阿里云监控及运维常见问题
云监控介绍:
阿里云的云监控服务(CloudMonitor)是一款简单易用、功能强大的监控工具,主要用来帮助用户实时监控阿里 云上的各种资源(比如服务器、数据库、网络等),并在出现问题时及时发出警报,确保业务稳定运行。
1.打开阿里云,找到对应服务
点击立即开通
2.在控制台找到云监控服务
开通云主机监控策略
为需要监控的主机安装Agent,点击自动安装Agent
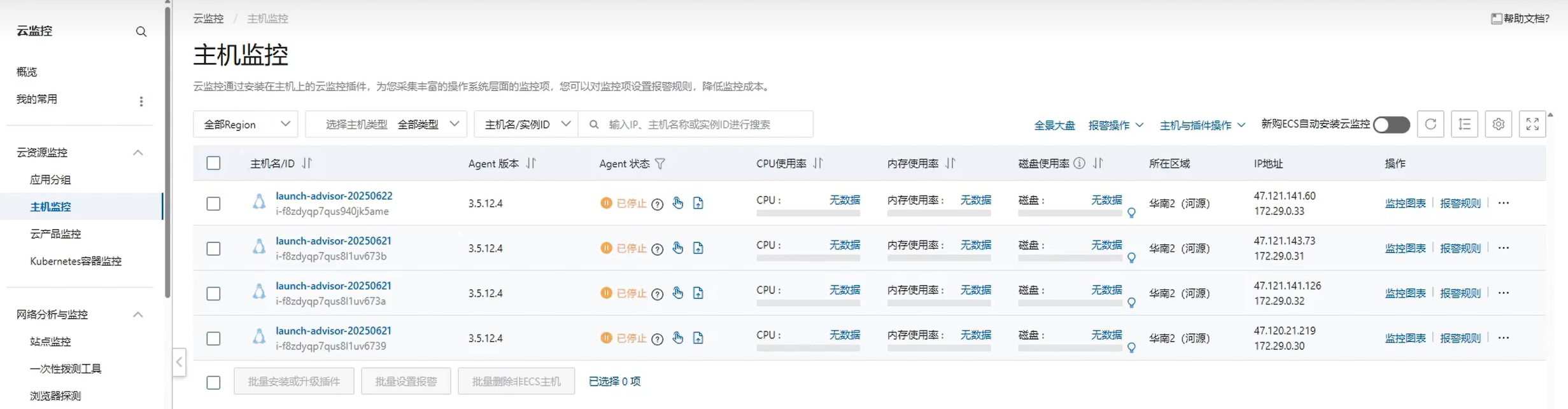
等待片刻, 重新刷新对应的CPU使用率、内存使用率、磁盘使用率的数据即可出现
系统报警服务配置
云监控中的报警服务规则配置的主要目的是帮助用户实时监控阿里云资源、线下IDC、其他云厂商产品或自定义监 控数据的运行状态,并在监控指标达到预设条件时,自动触发报警通知。通过这种方式,用户可以及时获取异常信息 并 快速采取措施,确保业务系统的稳定性和可靠性。
1:设置报警联系人
报警联系人: 当触发条件后,需要通知相关人员, 这些对应的人员信息需要提前录入
2:设置报警联系组
报警联系组:多个联系人合并为一个组, 不同的类型可以单独设置为组,告警的时候可以直接针对多个用户同时告警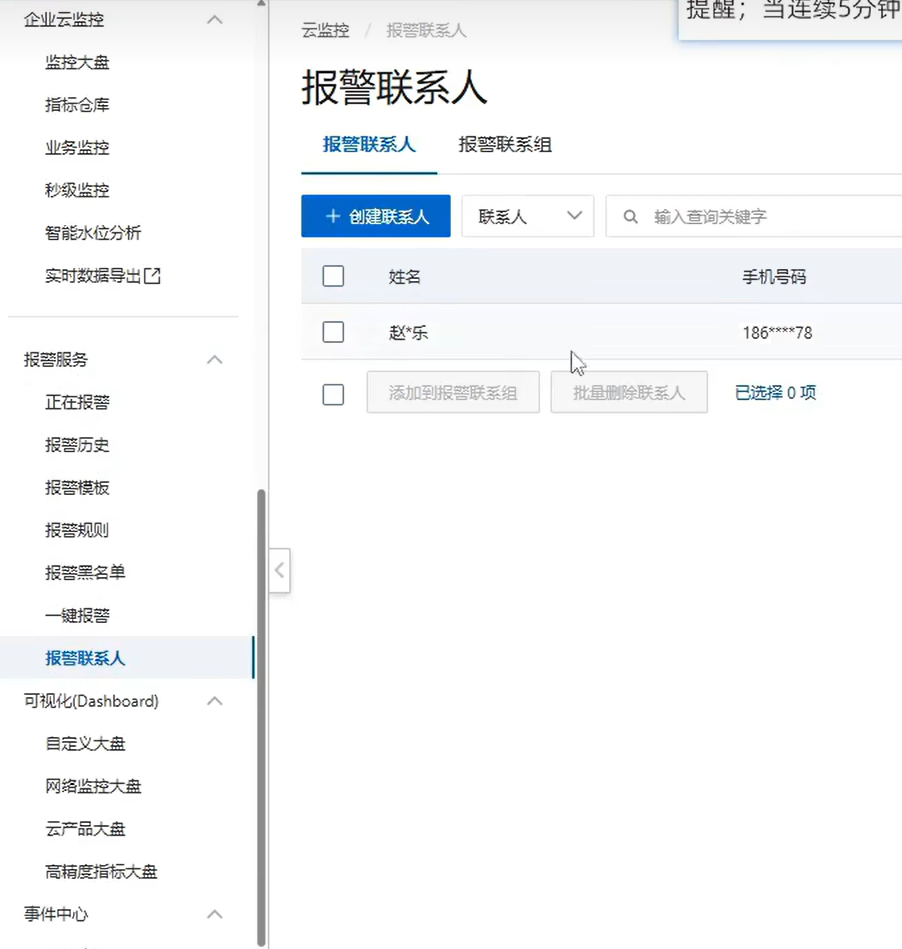
3:设置报警规则
报警规则:帮助用户监控运行状态,并在监控指标达到预设条件时,自动触发报警通知
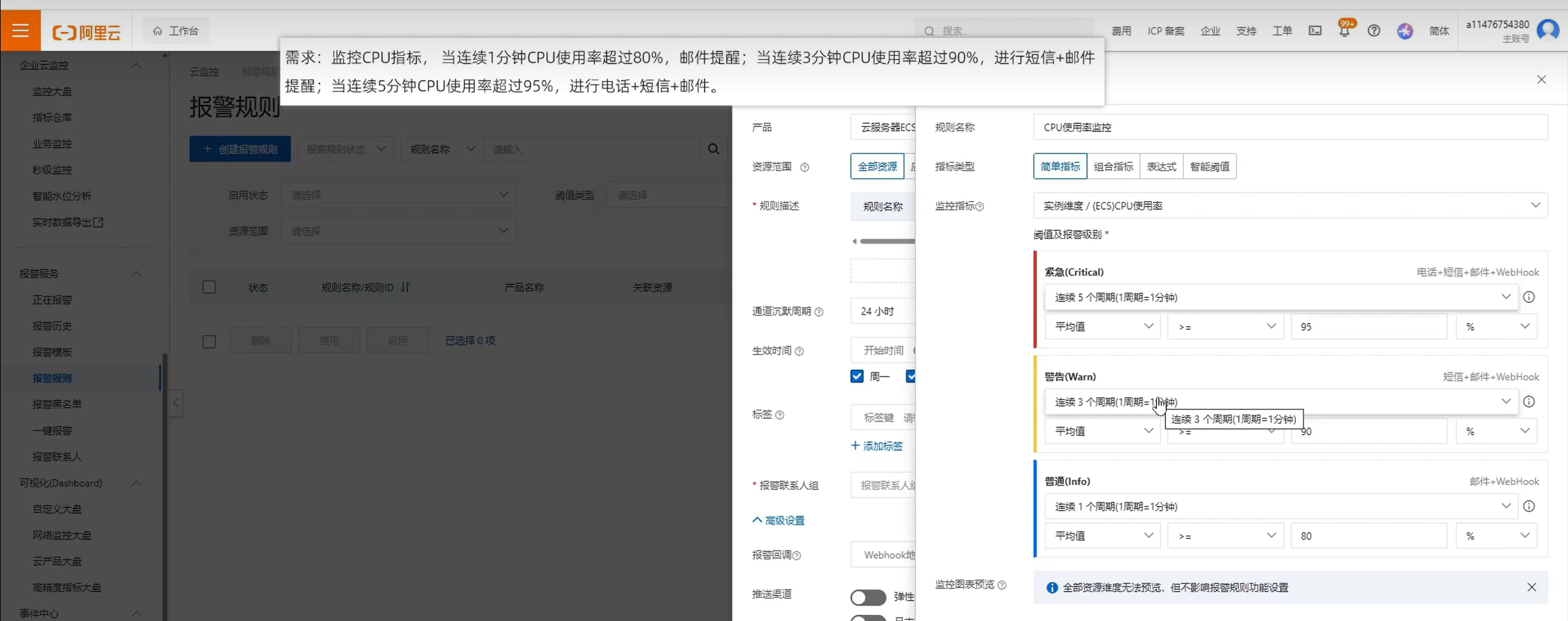
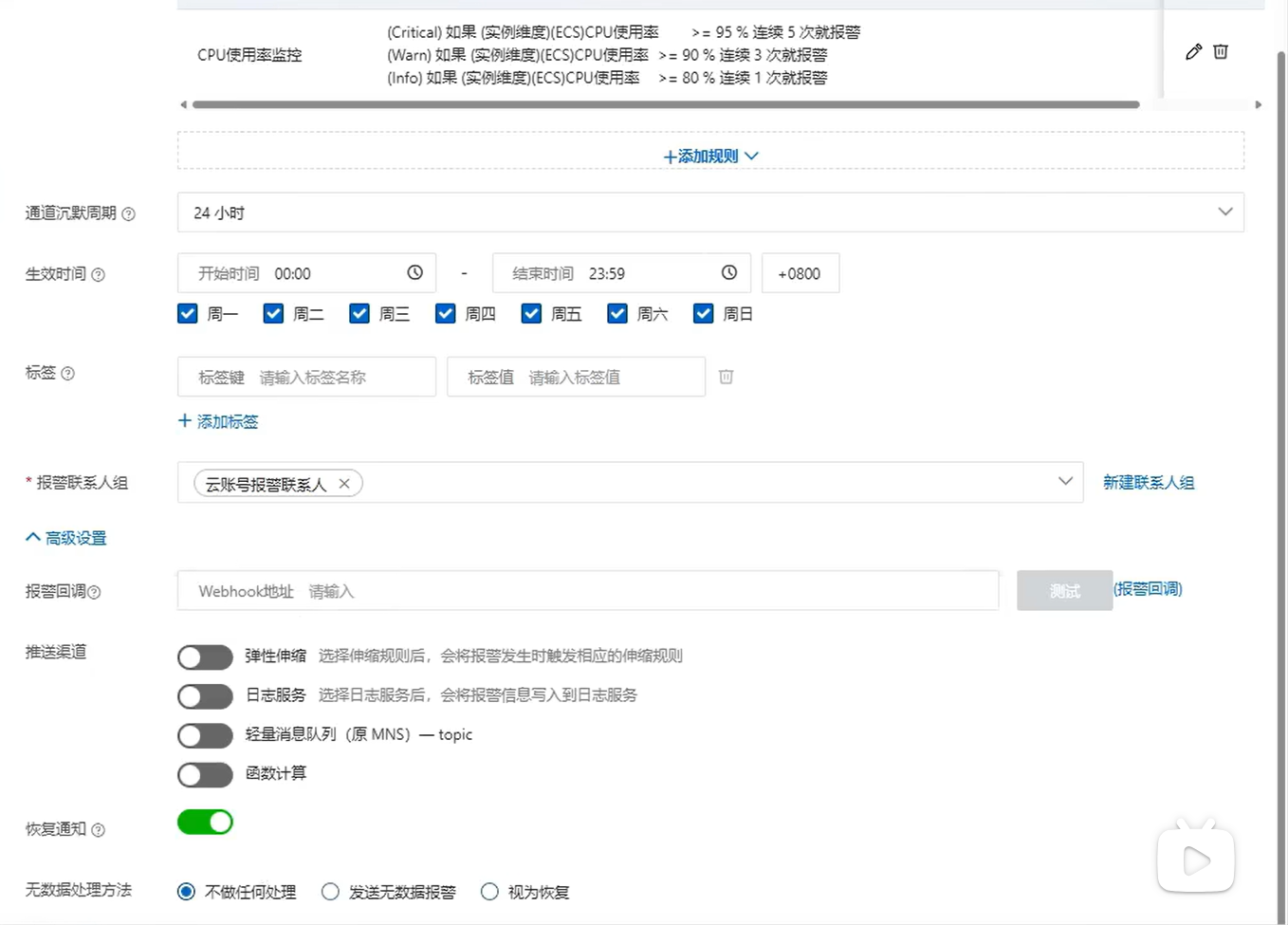
系统运维常见问题
问题一:CPU负载
1: 确认是否存在负载过高使用top或htop命令查看系统的平均负载值。
注意:如果负载值持续高于CPU核心数的0.5倍,则可能存在负载过高问题。如果超过1则负载已经较高了, 当超过2~3倍意味着负载超高,需要立即解决

这三个值即表示CPU分别1分钟、5分钟和15分钟的平均负载情况
2: 排查CPU负载过高的原因
| 原因 | 具体表现 | 如何解决 |
|---|---|---|
| 异常进程或服务占用大量 CPU 资源 | 单个进程或服务占用大量 CPU 资源,导致整体 CPU 使用率升高。 | 使用 top 或 htop 命令查看具体占用 CPU 资源的进程。 按 Shift+P 按键,按 CPU 使用率排序定位异常进程,然后通过 Kill -9 终止异常进程。 |
| 系统资源不足 | 实例的 CPU 性能不足以支撑当前业务需求 | 升级实例规格或者优化业务逻辑 |
| 磁盘或网络 I/O 瓶颈 | CPU 负载高但实际 CPU 使用率较低,可能是磁盘或网络 I/O 瓶颈导致 | 优化磁盘读写,比如升级高性能云盘 优化网络带宽:增加公网带宽或调整内网流量分布 |
| 僵尸进程或不可中断的睡眠状态 | 通过 top 命令观察,CPU 使用率不高但负载值较高 | ps -axjf|grep "D+" 查看是否存在僵尸进程或不可中断的睡眠状态, 如果存在,建议恢复其对应依赖资源或重启系统 |
| 系统遭遇病毒或恶意程序攻击 | CPU 使用率高但无法通过 top 等命令找到异常进程 | 通过云监控监测异常时间点,检查是否存在异常域名或 IP 的网络通信, 如果确认,建议先备份数据,然后回滚实例并进行病毒扫描 |
问题二:内存爆满
1: 确认是否存在内存爆满 使用top或htop命令查看,或者直接云监控查看均可。
注意:如果内存使用率持续接近或达到100%,则定义为内存爆满
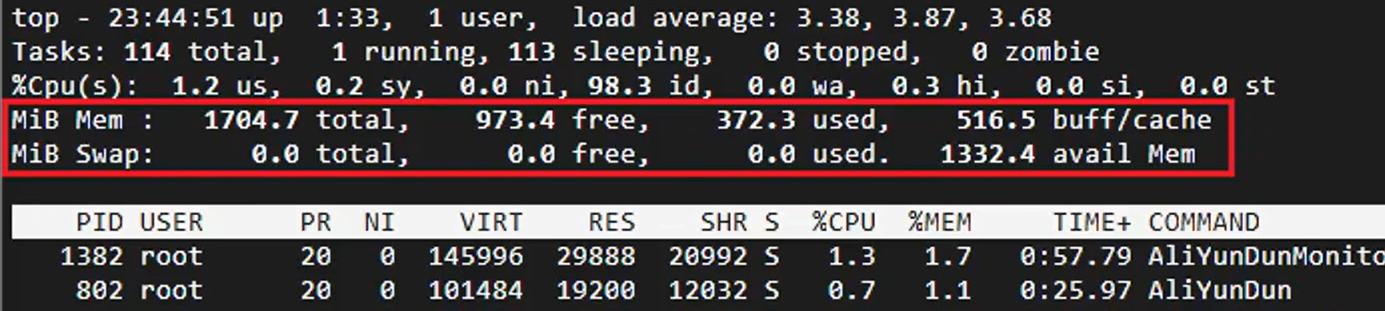
当Mem行的 free值几乎为0时, 表示剩余内存几乎没有了
2: 排查内存过高的原因
| 原因 | 具体表现 | 如何解决 |
|---|---|---|
| 异常进程占用大量内存 | 单个进程或程序长时间占用大量内存资源 | 使用 top 或 htop 命令查看具体占用内存资源的进程。 按 M 按键,按内存使用率排序,定位异常进程,然后通过 Kill - 9 终止异常进程。 |
| 系统内存不足 | 实例的物理内存不足以支撑当前业务需求 | 升级实例规格或者优化业务逻辑 |
| 内存泄漏或代码缺陷 | 应用程序在运行过程中不断消耗内存,导致内存使用率持续升高 | 使用内存分析工具(如 Valgrind、jprofiler、jmap 等)分析应用程序的内存占用情况 根据分析结果优化业务代码,修复内存泄漏问题 |
| 已删除未释放的僵尸文件 | 磁盘空间充足,但内存使用率仍然很高 | lsof|grep deleted 查找已删除但未释放的文件,然后重启相关进程以释放内存 |
| 系统缓存或虚拟内存不足 | 系统缓存占用过多内存,或虚拟内存配置不足 | 设置 Swap 分区,增加虚拟内存大小 |
ECS服务器巡检报告介绍
ECS服务器巡检报告一般是用于评估云服务器ECS实例及其相关资源(如磁盘、网络等)的健康状态和运行性能。 该报告基于对ECS实例的全面检查,包括性能指标、安全风险、配置合规性等多个维度的分析。通过巡检报告可以提高 系统的稳定性、安全性、优化资源配置和支持合规性审计工作
巡检报告主要内容:
| 内容 | 说明 |
|---|---|
| 性能监控数据 | 包括 CPU 使用率、内存使用率、磁盘 I/O、网络流量等关键性能指标 |
| 异常问题诊断 | 列出 ECS 实例在运行过程中发现的异常问题,例如高 CPU 利用率、磁盘 I/O 异常、网络连接问题等。 每个异常项需要附带严重等级(如 Info、Warn、Critical) |
| 安全风险评估 | 检查 ECS 实例是否受到 DDoS 攻击或其他安全威胁,并提供防护建议 |
| 资源使用与配置分析 | 检查 ECS 实例的资源配置是否合理,例如磁盘空间是否充足、带宽是否满足业务需求,并提供优化建议 |
| 事件记录与处理建议 | 监测到云盘性能达到上限或未创建快照备份等风险事件,确保系统的稳定性和数据的安全性 |
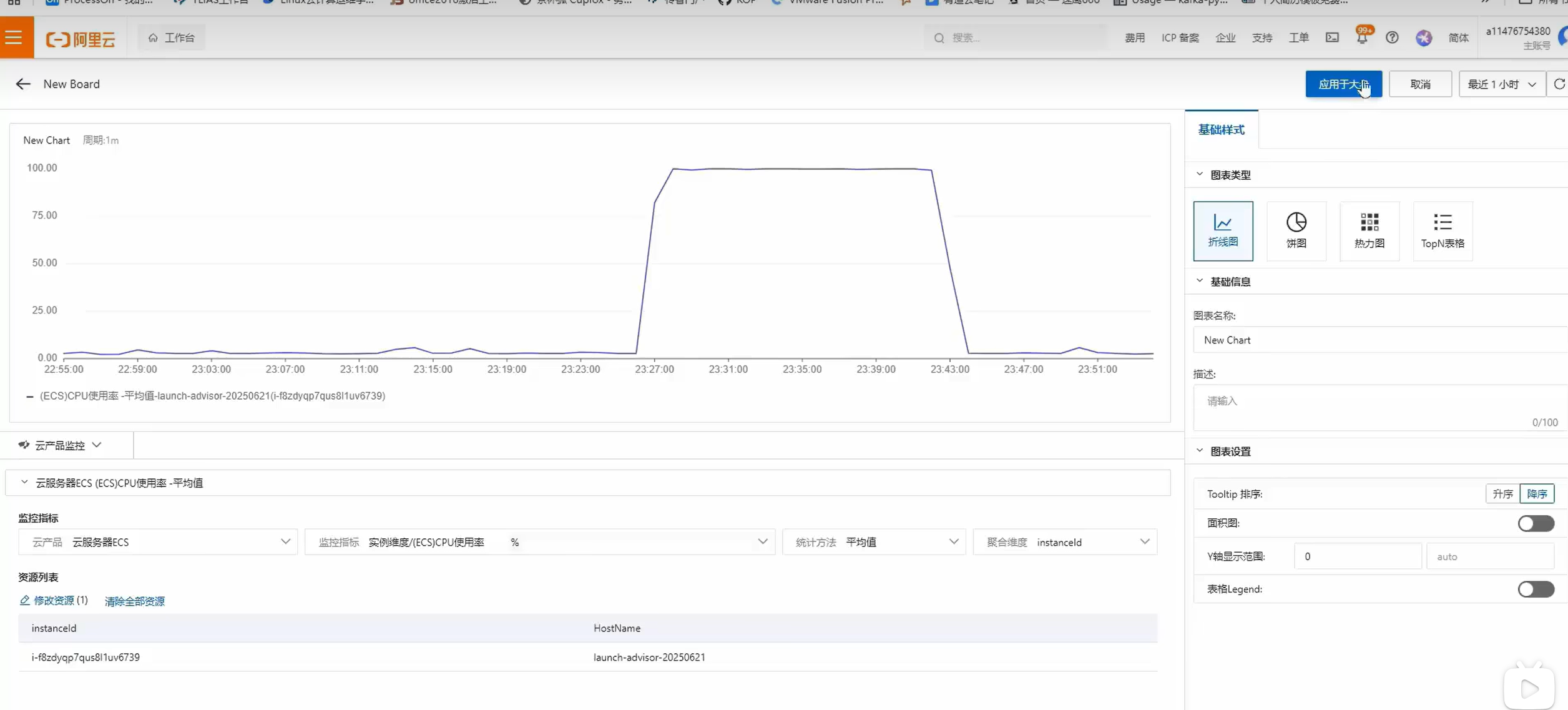
云服务器监控可视化大屏
2:打开自定义大盘,创建大盘
2:根据需求添加对应监测指标
如: 添加CPU使用率(折线图) 其他类似