深度解析Linux文件I/O三级缓冲体系:用户缓冲区→标准I/O→内核页缓存
在Linux文件I/O操作中,缓冲区的管理是一个核心概念,主要涉及用户空间缓冲区和内核空间缓冲区。理解这两者的区别和工作原理对于高效的文件操作至关重要。
目录
一、什么是缓冲区
二、为什么要引入缓冲区机制
三、三级缓冲体系
1、三级缓冲体系全景图
2、各级缓冲区的关键特性对比(重要!!!)
3、数据流动的详细机制
阶段1:应用缓冲区 → 标准I/O缓冲区
阶段2:标准I/O缓冲区 → 内核缓冲区
阶段3:内核缓冲区 → 物理存储
四、用户空间缓冲区
特点:
示例:
1. 文件打开
2. 用户缓冲区声明
3. 数据写入
4. 文件关闭
关键点说明
关键补充(重点!!!):
可视化流程
五、内核空间缓冲区
特点:
相关系统调用:
1. open() 系统调用
2. write() 系统调用
3. fsync() 系统调用
4. close() 系统调用
总结:数据流向
应用场景
扩展知识
两者协作流程
六、缓冲区的层级关系
七、缓冲模式对比
八、性能优化考虑
九、实际应用建议
一、什么是缓冲区
缓冲区是内存空间中预留的一部分存储空间,用于暂存输入或输出的数据。根据其对应的设备类型,缓冲区可分为输入缓冲区和输出缓冲区。
二、为什么要引入缓冲区机制
直接通过系统调用对磁盘进行读写操作时,每次操作都需要执行一次系统调用,这会导致CPU频繁地在用户空间和内核空间之间切换,消耗大量CPU时间,严重影响程序执行效率。
采用缓冲区机制可以有效减少系统调用次数。例如:
- 从磁盘读取数据时,可以一次性读取大量数据到缓冲区,后续访问直接从缓冲区读取,减少磁盘操作次数
- 计算机对缓冲区的操作速度远快于磁盘操作,因此使用缓冲区能显著提高运行速度
- 打印机操作时,数据先输出到打印机缓冲区,使CPU可以处理其他任务
缓冲区本质上是一块位于输入输出设备与CPU之间的内存区域,它协调了低速设备与高速CPU之间的工作节奏,避免了低速设备占用CPU资源,从而提升CPU的工作效率。
三、三级缓冲体系
1、三级缓冲体系全景图
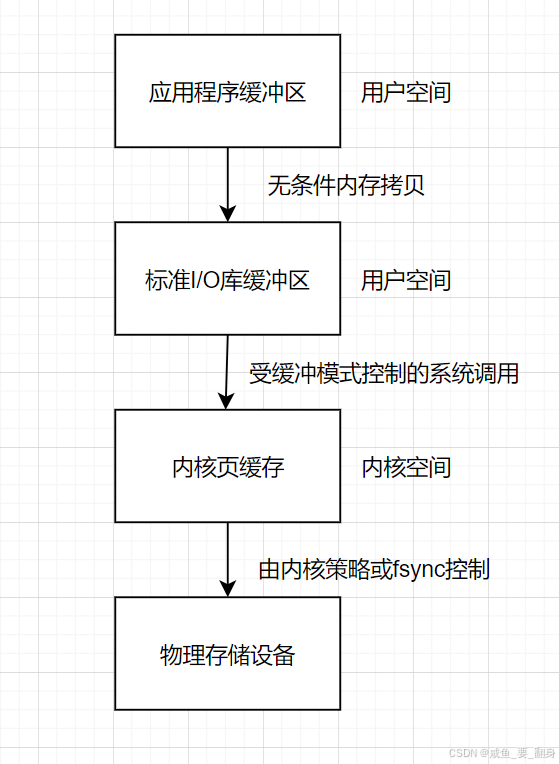
2、各级缓冲区的关键特性对比(重要!!!)
| 特性 | 应用程序缓冲区 | 标准I/O库缓冲区 | 内核缓冲区(页缓存) |
|---|---|---|---|
| 所处空间 | 用户空间 | 用户空间 | 内核空间 |
| 管理方 | 应用程序 | C运行时库 | Linux内核 |
| 典型大小 | 任意(程序员定义) | 通常8KB(BUFSIZ) | 动态(占内存20-40%) |
| 同步触发条件 | 显式调用I/O函数 | 缓冲模式规则 | 脏页超时或手动sync |
| 持久性保证 | 无 | 无 | 需fsync保证 |
| 可见性 | 完全可见 | 部分可见(setvbuf) | 完全隐藏 |
3、数据流动的详细机制
阶段1:应用缓冲区 → 标准I/O缓冲区
-
触发条件:调用
fwrite/fprintf等库函数时立即发生 -
内存操作:
// 伪代码:fwrite的核心逻辑 memcpy(FILE->buffer + FILE->pos, user_buf, user_size); FILE->pos += user_size; -
关键特点:
-
纯用户空间的内存拷贝(不涉及系统调用)
-
拷贝完成后函数立即返回
-
不受缓冲模式影响(模式只控制下一阶段)
-
阶段2:标准I/O缓冲区 → 内核缓冲区
-
触发条件:
缓冲模式 触发时机 _IOFBF(全缓冲) 缓冲区满或文件关闭 _IOLBF(行缓冲) 遇到换行符、缓冲区满或文件关闭 _IONBF(无缓冲) 每次操作立即触发 -
系统调用流程:
-
库调用
write(fd, internal_buf, buf_used) -
执行权限提升(用户态→内核态)
-
内核通过
copy_from_user()将数据复制到页缓存 -
标记相关页为PG_dirty
-
-
性能优化:
// 手动刷新示例 setvbuf(fp, NULL, _IOFBF, 16384); // 16KB缓冲 fwrite(buf, 1, 16000, fp); // 不触发write fwrite(buf, 1, 4000, fp); // 总20KB>16KB,触发write
阶段3:内核缓冲区 → 物理存储
-
自动刷出条件:
-
脏页存在时间 > dirty_expire_centisecs(默认3000cs/30秒)
-
系统脏页比例 > dirty_background_ratio(默认10%)
-
内存回收压力
-
-
手动控制:
fsync(fd); // 阻塞直到数据落盘 fdatasync(fd); // 只同步数据不同步元数据
四、用户空间缓冲区
用户空间缓冲区是由应用程序或标准库(如glibc)在用户空间维护的内存区域,用于临时存储要写入或读取的数据。
特点:
-
位置:位于进程的用户空间内存中
-
管理方:由应用程序或标准库管理
-
目的:减少系统调用次数,提高I/O效率
-
大小:通常由应用程序决定,标准库可能有默认大小
示例:
// 使用标准I/O函数时的用户缓冲区
FILE *fp = fopen("file.txt", "w");
char buf[1024]; // 用户缓冲区
fwrite(buf, 1, sizeof(buf), fp); // 数据先写入用户缓冲区
fclose(fp); // 最终flush到内核1. 文件打开
FILE *fp = fopen("file.txt", "w");-
使用标准I/O函数
fopen()打开文件 -
返回
FILE*指针,这个结构体包含了文件描述符和用户缓冲区信息 -
"w"模式表示以写入方式打开文件(如果存在则清空)
2. 用户缓冲区声明
char buf[1024]; // 用户缓冲区-
在用户空间声明了一个1024字节的缓冲区
-
这是应用程序自己管理的缓冲区,与标准I/O库的缓冲区是分开的
3. 数据写入
fwrite(buf, 1, sizeof(buf), fp); // 数据先写入用户缓冲区-
fwrite()将数据从buf写入文件流 -
实际流程:
-
数据从
buf复制到标准I/O库维护的用户缓冲区(在FILE结构体中) -
当用户缓冲区填满时,库函数会自动调用
write()系统调用将数据送入内核缓冲区 -
对于1024字节的写入,如果标准I/O的缓冲区足够大,可能不会立即触发系统调用
-
4. 文件关闭
fclose(fp); // 最终flush到内核-
fclose()执行以下操作:-
将标准I/O库的用户缓冲区中剩余数据flush到内核(通过
write()系统调用) -
释放FILE结构体和相关资源
-
关闭文件描述符
-
关键点说明
-
双层缓冲:
-
第一层:应用程序自己的缓冲区(
buf[1024]) -
第二层:标准I/O库维护的用户缓冲区(在FILE结构体中)
-
-
缓冲策略:
-
标准I/O库通常使用全缓冲模式(对于磁盘文件)
-
缓冲区大小可以通过
setvbuf()函数设置
-
-
实际写入时机:
-
缓冲区满时
-
显式调用
fflush() -
文件关闭时
-
程序正常终止时
-
-
与内核缓冲区的关系:
-
只有当数据从用户缓冲区通过
write()系统调用进入内核后,才会被加入内核的页缓存 -
此时数据仍未真正写入磁盘,除非:
-
显式调用
fsync() -
使用
O_SYNC标志打开文件 -
内核定期刷出脏页
-
-
关键补充(重点!!!):
当调用fwrite(buf, size, nmemb, stream)时,数据从用户缓冲区到标准I/O库缓冲区的复制遵循以下规则:
-
无条件立即复制:
-
从用户缓冲区到标准I/O库缓冲区的内存拷贝是无条件立即执行的
-
这个复制操作不受缓冲模式(全缓冲、行缓冲、无缓冲)的影响
-
缓冲模式只控制从库缓冲区到内核的刷新时机
-
可视化流程
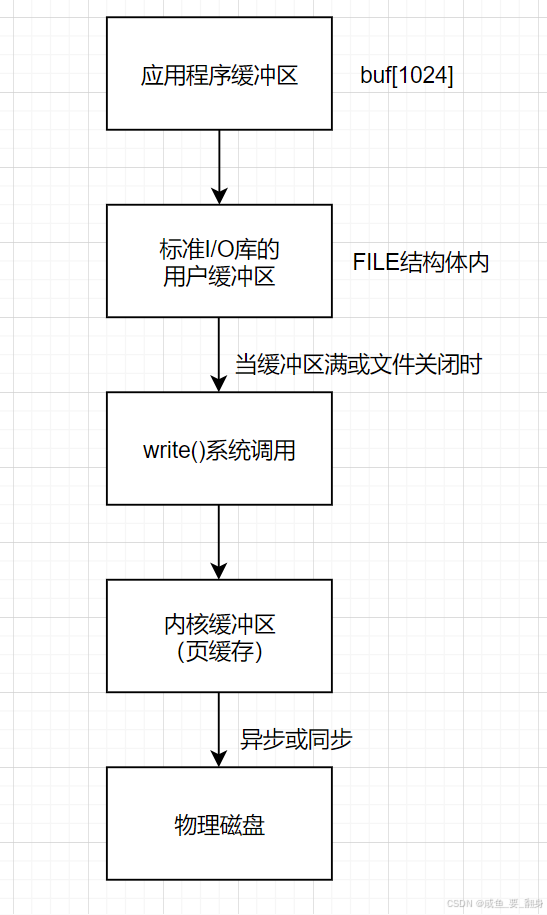
五、内核空间缓冲区
内核缓冲区是由操作系统内核维护的内存区域,也称为页缓存(page cache)。
特点:
-
位置:位于内核空间
-
管理方:由Linux内核管理
-
目的:缓存磁盘数据,减少实际磁盘I/O
-
大小:动态调整,受系统内存限制
-
持久性:默认情况下不保证立即写入磁盘(除非O_SYNC)
相关系统调用:
// 直接系统调用,绕过用户缓冲区
int fd = open("file.txt", O_WRONLY);
char buf[1024];
write(fd, buf, sizeof(buf)); // 数据进入内核缓冲区
fsync(fd); // 强制将内核缓冲区写入磁盘
close(fd);1. open() 系统调用
int fd = open("file.txt", O_WRONLY);-
功能:打开(或创建)文件
file.txt,返回文件描述符fd。 -
参数:
-
"file.txt":目标文件名。 -
O_WRONLY:以只写模式打开(其他常用标志包括O_CREAT、O_TRUNC等)。
-
-
作用:绕过标准I/O库的用户态缓冲区,直接通过系统调用操作文件。
2. write() 系统调用
char buf[1024];
write(fd, buf, sizeof(buf));-
功能:将用户态缓冲区
buf的 1024 字节数据写入文件。 -
关键点:
-
数据从用户空间拷贝到内核空间的内核缓冲区(Page Cache)。
-
此时数据尚未写入磁盘,依赖内核的刷新机制(如定时刷盘或内存不足时)。
-
若应用崩溃,内核可能尚未刷盘,导致数据丢失。
-
3. fsync() 系统调用
fsync(fd);-
功能:强制将文件描述符
fd对应的内核缓冲区数据同步到磁盘。 -
作用:
-
确保数据持久化,即使系统崩溃也不会丢失。
-
会阻塞直到磁盘写入完成,性能开销较大(涉及磁盘I/O)。
-
-
替代方案:
-
fdatasync():仅同步数据,不同步元数据(如修改时间),性能稍好。 -
sync():同步所有内核缓冲区,不针对单个文件。
-
4. close() 系统调用
close(fd);-
功能:关闭文件描述符,释放资源。
-
注意:关闭前未调用
fsync()时,数据仍可能在内核缓冲区,存在丢失风险。
总结:数据流向
-
用户缓冲区 (
buf) → 内核缓冲区 (Page Cache) → 磁盘。 -
write()只保证数据到内核缓冲区,fsync()保证到磁盘。
应用场景
-
关键数据持久化:如数据库事务日志、配置文件更新。
-
性能权衡:频繁调用
fsync()会降低性能,需根据需求平衡安全性与速度。
扩展知识
-
O_DIRECT标志:绕过内核缓冲区,直接操作磁盘(需对齐内存和大小),但需自行管理缓存。 -
文件系统屏障:某些文件系统(如ext4)支持屏障写入,进一步确保数据顺序和一致性。
通过这段代码,可以理解系统调用如何直接控制数据持久化,避免依赖用户态缓冲区的延迟写入问题。
两者协作流程
-
写入流程:
应用程序数据 → 用户缓冲区 →write()系统调用 → 内核缓冲区 → (异步)写入磁盘 -
读取流程:
磁盘数据 → 内核缓冲区 →read()系统调用 → 用户缓冲区 → 应用程序
六、缓冲区的层级关系

-
从应用程序buf到库缓冲区的复制是内存拷贝,无条件发生
-
从库缓冲区到内核的传输才受缓冲模式控制
七、缓冲模式对比
| 特性 | 用户缓冲区 | 内核缓冲区 |
|---|---|---|
| 位置 | 用户空间 | 内核空间 |
| 管理方 | 应用程序/库 | 操作系统内核 |
| 大小控制 | 应用程序可控制 | 系统动态调整 |
| 持久性 | 需flush到内核 | 需sync到磁盘 |
| 典型API | stdio (fopen, fwrite) | 系统调用 (open, write) |
八、性能优化考虑
-
缓冲策略选择:
-
小量频繁I/O:使用用户缓冲区更高效
-
大批量I/O:直接系统调用可能更好
-
-
同步控制:
-
fflush():用户缓冲区 → 内核 -
fsync()/fdatasync():内核 → 磁盘 -
O_SYNC/O_DSYNC:每次write都同步到磁盘
-
-
直接I/O:使用
O_DIRECT标志绕过内核缓冲区,直接操作磁盘(特定场景下使用)
九、实际应用建议
-
对于大多数应用,使用标准I/O库(用户缓冲区)是最佳选择
-
需要严格控制写入时序时,考虑适当的同步操作
-
高性能应用可以尝试内存映射(mmap)或直接I/O
-
监控
/proc/meminfo中的Dirty项了解待写入磁盘的内核缓冲区大小