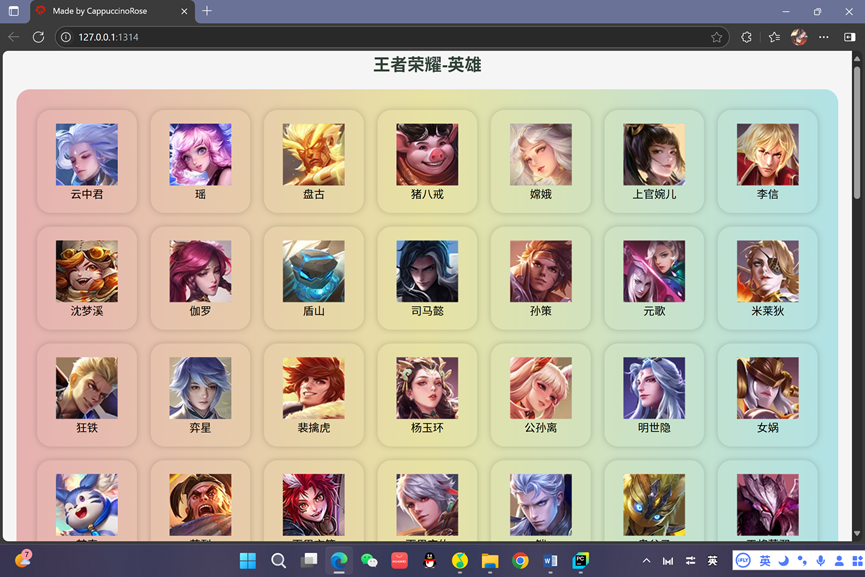
复盘爬虫课后练习题
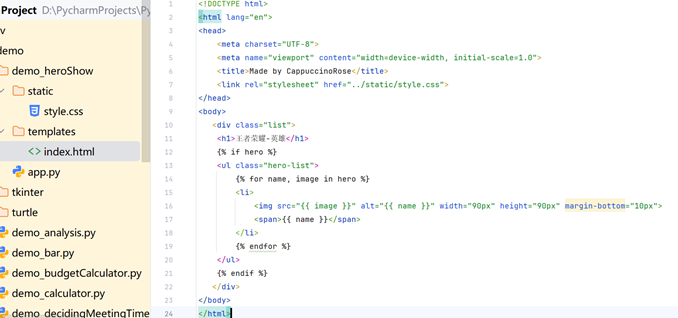
项目框架
Static文件夹下是.css样式设置文件
Templates文件夹下是.html页面布局文件
App.py是编写爬虫的python模块
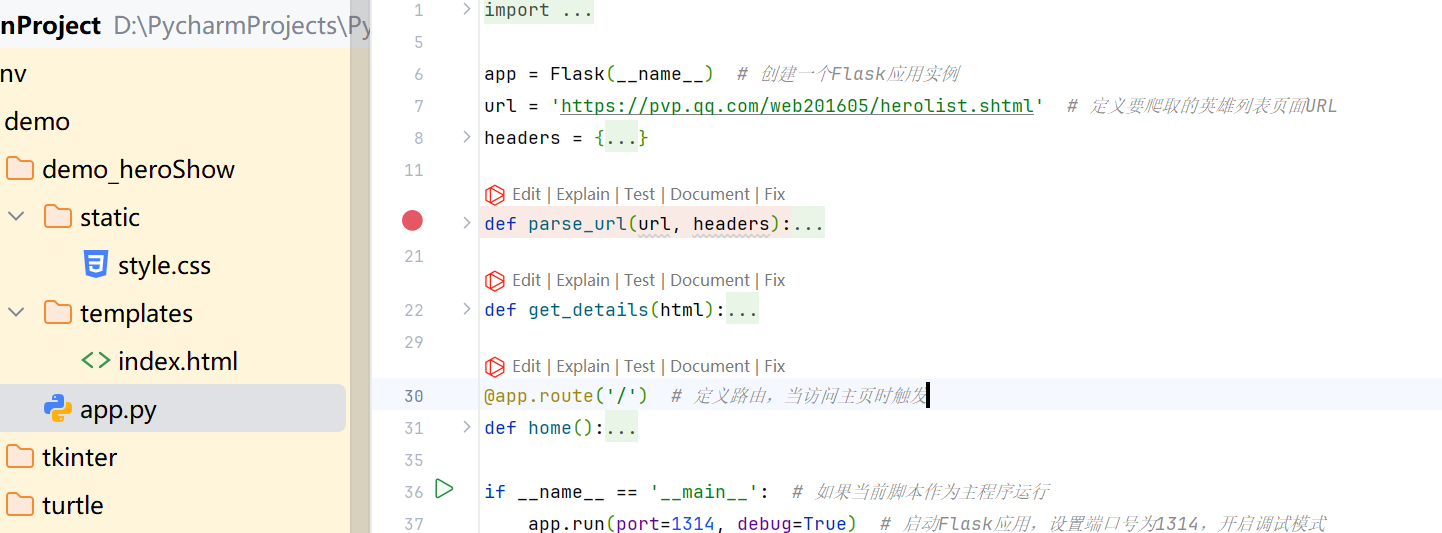
python详细代码
from flask import Flask, render_template, request # 从flask库导入Flask类,render_template函数和request对象
import requests
# 导入requests库,用于发送HTTP请求
from lxml import etree
# 从lxml库导入etree模块,用于解析HTML文档
import random
# 导入random库,用于生成随机数app = Flask(__name__) # 创建一个Flask应用实例
url = 'https://pvp.qq.com/web201605/herolist.shtml' # 定义要爬取的英雄列表页面URL
headers = { # 定义请求头,模拟浏览器访问'user-agent': # 定义自己电脑的
}def parse_url(url, headers): # 定义解析URL的函数try:response = requests.get(url, headers=headers) # 发送GET请求response.raise_for_status() # 检查请求是否成功,如果不成功则抛出异常response.encoding = 'gbk' # 设置响应的编码为gbkreturn etree.HTML(response.text) # 将响应的文本内容转换为HTML元素,并返回except requests.RequestException as e: # 捕获请求过程中的异常print(f"请求错误: {e}") # 打印错误信息return None # 如果发生异常,返回Nonedef get_details(html): # 定义获取英雄详细信息的函数if html is not None: # 如果HTML元素不为空hero_name = html.xpath('//ul[@class="herolist clearfix"]/li/a/text()') # 使用XPath获取英雄名字hero_image_urls = html.xpath('//ul[@class="herolist clearfix"]/li/a/img/@src') # 使用XPath获取英雄图片的URLreturn hero_name, hero_image_urls # 返回英雄名字和图片URLelse:return None # 如果HTML元素为空,返回None@app.route('/') # 定义路由,当访问主页时触发
def home(): # 定义主页的视图函数html_content = parse_url(url, headers) # 调用parse_url函数获取HTML内容hero_name, hero_image_url = get_details(html_content) # 调用get_details函数获取英雄详细信息和图片URLreturn render_template('index.html', hero=zip(hero_name, hero_image_url)) # 渲染index.html模板,并传递英雄信息if __name__ == '__main__': # 如果当前脚本作为主程序运行app.run(port=1314, debug=True) # 启动Flask应用,设置端口号为1314,开启调试模式
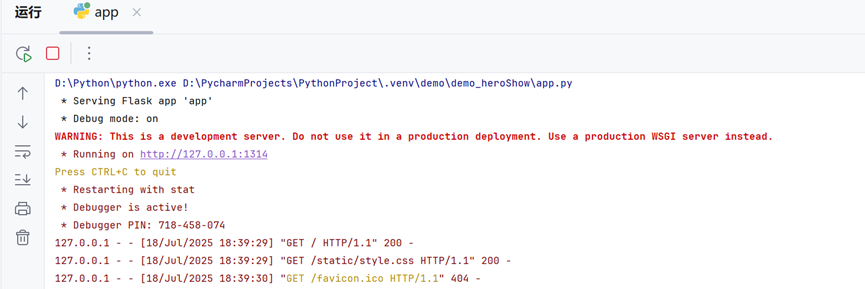
运行程序
- 后台
- 前端