解锁C++性能密码:TCMalloc深度剖析
在当今数字化时代,软件应用的复杂度与日俱增,对性能的要求也愈发严苛。C++ 作为一门强大的编程语言,凭借其高效的执行效率、灵活的内存管理以及对硬件资源的直接操控能力,在大型项目开发、系统软件编写、游戏开发、人工智能等众多关键领域占据着举足轻重的地位。比如,在大型游戏开发中,像《使命召唤》《绝地求生》这些知名游戏,其核心引擎部分大量运用 C++ 编写,以实现逼真的画面渲染、流畅的游戏体验和高效的资源利用;在操作系统领域,Windows、Linux 等主流操作系统的内核也离不开 C++ 的支持,确保系统对硬件的精准控制和稳定运行。
然而,随着项目规模的不断扩大和功能的日益丰富,C++ 程序也面临着性能瓶颈的挑战。性能不佳的 C++ 程序,可能会导致系统响应迟缓,比如在金融交易系统中,每一次交易指令的处理都对时间极为敏感,若程序性能不足,交易延迟可能会造成巨大的经济损失;也可能会消耗过多的硬件资源,以服务器端程序为例,高资源消耗会增加运营成本,降低服务器的并发处理能力。
因此,对 C++ 程序进行性能优化显得尤为重要。它不仅能够显著提升程序的运行效率,让软件在有限的硬件条件下发挥出最大效能,还能有效降低资源消耗,节省硬件成本,增强软件的稳定性和可靠性,为用户带来更优质的使用体验 ,从而在激烈的市场竞争中脱颖而出。
一、传统内存管理的困境
在 C++ 的编程世界里,传统的内存管理方式主要依赖于new、delete、malloc和free 这几个关键的操作符与函数。new和delete是 C++ 中用于动态内存分配与释放的操作符,其中new会在堆上为对象分配内存,并调用对象的构造函数进行初始化;delete则相反,它会调用对象的析构函数清理资源,然后释放对象所占用的内存空间。例如:
int* ptr1 = new int; // 动态分配一个int类型空间
delete ptr1; // 释放ptr1指向的内存空间class MyClass {
public:MyClass() { /* 构造函数 */ }~MyClass() { /* 析构函数 */ }
};
MyClass* ptr2 = new MyClass; // 动态分配一个MyClass类型的对象
delete ptr2; // 释放ptr2指向的MyClass对象的内存空间而malloc和free是 C 语言中就存在的内存管理函数,malloc用于在堆上分配指定字节数的内存空间,但它不会对分配的内存进行初始化;free则用于释放malloc分配的内存空间。在 C++ 中,malloc分配的内存也可以用free释放,不过在处理自定义类型时,malloc和free不会调用构造函数和析构函数。例如:
int* ptr3 = (int*)malloc(sizeof(int)); // 分配一个int类型大小的内存空间
free(ptr3); // 释放ptr3指向的内存空间MyClass* ptr4 = (MyClass*)malloc(sizeof(MyClass)); // 分配一个MyClass类型大小的内存空间,但未初始化
// 这里ptr4指向的内存空间未调用构造函数,使用时可能出错
free(ptr4); // 释放ptr4指向的内存空间,但未调用析构函数,可能导致资源泄漏在程序进行少量且不频繁的内存操作时,这些传统的内存管理方式能够正常工作,满足基本的内存分配与释放需求。然而,一旦程序进入高频次的内存分配与释放场景,它们的弊端便会逐渐暴露出来,其中最为突出的问题便是内存碎片的产生和内存分配效率的低下 。
随着程序不断地进行内存的分配与释放操作,内存空间会逐渐被分割成许多不连续的小块。这些小块就如同零散分布的拼图碎片,单独来看,每一块都难以满足较大内存分配的需求,从而形成了内存碎片。内存碎片又可细分为内部碎片和外部碎片。内部碎片是指已分配给某个对象的内存中,存在未被该对象完全使用的部分。比如,使用固定大小的内存块分配策略时,如果对象实际所需内存小于分配的块大小,就会产生内部碎片。外部碎片则是指内存中存在许多不连续的小空闲块,这些空闲块由于不连续,无法被有效地利用来满足较大的内存分配请求。
内存碎片的存在,会极大地降低内存的利用率。因为即使系统中剩余的空闲内存总量足够,但由于这些内存以碎片的形式存在,程序在需要分配较大连续内存块时,可能会因为找不到足够大的连续空闲内存而失败,导致程序无法正常运行。同时,内存碎片还会显著增加内存分配和释放操作的时间开销。当程序请求分配内存时,内存管理系统需要花费更多的时间去遍历内存空间,寻找合适的空闲内存块;而在释放内存时,也需要进行额外的操作,尝试合并相邻的空闲块,以减少碎片的产生。这些额外的操作无疑会拖慢程序的运行速度,降低程序的整体性能。
以一个实时图像处理程序为例,在图像的读取、处理和显示过程中,需要频繁地分配和释放内存来存储图像数据、中间计算结果等。如果采用传统的内存管理方式,随着程序的长时间运行,内存碎片会不断积累。当内存碎片达到一定程度后,程序在分配用于存储高分辨率图像数据的连续内存块时,可能会频繁失败,导致图像加载缓慢、处理卡顿甚至程序崩溃。据相关测试数据显示,在一个模拟的频繁内存操作场景中,使用传统内存管理方式运行一段时间后,内存分配时间平均增加了 30% - 50%,内存利用率下降了 20% - 30%,严重影响了程序的性能和稳定性。
二、TCMalloc闪亮登场
2.1 TCMalloc 是什么
在众多的 C++ 性能优化工具中,TCMalloc 就像是一颗璀璨的明星,闪耀着独特的光芒。TCMalloc,全称 Thread-Caching Malloc,即线程缓存的 malloc,是 Google 开发的一款极具创新性的内存分配算法库 。它最初作为 Google 性能工具库 gperftools 的一部分,横空出世,旨在为多线程环境下的内存管理提供高效的解决方案,用于替代操作系统原生的内存分配函数,如malloc、free、new、new[]等。
TCMalloc 之所以备受瞩目,是因为它具备一系列卓越的特性。它能够显著减少内存碎片的产生,就像一位心灵手巧的工匠,将内存空间精心地规划和利用,使得每一块内存都能物尽其用,大大提高了内存的利用率。同时,TCMalloc 对多核处理器有着天然的亲和力,能够充分发挥多核的优势,为并行计算提供强大的支持。在多线程并发的场景中,它表现得尤为出色,极大地减少了线程之间的锁竞争,就像一位经验丰富的交通指挥员,让各个线程在内存分配的 “道路” 上有序通行,避免了交通堵塞,从而显著提升了内存分配的速度和效率。 比如在 Chrome 浏览器中,大量的页面渲染、脚本执行等任务都是多线程并发进行的,TCMalloc 的使用使得浏览器在处理这些复杂任务时,能够高效地管理内存,避免因内存问题导致的卡顿和崩溃,为用户带来流畅的浏览体验。
2.2 TCMalloc与传统内存管理对比
与传统的内存管理方式相比,TCMalloc 在多个关键方面展现出了压倒性的优势,就如同现代的高速列车与古老的蒸汽火车,在性能上有着天壤之别。
在速度方面,TCMalloc 堪称 “闪电侠”。相关测试数据显示,在 2GHz 的 CPU 上,当进行 256K 字节的内存分配和释放操作时,传统的基于 glibc 实现的 ptmalloc2 需要耗时 32 纳秒,而 TCMalloc 仅需 10 纳秒,速度提升超过了 3 倍。这就好比在一场短跑比赛中,传统内存管理方式还在慢悠悠地起跑,TCMalloc 已经如离弦之箭般冲过了终点。
在多线程环境下,这种速度优势更加明显。当线程数增加到 40 个时,进行同样的内存操作,ptmalloc2 的耗时从 32 纳秒飙升到 137 纳秒,增长了 3 倍以上;而 TCMalloc 只是从 10 纳秒上升到 25 纳秒,仅增长了 1.5 倍 。随着线程数量的进一步增加,ptmalloc2 的性能急剧下降,而 TCMalloc 依然能够保持相对稳定的速度,展现出强大的性能优势。
在内存利用率上,TCMalloc 同样表现出色。传统内存管理方式在频繁的内存分配和释放过程中,容易产生大量的内存碎片,就像一堆杂乱无章的拼图碎片,难以拼凑出完整的图案。而 TCMalloc 通过其独特的内存管理算法,对内存进行精细的划分和管理,能够有效地减少内存碎片的产生。例如,对于小对象的分配,TCMalloc 采用了线程本地缓存和中央缓存相结合的方式,使得小对象的分配和释放更加高效,减少了内存碎片的产生。据统计,在一些模拟的频繁内存操作场景中,使用传统内存管理方式,内存利用率可能会下降到 70% 以下,而使用 TCMalloc,内存利用率可以保持在 90% 以上,大大提高了内存的使用效率。
在多线程支持方面,TCMalloc 更是一骑绝尘。传统的内存管理方式在多线程环境下,由于线程之间对内存资源的竞争,往往需要频繁地加锁和解锁,这就像在一条狭窄的道路上,车辆需要频繁地停车等待,严重影响了交通的流畅性。而 TCMalloc 为每个线程分配了独立的局部缓存,对于小对象的分配,可以直接由线程局部缓存来完成,无需加锁,大大减少了锁竞争带来的开销。
对于大对象的分配,TCMalloc 则采用了细粒度、高效的自旋锁,进一步减少了多线程的锁竞争问题。以一个多线程的服务器程序为例,在高并发的情况下,使用传统内存管理方式,由于锁竞争的存在,服务器的吞吐量可能会受到严重限制;而使用 TCMalloc 后,服务器的吞吐量可以提高数倍,能够更好地应对大量的并发请求。
三、TCMalloc系统架构
3.1TCMalloc架构详解
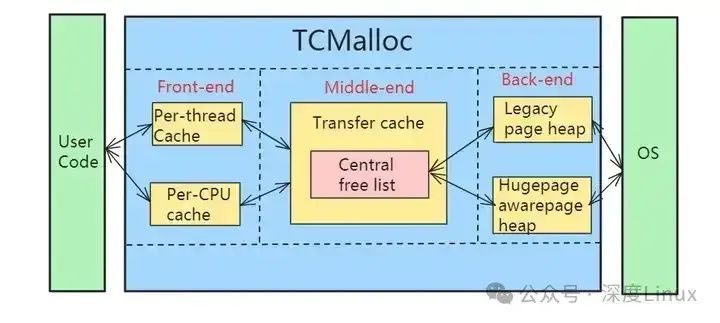
Front-end(前端):负责提供快速分配和重分配内存给应用,由Per-thread cache和Per-CPU cache两部分组成。
Middle-end(中台):负责给Front-end提供缓存。当Front-end缓存内存不够用时,从Middle-end申请内存。
Back-end(后端):负责从操作系统获取内存,并给Middle-end提供缓存使用。
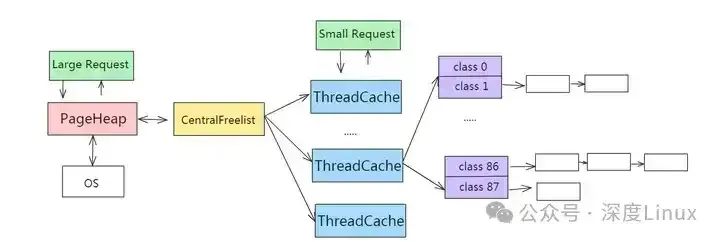
TCMalloc中每个线程都有独立的线程缓存ThreadCache,线程的内存分配请求会向ThreadCache申请,ThreadCache内存不够用会向CentralCache申请,CentralCache内存不够用时会向PageHeap申请,PageHeap不够用就会向OS操作系统申请。
TCMalloc将整个虚拟内存空间划分为n个同等大小的Page,将n个连续的page连接在一起组成一个Span;PageHeap向OS申请内存,申请的span可能只有一个page,也可能有n个page。
⑴Page
Page是操作系统对内存管理的单位,TCMalloc中以Page为单位管理内存,Page默认大小为8KB,通常为Linux系统中Page大小的倍数关系,如8、32、64,可以在编译选项配置时通过--with-tcmalloc-pagesize参数指定。
Page越大,TCMalloc的速度相对越快,但其占用的内存也会越高。默认Page大小通过减少内存碎片来最小化内存使用,使用更大的Page则会带来更多的内存碎片,但速度上会有所提升。
⑵Span
Span是PageHeap中管理内存Page的单位,由一个或多个连续的Page组成,比如2个Page组成的span,多个span使用链表来管理,TCMalloc以Span为单位向操作系统申请内存。
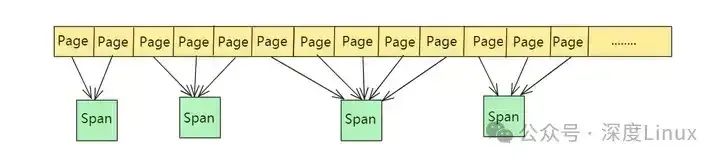
第1个span包含2个page,第2个和第4个span包含3个page,第3个span包含5个page。
Span会记录起始page的PageID(start)以及所包含page的数量(length)。
Span要么被拆分成多个相同size class的小对象用于小对象分配,要么作为一个整体用于中对象或大对象分配。当作用作小对象分配时,span的sizeclass成员变量记录了其对应的size class。
span中包含两个Span类型的指针(prev,next),用于将多个span以链表的形式存储。
Span有三种状态:IN_USE、ON_NORMAL_FREELIST、ON_RETURNED_FREELIST。
IN_USE是正在使用中,要么被拆分成小对象分配给CentralCache或者ThreadCache,要么已经分配给应用程序。
ON_NORMAL_FREELIST是空闲状态。
ON_RETURNED_FREELIST指span对应的内存已经被PageHeap释放给系统。
⑶ThreadCache
ThreadCache是每个线程独立拥有的Cache,包含多个空闲内存链表(size classes),每一个链表(size-class)都有大小相同的object。
线程可以从各自Thread Cache的FreeList获取对象,不需要加锁,所以速度很快。如果ThreadCache的FreeList为空,需要从CentralCache中的CentralFreeList中获取若干个object到ThreadCache对应的size class列表中,然后再取出其中一个object返回。
⑷Size Class
TCMalloc定义了很多个size class,每个size class都维护了一个可分配的FreeList,FreeList中的每一项称为一个object,同一个size-class的FreeList中每个object大小相同。
在申请小内存时(小于256K),TCMalloc会根据申请内存大小映射到某个size-class中。比如,申请0到8个字节的大小时,会被映射到size-class1中,分配8个字节大小;申请9到16字节大小时,会被映射到size-class2中,分配16个字节大小,以此类推。
⑸CentralCache
CentralCache是ThreadCache的缓存,ThreadCache内存不足时会向CentralCache申请。CentralCache本质是一组CentralFreeList,链表数量和ThreadCache数量相同。ThreadCache中内存过多时,可以放回CentralCache中。
如果CentralFreeList中的object不够,CentralFreeList会向PageHeap申请一连串由Span组成的Page,并将申请的Page切割成一系列的object后,再将部分object转移给ThreadCache。当申请的内存大于256K时,不再通过ThreadCache分配,而是通过PageHeap直接分配大内存。
⑹PageHeap
PageHeap保存存储Span的若干链表,CentralCache内存不足时,可以从PageHeap获取Span,然后把Span切割成object。
PageHeap申请内存时按照Page申请,但管理内存的基本单位是Span,Span代表若干连续Page。
3.2Front-end
Front-end处理对特定大小内存的请求,有一个内存缓存用于分配或保存空闲内存。Front-end缓存一次只能由单个线程访问,不需要任何锁,因此大多数分配和释放都很快。
只要有适当大小的缓存内存,Front-end将满足任何请求。如果特定大小的缓存为空,Front-end将从Middle-end请求一批内存来填充缓存。Middle-end包括CentralfReelList和TransferCache。
如果Middle-end内存耗尽,或者用户请求的内存大小大于Front-end缓存的最大值,则请求将转到Back-end,以满足大块内存分配,或重新填充Middle-end的缓存。Back-end也称为PageHeap。
Front-end由两种不同的实现模式:
Per-thread:TCMalloc最初支持对象的Per-thread缓存,但会导致内存占用随着线程数增加而增加。现代应用程序可能有大量的线程,会导致每个线程占用内存累积起来很大,也可能会导致由单个较小线程缓存累积起来的内存占用会很大。
Per-CPU:TCMalloc近期开始支持Per-CPU模式。在Per-CPU模式下,系统中的每个逻辑CPU都有自己的缓存,可以从中分配内存。在x86架构,逻辑CPU相当于一个超线程。
3.3Middle-end
Middle-end负责向Front-end提供内存并将内存返回Back-end。Middle-end由Transfer cache和Central free list组成,每个类大小都有一个Transfer cache和一个Central free list。缓存由互斥锁保护,因此访问缓存会产生串行化成本。
⑴Transfer cache
当Front-end请求内存或返回内存时,将访问Transfer cache。
Transfer cache保存一个指向空闲内存的指针数组,可以快速地将对象移动到数组中,或者代表Front-end从数组中获取对象。
当一个线程正在分配另一个线程释放的内存时,Transfer cache就可以得到内存名称。Transfer cache允许内存在两个不同的线程之间快速流动。
如果Transfer cache无法满足内存请求,或者没有足够的空间容纳返回的对象,Transfer cache将访问Central free list。
⑵Central Free List
Central Free List使用spans管理内存,span是一个或多个TCMalloc内存Page的集合。
一个或多个对象的内存请求由Central Free List来满足,方法是从span中提取对象,直到满足请求为止。如果span中没有足够的可用对象,则会从Back-end请求更多的span。
当对象返回到Central Free List时,每个对象都映射到其所属的span(使用pagemap,然后释放到span中)。如果驻留在指定span中的所有对象都返回给span,则整个span将返回给Back-end。
3.4Back-end
TCMalloc中Back-end有三项职责:
管理大量未使用的内存块。
负责在没有合适大小的内存来满足分配请求时从操作系统获取内存。
负责将不需要的内存返回给操作系统。
TCMalloc有两种Back-end:
(1)Legacy Pageheap,管理TCMalloc中Page大小的内存块。Legacy Pageheap是一个可用内存连续页面的特定长度的空闲列表数组。对于k<256,kth条目是由k个TCMalloc页组成的运行的免费列表。第256项是长度大于等于256页的运行的免费列表
(2)支持hugepage的pageheap,以hugepage大小的内存块来管理内存。管理hugepage内存块中内存,使分配器能够通过减少TLB未命中率来提高应用程序性能。
四、TCMalloc核心工作原理
TCMalloc 之所以能够在性能上实现如此大的飞跃,背后离不开其精妙绝伦的工作原理,就像一台精密的仪器,每一个部件都发挥着不可或缺的作用。接下来,让我们深入 TCMalloc 的内部,一探究竟。
4.1三级缓存架构解析
TCMalloc 采用了一种极具创新性的三级缓存架构,这种架构就像是一个精心构建的金字塔,每一层都承担着独特的职责,共同协作以实现高效的内存管理 。这三级缓存分别是 ThreadCache(线程缓存)、CentralCache(中央缓存)和 PageHeap(页堆)。
ThreadCache 位于金字塔的顶端,是每个线程私有的缓存。它就像是线程的专属 “小仓库”,里面存放着各种小对象。当线程需要分配内存时,首先会到这个 “小仓库” 中寻找。由于 ThreadCache 是线程私有的,线程在访问它时无需加锁,这就大大提高了内存分配的速度,就像在自己家里找东西一样方便快捷。例如,在一个多线程的网络服务器程序中,每个线程在处理网络请求时,可能会频繁地分配和释放一些小的内存块,用于存储请求数据、响应数据等。如果使用传统的内存管理方式,线程之间会因为争夺内存资源而频繁加锁,导致性能下降。而有了 ThreadCache,每个线程可以直接从自己的缓存中获取内存,避免了锁竞争,大大提高了处理请求的效率。
当 ThreadCache 中的内存不足时,就会向 CentralCache 发出求助信号。CentralCache 是所有线程共享的缓存,它就像是一个 “大型超市”,为各个线程提供内存补给。CentralCache 通过自旋锁来保护数据的一致性,虽然需要加锁,但由于它主要负责补充 ThreadCache 的内存,而不是直接处理大量的内存分配请求,所以锁竞争的情况相对较少。当 ThreadCache 向 CentralCache 申请内存时,CentralCache 会从自己的空闲内存列表中取出一部分内存,批量地提供给 ThreadCache。
如果 CentralCache 也无法满足内存需求,那么就轮到 PageHeap 登场了。PageHeap 是 TCMalloc 与操作系统内存交互的接口,它直接从操作系统的堆中获取内存,就像是从 “总仓库” 中提货。PageHeap 管理着大块的内存,这些内存以页(Page)为单位进行分配和管理。当 PageHeap 收到内存请求时,它会根据请求的大小,从自己管理的内存中找到合适的内存块分配出去。如果 PageHeap 中没有足够的空闲内存,它就会向操作系统申请更多的内存。
4.2内存管理单元:Page 与 Span
在 TCMalloc 的内存管理体系中,Page 和 Span 是两个非常重要的概念,它们就像是构建内存大厦的基石和砖块。
Page 是 TCMalloc 内存管理的基本单位,默认大小为 8KB ,通常与 Linux 系统中 Page 大小保持倍数关系,如 8、32、64 等,这个大小可以在编译选项配置时通过--with-tcmalloc-pagesize参数指定。Page 就像是一个个整齐排列的小房间,内存空间被划分为无数个这样的小房间,每个房间都有一个唯一的编号,即 PageID,由虚拟内存地址直接转换而得。Page 的大小对 TCMalloc 的性能有着重要影响。较小的 Page 可以减少内存碎片的产生,提高内存利用率,但在分配大对象时,可能需要多个 Page,增加了管理的复杂性;较大的 Page 则可以提高分配大对象的效率,但可能会产生更多的内存碎片。
Span 则是由一个或多个连续的 Page 组成的内存块,它就像是由多个小房间组成的一个大套间。Span 会记录起始 Page 的 PageID(start)以及所包含 Page 的数量(length) 。例如,一个 Span 可能由 2 个连续的 Page 组成,那么它的 start 就是第一个 Page 的 PageID,length 为 2。Span 有三种状态:IN_USE、ON_NORMAL_FREELIST、ON_RETURNED_FREELIST 。
IN_USE 表示该 Span 正在被使用,要么被拆分成小对象分配给 CentralCache 或者 ThreadCache,要么已经分配给应用程序;ON_NORMAL_FREELIST 表示该 Span 处于空闲状态,可以被重新分配使用;ON_RETURNED_FREELIST 表示该 Span 对应的内存已经被 PageHeap 释放给系统,但在某些情况下,可能还会被重新利用。Span 在 TCMalloc 的内存管理中起着关键作用,它是内存分配和回收的基本单元,通过对 Span 的有效管理,TCMalloc 能够实现高效的内存分配和回收。
4.3小对象与大对象的不同待遇
TCMalloc 根据对象的大小,将内存分配分为小对象分配和大对象分配两种情况,并且为它们提供了不同的分配策略,就像对待不同级别的客户,给予不同的服务。
对于小对象(<=32KB) ,TCMalloc 主要通过线程缓存 ThreadCache 来进行分配 。ThreadCache 中维护着多个空闲内存链表(FreeList),每个链表对应一种大小的小对象。当线程需要分配小对象时,首先会根据对象的大小找到对应的 FreeList,如果该链表中有空闲的内存块,就直接从链表中取出一块返回给线程,这个过程是无锁的,速度非常快。
如果 FreeList 为空,线程会从 CentralCache 中申请一批相同大小的小对象,填充到自己的 FreeList 中,然后再进行分配。例如,在一个图像处理程序中,可能会频繁地分配和释放一些小的图像数据块,这些数据块的大小通常在 32KB 以内。使用 TCMalloc 时,这些小对象的分配和释放可以在 ThreadCache 中高效地完成,大大提高了图像处理的速度。
而对于大对象(>32KB) ,TCMalloc 则直接从 PageHeap 中以页为单位进行分配 。由于大对象的大小超过了 ThreadCache 的管理范围,所以需要从 PageHeap 这个 “大仓库” 中获取内存。PageHeap 会根据大对象的大小,找到合适的 Span 进行分配。
如果没有合适大小的 Span,PageHeap 会向操作系统申请更多的内存,然后将新申请的内存划分为合适的 Span 进行分配。在释放大对象时,PageHeap 会检查相邻的 Span,如果相邻的 Span 是空闲的,则会将它们合并成一个更大的 Span,以减少内存碎片的产生。比如在一个大数据处理程序中,可能需要分配一些较大的内存块来存储中间计算结果,这些大对象就会由 PageHeap 直接分配,确保程序能够高效地处理大量的数据。
五、TCMalloc的使用方法
5.1TCMalloc安装
①TCMalloc源码安装
bazel源增加:
/etc/yum.repos.d/bazel.repo
[copr:copr.fedorainfracloud.org:vbatts:bazel]
name=Copr repo for bazel owned by vbatts
baseurl=https://download.copr.fedorainfracloud.org/results/vbatts/bazel/epel-7-$basearch/
type=rpm-md
skip_if_unavailable=True
gpgcheck=1
gpgkey=https://download.copr.fedorainfracloud.org/results/vbatts/bazel/pubkey.gpg
repo_gpgcheck=0
enabled=1
enabled_metadata=1在线安装bazel:
yum install bazel3TCMalloc源码下载:
git clone https://github.com/google/tcmalloc.git
cd tcmalloc && bazel test //tcmalloc/...由于TCMalloc依赖gcc 9.2+,clang 9.0+: -std=c++17,因此推荐使用其它方式安装。
②gperftools源码安装
gperftools源码下载:
git clone https://github.com/gperftools/gperftools.git生成构建工具:
autogen.sh配置编译选项:
configure --disable-debugalloc --enable-minimal编译:make -j4
安装:make install
TCMalloc库安装在/usr/local/lib目录下。
③在线安装
epel源安装:
yum install -y epel-releasegperftools安装:
yum install -y gperftools.x86_645.2Linux64位系统支持
在Linux64位系统环境下,gperftools使用glibc内置的stack-unwinder可能会引发死锁,因此官方推荐在配置和安装gperftools前,先安装libunwind-0.99-beta。
在Linux64位系统上使用libunwind只能使用TCMalloc,但heap-checker、heap-profiler和cpu-profiler不能正常使用。
如果不希望安装libunwind,也可以用gperftools内置的stack unwinder,但需要应用程序、TCMalloc库、系统库(比如libc)在编译时开启帧指针(frame pointer)选项。
在x86-64下,编译时开启帧指针选项并不是默认行为。因此需要指定-fno-omit-frame-pointer编译所有应用程序,然后在configure时通过--enable-frame-pointers选项使用内置的gperftools stack unwinder。
5.3基本使用示例
在 C++ 代码中引入 TCMalloc 非常简单。只需在编译时链接 TCMalloc 库即可。例如,使用 GCC 编译器时,编译命令为g++ -o my_program my_program.cpp -ltcmalloc。下面是一个简单的代码示例:
#include <iostream>
#include <stdlib.h>int main() {void* ptr = malloc(1024);if (ptr) {// 使用分配的内存free(ptr);}return 0;
}在上述代码中,虽然使用的是标准的malloc和free函数,但由于链接了 TCMalloc 库,实际的内存分配和释放操作将由 TCMalloc 完成,从而提升程序的性能 。
4.4配置与调优
TCMalloc 提供了丰富的配置选项,可通过环境变量进行设置。例如,TCMALLOC_RELEASE_RATE环境变量用于控制 TCMalloc 将未使用的内存归还给操作系统的频率。默认值为 1.0,表示 TCMalloc 会积极地将未使用的内存归还给操作系统。若将其设置为 0,则 TCMalloc 不会主动归还内存,适用于内存使用量波动较大的程序 。
还可以通过TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES环境变量来限制所有线程缓存的总大小。合理调整这些环境变量的值,能够根据程序的具体需求对 TCMalloc 进行优化,进一步提升程序的性能 。