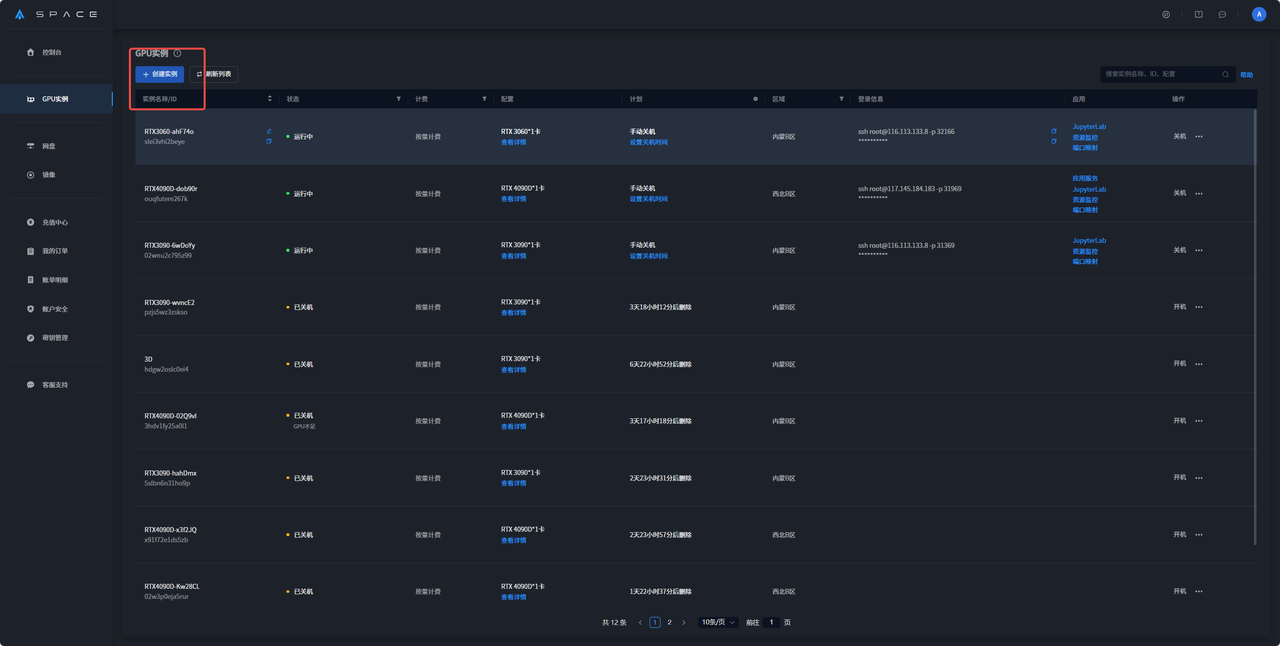
2. 在GPU实例界面中选择创建实例
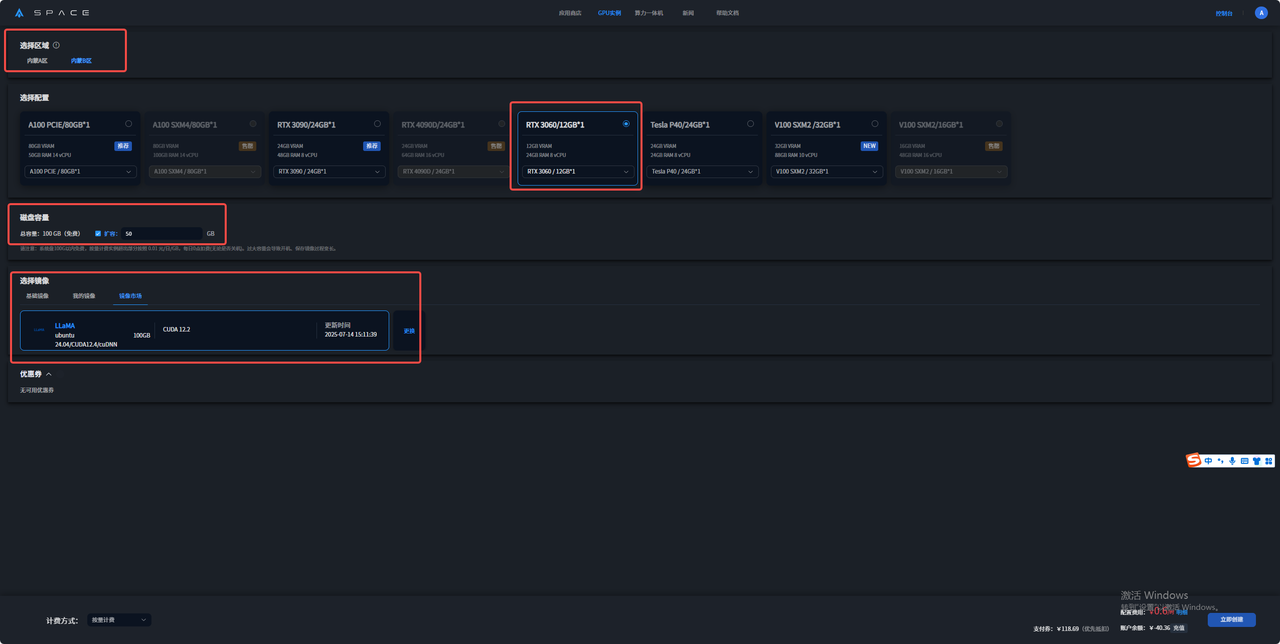
3.选择好所在区域、所需配置、计费方式后在镜像市场搜索LLaMA镜像
4.开机后等模型加载几分钟 点击应用服务
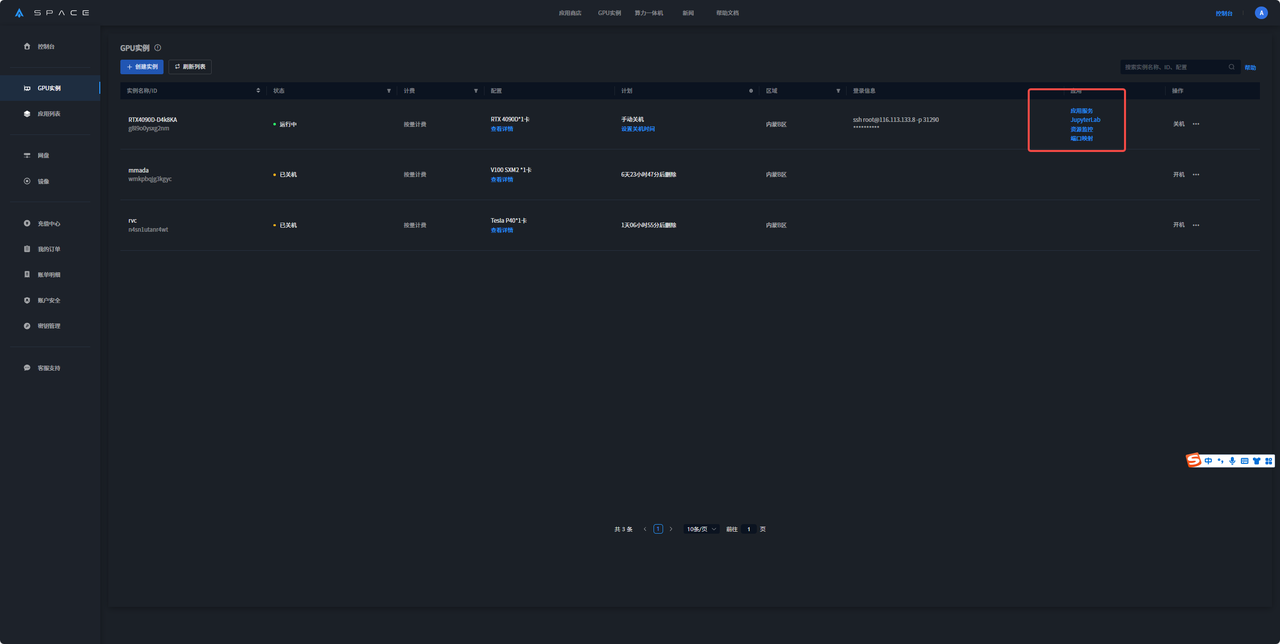
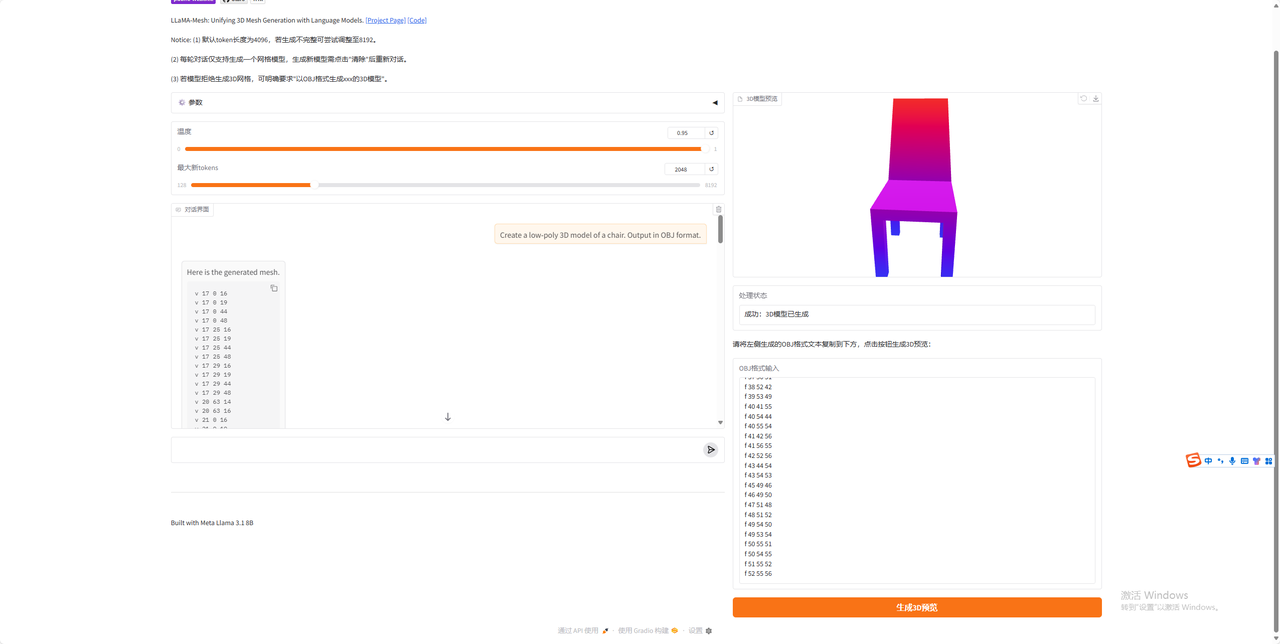
打开界面如下:
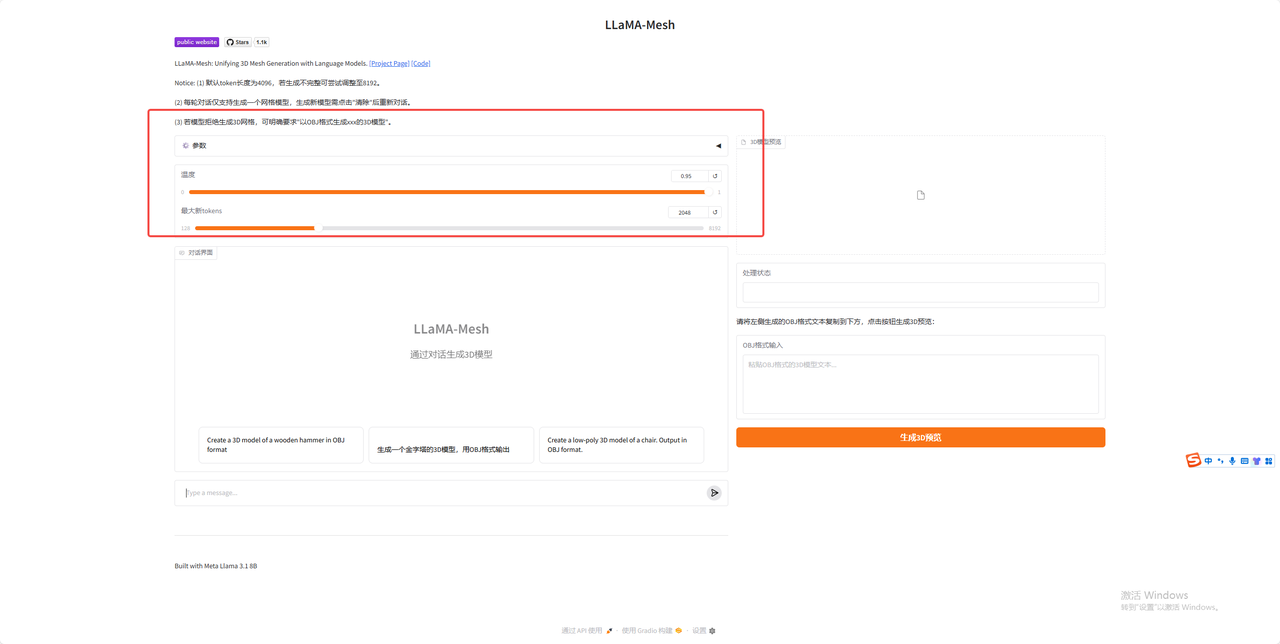
5.调整好参数
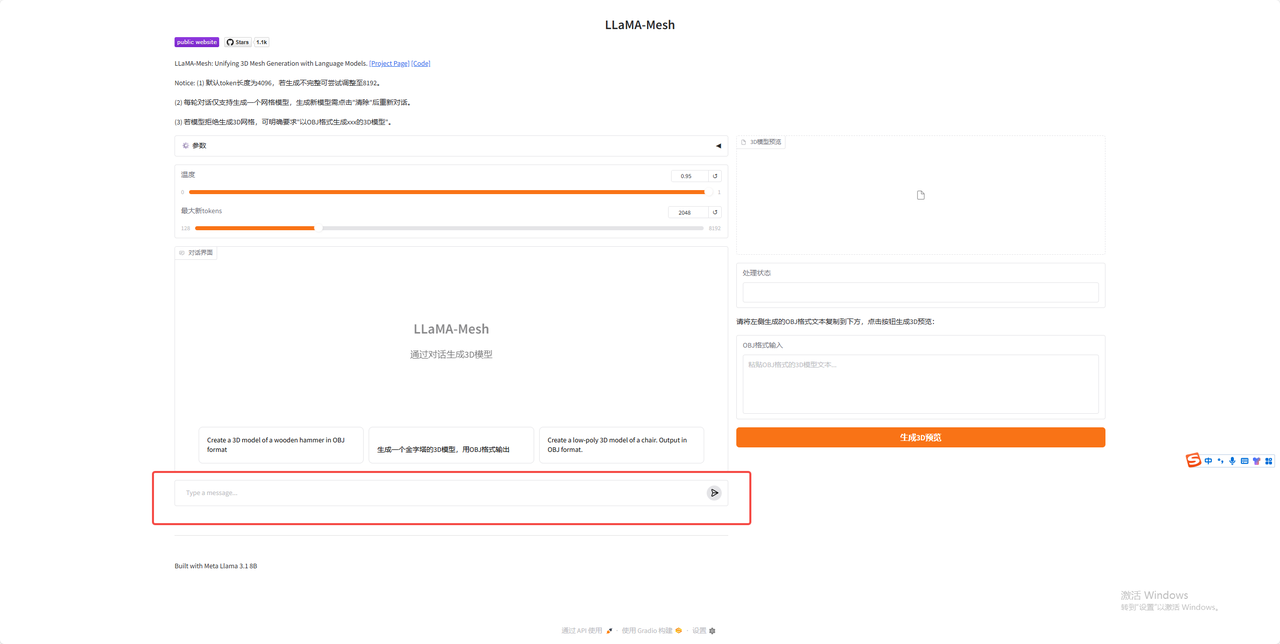
6.输入想要生成的模型(必须加上以obj格式生成)
7.黏贴生成的obj编码
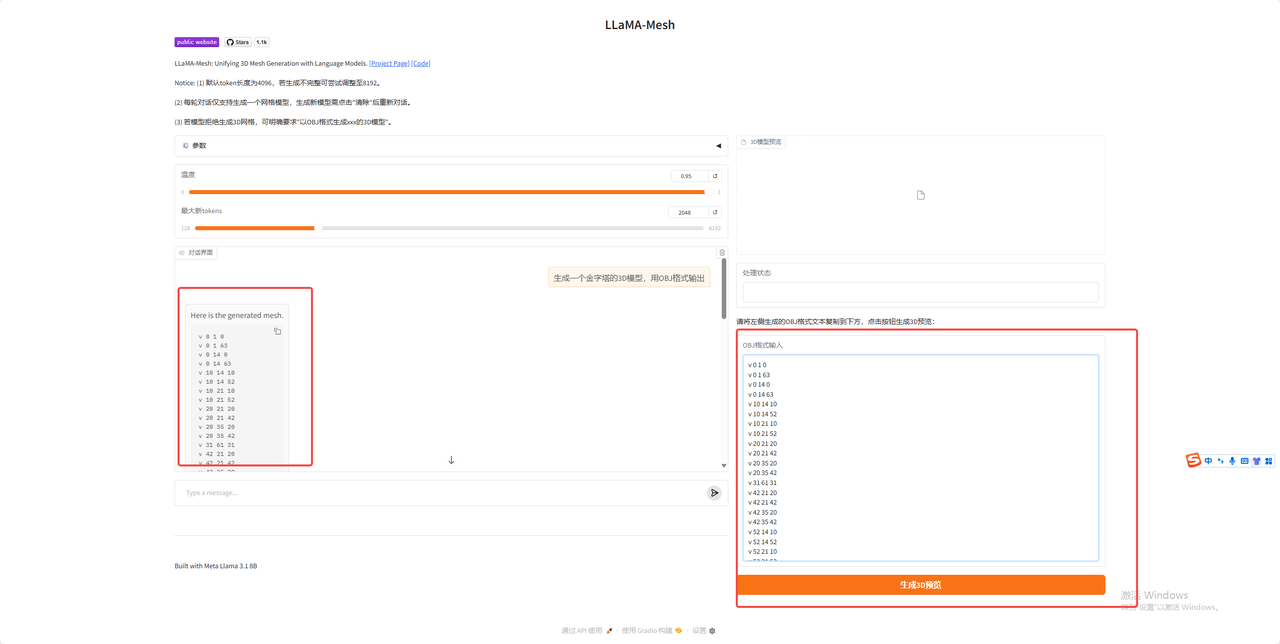
8.点击生成