探索显著性检测中语义信息的高效模型
摘要
问题一:什么叫做语义信息?
自然语言处理(NLP)中的语义信息:
- 在NLP中,语义信息指的是语言中单词、句子或段落所表达的意义。例如,“猫”和“狗”这两个词在字面上是不同的,但它们都有与动物相关的语义信息。
- 在语法结构和词汇层次上,语义信息是与上下文、语境以及词义之间的联系紧密相关的。例如,“银行”这个词的语义信息可能指代金融机构,也可能指代河岸,具体含义依赖于上下文。
2. 计算机视觉中的语义信息:
- 在计算机视觉中,语义信息指的是图像或视频中所呈现的对象、场景及其关系所代表的意义。例如,一张街道的照片中,图像的语义信息可以是“街道”,“汽车”,“行人”等。
- 语义分割是一个常见的任务,其中的目标是给图像中的每个像素赋予一个语义标签(比如“人”、“车”)。这与物体检测(检测物体的位置)不同,语义分割关注的是图像的“意义”层面。
3. 语义网与知识图谱中的语义信息:
- 在语义网或知识图谱中,语义信息通常表示为通过节点和边连接的知识结构。这些节点表示概念(如人、地点、事件),而边表示它们之间的关系(如“位于”,“属于”,“喜欢”)。
- 语义信息在这里是通过数据的“语义模型”来组织和表达的,用于机器理解复杂的知识和推理。
4. 人工智能中的语义信息:
-
在AI中,语义信息意味着机器能够理解、推理和应用知识,而不仅仅是通过模式匹配来处理数据。例如,AI系统能够从文字、图像或音频中提取出有效的语义信息,理解其背后的意图或情感。
一 引言
二 相关工作
2.1 显著性物体检测
问题一:,基于卷积神经网络的显著性检测模型背后的语义信息以 及预训练的必要性还没有人研究。什么意思?
传统的CNN在显著性检测中主要依赖的是低层次的视觉特征(如边缘、纹理、颜色等),而忽略了图像中的高层次语义信息。这就导致了在一些复杂场景下,显著性检测的效果可能不够理想。
这句话的含义是,现有的研究尚未充分探讨如何在基于卷积神经网络的显著性检测模型中,充分利用图像中的语义信息,以及是否必须通过预训练来提升模型的性能。因此,这些问题仍然是当前显著性检测领域需要进一步研究的方向。
2.2 轻量级模型
问题一:inverted block, channel shuffling , 和 SE attention module 分别是什么模块?
1. Inverted Block (倒置块):
- 概念:Inverted Block 是一种特殊的卷积模块,最早出现在 MobileNetV2中。它的核心思想是将传统的卷积块结构“倒置”过来,以减少计算量和提高模型的效率。
- 工作原理:Inverted Block 通常由以下几个步骤组成:
- 深度可分离卷积:首先,输入经过一个深度卷积(depthwise convolution),该操作对每个通道单独进行卷积。
- 扩展卷积:然后,卷积结果通过一个扩展的卷积(1x1卷积)将通道数量增加。
- 残差连接:这个模块还包括了残差连接(skip connections),即输入和输出通过某种方式相加,以加强梯度的流动,避免梯度消失的问题。
- 优点:这种倒置结构有助于减少模型的参数量和计算量,同时提高了模型的效率。它非常适合于移动端和嵌入式设备上运行。
2. Channel Shuffling (通道重排):
- 概念:Channel Shuffling 是一种通过改变卷积神经网络中通道排列的策略,通常用在 Group Convolution 和一些轻量化模型(如 ShuffleNet)中,来增强模型的表达能力。
- 工作原理:传统卷积网络中,特征通道之间是按照一定顺序排列的,而 Channel Shuffling 则通过打乱或重排列通道顺序,使得不同组的卷积层能够交流信息。它类似于将不同组的通道“打乱”,使得每个卷积层能够接触到来自其他组的特征,增强特征融合的效果。
- 优点:通过通道重排,模型能够减少通道间的“信息隔离”,提升卷积网络的表达能力,同时在保持轻量化的同时提高模型的性能。
3. SE Attention Module (SE注意力模块):
- 概念:SE(Squeeze-and-Excitation)Attention Module 是一种通过显式地对每个通道赋予不同重要性的机制,来增强网络对有意义特征的关注能力。它首次出现在《Squeeze-and-Excitation Networks》论文 [34] 中。
- 工作原理:
- Squeeze:首先,对输入特征图进行全局平均池化,将每个通道的特征压缩成一个单一的数值。
- Excitation:接下来,利用全连接层和激活函数(如ReLU)来学习每个通道的权重系数,从而决定每个通道的激活程度。
- Recalibration:最后,这些权重系数会与原始特征图中的每个通道进行逐通道的乘法操作,从而调整特征图的各个通道的特征响应。
- 优点:SE模块能够显著提高网络的表示能力,通过学习各个通道的重要性,使得网络能够自动地为关键的特征分配更多的注意力,而减少无用信息的影响。
问题二: 什么叫做降采样策略?
降采样是指按照一定的规则或算法,对原始数据进行下采样操作,即减少数据的数量,同时尽可能保留原始数据的关键特征和信息,以便于后续的处理、分析或存储等操作。
常见方法
- 平均池化:在图像处理或卷积神经网络中较为常见。以二维图像为例,将图像划分成多个不重叠的小区域,通常是正方形或矩形区域,然后计算每个小区域内像素值的平均值,用这个平均值来代表该区域的像素值,从而得到降采样后的图像。这样可以在一定程度上减少图像的分辨率,降低数据量,同时保留图像的大致轮廓和主要特征。
- 最大值池化:同样在图像处理和神经网络中常用。也是将图像划分为若干个小区域,取每个小区域内像素值的最大值作为该区域的代表值,完成降采样。最大值池化更侧重于保留图像中的突出特征或边缘信息等,因为它选取的是区域内的最大值,能够突出图像中的一些关键特征点。
- 抽取:按照一定的间隔或规则直接从原始数据中选取部分数据点作为降采样后的数据。例如,在时间序列数据中,每隔一定的时间间隔抽取一个数据点,或者在图像中每隔若干行和列抽取一个像素点,以此来减少数据量。
作用和目的
- 降低数据维度:在数据量非常大的情况下,如高分辨率的图像或长时间的音频信号等,进行降采样可以显著减少数据的规模,降低对存储和计算资源的需求,使后续的处理更加高效。例如在存储大量卫星遥感图像时,降采样可以在不影响对图像主要信息理解的基础上,减少存储空间。
- 减少噪声影响:在一些情况下,数据中的噪声可能是高频成分,而降采样可以在一定程度上过滤掉部分高频噪声,使数据更加平滑,提高数据的稳定性和可靠性。比如在对音频信号进行处理时,适当的降采样可以去除一些高频的杂音。
- 防止过拟合:在机器学习和深度学习中,降采样可以作为一种数据增强或预处理的手段。通过减少数据量,可以降低模型的复杂度,减少模型对训练数据的过拟合风险,提高模型的泛化能力。例如在训练图像识别模型时,对图像进行降采样处理后再输入模型,可以使模型学习到更具一般性的特征。
2.3 网络剪枝
问题一:什么叫做网络剪枝?
网络剪枝是一种模型压缩技术,旨在通过去除神经网络中不必要的连接、神经元或参数,来减少模型的复杂度和计算量,同时尽量保持模型的性能。以下是关于网络剪枝的详细介绍:
主要类型
- 结构化剪枝:这种剪枝方式会剪掉整个神经元、卷积核或网络层等具有一定结构的部分。例如,在卷积神经网络中,可以直接删除一些卷积层或者卷积核,使得网络的结构变得更简单,计算量大幅下降。结构化剪枝后的网络可以方便地在各种计算平台上进行高效部署,因为它可以直接减少网络的层次和参数数量,便于硬件进行并行计算等操作。
- 非结构化剪枝:主要是对神经网络中的连接权重进行剪枝,直接删除那些绝对值较小的权重,而不考虑网络的结构。这种方式可以更精细地对网络进行优化,能够在不明显影响模型性能的前提下,大量减少网络的参数数量。但是非结构化剪枝后的网络在计算时,由于权重的稀疏性,可能需要特殊的存储格式和计算方法来提高计算效率,比如使用稀疏矩阵存储和计算库。
剪枝方法
- 基于权重大小的剪枝:按照权重的绝对值大小来确定是否剪枝。设定一个阈值,将绝对值小于阈值的权重直接置为零,从而实现剪枝。例如,在一个全连接神经网络中,通过遍历所有的权重,将那些小于某个设定值的权重删除,这样可以快速地减少网络中的参数数量。
- 基于重要性得分的剪枝:为每个神经元或连接计算一个重要性得分,根据得分来决定是否剪枝。重要性得分的计算方式可以基于多种因素,如权重的方差、对输出的贡献度等。比如在卷积神经网络中,对于每个卷积核,可以计算其在训练过程中对特征提取的重要性得分,将得分较低的卷积核删除。
- 基于正则化的剪枝:在模型训练过程中,通过添加正则化项来促使一些权重变为零或接近零。例如,L1 正则化可以使权重的绝对值之和最小化,从而使得一些权重趋向于零,实现自动剪枝的效果。这种方式将剪枝与模型训练结合起来,在训练过程中自动优化网络结构。
作用和意义
- 减少计算资源消耗:随着神经网络规模越来越大,对计算资源的需求也急剧增加。网络剪枝可以显著减少模型的参数数量和计算量,使得模型在运行时所需的内存和计算时间大大降低,便于在资源有限的设备上,如移动设备、嵌入式系统等进行部署和运行。
- 提高模型运行速度:剪枝后的网络结构更简单,计算量减少,从而可以提高模型的推理速度,能够更快地给出预测结果。在一些对实时性要求较高的应用场景,如自动驾驶中的目标检测、实时语音识别等,提高模型运行速度至关重要。
- 防止过拟合:过多的参数可能导致模型对训练数据过拟合,泛化能力下降。通过网络剪枝,去除一些不必要的参数,可以降低模型的复杂度,减少过拟合的风险,提高模型在未知数据上的泛化性能,使模型更加稳定和可靠。
三 GOCTCONV与可学习通道数
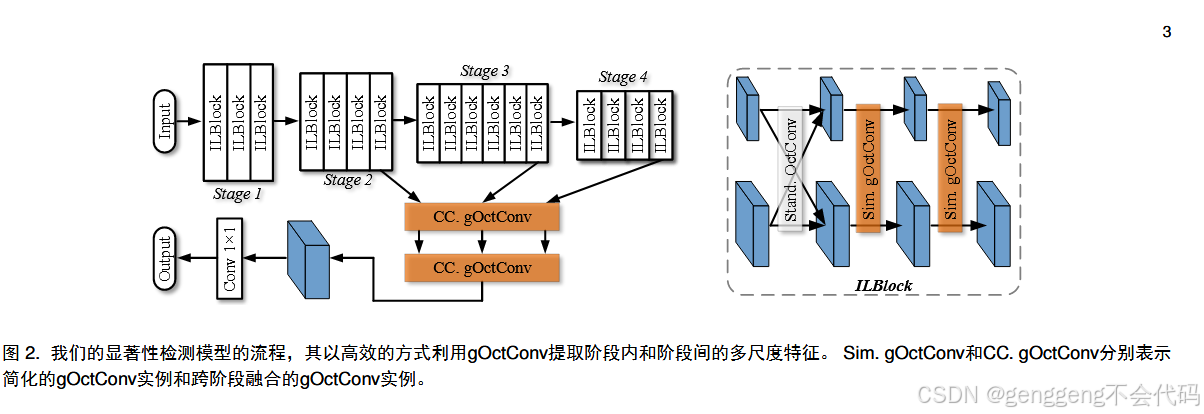
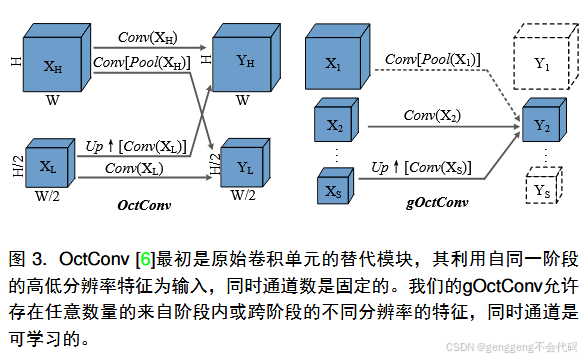
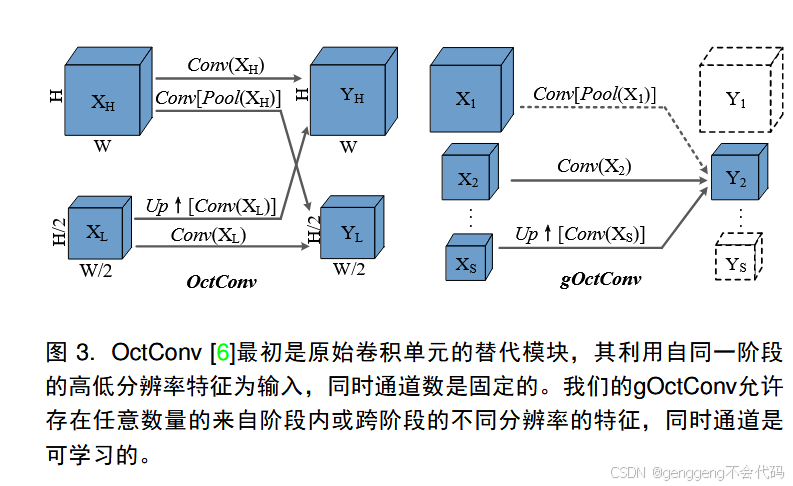
问题一:一 般 化 的Octave卷积(gOctConv)是什么?
一般化的Octave卷积(Generalized Octave Convolution, gOctConv) 是对Octave卷积(OctConv)的扩展,旨在更灵活地处理多尺度特征。OctConv最初用于在卷积神经网络中高效处理高频和低频特征,而gOctConv进一步增强了这一能力,使其适用于更广泛的任务和网络结构。
核心思想
-
多尺度特征表示:OctConv将特征图分为高频和低频两部分,分别处理后再融合。gOctConv扩展了这一概念,支持更多频率分量,适应更复杂的多尺度特征。
-
灵活的频率分组:gOctConv允许动态调整频率分组的数量和比例,根据任务需求优化特征表示。
-
跨频率信息交互:gOctConv增强了不同频率组之间的信息交换,通过改进的卷积操作提升特征融合效果。
主要优势
-
更强的多尺度处理能力:通过增加频率分组,gOctConv能更细致地捕捉图像的多尺度信息。
-
更高的灵活性:动态调整频率分组使gOctConv能适应不同任务和数据集的需求。
-
计算效率:尽管增加了频率分组,gOctConv通过优化卷积操作,保持了较高的计算效率。
3.1 gOctConv
3.2 自适应通道
四 用于研究显著性检测模型语义信息的整体的轻量性模型
4.1 概述
问题一:什么叫做CSNet?
CSNet 是一种专注于 通道和空间特征 的神经网络架构,旨在通过同时优化通道维度和空间维度的特征表示,提升模型在计算机视觉任务(如图像分类、目标检测、语义分割等)中的性能。CSNet 的核心思想是通过 通道注意力机制 和 空间注意力机制 来增强特征提取能力。
核心思想
-
通道维度优化:通过通道注意力机制(Channel Attention)动态调整每个通道的权重,增强重要通道的特征表示。例如,使用 Squeeze-and-Excitation (SE) 模块来学习通道间的依赖关系。
-
空间维度优化:通过空间注意力机制(Spatial Attention)关注特征图中的重要空间区域,增强空间特征表示。例如,使用空间注意力模块来学习特征图中每个位置的重要性。
主要组件
1)通道注意力模块(Channel Attention Module)
-
作用:学习通道间的依赖关系,增强重要通道的特征。
-
实现:
-
对输入特征图进行全局平均池化(Global Average Pooling, GAP),得到通道描述符。
-
通过全连接层(或卷积层)学习通道权重。
-
将学习到的权重应用于原始特征图,增强重要通道的特征。
-
(2)空间注意力模块(Spatial Attention Module)
-
作用:学习空间位置的重要性,增强重要区域的特征。
-
实现:
-
对输入特征图进行通道维度的聚合(如最大池化或平均池化),得到空间描述符。
-
通过卷积层学习空间权重。
-
将学习到的权重应用于原始特征图,增强重要空间区域的特征。
-
(3)通道-空间联合优化
-
将通道注意力模块和空间注意力模块结合起来,同时优化通道和空间维度的特征表示。
-
例如,可以串联或并联两个模块,或者设计更复杂的交互机制。
4.2 层内多尺度模块
问题一:ILblock是什么?
ILBlock 是一种用于显著性检测任务的特征提取模块,其核心思想是通过 层内多尺度特征提取 来增强模型对多尺度信息的表征能力。ILBlock 通常由 gOctConv(Generalized Octave Convolution) 的实例组成,能够同时处理高频和低频特征,从而更好地捕捉图像中的显著性区域。
ILBlock 的设计目标
-
多尺度特征提取:显著性检测任务需要处理不同尺度的目标(如大目标和小目标),因此 ILBlock 通过多尺度卷积操作(如 gOctConv)来提取层内多尺度特征。
-
高效性:ILBlock 的设计简单高效,避免了复杂模块的计算开销,同时保持了对多尺度信息的敏感度。
ILBlock 的核心结构
ILBlock 的核心结构通常包括以下部分:
(1)gOctConv 层
-
作用:gOctConv 是一种改进的 Octave 卷积,能够同时处理高频和低频特征。
-
高频特征:捕捉细节信息(如边缘、纹理)。
-
低频特征:捕捉全局信息(如大目标的结构)。
-
-
优势:通过 gOctConv,ILBlock 能够在单个层内提取多尺度特征,避免了对多分支结构的依赖。
(2)特征融合
-
作用:将 gOctConv 提取的高频和低频特征进行融合,生成丰富的多尺度特征表示。
-
实现方式:可以通过简单的加法或拼接操作将高频和低频特征结合起来。
(3)非线性激活函数
-
作用:在 gOctConv 和特征融合之后,使用非线性激活函数(如 ReLU)增强模型的表达能力。
ILBlock 的工作流程
-
输入特征图:接收来自上一层的特征图。
-
gOctConv 提取多尺度特征:使用 gOctConv 同时提取高频和低频特征。
-
特征融合:将高频和低频特征融合,生成多尺度特征表示。
-
非线性激活:对融合后的特征应用激活函数,增强非线性表达能力。
-
输出特征图:将处理后的特征图传递到下一层。
4.3 跨阶段融合
4.4 CSNet的实现细节
五 分析显著性检测模型
5.1 类别敏感性
5.1.1 数据准备
数据集:DUTS-TR [74],DUTS-TE [74] 和ECSSD [86]作为源数据集
5.1.2 从显著性模型迁移到分类模型
5.1.3 当显著性模型遇上未知类别
5.2 模型复杂度
我们提出的gOctConv配合动态权 重衰减机制可以消除冗余的参数,我们可以对每一个任务的 模型复杂性有清晰的认识。
5.3 提取器需要的特征
5.4 ImageNet预训练
六 分析与消融
6.1 实现
数据集:DUTS-TR [74]数据集训练我们的模型,并且在ECSSD [86], PASCAL-S [48], DUT-O [87], HKU-IS [43], SOD [64], 和DUTS-TE [74]数据集上测试我们的模型
评价指标:我们使用maximum F-measure (Fβ) [1] 和 MAE (M ) [11] 作为我们的评价指标。
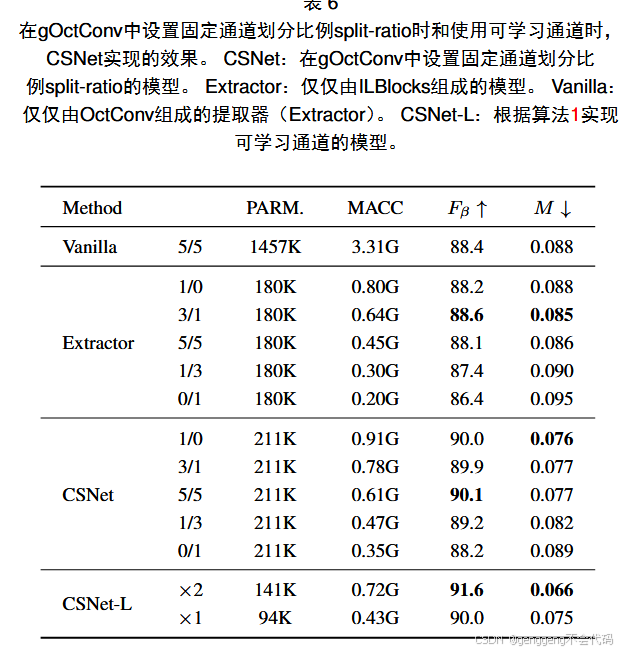
6.2 性能分析
通道固定时的CSNet
利用可学习通道的CSNet
与轻量模型的比较
运行时间
6.3 消融
动态权重衰减
固定的剪枝率/阈值
将动态权重衰减机制集成进剪枝算法
剪枝率 & 通道宽度