【机器学习深度学习】什么是 GGUF?
目录
前言
一、什么是 GGUF?
二、GGUF 的前身:GGML 简介
2.1 GGML 是什么?
2.2 GGML 的局限
三、GGUF 的优势:为什么 GGML 要升级?
四、GGUF 的工作原理与结构简析
五、GGUF 的典型使用场景
六、GGUF 如何使用?——实战简要指南
✅ 步骤一:下载 GGUF 格式模型
✅ 步骤二:准备运行环境
1. 安装 Python 和 llama-cpp-python
2. 准备 C++ 版 llama.cpp(可选)
✅ 步骤三:运行推理
七、未来展望:GGUF 会统一大模型推理标准吗?
🎯 潜在趋势:
八、总结

前言
在大模型本地化部署日益流行的今天,轻量、高效、跨平台的推理格式 正成为模型落地的关键。过去我们常用 ONNX、HF Transformers 格式来保存模型,但这些格式在边缘设备或 CPU 上部署时显得笨重、效率低。于是,为了解决这一问题,GGUF 格式 诞生了,它正逐步成为 本地推理模型的“新通用语言”。
那么,GGUF 到底是什么?它为什么取代了 GGML?又该如何使用?本文将带你全面了解 GGUF,从概念、发展、优势到实战使用,深入解析其在大模型推理中的价值。
一、什么是 GGUF?
1.1 概念
GGUF 全称是 GPT-Generated Unified Format,是由开源社区(特别是 llama.cpp 项目)提出的一种 统一的模型格式,用于本地部署大语言模型。
它是 GGML 的继任者,专门设计用于:
-
跨平台(x86, ARM, GPU, macOS Metal 等);
-
跨模型架构(LLaMA, Qwen, Mistral, Phi 等);
-
高效推理(支持 int4/int8 量化);
-
单文件结构,易于存储与分发。
1.2 GGUF 的优势
-
存储和内存优化:
-
相比于传统的模型格式,GGUF 采用了优化的存储结构,能更有效地压缩模型数据,减少内存使用和硬盘存储。
-
-
跨平台支持:
-
GGUF 格式可以在多个平台之间更好地迁移,支持更多的硬件(CPU 和 GPU)加速,且与具体框架(如 TensorFlow、PyTorch)无关。
-
-
推理性能优化:
-
GGUF 格式专为推理而设计,提供了更高的加载速度和推理效率,可以在本地计算资源有限的情况下实现更高效的推理。
-
1.3 GGUF 格式的内部结构
GGUF 格式内部结构经过优化,以提高推理速度和存储效率。相比于传统格式,它可能在以下方面有差异:
-
量化:通过量化(例如 Q4, Q8 等),减少模型存储的内存占用。
-
结构化存储:GGUF 文件可能将模型的参数、权重、激活值等数据结构化存储,以便于快速加载和推理。
1.4 常见问题和疑问
-
GGUF 格式和其他格式的区别?
-
GGUF 格式的主要优势在于推理的高效性和存储的优化。相比于
.bin或.pth文件,它通常更小,且加载和推理速度更快。
-
-
是否所有的机器学习框架都支持 GGUF?
-
目前,GGUF 主要由 llama.cpp 和相关工具支持,但它在未来可能会被更多框架采纳。
-
-
GGUF 是否支持 GPU 加速?
-
是的,GGUF 格式支持 GPU 加速,尤其是通过 C++ 实现的工具(llama.cpp)能够有效利用 GPU 来加速推理过程。
-
1.5 小结
-
GGUF 是一个优化的机器学习模型格式,主要针对高效推理和存储优化。
-
通过 llama-cpp-python 或 llama.cpp 可以加载并运行 GGUF 格式的模型。
-
适合需要高效推理的场景,尤其是在资源有限的环境中。
下载 GGUF 文件后,你可以在本地机器上通过相应的推理工具直接加载并运行模型。
无需依赖云端,完全可以离线运行大模型,进行文本生成、对话等任务。
二、GGUF 的前身:GGML 简介
要理解 GGUF,就不能不提它的前身 —— GGML(GPT-Generated Model Language)。
2.1 GGML 是什么?
-
是一个用于高效张量计算的 C 语言推理框架;
-
最早出现在 2022 年,主要用于将 Meta 的 LLaMA 模型在 CPU 上进行本地推理;
-
其最大亮点是:无需 GPU,仅用 CPU 就能运行大模型!
2.2 GGML 的局限
-
不支持模型结构信息(如 tokenizer、系统信息等);
-
各种模型之间格式差异大、难以统一;
-
不易扩展,不支持并发、分片、多模态等高级功能;
-
社区贡献难,文档稀缺,不利于后期维护。
三、GGUF 的优势:为什么 GGML 要升级?
GGUF 的设计目标就是解决 GGML 的一系列痛点。它的出现大大提升了本地推理体验,主要优势如下:
| 优势 | 说明 |
|---|---|
| ✅ 单一统一格式 | 无论你是 LLaMA、Mistral 还是 Qwen,GGUF 都支持 |
| ✅ 支持完整模型信息 | 包含 tokenizer、meta-info、prompt 格式等 |
| ✅ 多平台兼容 | 支持 x86、ARM、macOS Metal、Windows 等 |
| ✅ 推理效率高 | 原生支持 int4、int8、fp16 等多种量化精度 |
| ✅ 易于扩展 | 支持多文件组合、多语言字段、版本标识等 |
| ✅ 社区活跃 | llama.cpp、llama-cpp-python 等主流工具已原生支持 |
四、GGUF 的工作原理与结构简析
GGUF 本质上是一个结构化的模型描述容器,它会将以下组件打包到一个 .gguf 文件中:
📦 模型结构├── 超参数(模型类型、层数、维度等)├── 权重参数(可量化)├── 分词器(tokenizer)├── 模型描述(meta 信息、作者、版本)└── 可选扩展字段(训练数据描述、用途等)
这意味着,只需要一个
.gguf文件,就可以完整地在不同平台上运行一个语言模型,不依赖外部配置或权重补丁,真正实现一键部署、跨平台推理。
五、GGUF 的典型使用场景
-
本地聊天助手(如在桌面、手机上运行 Qwen、Mistral)
-
边缘设备部署(如树莓派、国产 ARM 板子)
-
无需联网的私有推理环境(保证数据隐私)
-
模型快速压缩与分享(GitHub/ Hugging Face 上广泛使用)
-
结合 llama.cpp/ollama 进行推理服务封装
六、GGUF 如何使用?——实战简要指南
工具推荐:
llama.cpp,llama-cpp-python,text-generation-webui,Ollama
✅ 步骤一:下载 GGUF 格式模型
可从以下平台获取:
-
ModelScope 魔搭社区
-
Hugging Face 模型仓库(gguf tag)
-
llama.cpp 官方推荐模型列表
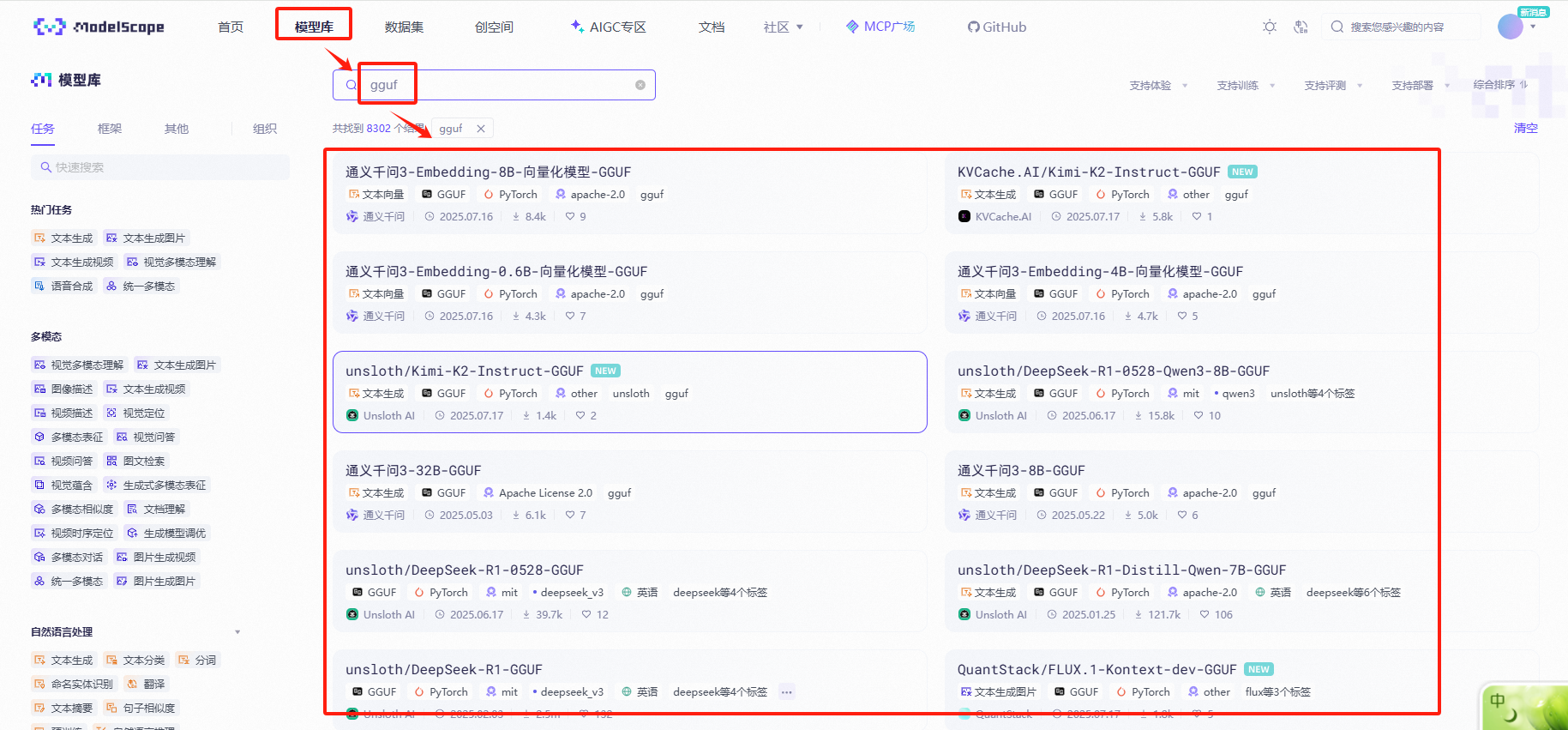
1、下面以【魔塔社区为例】,进入魔塔社区
模型库→搜索【gguf】→选择一个模型(可选)
2、获取下载链接
https://www.modelscope.cn/models/Qwen/Qwen3-0.6B-GGUF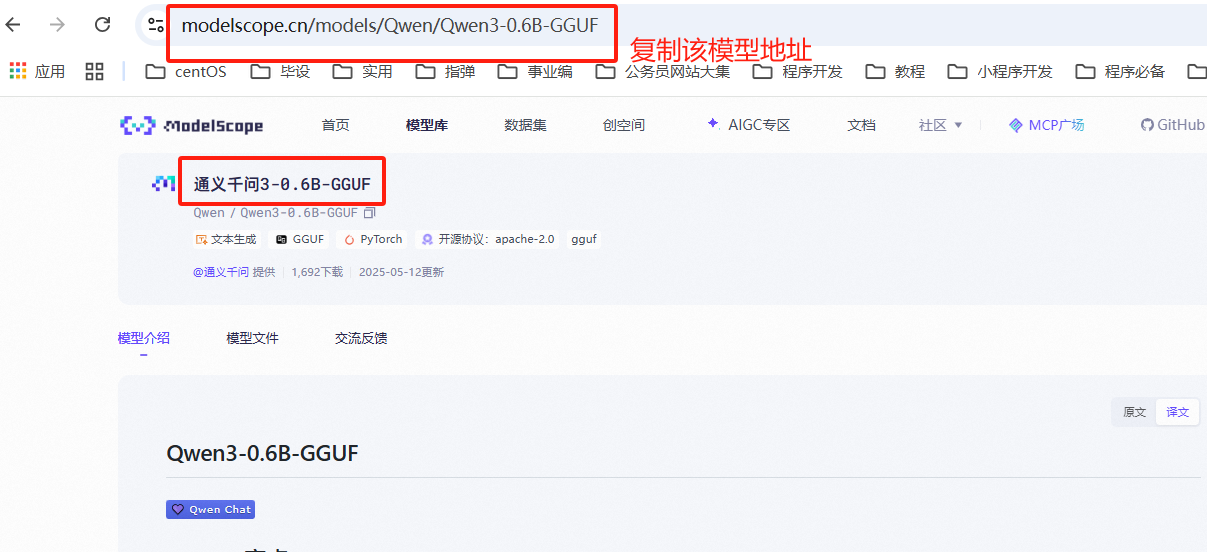
3、使用命令行下载
wget -c https://www.modelscope.cn/models/Qwen/Qwen3-0.6B-GGUF -O /mnt/workspace/model/qwen/qwen3-0.6b.gguf▲https://www.modelscope.cn/models/Qwen/Qwen3-0.6B-GGUF表示模型地址
▲/mnt/workspace/model/qwen/qwen3-0.6b.gguf:表示模型存放路径
✅ 步骤二:准备运行环境
1. 安装 Python 和 llama-cpp-python
建议用 Python 虚拟环境,操作示例:
#创建虚拟环境download_model
python3 -m venv download_model#激活虚拟环境:download_model
source download_model/bin/activate#安装依赖
pip install --upgrade pip
pip install llama-cpp-python
2. 准备 C++ 版 llama.cpp(可选)
如果想用更高性能或者无 Python 环境,也可从 llama.cpp 编译使用。
✅ 步骤三:运行推理
1、以 llama.cpp 为例:
./main -m /mnt/workspace/model/qwen/qwen3-0.6b.gguf -p "你好,请问你是谁?" -t 8
▲/mnt/workspace/model/qwen/qwen3-0.6b.gguf 表示gguf文件路径
-m指定模型文件路径
-p提示语句
-t线程数(根据CPU核数调整),可不写
2、以 llama-cpp-python 为例(Python 环境):
from llama_cpp import Llamallm = Llama(model_path="models/qwen3/qwen3-0.6b.gguf")prompt = "你好,请问你是谁?"
response = llm(prompt)print(response)
七、不同模型格式对比
7.1 对比表
| 模型格式 | 描述 | 是否可以直接调用 | 支持的框架/工具 | 优缺点 |
|---|---|---|---|---|
| GGUF | 优化过的生成模型格式,主要用于推理 | ✅ 直接调用,使用 llama-cpp 或 llama-cpp-python | llama-cpp, llama-cpp-python | 优化存储和推理性能,适合本地推理,支持多平台 |
PyTorch .pt | PyTorch 模型文件,包含模型结构和权重 | ❌ 需要 PyTorch 框架加载 | PyTorch, transformers | 适用于深度学习研究,广泛应用于 NLP 和 CV |
TensorFlow .h5 | Keras 保存的模型格式(基于 TensorFlow) | ❌ 需要 TensorFlow 或 Keras 框架加载 | TensorFlow, Keras | 适合深度学习部署,兼容性强,但不支持跨框架 |
| ONNX | 跨平台的开放神经网络交换格式,支持多种框架之间转换 | ✅ 通过 onnxruntime 直接调用 | onnxruntime, PyTorch, TensorFlow | 跨平台,框架无关,适合模型转换与部署 |
| SavedModel (TF) | TensorFlow 的原生保存格式,适合大规模部署 | ✅ 直接调用,使用 TensorFlow 加载 | TensorFlow | 高效存储和部署,TensorFlow 专用 |
Keras .h5 | Keras 保存的模型格式,通常用于小型模型和部署 | ✅ 直接调用,使用 Keras 或 TensorFlow 加载 | Keras, TensorFlow | 适合快速实验和部署,但不支持跨框架兼容 |
7.2 详细说明
-
GGUF 格式:
-
优点:专为推理优化,支持高效加载和推理,可以在本地机器上直接调用,适用于资源有限的环境。
-
缺点:目前支持的工具较少,主要依赖
llama-cpp和llama-cpp-python,不适合深度定制。
-
-
PyTorch
.pt格式:-
优点:广泛应用于研究和实际应用,支持灵活的训练和推理操作。
-
缺点:需要加载模型权重,不能直接调用。
-
-
TensorFlow
.h5格式:-
优点:Keras 保存的格式易于使用,广泛应用于深度学习任务。
-
缺点:需要 TensorFlow 或 Keras 框架进行加载和运行,不能直接调用。
-
-
ONNX 格式:
-
优点:跨框架支持,能够在 PyTorch、TensorFlow 和其他深度学习框架间共享模型,适合模型的转换与部署。
-
缺点:需要
onnxruntime等工具来加载和推理,运行时不如框架原生支持直接调用方便。
-
-
SavedModel (TF):
-
优点:TensorFlow 原生支持的格式,支持高效的存储和推理,适合大规模生产环境。
-
缺点:TensorFlow 专用,不支持其他框架。
-
-
Keras
.h5格式:-
优点:适用于 Keras 和 TensorFlow,轻量且方便用于快速实验和部署。
-
缺点:缺少跨框架兼容性,适合简单模型的使用,不支持复杂定制。
-
7.3 小结
-
GGUF 格式:如果你专注于推理,且希望高效地加载和运行大模型,GGUF 是非常合适的选择,尤其适用于本地运行和部署。
-
PyTorch/TensorFlow:适用于需要训练或细节定制的场景,但这些格式通常不适合直接调用,需要依赖相应框架来加载和推理。
-
ONNX:适合跨框架使用,尤其是模型转换和跨平台部署时,可以不依赖特定框架。
八、未来展望:GGUF 会统一大模型推理标准吗?
目前来看,GGUF 已逐步成为大模型 轻量级本地推理的事实标准,尤其在以下方面:
-
社区兼容广泛(llama.cpp / Ollama / Kobold / webui)
-
模型更新频率高(如 Qwen、Yi、Mistral 均已支持)
-
性能与精度不断优化(支持分组量化、KV缓存等)
🎯 潜在趋势:
-
向 多模态模型 拓展(如图文、语音大模型)
-
融入 WebAssembly / edge AI 场景
-
推动与 ONNX 等格式的 互转生态
八、总结
GGUF = 面向未来的本地推理模型通用格式
如果说 GGML 是本地 AI 推理的起点,那么 GGUF 就是它的成熟版本。它统一了模型格式,降低了部署门槛,提升了运行效率,为轻量化、隐私、安全本地 AI 应用开辟了广阔空间。
对于个人开发者、AI 工程师或企业部署者来说,掌握 GGUF 的使用与生态,将是未来大模型落地的基本能力之一。