PCIe之P2P应用
目录
3.1GPU Direct Storage
3.1.1 单机多卡GPU通信
1.GPUDirect Storage
2.GPUDirect P2P
3.1.2多机多卡GPU通信
1.RDMA
2.GPUDirect RDMA(GDR)
3.2PCIE交换P2P关键配置-ACS选项
3.2.1 使用ACS的原因
1.P2P传输风险
2.解决方案-ACS
测试场景及结果
3.1GPU Direct Storage
参考博客:聊透 GPU 通信技术——GPU Direct、NVLink、RDMA - 知乎
GPU Direct是NVIDIA开发的一项技术,利用PCIE交换实现GPU与其他设备(比如网络接口卡(NIC)和存储设备)之间的直接通信和数据传输,而不涉及CPU,从而减少不必要的内存和CPU开销,从而显著提升性能
该技术主要包括
3.1.1 单机多卡GPU通信
1.GPUDirect Storage
GPUDirect Storage 允许存储设备和 GPU 之间进行直接数据传输,绕过 CPU,减少数据传输的延迟和 CPU 开销。
通过 GPUDirect Storage,GPU 可以直接从存储设备(如固态硬盘(SSD)或非易失性内存扩展(NVMe)驱动器)访问数据,而无需将数据先复制到 CPU 的内存中。这种直接访问能够实现更快的数据传输速度,并更高效地利用 GPU 资源。
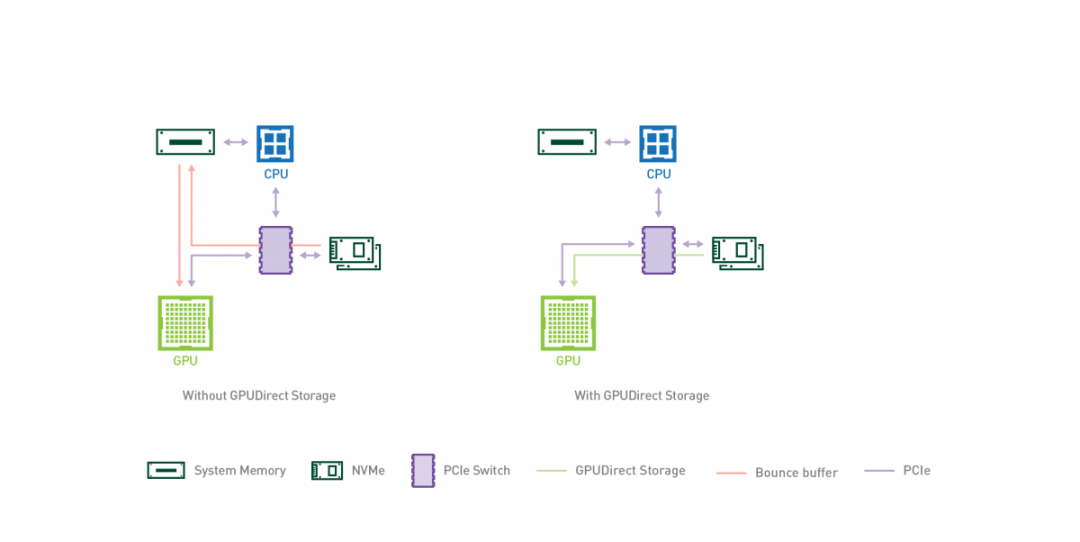
GPUDirect Storage 的主要特点和优势包括:
-
减少 CPU 参与:通过绕过 CPU,实现 GPU 和存储设备之间的直接通信,GPUDirect Storage 减少了 CPU 开销,并释放 CPU 资源用于其他任务,从而改善系统的整体性能。
-
低延迟数据访问:GPUDirect Storage 消除了数据通过 CPU 的传输路径,从而最小化了数据传输的延迟。这对于实时分析、机器学习和高性能计算等对延迟敏感的应用非常有益。
-
提高存储性能:通过允许 GPU 直接访问存储设备,GPUDirect Storage 实现了高速数据传输,可以显著提高存储性能,加速数据密集型工作负载的处理速度。
-
增强的可扩展性:GPUDirect Storage 支持多 GPU 配置,允许多个 GPU 同时访问存储设备。这种可扩展性对于需要大规模并行处理和数据分析的应用至关重要。
-
兼容性和生态系统支持:GPUDirect Storage 设计用于与各种存储协议兼容,包括 NVMe、NVMe over Fabrics和网络附加存储(NAS)。它得到了主要存储供应商的支持,并集成到流行的软件框架(如NVIDIA CUDA)中,以简化与现有的 GPU 加速应用程序的集成。
2.GPUDirect P2P
某些工作负载需要位于同一服务器中的两个或多个 GPU 之间进行数据交换,在没有 GPUDirect P2P 技术的情况下,来自 GPU 的数据将首先通过 CPU 和 PCIe 总线复制到主机固定的共享内存。然后,数据将通过 CPU 和 PCIe 总线从主机固定的共享内存复制到目标 GPU,数据在到达目的地之前需要被复制两次
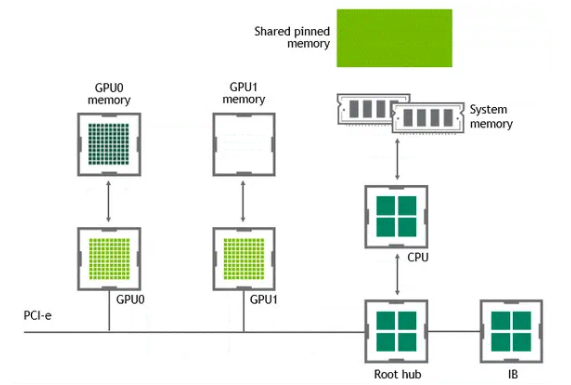
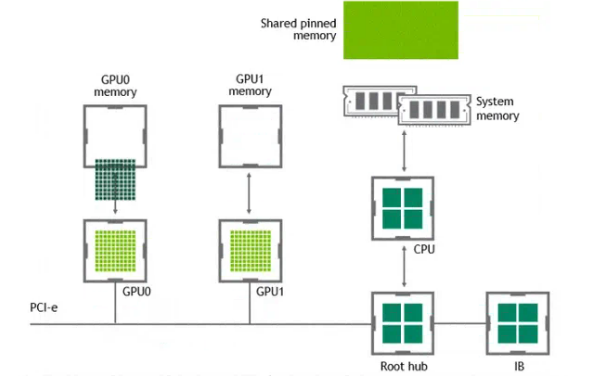
有了 GPUDirect P2P 通信技术后,将数据从源 GPU 复制到同一节点中的另一个 GPU 不再需要将数据临时暂存到主机内存中。如果两个 GPU 连接到同一 PCIe 总线,GPUDirect P2P 允许访问其相应的内存,而无需 CPU 参与。前者将执行相同任务所需的复制操作数量减半。
3.1.2多机多卡GPU通信
1.RDMA
AI 计算对算力需求巨大,多机多卡的计算是一个常态,多机间的通信是影响分布式训练的一个重要指标。在传统的 TCP/IP 网络通信中,数据发送方需要将数据进行多次内存拷贝,并经过一系列的网络协议的数据包处理工作;数据接收方在应用程序中处理数据前,也需要经过多次内存拷贝和一系列的网络协议的数据包处理工作。经过这一系列的内存拷贝、数据包处理以及网络传输延时等,服务器间的通信时延往往在毫秒级别,不能够满足多机多卡场景对于网络通信的需求。
RDMA(Remote Direct Memory Access)是一种绕过远程主机而访问其内存中数据的技术,解决网络传输中数据处理延迟而产生的一种远端内存直接访问技术。
目前 RDMA 有三种不同的技术实现方式:
-
InfiniBand(IB):IB 是一种高性能互连技术,它提供了原生的 RDMA 支持。IB 网络使用专用的 IB 适配器和交换机,通过 RDMA 操作实现节点之间的高速直接内存访问和数据传输。
-
RoCE(RDMA over Converged Ethernet):RoCE是在以太网上实现 RDMA 的技术。它使用标准的以太网作为底层传输介质,并通过使用 RoCE 适配器和适当的协议栈来实现 RDMA 功能。
-
iWARP:iWARP 是基于 TCP/IP 协议栈的 RDMA 实现。它使用普通的以太网适配器和标准的网络交换机,并通过在 TCP/IP 协议栈中实现 RDMA 功能来提供高性能的远程内存访问和数据传输。
2.GPUDirect RDMA(GDR)
GPUDirect RDMA 结合了 GPU 加速计算和 RDMA(Remote Direct Memory Access)技术,实现了在 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力。它允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介。
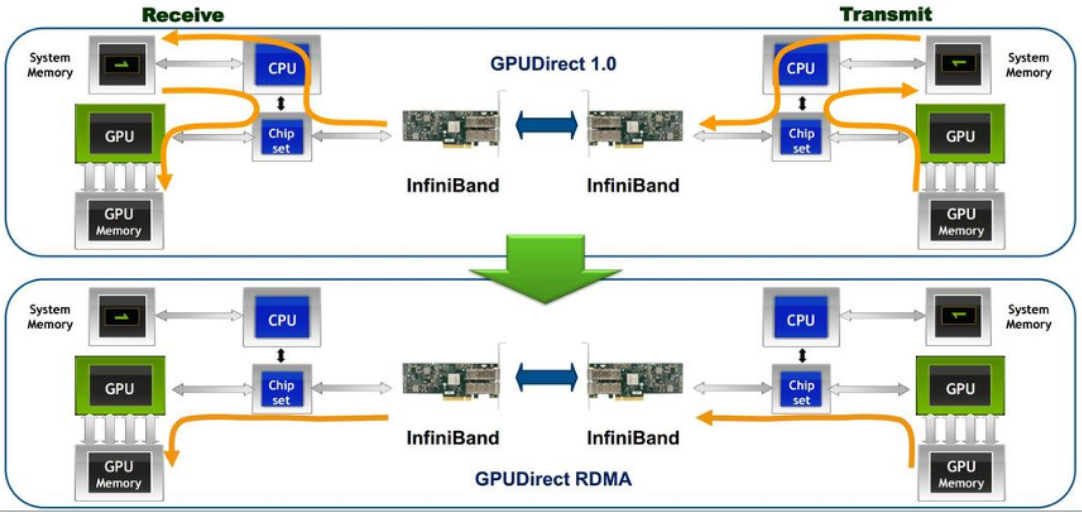
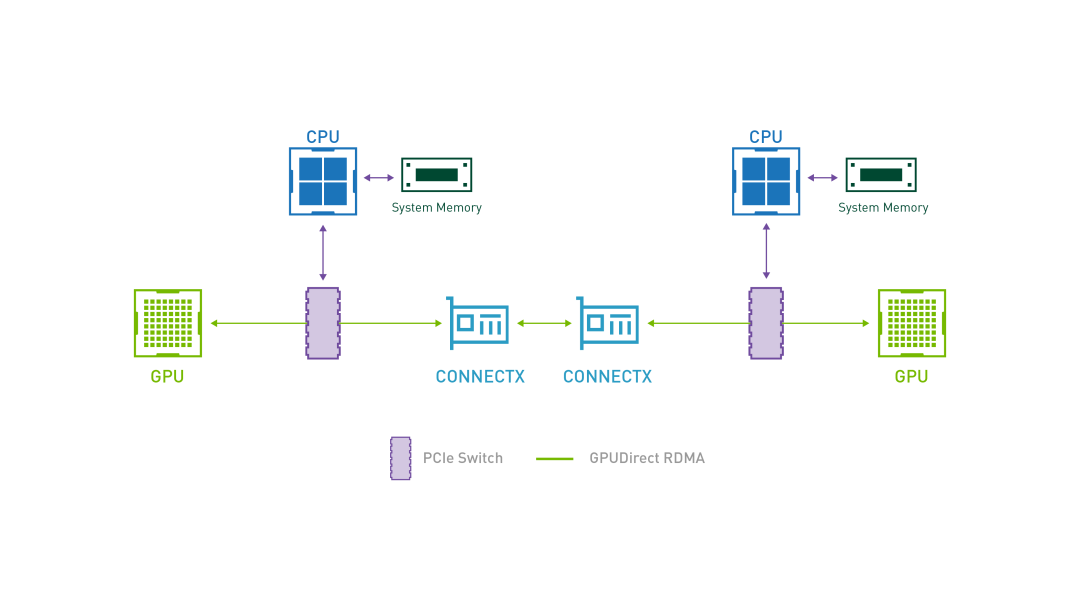
GPUDirect RDMA 通过绕过主机内存和 CPU,直接在 GPU 和 RDMA 网络设备之间进行数据传输,显著降低传输延迟,加快数据交换速度,并可以减轻 CPU 负载,释放 CPU 的计算能力。另外,GPUDirect RDMA 技术允许 GPU 直接访问 RDMA 网络设备中的数据,避免了数据在主机内存中的复制,提高了数据传输的带宽利用率
3.2PCIE交换P2P关键配置-ACS选项
参考博客:PCIe访问控制服务(ACS)_pcie acs-CSDN博客
3.2.1 使用ACS的原因
1.P2P传输风险
Access Control Services (ACS) 是一种基于信任的服务协议。如果EP端ATC(Address Translation Cache)声称其发出的访问请求是经过转换后的地址,并且该地址刚好落在PCIe交换开关的BAR范围内,则该访问请求不会到达RC,而是被交换开关路由到该地址所对应的EP。也就是说,该访问请求绕过了IOMMU的隔离,进行了P2P(peer to peer)传输
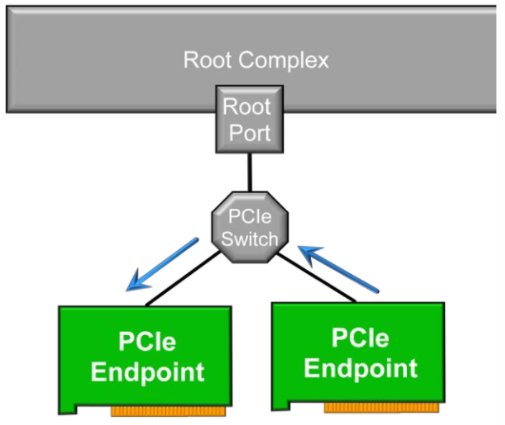
PCIe协议允许P2P传输,这就意味着同一个PCIe交换开关连接下不同EP可以在不流转RC的情况下互相通信。若使用过程中不希望P2P直接通信又不采取相关措施,那么这个漏洞可能被无意或者有意触发,使得某些EP收到无效、非法设置恶意的访问请求,从而引发一系列潜在问题
2.解决方案-ACS
ACS协议提供了一种机制,能够决定一个TLP被正常路由、阻塞或者重定向。在SR-IOV系统中,还能防止属于VI或者不同SI的设备Function之间直接通信。通过在交换节点上开启ACS服务,可以禁止P2P发送,强迫交换节点将所有地址的访问请求送到RC,从而避开P2P访问中的风险。ACS可以用于PCIe桥,交换节点以及带有VF的PF等所有具有调度功能的节点,充当一个看门人的角色。
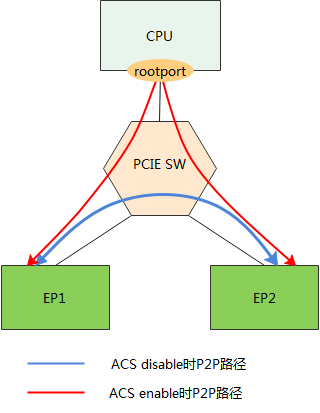
Access Control Services (ACS) :可以强制点对点PCIe事务经过root port转发,防止未经授权的P2P事务发生。
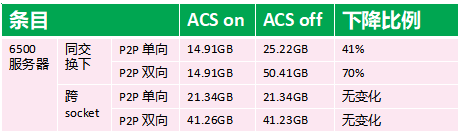
测试场景及结果
-
6500 服务器 - 同交 换下
-
P2P 单向:ACS 开启时带宽为 14.91GB,关闭时为 25.22GB,性能下降比例达 41% 。说明在同交换机环境下,P2P(Peer - to - Peer,点对点)单向传输时,ACS 功能开启对带宽影响明显。
-
P2P 双向:ACS 开启时带宽 14.91GB,关闭时 50.41GB,下降比例高达 70% 。表明此场景下,P2P 双向传输受 ACS 功能开启的影响更大。
-
-
6500 服务器 - 跨 socket
-
P2P 单向:ACS 开启和关闭时带宽均为 21.34GB,下降比例为无变化。意味着在跨 socket(处理器插槽)环境下,P2P 单向传输不受 ACS 功能开启与否的影响。
-
P2P 双向:ACS 开启时带宽 41.26GB,关闭时 41.23GB ,下降比例无变化。说明此场景下,P2P 双向传输也基本不受 ACS 功能开启的影响。
-