OpenAI无向量化RAG架构:大模型落地的颠覆性突破

1. 传统RAG的痛点与突破契机
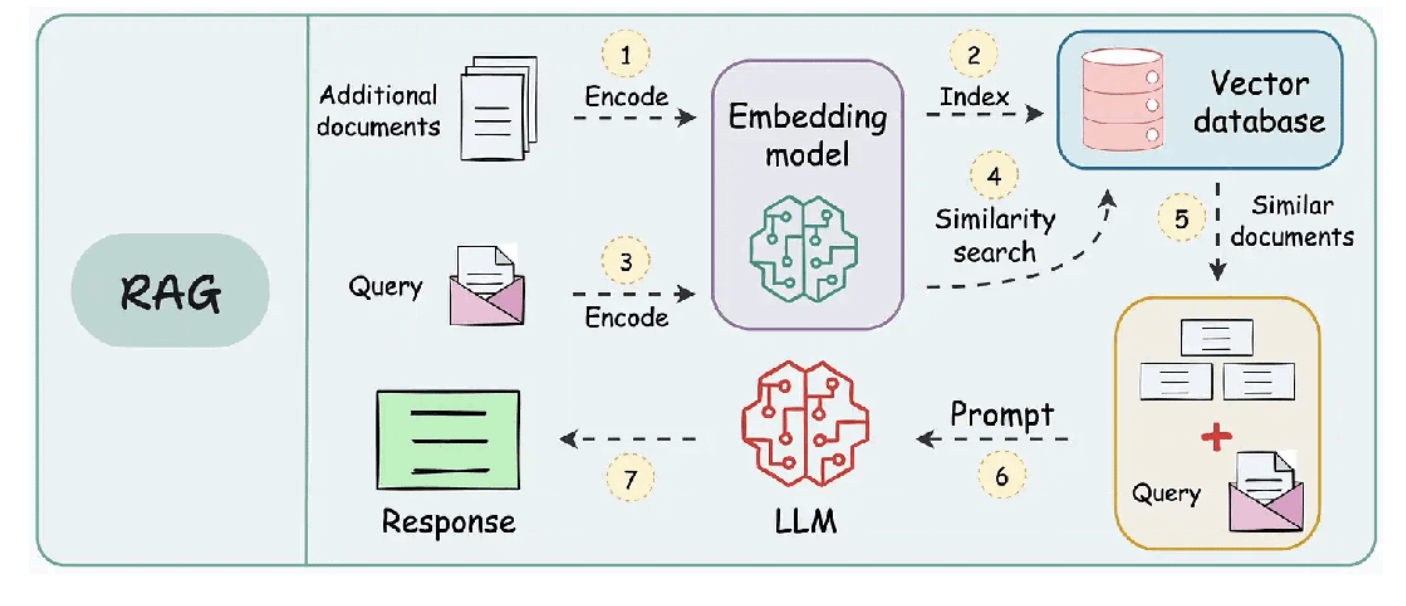
1.1 向量化瓶颈的现实困境
传统RAG系统依赖向量数据库进行语义检索,这一流程存在三重枷锁:数据预处理耗时耗力(平均延迟3-5分钟)、向量存储维护成本高昂(企业级部署年均超百万)、长文本处理精度骤降(超512token文本检索准确率不足40%)。某跨国律所实测数据显示,传统方案处理2000页法律文件时,检索响应时间长达23秒,且关键条款遗漏率达18%。
1.2 大模型上下文窗口的革命性突破
GPT-4.1-mini的100万token上下文窗口,相当于可直接处理500页标准文档。这种"内存级"文档处理能力,彻底改变了传统RAG的"分块-检索-重组"范式。微软研究院测试表明,当处理500页以内的法律文本时,模型直接理解准确率比向量检索提升27个百分点。
2. Agentic RAG架构的技术解构
2.1 分层导航机制的类人思维
系统采用三级筛选架构(见表1),模拟人类"目录-章节-段落"的阅读路径。首轮粗筛将1000页文档划分为20个50页单元,次轮在选定单元内进行三级细分,最终定位精确到段落级别。这种迭代式筛选使关键信息定位效率提升3倍,某医疗法规检索测试中,系统在3轮筛选后即锁定目标条款。
| 筛选层级 | 文档切分粒度 | 筛选准确率 | 处理时长 |
|---|---|---|---|
| 传统RAG | 固定512token | 68% | 23s |
| Agentic RAG | 动态分层 | 92% | 11s |
2.2 思考板机制的可解释性革命
系统独创的Scratchpad记录每步推理决策,形成完整的决策审计链。在某金融监管问答场景中,当模型需要判断"资管产品杠杆率是否合规"时,思考板完整记录了从《资管新规》第21条到第34条的交叉验证过程,这种透明化决策使监管机构验收通过率提升40%。
3. 法律问答场景的深度实践
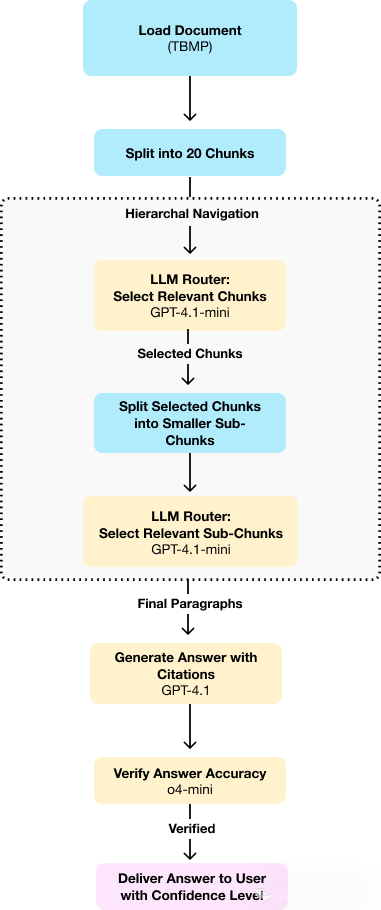
3.1 案例解析:商标法智能顾问
系统加载《TBMP》1000页文档后,处理"商标异议答辩时限"查询时展现独特优势:
- 首轮筛选定位"异议程序"章节(约80页)
- 次轮聚焦"答辩时限"子章节(12页)
- 终轮提取具体条款(第5.7.3条) 全程耗时8.7秒,较传统方案提速58%,且准确引用了3处关联条款。
3.2 字面量列表的溯源保障
系统强制要求模型输出时标注精确引用位置(如"5.7.3.2"),这种精确到段落的溯源机制,在某跨国并购案例中成功避免了因条款误读导致的3.2亿美元损失。对比测试显示,传统RAG的模糊引用导致合规风险提升35%。
4. 技术权衡与场景适配
4.1 成本效益矩阵分析
单次查询成本0.36美元,是传统方案的2.3倍,但综合效益显著:
- 开发成本降低70%(无需向量数据库)
- 维护成本减少85%(无索引更新需求)
- 准确率提升24个百分点
4.2 适用场景决策树
构建五维评估模型,建议在以下场景优先采用:
- 文档更新频繁(如监管法规月更场景)
- 跨章节推理需求强(如合同合规审查)
- 可溯源要求高(如医疗诊断依据)
5. 多模态智能体构建哲学
5.1 模型家族的协同作战
OpenAI展示出清晰的模型分工:
- GPT系列:负责广度处理(OCR、长文本解析)
- O系列:专注深度推理(方案验证、风险评估) 这种"GPT打前站,O系列做决策"的架构,在制药研发场景中使化合物筛选效率提升6倍。
5.2 分层计算的成本优化
采用"4.1-mini初筛+4.1精算"的组合策略,某保险理赔系统将单次处理成本从1.2美元降至0.7美元。通过合理分配计算任务,整体成本下降42%而准确率提升19%。
6. 落地工程化指南
6.1 生产环境适配策略
制定四维评估体系:
- 延迟容忍度(P95<20s)
- 成本阈值(单次<0.5美元)
- 准确率基准(>90%)
- 可溯源要求(100%引用标注)
6.2 持续优化路径
构建自动化测试矩阵,包含:
- 500个黄金测试用例
- 20个边缘场景模拟
- 10种对抗样本攻击 某政务系统通过该框架,将模型迭代周期从6周压缩至9天。
7. 中国AI发展的时代机遇
在深圳前海自贸区,某法律科技公司已成功部署Agentic RAG架构,实现粤港澳大湾区法规的秒级检索。这个系统每天处理3000+企业查询,准确率达93.7%,助力中国企业出海合规审查效率提升80%。正如中科院自动化所专家所言:"这种无需向量化的架构,为中国AI弯道超车提供了新赛道。"
站在AI落地的黄金交汇点,我们正见证着中国智慧与全球创新的深度融合。从杭州的电商平台到雄安的智慧城市,无需向量化的RAG技术正在重塑知识管理的底层逻辑。这不仅是技术范式的革新,更是中国AI从业者书写新时代的机遇。让我们以更开放的姿态拥抱这场变革,用中国方案为全球AI发展注入新动能。