重塑优化建模与算法设计:2024上半年大模型(LLM)在优化领域的应用盘点
引言
运筹学(Operations Research)与组合优化(Combinatorial Optimization)领域面临着一道鸿沟:一边是能够解决复杂决策问题的强大数学模型与算法,另一边则是缺乏专业知识、难以将现实需求转化为形式化语言的广大业务决策者。传统上,跨越这道鸿沟极度依赖领域专家高昂的时间投入和智力成本。然而,近期以大型语言模型(LLM)为代表的人工智能技术浪潮,正为自动化、平民化地解决优化问题开辟一条充满想象力的道路。纵观2024年上半年涌现的相关研究,我们可以清晰地看到几个相辅相成、并行发展的核心趋势。
- 其一,将LLM作为自动化算法设计的“进化引擎”:通过反思反馈来指导代码优化的 ReEvo (01),还是将复杂求解器模块化、再由LLM逐个重写的 AutoSAT (02),亦或是模仿人类专家同时进化“思想”与“代码”的 EoH (07),其共同目标都是利用LLM强大的代码生成与理解能力,自动探索并设计出超越人类手工水平的高性能启发式算法。
- 其二,致力于让LLM扮演“建模专家”的角色:ORLM (08) 通过构建高质量的专业指令数据集 OR-INSTRUCT,扎实地解决了通用LLM在专业建模任务上“幻觉”频发、精度不足的核心痛点,证明了领域专用模型(Domain-Specific LLM)的巨大潜力。
- 其三,探索通过更精巧的提示策略(Prompting),直接引导LLM进行端到端的推理求解:“自我引导探索”(SGE, 09) 策略模仿元启发式思想,让LLM自主地进行“探索-分解-解决-优化”的多路径思考,显著提升了在复杂问题上的求解质量。与此同时,研究 (06) 对LLM解决机器人路径规划的能力进行了系统性评测,揭示了“自我调试”与“自我验证”等框架虽能提升方案的可行性。
- 最后,多模态(Multimodal)方法的出现为优化问题注入了新的活力,让LLM得以“眼见为实”:无论是将图文结合用于车辆路径规划的 MLLM (04),还是完全依赖“目测”图片并进行视觉化自我迭代来求解旅行商问题的 (10),都证明了视觉信息在帮助LLM理解问题内在结构方面的独特价值。同时,为了让这些AI生成的“最优解”不再是令人费解的黑箱,RouteExplainer (05) 等工作利用LLM生成反事实解释,极大地提升了方案的可信度与人机交互的效率。
以下,我们将按照发表时间的顺序,逐一梳理这些代表性研究的核心内容。每一篇笔记都将聚焦于论文所解决的关键问题、提出的创新方法及其取得的实验效果,从而为引言中勾勒的宏观趋势提供具体的案例支撑。
2024.02
(01) ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution
NeurIPS 2024
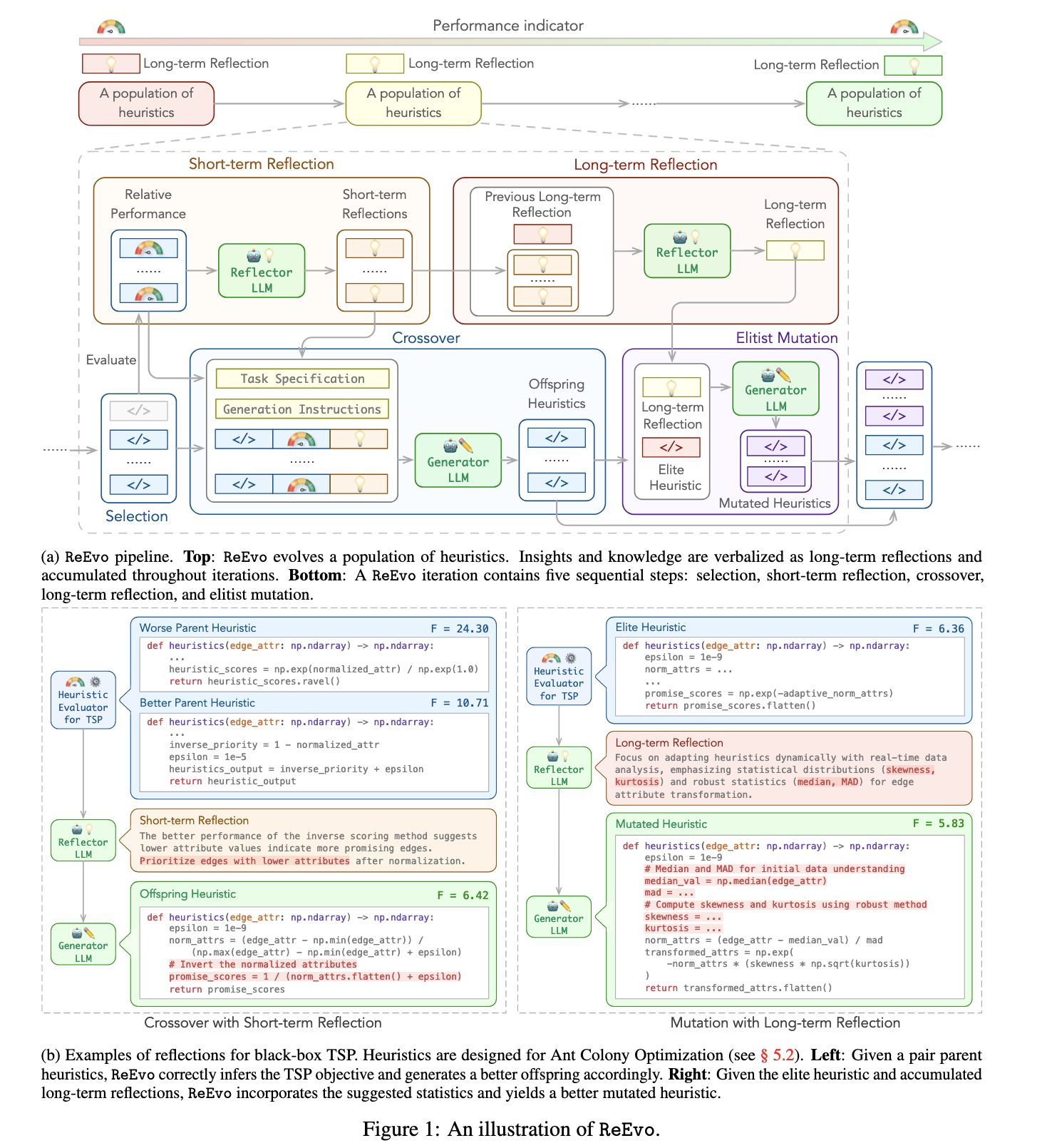
- 问题:在组合优化问题(如旅行商问题、车辆路径问题)中,设计高效的启发式算法(heuristics)通常需要领域专家进行大量繁琐的试错和手动调整。传统的自动化方法(超启发式算法,Hyper-Heuristics)又受限于预先定义好的、无法扩展的启发式规则空间。如何以更低的成本、更强的自动化能力来设计出高性能的启发式算法,是一个长期存在的挑战。
- 方法:提出了一种名为 反思进化 (Reflective Evolution, ReEvo) 的新方法,其核心思想是将大型语言模型 (LLM) 与进化算法相结合,来自动生成和优化解决组合优化问题的启发式算法代码。
- 生成器 (Generator):像进化算法中的“交叉”和“变异”操作一样,根据指令生成新的启发式算法代码。
- 反思器 (Reflector):通过对比两个现有算法的优劣,LLM 会生成“反思性”的语言反馈(verbal gradients),总结出什么样的修改可能带来性能提升。这种反馈被用来指导下一代算法的生成。
- 双层反思机制:
- 短期反思:针对一对“父代”算法进行比较,给出直接的改进建议。
- 长期反思:不断积累迭代过程中的短期反思,形成更宏观、更深刻的改进策略,指导精英个体的变异。
- 效果:该方法在 6 个不同的组合优化问题上,针对 5 种不同类型的算法进行了测试,均取得了当前最优(SOTA)或极具竞争力的效果。
(02) AutoSAT: Automatically Optimize SAT Solvers via Large Language Models
arXiv
- 问题:手动为布尔可满足性问题(SAT)求解器设计和微调其核心的启发式策略(heuristics),是一个极其耗费时间、精力和专家经验的过程。
- 方法:论文提出了一个名为 AutoSAT 的自动化优化框架 。其核心创新思想是,不让大语言模型(LLM)从零开始编写一个完整的、复杂的求解器(实践证明这种方式效果不佳 ),而是:
- 模块化分解:将一个现有的SAT求解器分解为9个独立的、细粒度的启发式功能模块(如重启策略、变量选择等)
- LLM作为优化算子:利用LLM作为“代码生成器”,针对性地重写和优化这些独立的函数模块,而不是整个求解器。
- 进化搜索:将这个“LLM生成新模块”的过程嵌入到一个进化算法(如
(1+1)EA)或贪心搜索(GHC)的框架中。该框架通过在具体数据集上进行性能评估,迭代地搜索并采纳能带来性能提升的、由LLM生成的更优启发式策略组合。
- 效果:从一个简单的基准求解器(EasySAT)出发,AutoSAT优化后的版本性能远超基准 。与经典的、性能强大的 MiniSat 求解器相比,AutoSAT 在12个测试数据集中的 9个 上表现更优 。
(03) From Large Language Models and Optimization to Decision Optimization CoPilot: A Research Manifesto
arXiv
- 问题:现实世界中的商业决策者们虽然能从数学最优化方法中获益巨大,但他们大多缺乏将复杂的商业问题转化为形式化、可求解的数学最优化模型所需的专业技能,这极大地限制了最优化技术的广泛应用。
- 方法:综述。提出了构建一个“决策优化协同驾驶舱”(Decision Optimization CoPilot, DOCP)的构想。 这是一个基于大型语言模型(LLM)的AI助手,其核心创新在于:通过自然语言与非专家用户(如商业决策者)进行对话,自动完成传统上需要优化专家才能执行的全套流程,包括:理解业务问题、构建数学模型、编写代码并求解,最终为决策者提供可行的建议。
- 效果:
- 现有的大型语言模型(如ChatGPT)已经具备了实现DOCP所需的部分能力,例如可以从自然语言描述中生成基础的最优化模型。
- 核心差距: 然而,研究也暴露出现有技术的重大不足:从高层次的业务问题到完整、恰当的数学模型的转化能力不足,生成的模型常常不完整或不适用。即使给出精确描述,模型也可能存在难以被非专家发现的微妙错误。在生成计算效率高的“精简”模型方面存在显著差距。
2024.03
(04) How Multimodal Integration Boost the Performance of LLM for Optimization: Case Study on Capacitated Vehicle Routing Problems
arXiv
- 问题:大型语言模型(LLMs)在处理优化问题时,如果仅仅依赖纯文本(尤其是数值型文本)作为输入,很难有效理解决策变量之间的空间或结构关系,导致在解决高维度复杂问题(如车辆路径规划)时性能不佳。
- 方法:提出了一个多模态(Multimodal)解决方案。其核心思想是,除了给大型语言模型(LLM)提供传统的文本描述外,还额外输入问题的“视觉”表征(即图形或图像)。 这个名为 MLLM 的框架通过“文字+图像”相结合的方式,让模型能够像人类一样,更直观地理解问题的空间布局和内在结构,从而学习到更优的求解策略(启发式方法)。具体流程分为三步:
- 启发式提取: 向多模态模型展示若干已解决的“问题-答案”对,每个案例都包含文本描述和一张对比图(问题布局 vs 最优解路线图),让模型从中学习求解规律。
- 方案生成: 针对一个新问题,向模型提供其文本描述和问题布局图(不含答案),要求模型基于学习到的规律生成一个初始解决方案。
- 评估与修正: 检查模型生成的方案是否存在逻辑错误(如ID缺失/重复),若有则将错误信息反馈给模型进行迭代修正。
- 效果:该方法在经典的组合优化问题——带容量约束的车辆路径问题(CVRP)上进行了验证,并取得了显著效果。通过分析发现,视觉信息的加入使模型能捕捉到纯文本无法提供的、更高级的启发式规则,例如“最小化路线重叠”和“基于地理邻近度进行聚类”,从而规划出更合理的路线。
(05) RouteExplainer: An Explanation Framework for Vehicle Routing Problem
PAKDD 2024
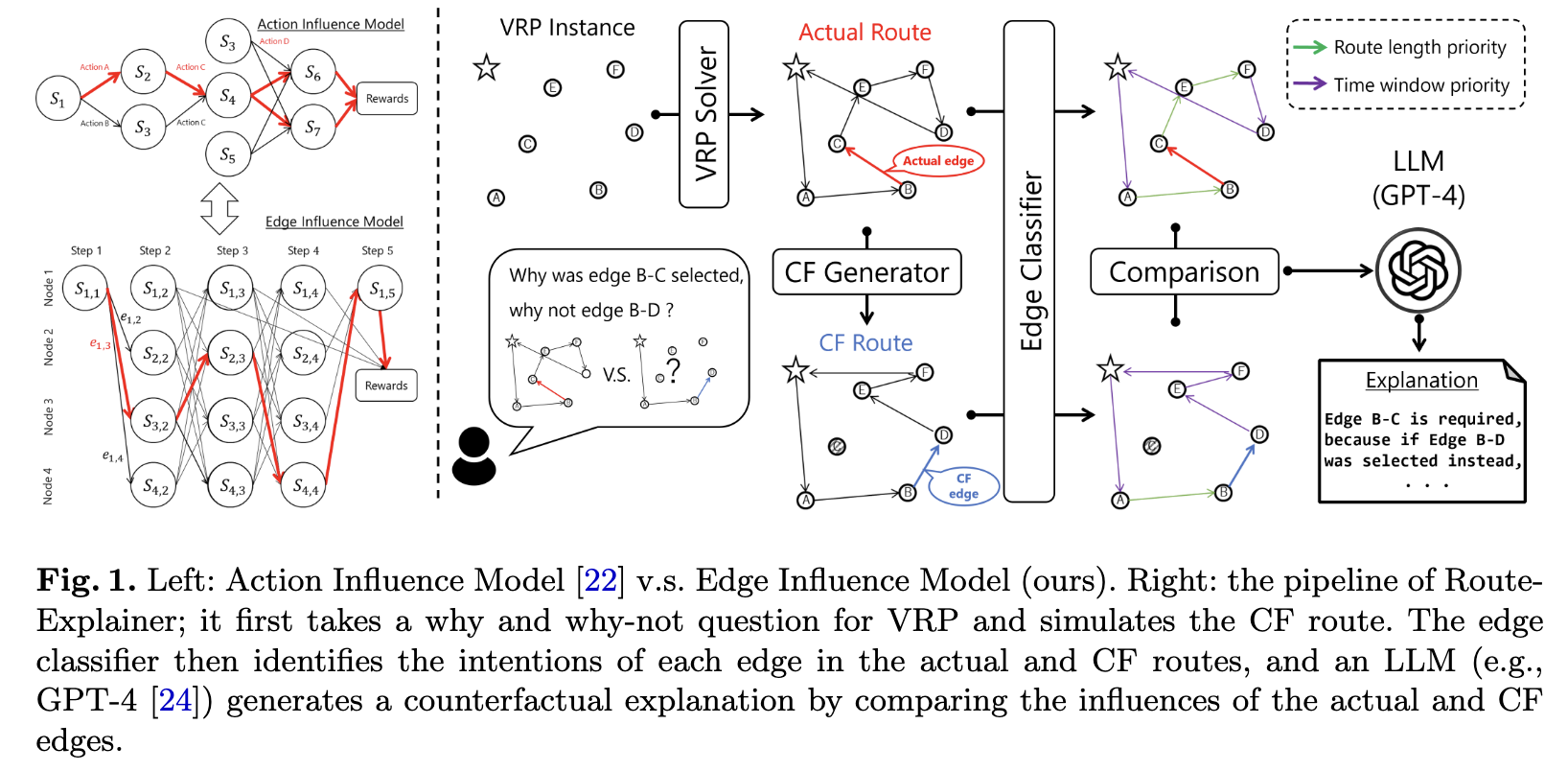
- 问题:车辆路径问题(VRP)的求解器虽然能给出最优或近优的路线方案,但这些方案对于用户来说是一个“黑箱”。用户不知道为什么系统会选择某条特定的路径而非另一条可能的路径。这种缺乏可解释性的问题,降低了用户在实际应用(如旅游规划、应急调度)中对系统的信任度,也使得用户难以根据个人偏好对路线进行有效的交互式修改。
- 方法:提出了一个名为 RouteExplainer 的事后解释框架,其核心思想是生成反事实解释
- 提出边影响模型 (EIM):将一条路线视为一系列连续的“动作”(即边的选择),并构建一个因果模型来分析每一步选择(每一条边)对后续整个路线产生的影响。
- 生成反事实路线:当用户提问“为什么走A路线而不是B路线?”时,框架会强制选择B路线,然后由VRP求解器重新计算出一条最优的“反事实路线” 。
- 推理边的“意图”:设计了一个基于 Transformer 的序列分类器,用于自动标注实际路线和反事实路线中每一条边的“意图”,例如,这条边是为了“优先保证时间窗口”还是为了“优先缩短路程” 。
- 利用大语言模型 (LLM) 生成解释:通过对比分析“实际路线”和“反事实路线”在总成本、可行性、以及各边“意图”等多个维度的差异,最终利用大语言模型(如GPT-4)生成通俗易懂的自然语言文本,向用户解释选择原始路线的利弊。
- 效果:其核心组件“边意图分类器”在计算速度上实现了巨大提升,处理1万个样本仅需不到3秒,而基线方法则需要数分钟,这证明了其在实际应用中快速响应大量请求的潜力 。同时,在多数VRP数据集上,其分类准确率(宏F1分数)能保持在85-95% 。在京都旅游路线的定性评估中,该框架成功地生成了高质量的解释。它不仅清楚地说明了选择原始路线的必要性(例如,若不这么走会错过一个有英文导览的预定活动),还帮助用户在权衡利弊后做出更明智的决策,验证了框架的有效性以及与大语言模型结合的巨大潜力。
(06) Can Large Language Models Solve Robot Routing?
arXiv
- 问题:大型语言模型(LLM)能否直接根据自然语言描述,端到端地解决复杂的机器人路径规划问题,从而取代传统“人工转译 + 数学建模 + 专业求解器”的整套流程?
- 方法:未提出一个新算法,其核心创新在于设计了一套系统的评测体系来全面评估LLM的能力。该体系包含三个关键部分:
- 构建基准: 创建了一个包含8种不同类型、共80个独特问题的机器人路径规划数据集,作为评估的标准化平台。
- 设计框架: 提出了三种由简到繁的自动化框架来驱动LLM解决问题:
- 单次尝试 (Single attempt): LLM直接生成最终方案。
- 自我调试 (Self-debugging): 如果代码执行失败,LLM会根据错误信息自行修改并重新生成。
- 自我调试与自我验证 (Self-debugging with self-verification): 在“自我调试”基础上,LLM还会从任务描述中提取约束条件,生成单元测试来验证方案的正确性,若验证失败则再次修改。
- 评估维度: 在上述框架基础上,系统比较了不同上下文(如提供数学公式、伪代码、研究论文等)和不同LLM模型(如GPT-4、Llama等)对结果的影响。
- 效果:“自我调试”和“自我验证”框架能显著提高生成可行解的成功率(相较于单次尝试,成功率累计提升超过40%),但并不能保证、甚至有时会损害解的最优性(即方案质量)。 LLM对上下文信息极其敏感。提供“数学公式”会降低成功率但能提升解的最优性 ;而提供“伪代码”或“研究论文”则对结果没有稳定一致的改善效果。
2024.05
(07) Evolution of Heuristics: Towards Efficient Automatic Algorithm Design Using Large Language Model
ICML 2024
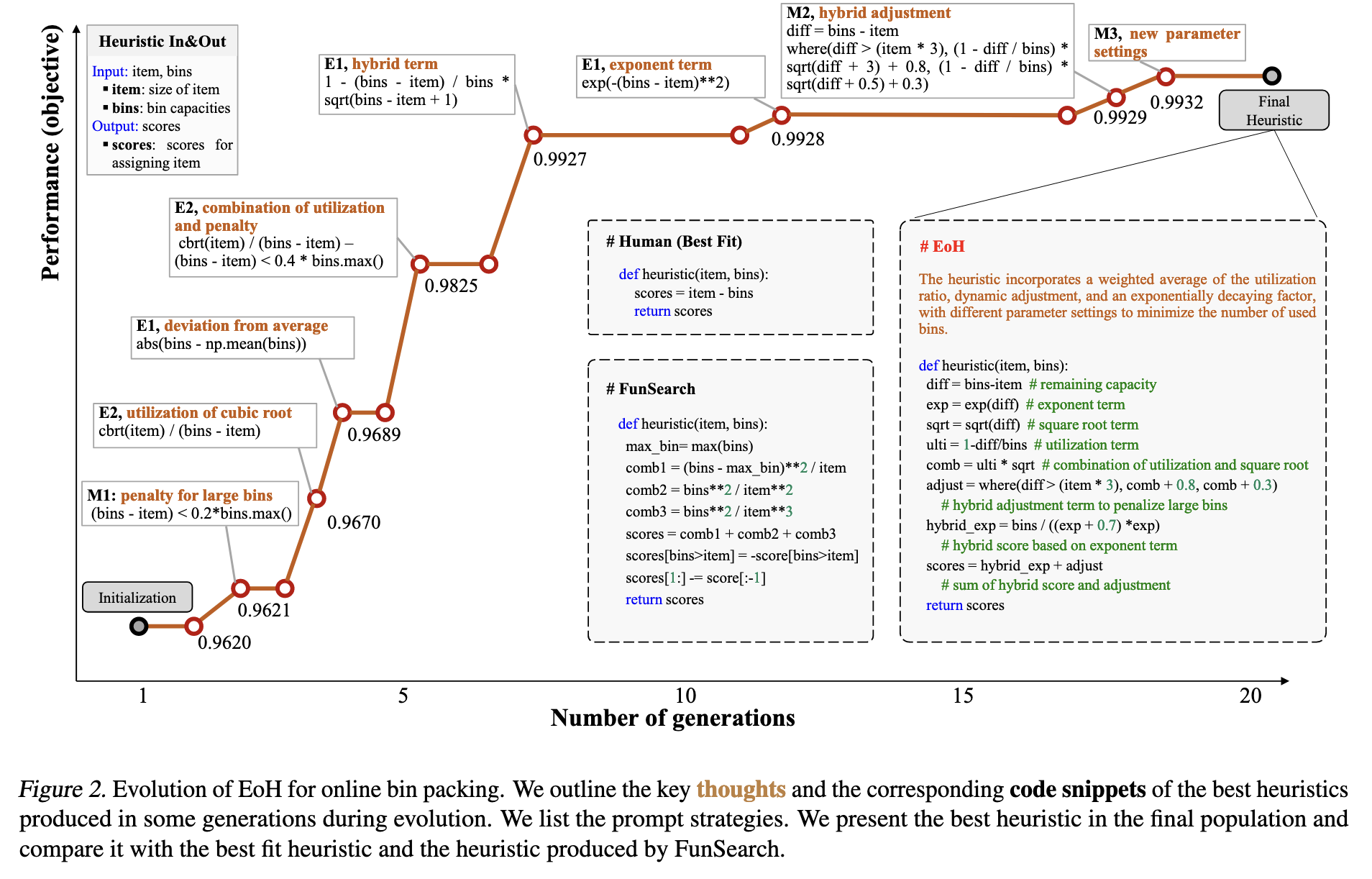
- 问题:人工为复杂问题设计高效的启发式算法(Heuristics)非常耗时、费力,且高度依赖专家经验。 而现有的自动算法设计方法(如FunSearch)虽然可行,但通常需要巨大的计算资源(例如对大语言模型进行上百万次调用),效率极低,不切实际。
- 方法:提出了一种名为“启发式进化”(Evolution of Heuristics, EoH)的框架。 其核心创新在于模仿人类专家的思考模式,同时进化“思想”(Thought)和“代码”(Code)。该方法在一个进化框架中,将“思想-代码”对作为进化的基本单位,利用LLM作为生成和变异引擎,通过精心设计的提示策略(Prompt Strategies)来指导LLM对已有算法进行探索和优化,从而高效地自动设计出新的、性能更强的算法。
- 思想(Thought): 用自然语言描述一个算法的高层逻辑和核心思路。
- 代码(Code): 由大语言模型(LLM)将上述“思想”翻译成的具体可执行程序。
- 效果:该方法在三个经典的组合优化问题上均取得了显著效果。生成的算法在在线装箱、旅行商问题(TSP)和流水车间调度问题(FSSP)上,其性能全面超越了多种广泛使用的人工设计算法以及包括FunSearch在内的其他自动设计方法。
(08) ORLM: Training Large Language Models for Optimization Modeling
Operations Research
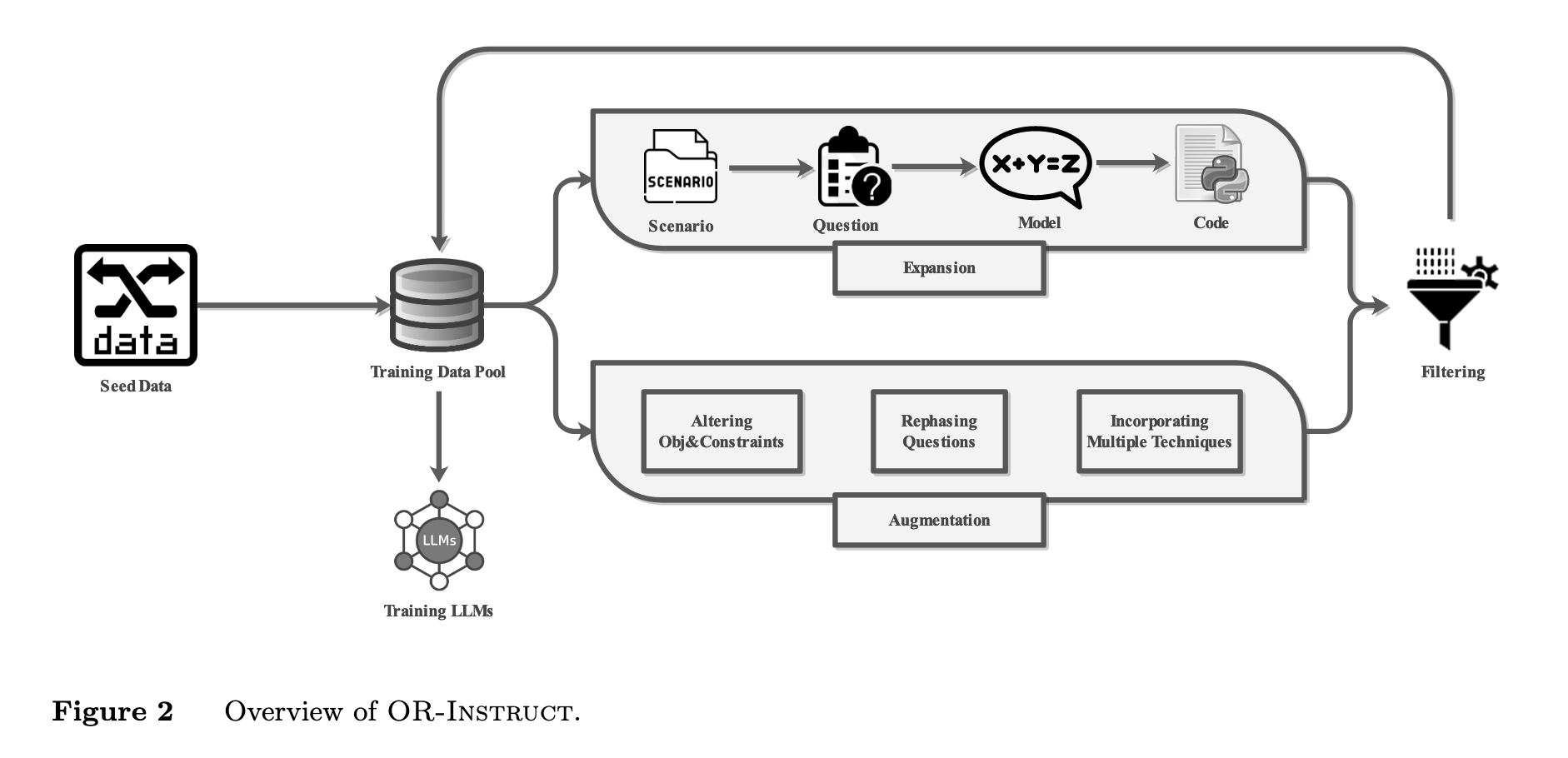
- 问题:当前,将现实世界中的复杂问题转化为数学优化模型(例如,线性规划、整数规划)非常依赖昂贵的、闭源的大语言模型(如GPT-4) 。然而,这些通用模型不仅成本高、有隐私风险,而且在处理专业的、带有复杂逻辑约束的优化问题时,常常会出错 。根本原因在于,缺少高质量、多样化的专业训练数据来教导开源模型如何进行精确的优化建模 。
- 方法:提出了一个名为 OR-INSTRUCT 的半自动化、可定制的数据合成框架 。其核心思想是:
- 种子与引导 (Seed & Bootstrap): 从一个小的、高质量的真实工业案例“种子”数据集开始 。
- 扩展与增强(Expansion & Augmentation):通过两种策略迭代地扩充数据集 。扩展策略利用GPT-4生成不同场景下的新问题,以保证覆盖面 ;增強策略则通过对现有问题进行三种改造——改变目标/约束、改写问题描述、引入多种建模技巧——来提升数据的多样性、复杂性和鲁棒性 。
- 专业化微调 (Specialized Fine-tuning): 使用这个合成的高质量数据集,对中等规模的开源语言模型(如LLaMA-3 8B)进行微调,使其成为专门用于优化建模的专家模型,称为ORLM (Operation Research Language Model) 。
- 效果:经过OR-INSTRUCT训练的7B参数规模的ORLM模型,在多个优化建模基准测试(包括论文新提出的工业级基准IndustryOR)上,其性能显著超越了基于GPT-4的标准提示方法 。 在一项对比实验中,借助ORLM的工程师在解决优化问题时的准确率提升了10%-25%,解决时间缩短了约1.8-2.2小时 。
(09) Self-Guiding Exploration for Combinatorial Problems
NeurIPS 2024
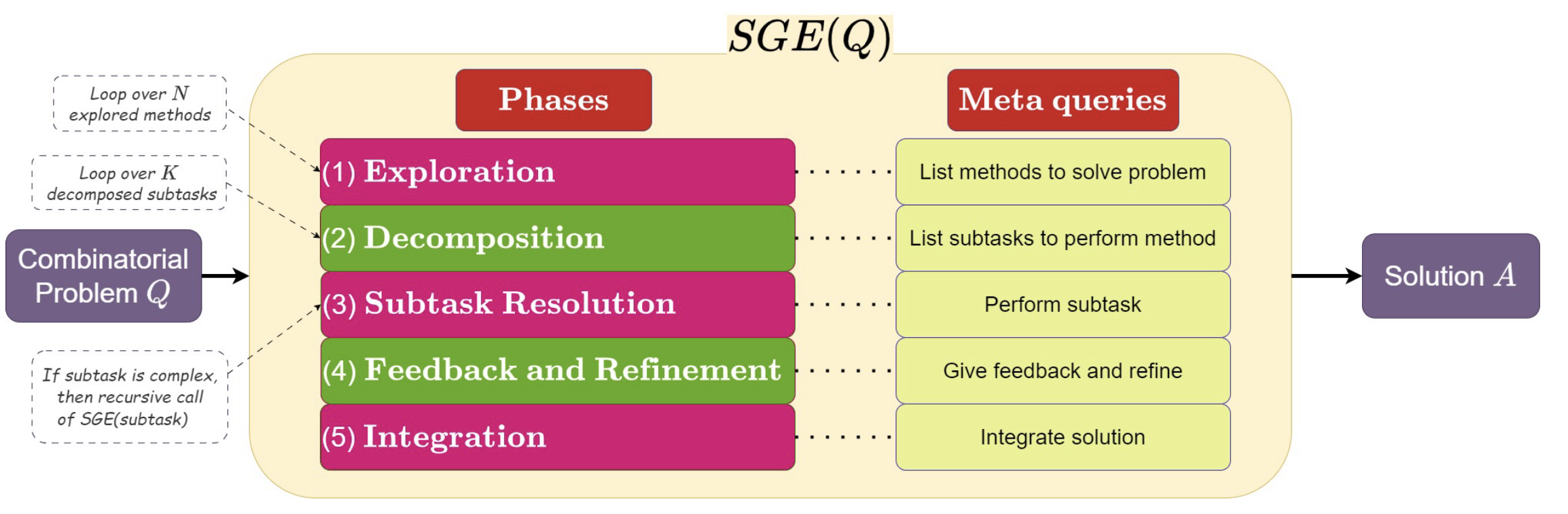
- 问题:组合优化问题(如旅行商问题、车辆路径问题)因其固有的 NP-难特性,在物流、规划和资源管理等领域至关重要,但传统上利用LLM解决的研究非常有限,且现有方法在问题规模增大时效果不佳 。
- 方法:提出了一种名为“自我引导探索”(Self-Guiding Exploration, SGE)的新型提示策略 。其核心思想是模仿元启发式算法(metaheuristic methods),让LLM无需人工编写特定的示例,即可自主、分阶段地解决复杂问题 。具体步骤如下:
- 探索 (Exploration):首先,LLM被要求列出所有可能解决当前问题的方法(如“最近邻算法”、“匈牙利算法”等),从而生成多个不同的“思考轨迹” 。
- 分解 (Decomposition):接着,针对每一个探索出的方法,LLM会自主地将其分解为一系列更小、更易于执行的子任务 。
- 解决与优化 (Resolution & Refinement):LLM按顺序执行每个子任务,并对生成的初步解决方案进行反馈和优化(例如,在旅行商问题中,它可能会自动建议使用2-opt算法来改进“最近邻算法”得出的路线)
- 整合 (Integration):最后,LLM会整合所有不同思考轨迹得出的优化后方案,形成最终的答案 。
- 效果:在组合优化问题上,SGE策略的效果比现有的其他提示策略(如思维链、分解法等)平均高出27.84% 。对于可以计算出全局最优解的较小规模问题,SGE的表现也更优。例如,在复杂的作业调度问题上,SGE得到的解与最优解的差距(Optimality Gap)比次优方法小了34.85% 。SGE虽然性能优越,但计算成本也更高,其模型调用次数比分解法多出87.89%。
2024.06
(10) Eyeballing Combinatorial Problems: A Case Study of Using Multimodal Large Language Models to Solve Traveling Salesman Problems
ISBCom 2024
- 问题:能否利用多模态大语言模型(MLLM)的视觉理解能力,像人类专家一样,仅仅通过“目测”(Eyeballing)节点分布图,来解决旅行商问题(TSP)这类经典的组合优化难题?
- 方法:将组合优化问题转化为一个纯粹的视觉推理任务 。他们没有依赖传统的数学公式或算法描述,而是直接将TSP问题的节点位置可视化成一张图片,输入给多模态模型(如Gemini系列),让模型“看图”来寻找最优路径 。论文最关键的创新是提出并验证了两种**视觉化自我迭代优化(Self-Refinement)**的框架 :
- 初始解生成:首先让模型根据节点图(或文本坐标)生成一个初始的TSP路径方案 。
- 可视化反馈:将模型生成的路径方案绘制成一张新的路径图 。
- 迭代改进:将这张包含当前路径的“解的可视化图”再次输入给模型,并指令它“观察上图并给出一个更好的路径方案” 。
- 循环优化:通过这种纯视觉的反馈循环,让模型反复“审视”并改进自己的答案,从而逐步逼近最优解 。
- 效果:证实了其方法的可行性,并在“中位差百分比”(Median gap %,即模型解与最优解的差距,越低越好)和“幻觉率”(Hallucination %,即出错率)等关键指标上取得了以下效果:
- 令人意外的是,“零样本”(Zero-shot)推理(即不给任何范例,直接看图求解)的表现比提供范例的“少样本”(Few-shot)方法更为稳定 。
- 自我迭代策略被证明是有效的。在两种迭代方法中,虽然两者都能优化解,但从图表上看,
Self-refine 1在问题规模增大时,其中位差(Median Gap)增长更平稳,表现相对更优 。 - “自集成”(Self-Ensemble)策略效果显著,即让模型对同一问题生成多个候选解,然后从中选取路径最短的那个 。实验证明,集成的规模越大(例如,从13个候选解中选择),最终得到的解质量越高(中位差越低) 。
- 所有方法的解题质量都会随着问题规模(节点数量)的增加而下降,同时,问题越复杂,模型出错(如产生不完整路径)的概率也越高 。