【CNN】卷积神经网络池化- part2
1.池化
降采样,减少参数数量,避免过拟合,提高鲁棒性
2.池化操作
池化操作(也称为下采样,Subsampling)类似卷积操作,使用的也是一个很小的矩阵,叫做池化核,但是池化核本身没有参数,只是通过对输入特征矩阵本身进行运算,它的大小通常是2x2、3x3、4x4等,其中2x2使用频率最高。然后将池化核在卷积得到的输出特征图中进行池化操作,需要注意的是,池化的过程中也有Padding方式以及步长的概念,与卷积不同的是,池化的步长往往等于池化核的大小。
最常见的池化操作为最大值池化(Max Pooling)和平均值池化(AveragePooling)两种。
最大池化是从每个局部区域中选择最大值作为池化后的值,这样可以保留局部区域中最显著的特征。最大池化在提取图像中的纹理、形状等方面具有很好的效果。
平均池化是将局部区域中的值取平均作为池化后的值,这样可以得到整体特征的平均值。平均池化在提取图像中的整体特征、减少噪声等方面具有较好的效果。
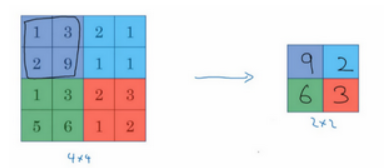
先举一个池化层的例子,然后再讨论池化层的必要性。假如输入是一个4×4矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的树池是一个2×2矩阵。执行过程非常简单,把4×4的输入拆分成不同的区域,把这个区域用不同颜色来标记。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
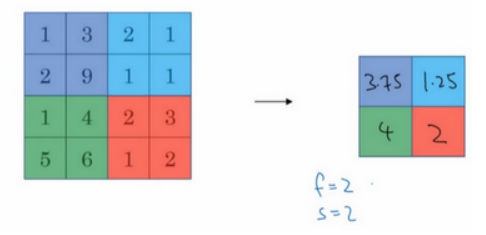
另外还有一种类型的池化,平均池化。简单介绍一下,这种运算顾名思义,选取的不是每个过滤器的最大值,而是平均值。示例中,紫色区域的平均值是3.75,后面依次是1.25、4和2。这个平均池化的超级参数 f=2,s=2,也可以选择其它超级参数。
下面是最大池化(Max Pooling)的计算过程的动画演示,左侧图像池化运算得到右侧图像。

通过上面动画演示,大致可以看出,经过池化计算后的图像,基本就是左侧特征图的“低像素版”结果。也就是说池化运算能够保留最强烈的特征,并大大降低数据体量。
3.池化的作用
降低特征图尺寸,减少计算量,提高运行效率
特此平移,选择的不变性,提高鲁棒性
非线性操作,如最大值池化
缺点:
会丢失部分信息
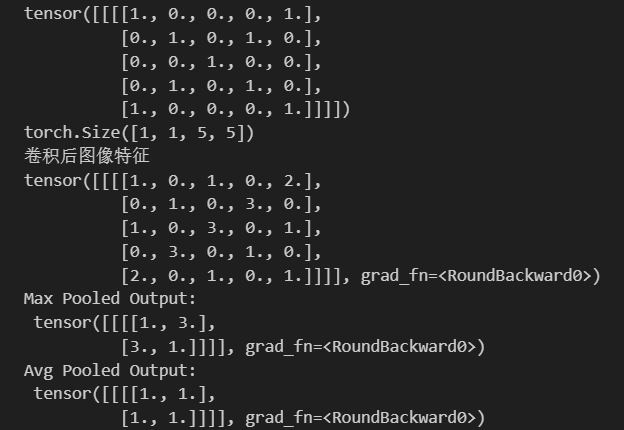
import torch
import torch.nn as nn
import numpy as np# 定义输入张量
input_tensor = torch.randn(1, 1, 5, 5) # 形状为 [batch_size, channels, height, width]# 创建一个 NumPy 数组
matrix_np = np.array([[[[1.0, 0.0, 0.0, 0.0, 1.0],[0.0, 1.0, 0.0, 1.0, 0.0],[0.0, 0.0, 1.0, 0.0, 0.0],[0.0, 1.0, 0.0, 1.0, 0.0],[1.0, 0.0, 0.0, 0.0, 1.0]]]])
kernel = torch.tensor([[0., 0., 1.],[0., 1., 0.],[1., 0., 0.]
], dtype=torch.float32)matrix_np = np.array(matrix_np).astype(np.float32)
# 转换为 PyTorch 张量
input_data = torch.from_numpy(matrix_np)print(input_data)# 创建卷积层,输入通道数为 1
# 输出通道数1
# 步长默认是1
# 卷积核大小3*3
# 1个0填充
conv_layer = nn.Conv2d(in_channels=1, out_channels=1, stride=1, kernel_size=3, padding=1)conv_layer.weight.data = kernel.view(1, 1, 3, 3)
# 对输入数据进行卷积操作
output_data = conv_layer(input_data)# 输出结果
print(output_data.shape)
print("卷积后图像特征")
print(torch.round(output_data))# 定义池化层
#最大池化
max_pool_layer = nn.MaxPool2d(kernel_size=2, stride=3)
#平均池化
avg_pool_layer = nn.AvgPool2d(kernel_size=2, stride=3)# 应用最大池化
max_pooled = max_pool_layer(output_data)
print("Max Pooled Output:\n", torch.round(max_pooled))# 应用平均池化
avg_pooled = avg_pool_layer(output_data)
print("Avg Pooled Output:\n", torch.round(avg_pooled))