安装minerU的API服务
下载minerU的源码(下载地址:MinerU),然后找到web_api文件夹
进入文件夹,执行docker命令,生成minerU的镜像文件。
docker build -t mineru-api .
执行过程如下图
执行成功会创建一个镜像。
启动镜像,生成容器
docker run --rm -it --gpus=all -p 8000:8000 mineru-api
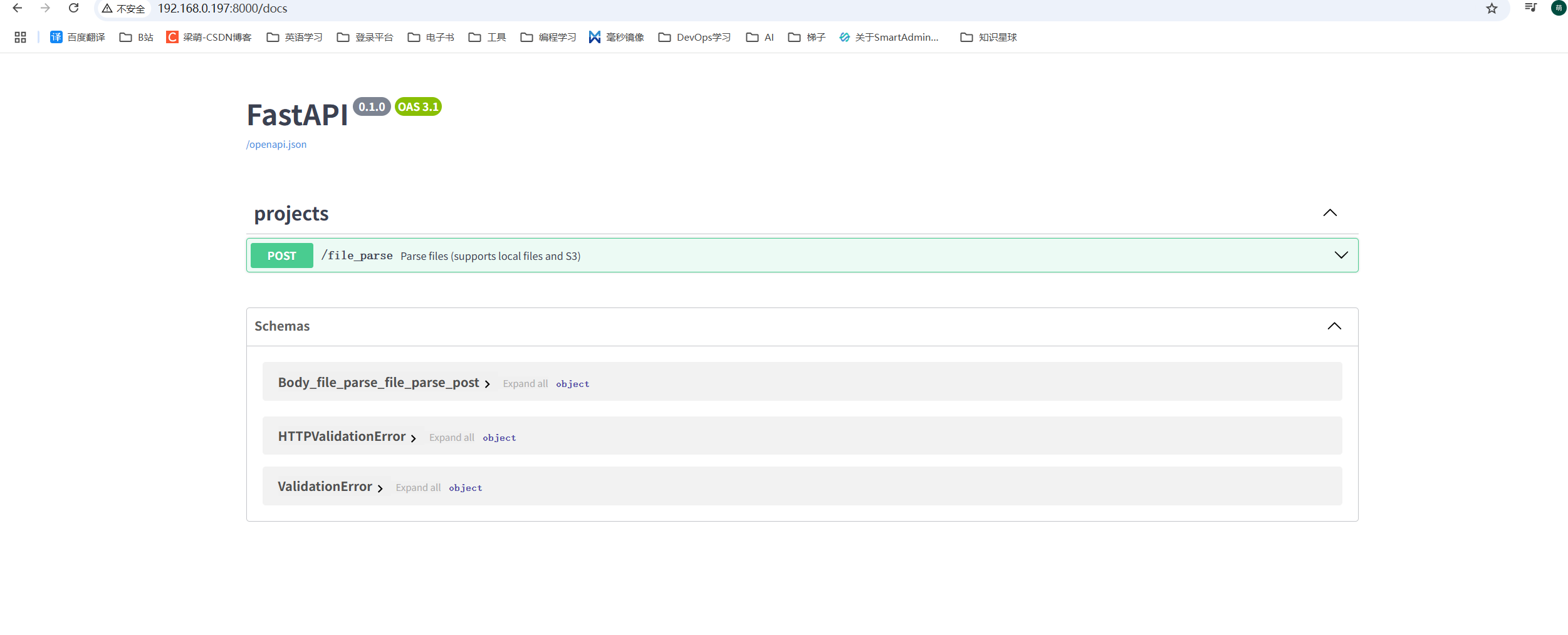
容器启动成功,可以通过浏览器进行访问:
http://localhost:8000/docs
localhost可以改为具体的IP地址
看到这样的 一个页面,就代表mineru的webapi构建成功。
注意:如果是在Windows系统中做上面的操作,会遇到各种问题,尤其是镜像的构建,会出现各种报错,大多数是网络原因,使用科学上网能够解决一部分。
我用了科学上网后,还是有一些报错,比如在拉取大模型时,一直出现拉取失败的情况,无奈我只好把dockerfile中拉取模型的命令先注释掉,然后构建镜像,镜像构建好了之后,在单独下载大模型,然后在镜像启动的命令中,动态把模型的文件加载到容器中。
具体操作如下:
先把dockerfile中这些内容注释,在构建镜像时,不下载模型。
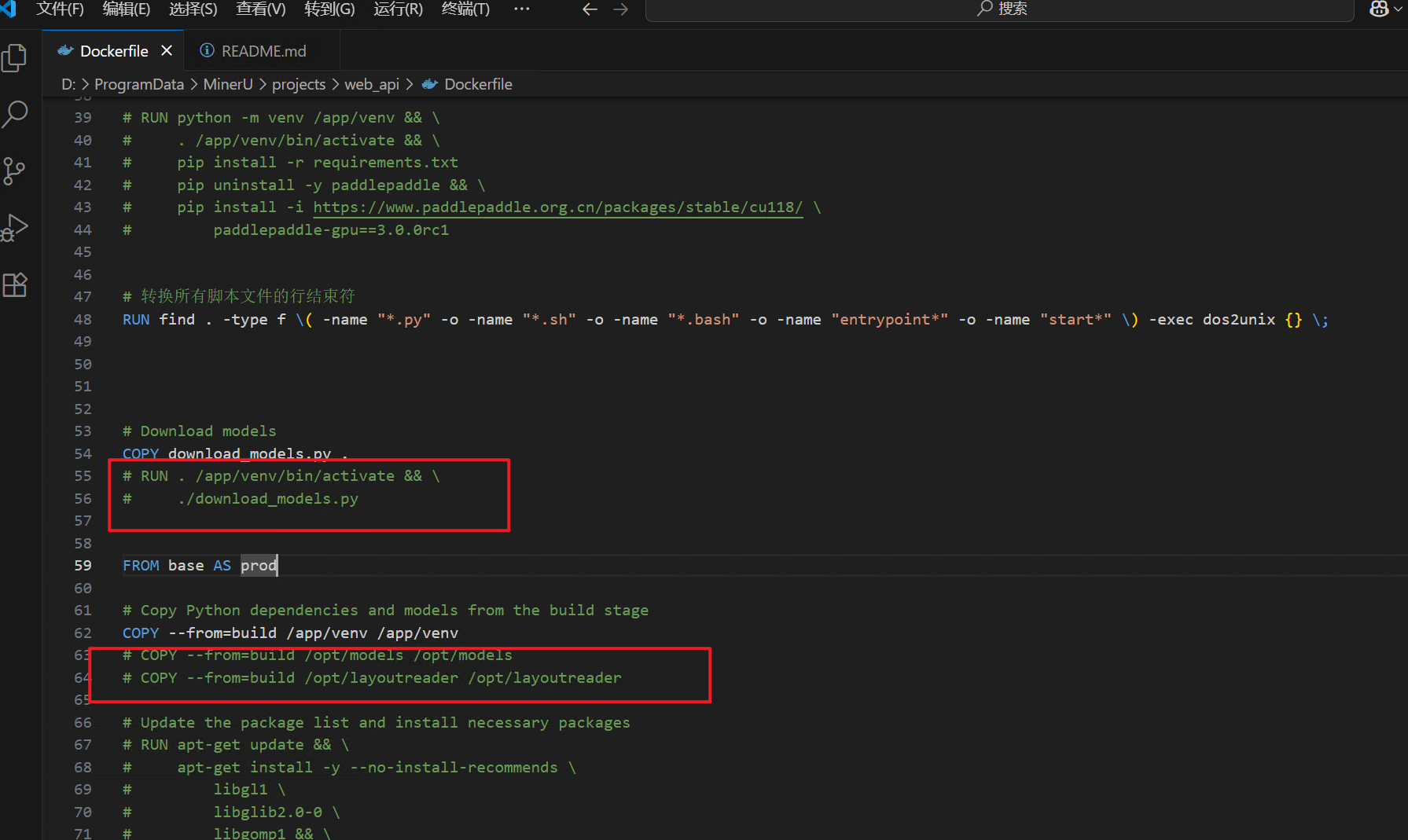
等镜像构建好之后,再下载模型。
下载模型的操作,在web_api目录下面,先创建一个文件 dw_model.py
内容如下
#!/usr/bin/env python
import os
import sys
import time
import shutil
from huggingface_hub import snapshot_download# 设置国内镜像
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'def download_with_retry(repo_id, allow_patterns, local_dir, max_retries=3):"""带重试机制的模型下载"""for attempt in range(max_retries):try:print(f"\n🔄 开始下载 {repo_id} (尝试 {attempt + 1}/{max_retries})")print(f"📁 下载到: {local_dir}")model_dir = snapshot_download(repo_id=repo_id,allow_patterns=allow_patterns,local_dir=local_dir,resume_download=True,local_files_only=False,token=None,)print(f"✅ {repo_id} 下载成功!")print(f"📂 模型目录: {model_dir}")return model_direxcept Exception as e:print(f"❌ 下载失败 (尝试 {attempt + 1}/{max_retries}): {e}")if attempt < max_retries - 1:wait_time = (attempt + 1) * 30print(f"⏳ 等待 {wait_time} 秒后重试...")time.sleep(wait_time)else:print(f"❌ {repo_id} 下载最终失败")raisedef fix_directory_structure(models_dir):"""修复目录结构 - 将 models/models/ 中的文件移动到 models/"""models_subdir = os.path.join(models_dir, "models")if os.path.exists(models_subdir):print(f"\n🔧 修复目录结构...")print(f"📁 发现嵌套的 models 目录: {models_subdir}")# 移动所有文件从 models/models/ 到 models/for item in os.listdir(models_subdir):src = os.path.join(models_subdir, item)dst = os.path.join(models_dir, item)if os.path.exists(dst):if os.path.isdir(dst):print(f"📂 合并目录: {item}")# 如果是目录,合并内容for subitem in os.listdir(src):sub_src = os.path.join(src, subitem)sub_dst = os.path.join(dst, subitem)if os.path.exists(sub_dst):shutil.rmtree(sub_dst)shutil.move(sub_src, sub_dst)else:print(f"📄 覆盖文件: {item}")os.remove(dst)shutil.move(src, dst)else:print(f"📦 移动: {item}")shutil.move(src, dst)# 删除空的 models 子目录os.rmdir(models_subdir)print(f"✅ 目录结构修复完成!")# 验证修复结果print(f"\n📋 修复后的目录结构:")for item in os.listdir(models_dir):item_path = os.path.join(models_dir, item)if os.path.isdir(item_path):print(f" 📂 {item}/")try:subitems = os.listdir(item_path)for subitem in subitems[:3]: # 只显示前3个print(f" - {subitem}")if len(subitems) > 3:print(f" ... 还有 {len(subitems) - 3} 个文件")except:passelse:print(f" 📄 {item}")def check_disk_space(required_gb=10):"""检查磁盘空间"""total, used, free = shutil.disk_usage("./")free_gb = free // (1024**3)print(f"💾 可用磁盘空间: {free_gb} GB")if free_gb < required_gb:print(f"⚠️ 警告: 可用空间不足 {required_gb} GB,可能影响下载")return free_gb >= required_gbif __name__ == "__main__":try:print("🚀 开始下载 MinerU 所需模型...")print("=" * 50)# 检查磁盘空间check_disk_space(15)# 创建本地目录models_dir = "./models"layoutreader_dir = "./layoutreader"os.makedirs(models_dir, exist_ok=True)os.makedirs(layoutreader_dir, exist_ok=True)print(f"\n📦 下载 PDF-Extract-Kit 模型...")model_dir = download_with_retry("opendatalab/PDF-Extract-Kit-1.0",["models/Layout/YOLO/*","models/MFD/YOLO/*", "models/MFR/unimernet_hf_small_2503/*","models/OCR/paddleocr_torch/*",],models_dir)# 修复目录结构fix_directory_structure(models_dir)print(f"\n📦 下载 LayoutReader 模型...")layoutreader_model_dir = download_with_retry("hantian/layoutreader",["*.json", "*.safetensors"],layoutreader_dir)print("\n" + "=" * 50)print("🎉 所有模型下载完成!")print(f"📂 PDF-Extract-Kit 模型: {model_dir}")print(f"📂 LayoutReader 模型: {layoutreader_model_dir}")print("\n✅ 目录结构已修复,现在可以运行 MinerU 了!")print("\n💡 提示: 如果使用 Docker,请确保将 models 目录挂载到容器的 /opt/models")except KeyboardInterrupt:print("\n⚠️ 下载被用户中断")sys.exit(1)except Exception as e:print(f"\n❌ 下载过程中发生错误: {e}")print("💡 建议:")print(" 1. 检查网络连接")print(" 2. 确保有足够的磁盘空间")print(" 3. 尝试使用 VPN 或代理")sys.exit(1) 运行这个文件,用来下载模型
python dw_model.py
如果执行失败,就多执行几次,可能就成功了。
启动镜像的脚本,就改成如下的命令:
docker run -d --restart=always -v D:\ProgramData\MinerU\projects\web_api\models:/opt/models -v D:\ProgramData\MinerU\projects\web_api\layoutreader:/opt/layoutreader -p 8000:8000 --name mineru-api 镜像ID
镜像ID:通过 docker images命令,查询出mineru的镜像ID。
下面这两个路径,要根据自己电脑的路径,进行修改:
D:\ProgramData\MinerU\projects\web_api\models:/opt/models
D:\ProgramData\MinerU\projects\web_api\layoutreader:/opt/layoutreader