Kafka的基本使用
目录
认识Kafka
消息队列
消息队列的核心概念
核心价值与解决的问题
Kafka
ZooKeeper
Kafka的基本使用
环境安装
启动zookeeper
启动Kafka
消息主题
创建主题
查询主题
修改主题
发送数据
命令行操作
JavaAPI操作
消费数据
命令行操作
JavaAPI操作
认识Kafka
消息队列
消息队列是分布式系统和现代应用架构中至关重要的中间件。它的核心作用是解耦、异步和削峰填谷,像一个高效的“通信员”和“缓冲池”协调不同组件之间的工作。
消息队列的核心概念
-
生产者: 产生消息(数据、任务请求、事件通知)并发送到队列的应用程序或服务。
-
消息队列: 一个临时的、持久化的存储区域(通常基于内存、磁盘或数据库),用于存放生产者发送的消息。消息按照先进先出的顺序存储,但很多队列支持优先级、延迟等特性。
-
消费者: 从队列中获取消息并进行处理的应用程序或服务。
-
消息: 队列中传输的数据单元,通常包含有效载荷(实际数据)和元数据(如ID、时间戳、优先级等)。
核心价值与解决的问题
-
解耦:
-
问题: 系统组件(服务)之间直接调用会导致紧密耦合。一个组件的变更、故障或性能瓶颈会直接影响其他依赖它的组件。扩展也变得困难。
-
解决: 生产者只需将消息发送到队列,无需知道谁(消费者)会处理它,消费者只需从队列订阅消息,无需知道消息是谁(生产者)发送的。双方只依赖队列,不直接依赖对方,大大降低了耦合度。系统更灵活、更易于维护和扩展。
-
-
异步:
-
问题: 同步调用要求调用方(生产者)必须等待被调用方(消费者)处理完成并返回结果才能继续执行。如果处理耗时很长,调用方会被阻塞,资源利用率低,用户体验差(如网页卡顿)。
-
解决: 生产者发送消息到队列后即可返回,无需等待消费者处理。消费者在后台异步地从队列拉取消息进行处理。这显著提高了系统的吞吐量和响应速度。
-
-
削峰填谷:
-
问题: 系统流量往往存在高峰和低谷。高峰期如果请求量远超消费者处理能力,会导致系统过载、崩溃或请求超时。低谷期资源又可能闲置。
-
解决: 队列作为缓冲区,在流量高峰时积压请求,平滑地将大量请求暂存起来。消费者按照自己的稳定处理能力从队列中拉取消息进行处理,避免了瞬间洪峰压垮下游系统。在流量低谷时,消费者可以继续处理队列中积压的消息。
-
-
冗余与可靠性:
-
问题: 直接调用时,如果消费者临时不可用(故障、重启、维护),生产者的请求会丢失或失败。
-
解决: 消息队列通常提供消息持久化功能(将消息写入磁盘)。即使消费者暂时离线,消息也会安全存储在队列中,待消费者恢复后继续处理,确保消息不丢失。许多队列还提供确认机制(ACK),消费者处理成功后才会从队列中移除消息。
-
-
可伸缩性:
-
问题: 单一消费者处理能力有限,难以应对增长的业务量。
-
解决: 可以很容易地增加消费者的数量(水平扩展),让多个消费者并行地从同一个队列中拉取消息进行处理,显著提高系统的整体吞吐量。队列本身也可以做成分布式集群来应对高吞吐量需求。
-
-
顺序保证:
-
问题: 在分布式环境中保证消息处理的严格顺序很困难。
-
解决: 虽然完全全局有序很难,但许多消息队列能保证分区有序或队列有序(在单个队列/分区内,消息按照发送顺序被消费)。这对于某些需要保证因果关系的业务场景(如账户流水)非常重要。
-
-
缓冲:
-
问题: 生产者和消费者的处理速度不一致。
-
解决: 队列天然提供了缓冲能力,允许生产者和消费者以各自不同的速率工作,不会互相拖累。
-
常见的消息队列有RabbitMQ,Kafka,RocketMQ。这里主要介绍Kafka。
Kafka
Kafka 通常指 Apache Kafka,这是一个开源的、分布式的、高吞吐量、低延迟的流处理平台。它最初由 LinkedIn 开发,后来捐赠给了 Apache 软件基金会,并迅速成为大数据和实时数据处理领域的核心基础设施之一。
Kafka 不仅仅是一个消息队列,它是一个高吞吐、低延迟、分布式、持久化、可水平扩展的流数据平台。它设计之初就是为了处理持续产生、体量巨大、需要实时处理的“数据流”。
ZooKeeper是一个开源的分布式应用程序协调软件,而Kafka是分布式事件处理平台,底层是使用分布式架构设计,所以Kafka的多个节点之间是采用zookeeper来实现协调调度的。
ZooKeeper
ZooKeeper是一个开源的分布式应用程序协调软件,而Kafka是分布式事件处理平台,底层是使用分布式架构设计,所以Kafka的多个节点之间是采用zookeeper来实现协调调度的。
Zookeeper的核心作用
- ZooKeeper的数据存储结构可以简单地理解为一个Tree结构,而Tree结构上的每一个节点可以用于存储数据,所以一般情况下,我们可以将分布式系统的元数据(环境信息以及系统配置信息)保存在ZooKeeper节点中。
- ZooKeeper创建数据节点时,会根据业务场景创建临时节点或永久(持久)节点。永久节点就是无论客户端是否连接上ZooKeeper都一直存在的节点,而临时节点指的是客户端连接时创建,断开连接后删除的节点。同时,ZooKeeper也提供了Watch(监控)机制用于监控节点的变化,然后通知对应的客户端进行相应的变化。Kafka软件中就内置了ZooKeeper的客户端,用于进行ZooKeeper的连接和通信。
Kafka的基本使用
环境安装
我们这里先安装简单的Windows单机环境。在安装之前务必先安装Java8。
下载Kafka:Kafka下载地址Apache Kafka: A Distributed Streaming Platform.![]() https://kafka.apache.org/downloads
https://kafka.apache.org/downloads
选择版本为2.13-3.8.0
下载完成后进行解压,解压目录放在非系统盘根目录下。为了访问方便,可以将解压后的文件夹名称修改为Kafka
Kafka的文件目录
| bin | linux系统下可执行脚本文件 |
| bin/windows | windows系统下可执行脚本文件 |
| config | 配置文件 |
| libs | 依赖类库 |
| licenses | 许可信息 |
| site-docs | 文档 |
| logs | 服务日志 |
启动zookeeper
当前版本的Kafka软件仍然依赖Zookeeper,所以启动Kafka之前,需要先启动Zookeeper,Kafka软件内置了Zookeeper,所以无需额外安装,直接调用启动脚本即可。
1. 进入Kafka解压缩文件夹的config目录,修改zookeeper.properties配置文件
修改dataDir配置,用于设置ZooKeeper数据存储位置,该路径如果不存在会自动创建。
dataDir=D:/kafka/data/zk

在kafka解压缩后的目录中创建Zookeeper启动脚本文件:zk.cmd。
输入:
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
上述指令就是调用zookeeper启动命令,同时指定配置文件
双击启动即可:
启动完成。
启动Kafka
进入Kafka解压缩文件夹的config目录,修改server.properties配置文件.

设置Kafka数据的存储目录。如果文件目录不存在,会自动生成。
在kafka解压缩后的目录中创建Kafka启动脚本文件:kfk.cmd。
输入:
call bin/windows/kafka-server-start.bat config/server.properties
双击启动即可:
DOS窗口中,输入jps指令,查看当前启动的软件进程:
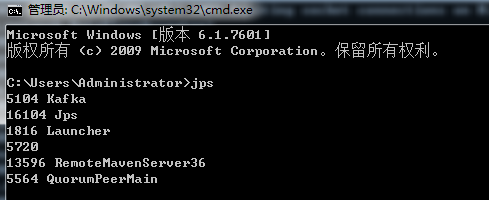
这里名称为QuorumPeerMain的就是ZooKeeper软件进程,名称为Kafka的就是Kafka系统进程。此时,说明Kafka已经可以正常使用了。
消息主题
在发布订阅模型中,为了让消费者对感兴趣的消息进行消费,而不是消费所有消息,所以就定义了主题(Topic),也就是说将不同的消息进行分类,分成不同的主题(Topic),然后消息生产者在生成消息时,就会向指定的主题(Topic)中发送,而消息消费者也可以订阅自己感兴趣的主题(Topic)并从中获取消息。
有很多种方式都可以操作Kafka消息中的主题(Topic):命令行、第三方工具、Java API、自动创建。而对于初学者来讲,掌握基本的命令行操作是必要的。所以接下来,我们采用命令行进行操作。
创建主题
使用命令行方式创建主题test
打开DOS窗口,在确保Zookeeper和Kafkfa启动的情况下,进入Kafkfa解压目录下的bin/windows目录。
输入如下命令创建主题test: kafka-topics.bat --bootstrap-server localhost:9092 --create --topic test

test主题创建完成。
查询主题
输入如下命令进行主题查询:kafka-topics.bat --bootstrap-server localhost:9092 --list

修改主题
kafka-topics.bat --bootstrap-server localhost:9092 --topic test --alter --partitions 2
上述命令将test主题的分区数量设置为2.关于分区的信息,后面会详细介绍。
发送数据
命令行操作
使用命令行方式发送:
kafka-console-producer.bat --bootstrap-server localhost:9092 --topic test

上述操作就是在控制台生成数据,hello kafka 这里的数据需要回车,才会发送到Kafka服务器。
JavaAPI操作
引入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.8.0</version>
</dependency>编写生产者
public class ProducerTest {public static void main(String[] args) {// 配置属性集合Map<String, Object> configMap = new HashMap<>();// 配置属性:Kafka服务器集群地址configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 配置属性:Kafka生产的数据为KV对,所以在生产数据进行传输前需要分别对K,V进行对应的序列化操作configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 创建Kafka生产者对象,建立Kafka连接// 构造对象时,需要传递配置参数KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// 准备数据,定义泛型// 构造对象时需要传递 【Topic主题名称】,【Key】,【Value】三个参数for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);// 生产(发送)数据producer.send(record);}// 关闭生产者连接producer.close();}
}消费数据
命令行操作
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning

JavaAPI操作
public class ConsumerTest {public static void main(String[] args) {
// 创建配置对象Map<String, Object> configMap = new HashMap<>();configMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 反序列化类配置configMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());configMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 组ID配置configMap.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 创建消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configMap);// 从kafka主题中获取对象 订阅主题consumer.subscribe(Collections.singleton("test"));// 消费者从Kafka主题中拉取数据while (true) {ConsumerRecords<String, String> datas = consumer.poll(100);for (ConsumerRecord<String, String> data : datas) {System.out.println(data);}}// 关闭消费者对象// consumer.close();}
}