Java并发编程第三篇(深入解析Synchronized)
1. Synchronized简介:一个常见的并发“陷阱”
在正式开始学习新知识前,我们不妨先来看一个现象,这是一个很多并发编程新手都会遇到的“陷阱”:
public class SynchronizedDemo implements Runnable {// 共享变量private static int count = 0;public static void main(String[] args) {// 创建10个线程for (int i = 0; i < 10; i++) {Thread thread = new Thread(new SynchronizedDemo());thread.start();}try {// 等待所有线程执行完毕Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("result: " + count);}@Overridepublic void run() {// 每个线程对count累加100万次for (int i = 0; i < 1000000; i++)count++;}
}
这段代码的意图很明确:开启10个线程,每个线程都对静态变量count累加100万次。从逻辑上推断,最终结果理应是 10 * 1,000,000 = 10,000,000。然而,如果你运行这段代码,会发现几乎每次都得不到这个正确答案,而且每次的运行结果都可能不同。
这是为什么呢?有什么解决方案?这就是我们今天要深入探讨的核心议题。
在上一篇博文中,我们已经了解了Java内存模型(JMM)的知识,并且知道并发问题的根源主要在于JMM的抽象设计——即主内存与线程工作内存交互导致的可见性问题,以及指令重排序导致的有序性问题。count++这个操作并非原子性,它在底层被分为了“读-改-写”三步,这就为线程不安全埋下了伏笔。
那么,如何解决共享数据的线程安全问题?一个很自然的想法就是建立一种秩序,让所有线程排好队,一个一个地、依次去读写这个共享变量,这样每个线程操作的就永远是最新值,问题也就迎刃而解了。在Java中,synchronized关键字正是实现这种“排队”机制的利器。
虽然synchronized这种互斥同步机制在某些场景下会有效率问题,但它依然是Java并发编程的基石,是其他高级并发容器实现的基础。透彻地理解它,不仅能大大提升我们对并发编程的认知,从功利的角度说,它也是面试中无法绕开的高频考点。好了,下面,就让我们一起深入这个关键字的内部世界。
2. Synchronized实现原理
在Java代码中,synchronized可以灵活地应用在代码块和方法中。根据其修饰的位置不同,其锁定的对象也不同,我们可以将其归纳为以下几种使用场景:
!(https://i.imgur.com/rN5G255.png)
如上图所示,synchronized可以用在实例方法和静态方法上,也可以用在代码块中。这里需要特别注意一点:当synchronized修饰静态方法或以ClassName.class为锁对象时,它锁住的是这个类的Class对象。这意味着,即便你new出多个不同的实例,当它们调用这个同步方法时,依然会互相阻塞,因为它们竞争的是同一把“类锁”。
现在我们知道了如何使用synchronized,但仅仅会用是远远不够的。你不好奇这个关键字背后,JVM究竟为我们做了什么吗?让我们像侦探一样,从字节码的蛛丝马迹中寻找答案。
2.1 对象锁(Monitor)机制:底层探秘
我们先来看一个简单的示例,并观察它的字节码:
public class SynchronizedBytecodeDemo {public static void main(String[] args) {synchronized (SynchronizedBytecodeDemo.class) {// 同步代码块}method(); // 调用同步方法}private synchronized static void method() {// 同步静态方法}
}
通过javap -v SynchronizedBytecodeDemo.class命令,我们可以一窥其字节码的奥秘:
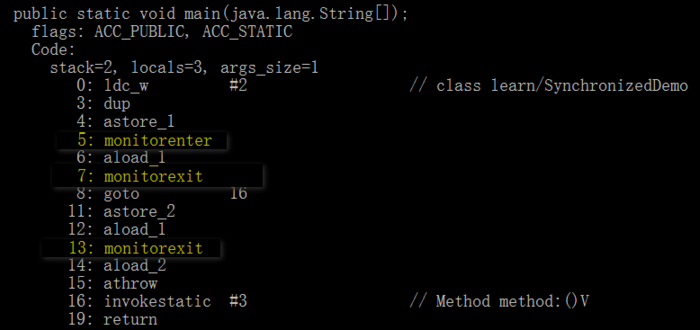
请注意上图中高亮的部分。我们发现,同步代码块的实现依赖于monitorenter和monitorexit这两条指令。当线程执行到monitorenter时,它会尝试获取对象的监视器(Monitor);当执行到monitorexit时,则会释放该监视器。而对于同步方法,虽然字节码中没有直接显示这两条指令,但其方法访问标志(flags)中会包含ACC_SYNCHRONIZED,JVM会根据这个标志,隐式地为方法调用加上monitorenter和monitorexit操作。
由此可见,synchronized的核心,就是对一个被称为“监视器”(Monitor)的对象的获取和释放。这个获取过程是互斥的,即同一时刻只有一个线程能成功持有Monitor。
一个有趣的问题是:如果一个线程已经持有了某个对象的锁,它在同步块内又尝试去获取同一个对象的锁(比如调用另一个同步方法),会怎么样?从上图的字节码中可以看到,静态同步方法method()只有一个monitorexit指令,并没有monitorenter。这就是锁的重入性:在同一个锁程中,线程无需再次获取同一把锁。其原理是,每个对象关联的Monitor内部都有一个计数器,线程每获取一次锁,计数器加一;每释放一次锁,计数器减一。只要计数器不为零,就代表当前线程持有该锁。
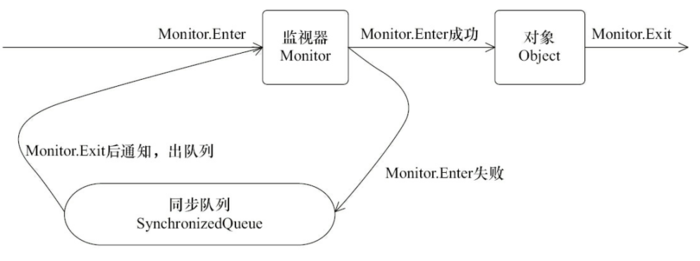
我们可以用一个更形象的比喻来理解这个机制:每个对象都像一个带锁的房间,房间的钥匙就是Monitor。任何线程想进入这个房间(访问同步代码),都必须先拿到这把唯一的钥匙。如果获取失败,该线程就会被阻塞在房间门口,进入一个“同步队列”中排队等候(线程状态变为BLOCKED)。当持有钥匙的线程从房间出来并归还钥匙后,在门口排队的线程们才有机会再次争抢这把钥匙。
2.2 Synchronized的Happens-Before关系
在上一篇文章中我们详细讨论过Happens-Before规则。抱着学以致用的原则,我们现在来分析synchronized对应的监视器锁规则:对同一个监视器的解锁(unlock),happens-before于后续对该监视器的加锁(lock)。
我们来看一段代码:
public class MonitorDemo {private int a = 0;public synchronized void writer() { // 1. 加锁a++; // 2. 临界区操作} // 3. 解锁public synchronized void reader() { // 4. 加锁int i = a; // 5. 临界区操作} // 6. 解锁
}
假设线程A调用writer(),线程B调用reader()。它们之间的Happens-Before关系如下图所示:
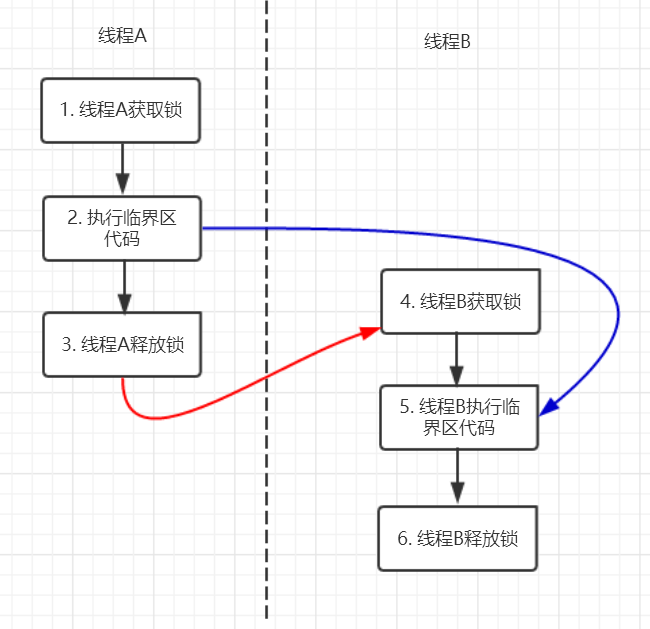
图中,黑色的箭头代表由“程序顺序规则”推导的关系。红色的箭头是关键,它由“监视器锁规则”保证:线程A的解锁操作(节点3)happens-before于线程B的加锁操作(节点4)。再结合“传递性”规则,我们可以清晰地推导出一个至关重要的关系:节点2 happens-before 节点5。
这个关系意味着什么?根据Happens-Before的定义,如果A happens-before B,则A的执行结果对B可见。这意味着,线程A执行a++的结果,对于后续获取锁并执行int i = a;的线程B来说,是绝对可见的。线程B读取到的a值一定是1,而不是旧的0。
2.3 锁获取和锁释放的内存语义
从JMM的抽象内存模型角度看,synchronized的Happens-Before关系是如何实现的呢?这就要归结于其锁获取和释放的内存语义。
我们可以把这个过程想象成两个线程通过主内存进行的一次“数据交接”:
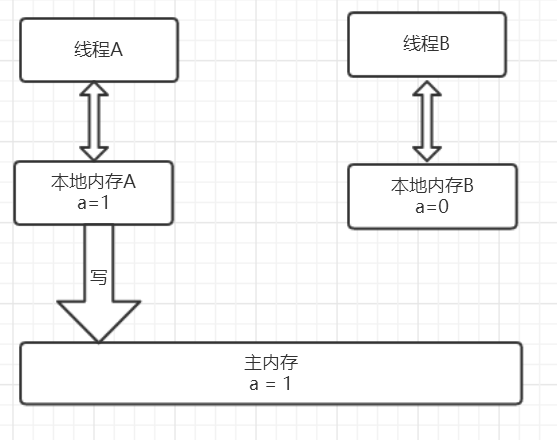
- 线程A释放锁时:它必须把自己工作内存中对共享变量的修改,全部刷新到主内存中。这就像完成工作后,把最终的报告文件存放到公共的服务器上。
- 线程B获取锁时:它必须先清空自己的工作内存,然后从主内存中重新加载共享变量的最新值。这就像开始新工作前,先从公共服务器上下载最新的报告文件。
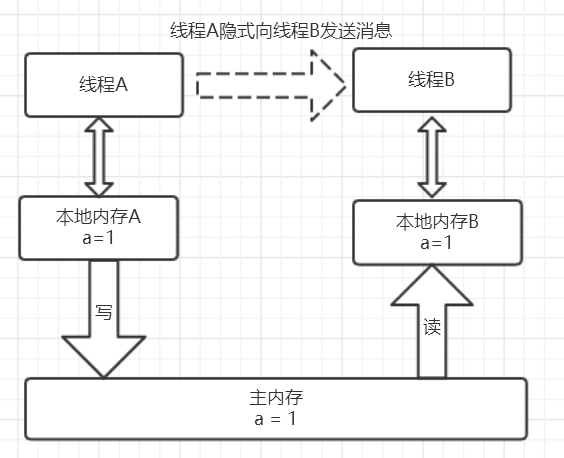
这一“写回”和“重新加载”的强制规定,确保了线程间的通信。线程A通过主内存告诉线程B:“我们共享的数据现在是最新版本了!”。这完美地解释了为什么synchronized能够保证可见性,也再次印证了2 happens-before 5的结论。
3. Synchronized优化:从重量级到自适应
通过上面的讨论,我们对synchronized应该有了比较深刻的印象。它最大的特征就是互斥性,保证了在同一时刻只有一个线程能够进入临界区。但这种“一夫当关,万夫莫开”的模式,在线程竞争激烈时,会涉及操作系统的线程阻塞和唤醒,开销巨大,因此早期的synchronized被称为重量级锁。
既然“排队通过”的形式无法改变,那么我们能不能让“每次通过的速度”变快一点呢?这就好比去收银台付款,过去用现金,找零耗时;现在用移动支付,扫码即走。同样是排队,但每个人的处理时间大大缩短,整体效率就提升了。Java的开发者们也是基于类似的思路,对synchronized进行了令人钦佩的优化。自JDK 1.6起,synchronized不再是“一根筋”的重量级锁,而是引入了偏向锁和轻量级锁,形成了一套随着竞争情况自动升级的锁机制。
要理解这套精妙的优化,有两个前置知识点需要我们先了解:CAS操作和Java对象头。
3.1 前置知识一:CAS操作
3.1.1 什么是CAS?
传统锁(如未优化的synchronized)是一种悲观锁策略,它假设每次访问临界区都会产生冲突,所以先加锁阻塞其他线程再说。而CAS(Compare-and-Swap,比较并交换)则是一种乐观锁策略。它假设线程访问共享资源时大概率不会冲突,因此不会阻塞其他线程,所有线程都可以“同时”向前尝试。
那么,如果真的出现冲突了怎么办?CAS通过“比较并交换”这个原子操作来鉴别。其过程可以通俗地理解为CAS(V, O, N),包含三个值:
- V: 内存地址中存放的实际值。
- O: 线程预期的旧值。
- N: 准备要更新的新值。
当且仅当内存中的实际值V和线程预期的旧值O相同时,才说明这个值没有被其他线程修改过,此时才会将新值N赋给V。如果V和O不相同,则说明值已经被其他线程改了,本次操作失败,然后线程会重新尝试(这个过程称为“自旋”),直到成功为止。
3.1.2 CAS的优缺点
synchronized(未优化前)的主要问题在于,线程竞争会引发内核态的线程阻塞和唤醒,性能开销大。而CAS是“非阻塞同步”,线程不会被挂起,而是在用户态不断自旋尝试,避免了上下文切换的开销。这是它最大的优势。
当然,CAS也有其固有的问题:
- ABA问题: 如果一个值从A变为B,又变回了A,CAS会误认为它没有变过。解决方案是引入版本号,如
AtomicStampedReference。 - 自旋时间过长: 如果竞争非常激烈,线程长时间自旋会持续消耗CPU资源。
- 只能保证一个共享变量的原子操作: 对多个变量操作时,需要将它们封装成一个对象,再使用
AtomicReference来保证原子性。
3.2 前置知识二:Java对象头
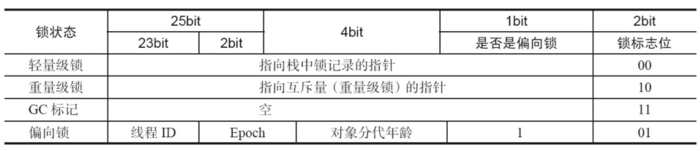
synchronized锁的是对象,那么锁的状态信息是存放在哪里的呢?答案就在Java对象头中。对象头里的Mark Word区域,在不同状态下存储着不同的信息,包括对象的HashCode、GC分代年龄,以及最重要的——锁状态标志。

3.3 锁的升级之路
在Java SE 1.6中,锁共有4种状态,级别从低到高依次是:无锁状态 -> 偏向锁状态 -> 轻量级锁状态 -> 重量级锁状态。锁会随着竞争情况逐渐升级,但不能降级,目的是为了在不同场景下提供最优的性能。
偏向锁
HotSpot的作者经过研究发现,在绝大多数情况下,锁不仅不存在多线程竞争,而且总是由同一个线程多次获得。为了让这种场景下获取锁的代价降到最低,引入了偏向锁。
当一个线程首次访问同步块时,它会通过CAS操作,将自己的线程ID记录在对象头的Mark Word中。此后,该线程再进入和退出该同步块时,无需任何加锁解锁操作,只需简单检查一下Mark Word中的线程ID是否是自己,开销极低。
只有当其他线程尝试竞争这个锁时,偏向锁才会撤销,并根据情况升级为轻量级锁或重量级锁。
轻量级锁
当出现第二个线程竞争锁时,偏向锁就会升级为轻量级锁。此时,线程不会直接被阻塞,而是会通过自旋的方式尝试获取锁。
其加锁过程是:JVM在当前线程的栈帧中创建一块名为“锁记录”(Lock Record)的空间,将对象头中的Mark Word复制到其中。然后,线程尝试用CAS将对象头中的Mark Word替换为指向这个锁记录的指针。如果成功,则获得锁。如果失败,表示有竞争,线程就会自旋等待。
解锁时,线程会用CAS将之前复制的Mark Word替换回对象头。如果失败,说明在持有锁期间有其他线程在竞争,锁就会膨胀为重量级锁。
重量级锁
一旦锁膨胀为重量级锁,它就和我们最初理解的synchronized一样了。所有尝试获取锁的线程都会被阻塞,进入同步队列排队,等待持有锁的线程释放锁后唤醒它们。
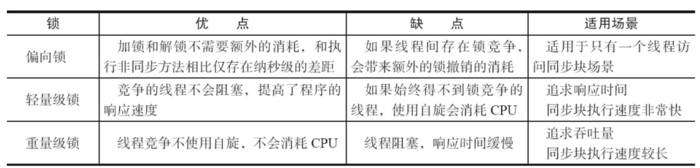
3.4 各种锁的比较
| 锁状态 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加解锁几乎没有额外开销 | 存在竞争时有额外的撤销开销 | 只有一个线程访问同步块 |
| 轻量级锁 | 竞争的线程不会阻塞,响应速度快 | 如果长时间自旋会消耗CPU | 线程交替执行同步块,追求响应时间 |
| 重量级锁 | 线程竞争激烈时,自旋消耗CPU少 | 线程阻塞和唤醒开销大,响应慢 | 线程竞争激烈,追求吞吐量 |
4. 一个例子:回到起点
经过上面的理解,我们现在应该知道该怎样解决文章开头的那个问题了。只需稍作修改:
public class SynchronizedDemo implements Runnable {private static int count = 0;public static void main(String[] args) {// ... (省略main方法中不变的代码)}@Overridepublic void run() {// 对共享变量的复合操作加锁synchronized (SynchronizedDemo.class) {for (int i = 0; i < 1000000; i++)count++;}}
}
通过在run方法中对count++的循环操作加入synchronized代码块,并使用类锁,我们保证了在任何时刻,只有一个线程能够执行累加操作。这确保了每次累加都是在最新的count值上进行的,从而保证了内存的可见性和操作的原子性,最终得到正确的结果10,000,000。
当然,synchronized并非唯一的解决方案。基于我们对JMM和并发工具的理解,聪明的你,还能想到哪些其他的实现方式呢?比如使用AtomicInteger?这会是一个很好的练习。
参考文献:《Java并发编程的艺术》