Python编程进阶知识之第二课学习网络爬虫(requests)
目录
1.网络爬虫介绍
1 网络爬虫库
2.robots.txt 规则
2.requests 库和网页源代码
1.requests 库的安装
2.网页源代码
3.获取网页资源
1. get () 函数
(1.) get()搜索信息
(2.) get()添加信息
2.返回 Response 对象
(1).Response 的属性
(2).设置编码
(3).返回网页内容
4.提交信息到网页
1.post () 函数
2.上传文件的方法
5.代理服务器
1.获取代理服务器
2.使用代理服务器
1.网络爬虫介绍
网络爬虫通俗来讲就是使用代码将 HTML 网页的内容下载到本地的过程。爬取网页主要是为了获取网页中的关键信息,例如网页中的数据、图片、视频等。Python 语言中提供了多个具有爬虫功能的库,在学习和实践过程中一定要严格遵守网站提供的爬取规则。
1 网络爬虫库
urllib库:是 Python 自带的标准库,无须下载、安装即可直接使用。urllib库中包含大量的爬虫功能,但代码编写略显复杂。requests库:是 Python 的第三方库,需要下载、安装之后才能使用。由于requests库是在urllib库的基础上建立的,它包含urllib库的功能,这使得requests库中的函数和方法的使用更加友好,因此requests库的代码看起来更加简洁、方便。scrapy库:是 Python 的第三方库,需要下载、安装之后才能使用。scrapy库是一个适用于专业爬虫开发的网络爬虫库。scrapy库集合了爬虫的框架,通过框架可创建一个专业爬虫系统。selenium库:是 Python 的第三方库,需要下载、安装后才能使用。selenium库可用于驱动计算机中的浏览器执行相关命令,而无须用户手动操作。常用于自动驱动浏览器实现办公自动化和 Web 应用程序测试。
这里我主要介绍requests库和后面的selenium库,如果感兴趣可以再去学习更高深的scrapy库,这两个库学好足够人工智能领域使用了。
2.robots.txt 规则
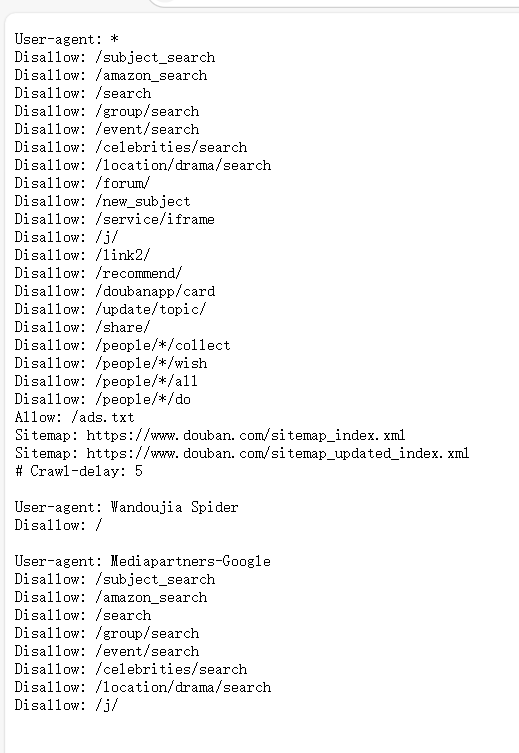
我们需要掌握爬取规则,不是网站中的所有信息都允许被爬取,也不是所有的网站都允许被爬取。在大部分网站的根目录中存在一个robots.txt文件,该文件用于声明此网站中禁止访问的 url 和可以访问的 url。用户只需在网站域名后面加上/robots.txt即可读取此文件的内容。以豆瓣为例。下面就是豆瓣的robots规则,disallow就是表示不允许被爬取的文件。
2.requests 库和网页源代码
1.requests 库的安装
pip install requests2.网页源代码
打开网页右击就可以看到查看页面源代码
3.获取网页资源
requests库具有获取网页内容和向网页中提交信息的功能,我主要介绍如何获取网页内容及如何对获取到的内容进行处理。
1. get () 函数
requests库获取 HTML 网页内容的方法是使用get()函数。其使用形式如下:
requests.get(url, params=None, **kwargs)url:需要获取的 HTML 网址(也称 url)。params:表示可选参数,以字典的形式发送信息,当需要向网页中提交查询信息时使用。**kwargs:表示请求采用的参数。
该函数返回一个由类Response创建的对象。类Response位于requests库的models.py文件中
import requests
r = requests.get('https://www.ptpress.com.cn/')
print(r.text)结果就是该网页的源代码
(1.) get()搜索信息
当在网页中搜索人民邮电出版社中的某些指定信息时,可以在搜索框中输入搜索信息,例如输入关键词 “java”, https://www.ptpress.com.cn/search?keyword=excel从搜索结果网页中可以看到当前页面的网址为 https://www.ptpress.com.cn/search?keyword=excel 。search表示搜索,keyword表示搜索的关键词(这里为java,表示需要搜索的关键词为 “java”),?用于分隔search和keyword。
import requests
r = requests.get('https://www.ptpress.com.cn/search?keyword=word')
print(r.text)第 2 行代码用于实现在人民邮电出版社官网中搜索关键词为 “word” 的信息。
(2.) get()添加信息
get()函数中第 2 个参数params会以字典的形式在url后自动添加信息,需要提前将params定义为字典。
import requests
info = {'keyword':'Excel'}
r = requests.get('https://www.ptpress.com.cn/search', params=info)
print(r.url)
print(r.text) 第 2 行代码建立字典info,包含一个键值对。
第 3 行代码使用get()函数获取网页,由于get()中包含参数params,因此系统会自动在url后添加字典信息,形式为https://www.ptpress.com.cn/search?keyword=excel,该使用形式便于灵活设定需要搜索的信息,并且可以添加或删除字典信息。
第 4 行代码输出返回的Response对象中的url,即获取网页的url。
2.返回 Response 对象
通过get()函数获取 HTML 网页内容后,由于网页的多样性,通常还需要对网页返回的Response对象进行处理。
(1).Response 的属性
Response包含的属性有status_code、headers、url、encoding、cookies等。
status_code(状态码):当获取一个 HTML 网页时,网页所在的服务器会返回一个状态码,表明本次获取网页的状态。例如访问人民邮电出版社官网,当使用get()函数发出请求时,人民邮电出版社官网的服务器接收请求信息后,会先判断请求信息是否合理,如果请求合理则返回状态码 200 和网页信息;如果请求不合理则返回一个异常状态码。
| 状态码 | 类别 | 含义 |
|---|---|---|
| 100 | 信息性状态码 | 继续。客户端应继续其请求。 |
| 101 | 信息性状态码 | 切换协议。服务器根据客户端的请求切换协议。 |
| 200 | 成功状态码 | 成功。请求已成功处理。 |
| 301 | 重定向状态码 | 永久移动。请求的资源已永久移动到新 URL。 |
| 302 | 重定向状态码 | 临时移动。请求的资源临时移动到新 URL。 |
| 304 | 重定向状态码 | 未修改。资源自上次请求后未修改,可以使用缓存版本。 |
| 400 | 客户端错误状态码 | 错误请求。服务器不理解请求的语法。 |
| 401 | 客户端错误状态码 | 未授权。请求需要身份验证。 |
| 403 | 客户端错误状态码 | 禁止访问。服务器理解请求客户端的请求,但是拒绝执行此请求。 |
| 404 | 客户端错误状态码 | 未找到。请求的资源不存在。 |
| 405 | 客户端错误状态码 | 方法禁用。禁用请求中指定的方法。 |
| 408 | 客户端错误状态码 | 请求超时。服务器等待请求超时。 |
| 429 | 客户端错误状态码 | 请求过多。用户在给定的时间内发送了太多请求。 |
| 500 | 服务器错误状态码 | 内部服务器错误。服务器遇到错误,无法完成请求。 |
| 501 | 服务器错误状态码 | 尚未实施。服务器不支持请求的功能,无法完成请求。 |
| 502 | 服务器错误状态码 | 错误网关。服务器作为网关或代理,从上游服务器收到无效响应。 |
| 503 | 服务器错误状态码 | 服务不可用。服务器目前无法使用(由于超载或停机维护)。 |
| 504 | 服务器错误状态码 | 网关超时。服务器作为网关或代理,但是没有及时从上游服务器收到请求。 |
import requests
r = requests.get('https://www.ptpress.com.cn/')
print(r.status_code)
if r.status_code == 200:print(r.text)
else:print('本次访问失败') headers(响应头):服务器返回的附加信息,主要包括服务器传递的数据类型、使用的压缩方法、语言、服务器的信息、响应该请求的时间等。
url:响应的最终url位置。
encoding:访问r.text时使用的编码。
cookies:服务器返回的文件。这是服务器为辨别用户身份,对用户操作进行会话跟踪而存储在用户本地终端上的数据
(2).设置编码
当访问一个网页时,如果获取的内容是乱码,这是由网页返回的编码错误导致的,可以通过设置requests.get(url)返回的Response对象的encoding属性来修改Response对象中text文本内容的编码方式。同时Response对象提供了apparent_encoding()方法来自动识别网页的编码方式,不过由于此方法是由机器自动识别,小概率存在识别错误的情况
Response对象.encoding = Response对象.apparent_encodingimport requests
r = requests.get('此处填入百度官网地址.com')
r.encoding = r.apparent_encoding
print(r.text)(3).返回网页内容
Response对象中返回网页内容有两种方法,分别是text()方法和content()方法,其中text()方法在前面的内容中有介绍,它是以字符串的形式返回网页内容。而content()方法是以二进制的形式返回网页内容,常用于直接保存网页中的媒体文件。
import requests
r = requests.get('https://cdn.ptpress.com.cn/uploading/Material/978-7-115-41359-8/72jpg/41359_1.jpg')
f2 = open('b.jpg', 'wb')
f2.write(r.content)
f2.close()下载人民邮电出版社官网中的图片,执行代码后将在相应文件夹中存储一张图片
4.提交信息到网页
requests库除了可以从网页中获取资源,还可以使用post()请求实现将信息上传到网站服务器中。
1.post () 函数
post()函数可用于向网站发送数据请求。其使用形式如下:
requests.post(url, data=None, json=None, **kwargs)- 参数
url:表示需要发送数据的目标网址。 - 参数
data:表示需要发送的数据对象,可以为字典、元组、列表、字节数据或文件。 - 参数
json:表示需要发送的数据对象,该数据对象为 JSON 数据(具体内容见 17.3 节)。 - 参数
**kwargs:表示请求采用的可选参数。
返回值:使用post()函数后返回一个Response对象。
import requests
d = {'OldPassword':'123456python', 'NewPassword':'123python', 'ConfirmPassword':'123python'}
r = requests.post('https://account.ryjiaoyu.com/change-password', data=d)
print(r.text) 第 2 行代码使用字典的形式保存了需要上传的数据。
第 3 行代码使用post()函数访问修改密码网页url,并提交修改密码数据。
执行代码后本质上还无法完成使用代码修改密码,因为在修改密码前还需要登录账户,这里代码并没有实现账户的登录,此处仅展示上传表单数据的方法。
2.上传文件的方法
如果需要将文件上传到网页中,可以使用files参数,该参数的内容为文件对象。
import requests
fp = {'file':open('bitbug.ico', 'rb')} # 上传的图片
r = requests.post('可上传图片的网址', files=fp)
print(r.text) 第 2 行代码创建了一个字典fp,其中键"file"对应的值为使用open()函数打开的图片对象。
第 3 行代码使用了post()函数上传这张图片,执行代码后会将此图片上传到网站服务器。
5.代理服务器
1.获取代理服务器
当爬取某些网站的网页资源时,如果请求次数较少,一般能正常获取内容,但是一旦开始大规模且频繁地爬取数据,网站可能会弹出验证码对话框,或者跳转到登录认证页面,甚至可能直接封禁客户端的 IP(Internet Protocol)地址,导致用户在一定时间段内无法再次访问该网站。为避免此种情况,可以使用代理服务器获取网。
代理服务器是介于客户端和网站服务器之间的一台中转站服务器。代理服务器的工作流程是客户端向代理服务器发出url请求,代理服务器接收到请求后,向指定服务器发出url请求,并将获取的网页返回给客户端,而不是直接从客户端到服务器获取网页。当客户端频繁爬取某个网站的信息时,由于中间使用了代理服务器,代理服务器会直接从服务器获取网页内容。
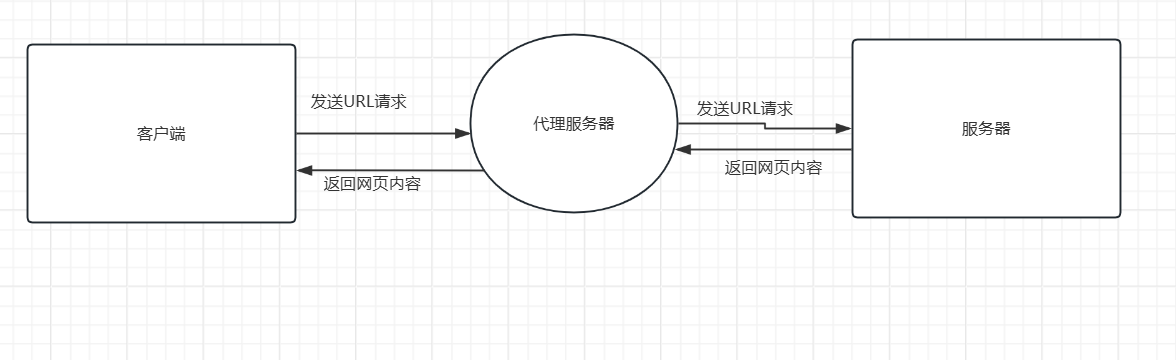
2.使用代理服务器
将get()、post()函数中的第 3 个参数设置为proxies,即表示使用代理服务器。
import requests
proxie = {'http':'http://代理服务器地址:ip'}
r = requests.get('https://www.ryjiaoyu.com/', proxies=proxie)
print(r.text) 第 2 行代码创建了一个字典,字典中的键http对应的值表示一个免费的代理服务器。
第 3 行代码在get()函数中填入参数proxies,且其值为字典proxie,表示在访问人民邮电出版社社区官网时,会通过 IP 地址为 115.29.199.16:8118 的代理服务器来间接访问。代理服务器获取到网页内容后,会将网页内容转发给客户端。