曼哈顿自注意力MaSA,基于曼哈顿距离的显式空间先验,以线性计算复杂度高效建模全局与局部空间关系,提升视觉任务的性能。
Vision Transformer(ViT)凭借强大的全局建模能力成为视觉领域的重要架构,但其核心的自注意力机制存在两大局限:一是缺乏显式空间先验,忽略了视觉数据中像素 / 区域间的空间距离关联性;二是二次计算复杂度(与 token 数量平方成正比),在处理高分辨率图像或全局信息时计算成本极高,限制了其在实时或大规模任务中的应用。为解决这些问题,研究者受 NLP 领域 Retentive Network(RetNet)的启发 ——RetNet 通过基于距离的时间衰减矩阵为文本数据引入显式时序先验,将这一思路扩展到视觉领域,提出了 Manhattan Self-Attention(MaSA),旨在为视觉模型注入显式空间先验并降低计算复杂度。
1.MaSA原理
MaSA 的核心原理是将 RetNet 中单向、一维的时间衰减机制转化为双向、二维的空间衰减机制,并通过注意力分解实现线性复杂度。
显式空间先验引入:基于曼哈顿距离(两点在水平和垂直方向的距离之和)构建空间衰减矩阵。距离越近的 token 衰减越小、注意力权重越高,距离越远则衰减越大,使模型天然捕捉 “近邻像素关联性更强” 的视觉先验。
线性复杂度实现:为避免全局自注意力的二次复杂度,MaSA 将注意力沿图像水平和垂直轴分解:先分别计算水平方向注意力和垂直方向注意力,再通过矩阵乘法组合为全局注意力。这种分解在保留完整空间衰减信息的同时,将计算复杂度从 O(N2) 降至 O(N)(N 为 token 数量),且保持与原始全局注意力一致的感受野。

MaSA 的结构围绕 “空间衰减矩阵” 和 “分解式注意力计算” 展开,主要包含以下部分:
空间衰减矩阵模块:根据输入 token 的二维坐标,动态生成基于曼哈顿距离的 D2d 矩阵,编码 token 间的空间距离关联;
分解式注意力计算模块:将查询(Q)、键(K)沿水平和垂直方向拆分,分别计算水平注意力 AttnH=Softmax(QHKH⊤)⊙DH 和垂直注意力 AttnW=Softmax(QWKW⊤)⊙DW,再通过矩阵转置与乘法组合,输出最终注意力特征;
辅助增强模块:包含 Local Context Enhancement(LCE)模块(通过 3×3 或 5×5 深度卷积增强局部上下文信息)和 Conditional Positional Encoding(CPE)模块(提供灵活的位置编码,补充空间位置信息),进一步提升空间建模能力。
2.MaSA习作思路
在目标检测中的优点
Manhattan Self-Attention 凭借基于曼哈顿距离的显式空间先验,能够自然强化目标内部及相邻目标间的空间关联性 —— 对于目标检测中关键的边界定位和尺度感知任务,近邻像素 / 区域的高注意力权重可精准捕捉目标边缘细节,而全局范围内的衰减机制又能抑制背景噪声干扰;同时,其分解式线性复杂度设计可高效处理图像全局信息,在保证对大目标、密集目标建模能力的同时,降低计算成本,兼顾检测精度与实时性需求。
在分割中的优点
分割任务对像素级空间关系的精准建模要求极高,Manhattan Self-Attention 的空间衰减矩阵能细致编码不同像素间的距离依赖,使同类区域内的像素保持高注意力关联,而不同类别边界处的像素因距离衰减产生显著区分,有效提升分割的边界精度与区域一致性;此外,分解式注意力在保留全局上下文的同时,避免了高分辨率图像中二次复杂度的计算瓶颈,可高效处理大尺寸分割图,平衡细节保留与全局语义理解的需求。
3. YOLO与MaSA的结合
YOLO 系列强调实时性与检测速度,Manhattan Self-Attention 的线性复杂度可显著降低其在处理全局信息时的计算负担,适配实时推理场景;同时,显式空间先验能帮助 YOLO 更好地捕捉目标的空间位置与尺度特征,提升小目标、遮挡目标的检测精度。
4.MaSA代码部分
YOLO12模型改进方法,快速发论文,总有适合你的改进,还不改进上车_哔哩哔哩_bilibili
代码获取:YOLOv8_improve/YOLOV12.md at master · tgf123/YOLOv8_improve · GitHub
5. MaSA引入到YOLOv12中
第一: 先新建一个v12_changemodel,将下面的核心代码复制到下面这个路径当中,如下图如所示。E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\v12_changemodel。
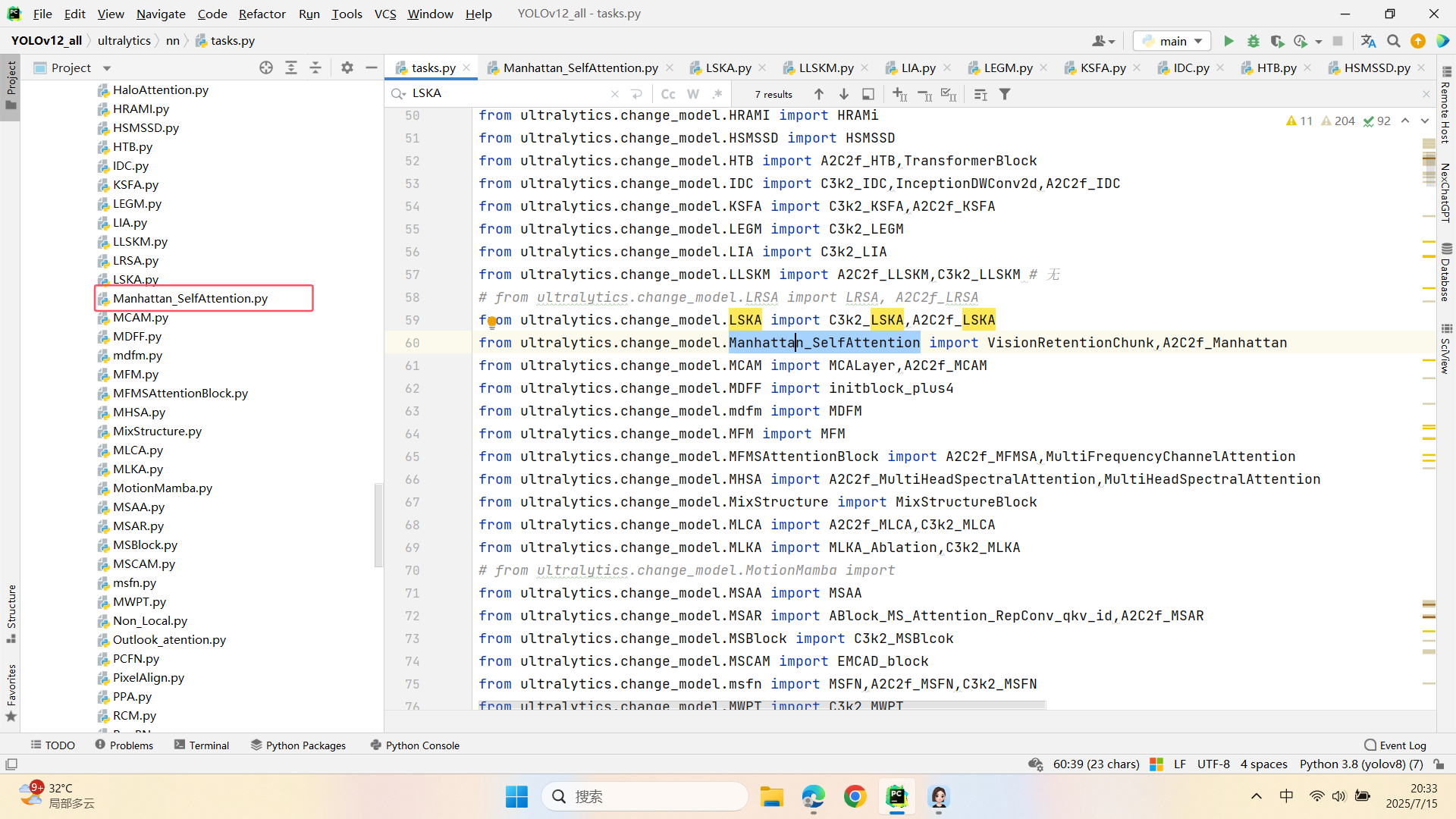
第二:在task.py中导入包
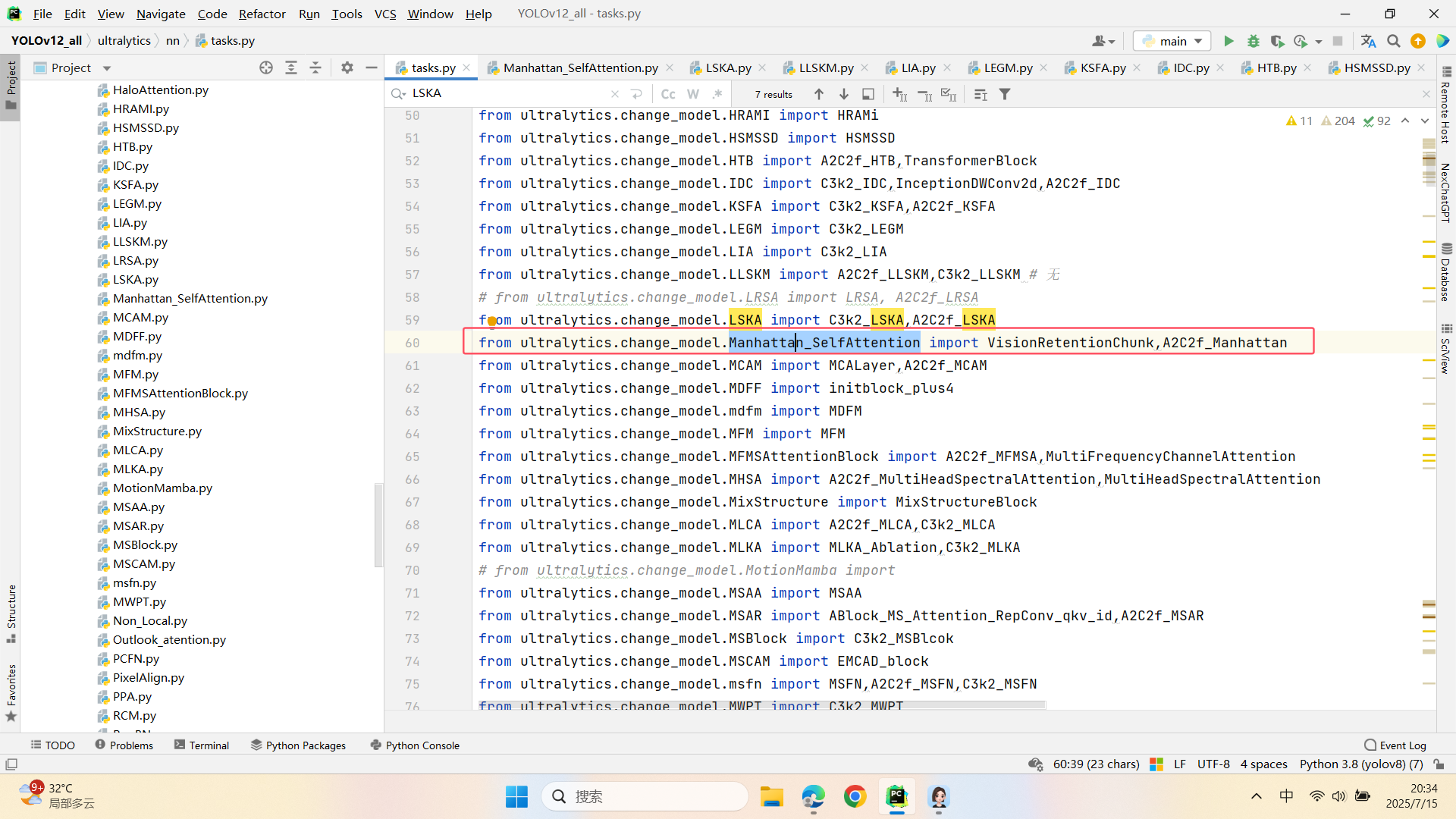
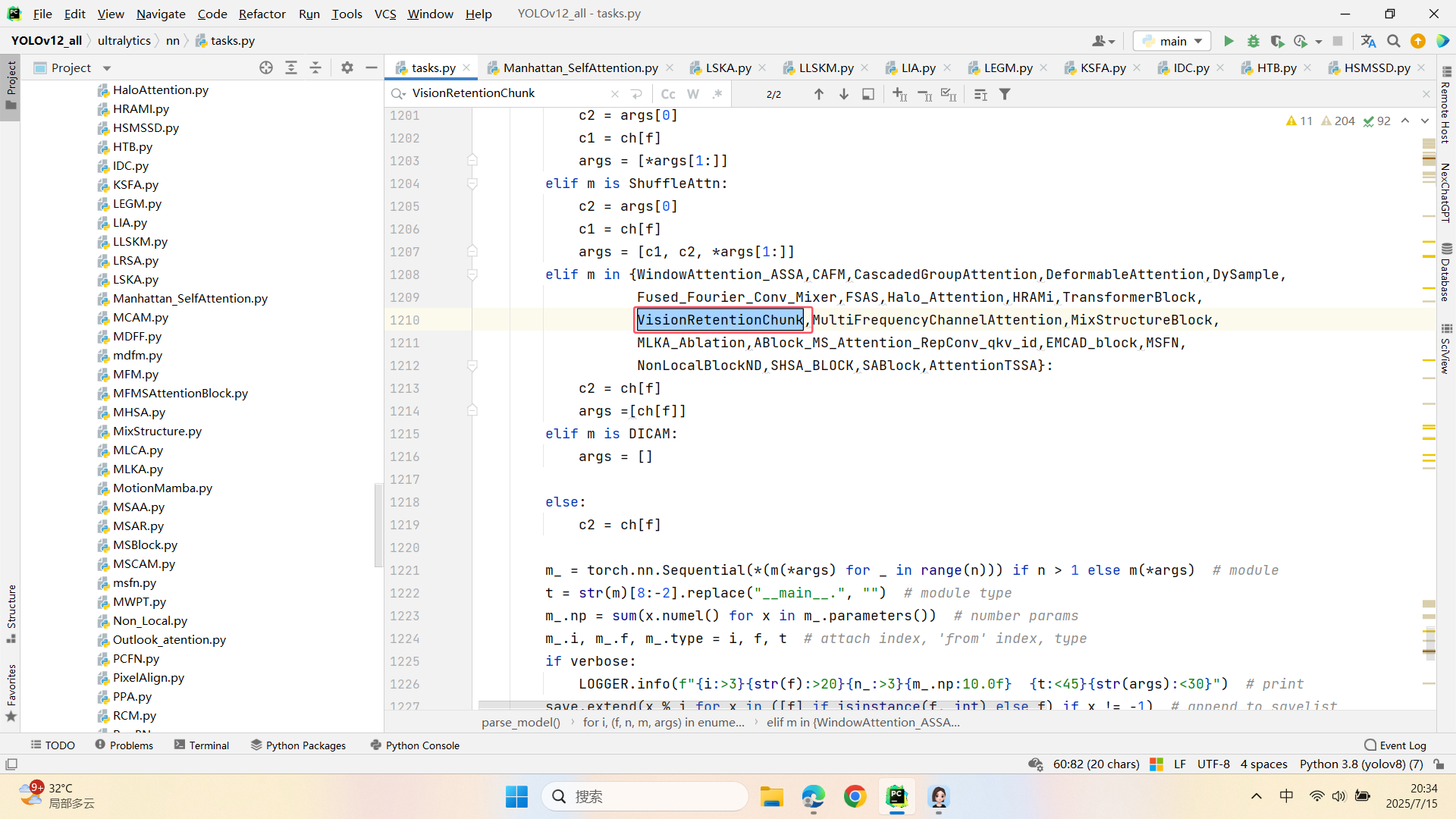
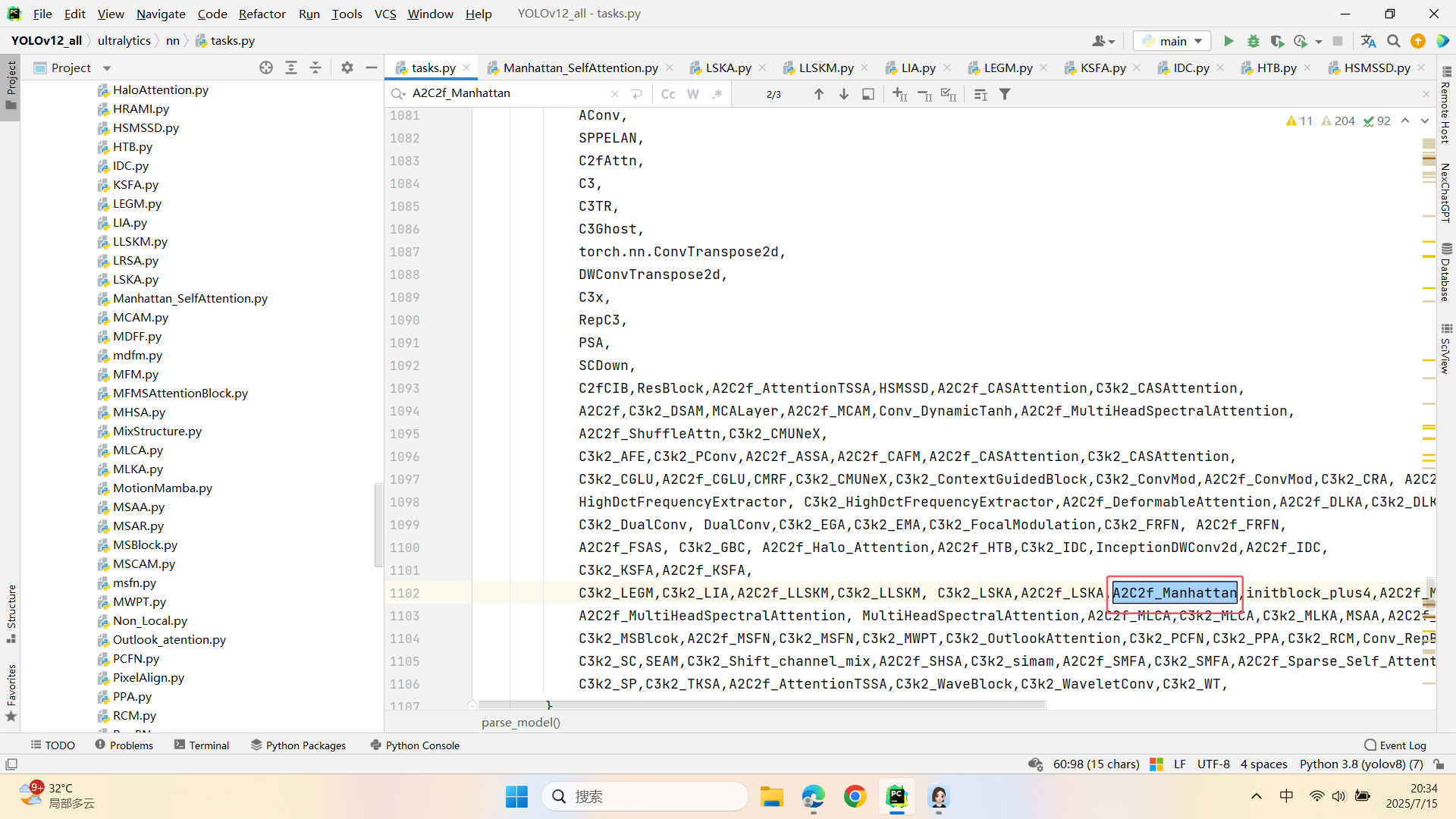
第三:在task.py中的模型配置部分下面代码
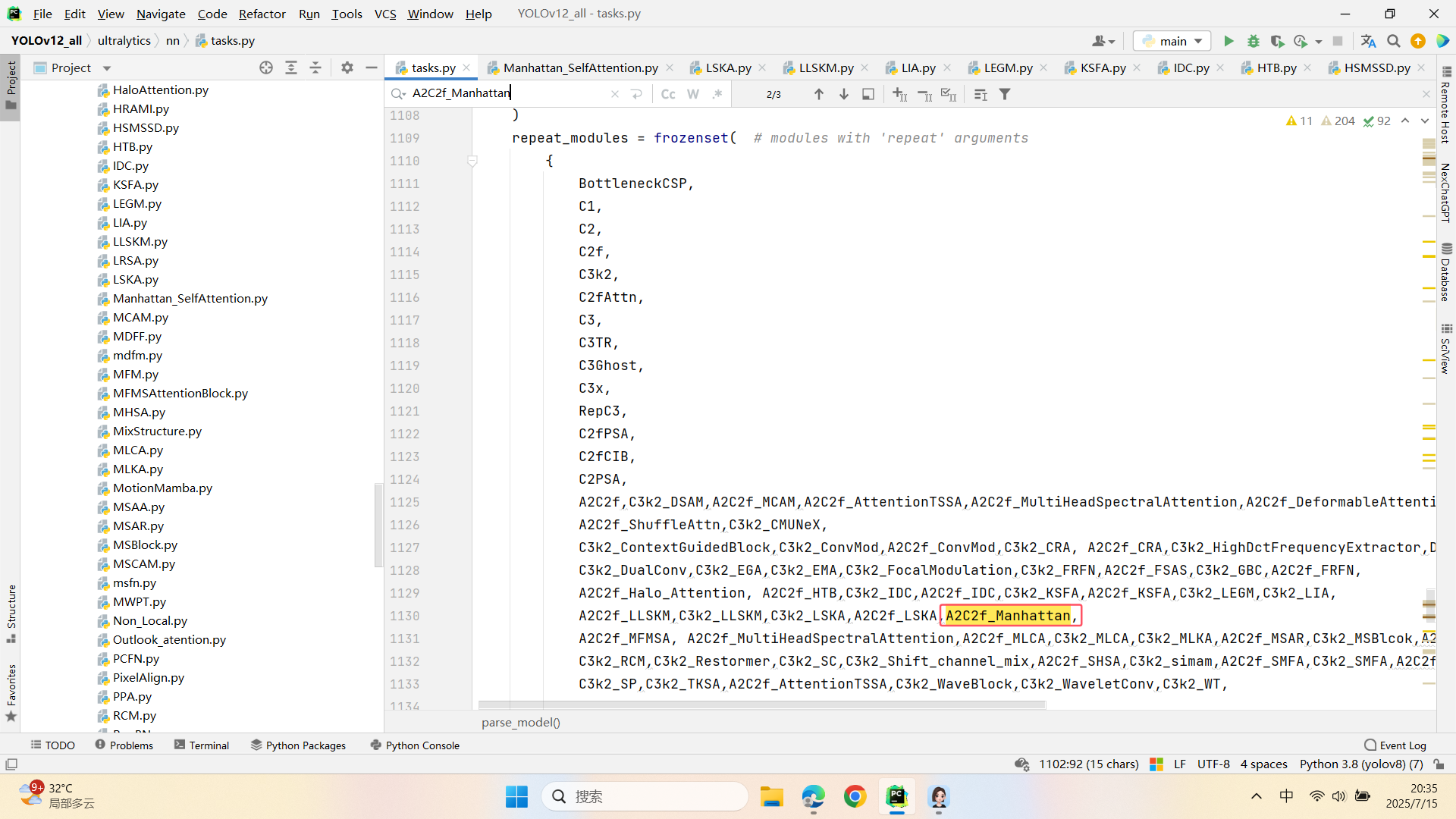
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行代码
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型model = YOLO("/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/models/11/yolo12_Manhattan_SelfAttention")\# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weightsresults = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",epochs=300,imgsz=640,batch=4,# cache = False,# single_cls = False, # 是否是单类别检测# workers = 0,# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',amp = True)