【Linux系统】进程地址空间
1. 程序地址空间回顾
在【C++内存管理】时,我们有提到过内存分布,可是我们对他并不理解!这次我们再来回顾一下,可以先对其进行各区域分布验证:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int g_unval;
int g_val = 100;int main(int argc, char *argv[], char *env[])
{const char *str = "helloworld";printf("code addr: %p\n", main);printf("init global addr: %p\n", &g_val);printf("uninit global addr: %p\n", &g_unval);static int test = 10;char *heap_mem = (char*)malloc(10);char *heap_mem1 = (char*)malloc(10);char *heap_mem2 = (char*)malloc(10);char *heap_mem3 = (char*)malloc(10);printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)printf("read only string addr: %p\n", str);for(int i = 0 ;i < argc; i++){printf("argv[%d]: %p\n", i, argv[i]);}for(int i = 0; env[i]; i++){printf("env[%d]: %p\n", i, env[i]);}return 0;
}运行结果;
ltx@hcss-ecs-d90d:~/lesson5$ touch code.c
ltx@hcss-ecs-d90d:~/lesson5$ vim code.c
ltx@hcss-ecs-d90d:~/lesson5$ touch Makefile
ltx@hcss-ecs-d90d:~/lesson5$ vim Makefile
ltx@hcss-ecs-d90d:~/lesson5$ make
gcc -o code code.c
ltx@hcss-ecs-d90d:~/lesson5$ ./code
code addr: 0x55fbceb76189
init global addr: 0x55fbceb79010
uninit global addr: 0x55fbceb7901c
heap addr: 0x55fbd04566b0
heap addr: 0x55fbd04566d0
heap addr: 0x55fbd04566f0
heap addr: 0x55fbd0456710
test static addr: 0x55fbceb79014
stack addr: 0x7fff7f9936c0
stack addr: 0x7fff7f9936c8
stack addr: 0x7fff7f9936d0
stack addr: 0x7fff7f9936d8
read only string addr: 0x55fbceb77004
argv[0]: 0x7fff7f99473b
env[0]: 0x7fff7f994742
env[1]: 0x7fff7f994752
env[2]: 0x7fff7f994760
env[3]: 0x7fff7f99477a
env[4]: 0x7fff7f994790
env[5]: 0x7fff7f99479c
env[6]: 0x7fff7f9947b1
env[7]: 0x7fff7f9947c0
env[8]: 0x7fff7f9947cf
env[9]: 0x7fff7f9947e0
env[10]: 0x7fff7f994dcf
env[11]: 0x7fff7f994e04
env[12]: 0x7fff7f994e26
env[13]: 0x7fff7f994e3d
env[14]: 0x7fff7f994e48
env[15]: 0x7fff7f994e68
env[16]: 0x7fff7f994e71
env[17]: 0x7fff7f994e88
env[18]: 0x7fff7f994e90
env[19]: 0x7fff7f994ea3
env[20]: 0x7fff7f994ec2
env[21]: 0x7fff7f994ee5
env[22]: 0x7fff7f994f26
env[23]: 0x7fff7f994f8e
env[24]: 0x7fff7f994fc4
env[25]: 0x7fff7f994fd7
env[26]: 0x7fff7f994fe0
通过结果可以看到,地址时依次增大的
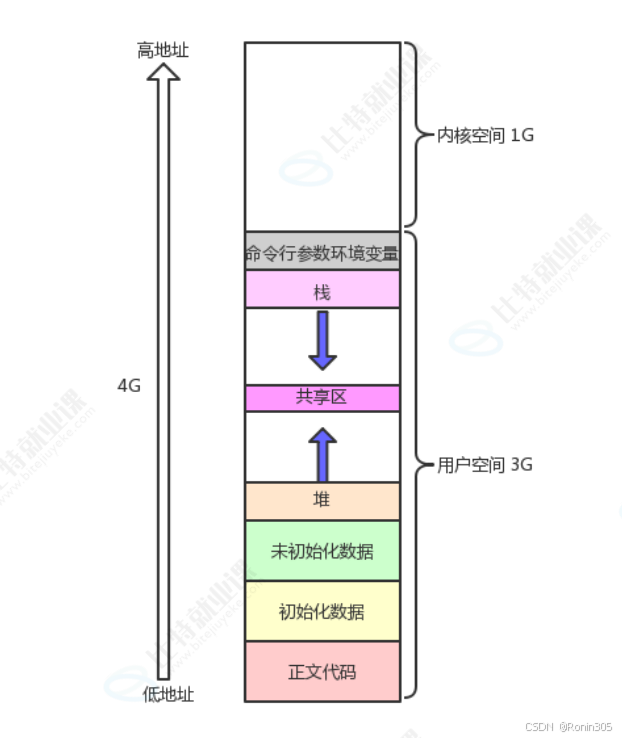
2. 虚拟地址
来段代码感受一下
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int gval = 0;int main()
{pid_t id = fork();if(id == 0){while(1){printf("子: gval: %d, &gval: %p, pid: %d, ppid: %d\n", gval, &gval, getpid(), getppid());sleep(1);gval++;}}else{while(1){printf("父: gval: %d, &gval: %p, pid: %d, ppid: %d\n", gval, &gval, getpid(), getppid());sleep(1);}}return 0;
}运行结果:
ltx@hcss-ecs-d90d:~/lesson5$ ./code
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
子: gval: 0, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
子: gval: 1, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
子: gval: 2, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
子: gval: 3, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
子: gval: 4, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
子: gval: 5, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
子: gval: 6, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
子: gval: 7, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
子: gval: 8, &gval: 0x55ab2eaf6014, pid: 878688, ppid: 878687
父: gval: 0, &gval: 0x55ab2eaf6014, pid: 878687, ppid: 878659
^C
父子进程共享代码段,但拥有独立的数据段(包括全局变量gval)。初始时,子进程是父进程的副本,因此gval初始值都为0,地址也相同。
运行结果显示:
- 父子进程输出的地址一致(例如,
&gval: 0x55ab2eaf6014),但gval的值不同:父进程始终为0,子进程从0开始递增。
- 父子进程输出的地址一致(例如,
这证明变量gval在父子进程中是独立的副本:修改子进程的gval不影响父进程,反之亦然。
为什么地址相同但值不同?
- 在C/C++中,输出的地址是虚拟地址(virtual address),不是物理地址(physical address)。虚拟地址是进程视角的地址,由OS统一管理,每个进程都有自己的虚拟地址空间。
- 当fork()创建子进程时,OS为子进程复制父进程的虚拟地址映射,因此初始地址相同。但物理地址可能不同,因为OS将虚拟地址映射到不同的物理内存位置。
3. 进程地址空间
所以之前说‘程序的地址空间’是不准确的,准确的应该说成 进程地址空间 ,那该如何理解呢?看
图:
分页&虚拟地址空间
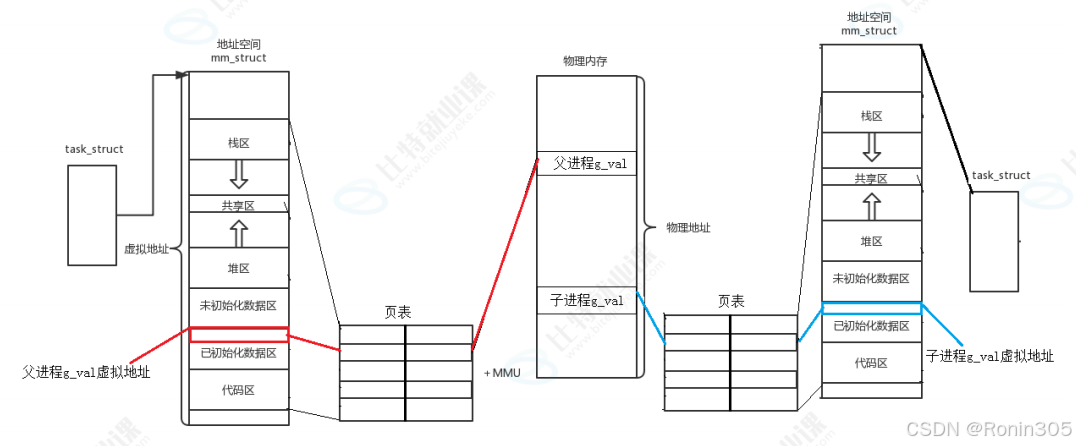
虚拟地址到物理地址的转换
- 当进程访问一个虚拟地址(如
0x55ab2eaf6014),MMU拦截该访问,查询页表找到对应的物理地址。父子进程可能有相同的虚拟地址,但页表映射到不同的物理地址,因此变量值独立。 - 在上面代码中,gval的虚拟地址相同,但物理地址不同:子进程的gval存储在另一个物理位置,导致值变化。(gval改变引起写时拷贝,在这之前子进程的虚拟地址空间和页表都是拷贝父进程的)
物理地址,用户一概看不到,由OS统一管理,OS必须负责将虚拟地址转化成物理地址:OS通过MMU硬件组件实现转换。MMU使用页表(page table)映射虚拟地址到物理地址,用户程序无法直接访问物理地址
一、再谈写时拷贝(COW)
写时拷贝是一种内存管理技术,用于在进程创建子进程时(例如通过fork()系统调用),避免立即复制父进程的内存页。具体步骤如下:
父进程和子进程共享内存页:在
fork()调用后,父进程和子进程共享相同的内存页。这意味着它们的虚拟地址空间中的某些区域(如已初始化数据区)指向相同的物理内存页。页表项设置为只读:为了实现写时拷贝,这些共享的内存页在页表中被标记为只读。这意味着如果任何一个进程尝试写入这些共享页,将会触发一个页错误(page fault)。
页错误处理:当发生页错误时,内核会检查错误的原因。如果是因为写操作导致的页错误,内核会执行以下操作:
- 复制页:内核会为写操作的进程(父进程或子进程)分配一个新的物理内存页,并将共享页的内容复制到新页中。
- 更新页表:内核会更新写操作进程的页表,使其指向新的物理内存页,并将该页标记为可写。
- 继续执行:进程继续执行,此时它对新页的写操作不会影响另一个进程。
二、如何理解虚拟地址空间
虚拟地址空间的概念
虚拟地址空间就像是一个虚拟的“地图”,程序中的每个变量、函数等都位于这个虚拟地图上的某个位置。这个“地图”对每个进程来说都是独立的,就像每个家庭都有自己的独立地址簿一样。
示例:
想象一下,一个城市中有许多图书馆。每个图书馆都有自己的书架编号系统,这些编号就像是虚拟地址。读者(程序)只需要根据书架编号(虚拟地址)就能找到书(数据)。不同图书馆的书架编号(虚拟地址)可能相同,但它们指向的是不同的书(不同的物理内存位置)。就好像在两个不同的图书馆中,都有编号为“123”的书架,但这两个书架上的书是完全不同的。图书馆管理员(操作系统)会将这些虚拟的书架编号(虚拟地址)映射到实际存放书籍的仓库位置(物理内存地址)。这样,读者(程序)不需要知道书籍实际存放的仓库位置,只需要知道图书馆内的书架编号(虚拟地址)就能访问书籍(数据)。
三、如何理解区域划分
区域划分的概念
区域划分是将虚拟地址空间按功能分割成不同区间(如代码区、堆区、栈区),每个区域通过 起始地址(start)和结束地址(end) 标记边界,由内核数据结构(如Linux的mm_struct)管理。区域可动态调整:扩大时修改end指针(如malloc申请堆空间),缩小时反向操作。
示例:
同桌两人共用一张100cm的课桌(虚拟地址空间)。他们在桌上画"三八线"划分区域:
- 小胖的区域:
start=0cm, end=50cm - 小美的区域:
start=50cm, end=100cm
这就像操作系统的mm_struct结构体记录了每个区域的边界。
当小美想扩大地盘时,她将三八线移到30cm处,此时:
- 小胖的区域变为:
start=0cm, end=30cm(缩小) - 小美的区域变为:
start=30cm, end=100cm(扩大)
这对应malloc扩大堆空间时,内核修改堆区的end值。
而小胖在50cm内放书包(堆区存变量)、小美在70cm处放水杯(栈区存局部变量),就像进程在不同虚拟区域存取数据。
4. 浅谈虚拟内存管理
由于刚开始学习,所以本篇文章只站在进程的角度去看待虚拟内存。
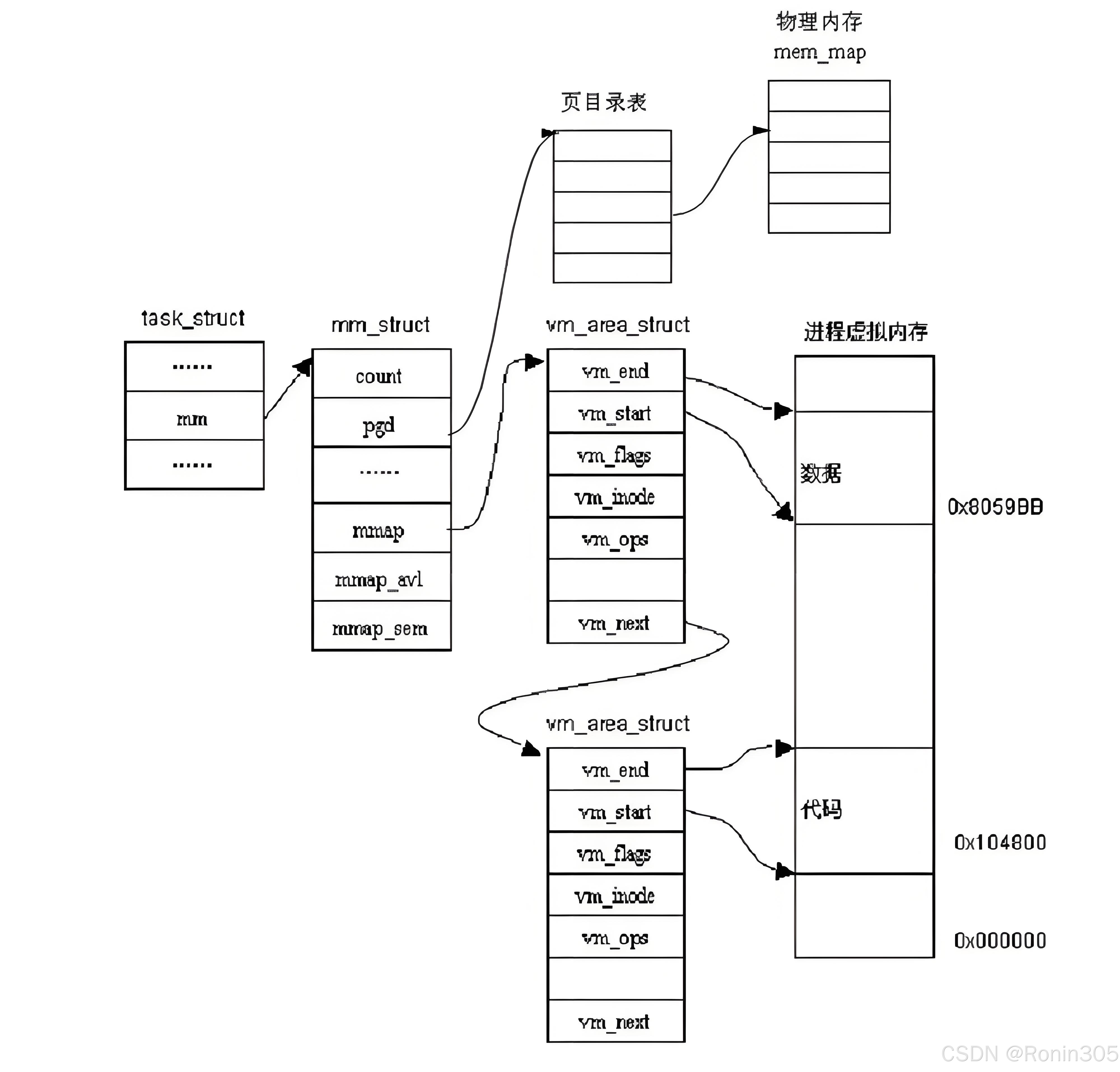
描述linux下进程的地址空间的所有的信息的结构体是 mm_struct (内存描述符)。每个进程只有一个mm_struct结构,在每个进程的 task_struct 结构中,有一个指向该进程的mm_struct结构体指 针。
1. mm_struct 的核心地位
作用:
mm_struct是描述整个进程用户空间虚拟地址空间的核心结构体,定义在include/linux/mm_types.h中 。独立性:每个进程拥有独立的
mm_struct,确保进程地址空间隔离 。与进程关联:在进程描述符
task_struct中,通过指针mm指向该进程的mm_struct:struct task_struct {struct mm_struct *mm; // 用户进程的地址空间描述符struct mm_struct *active_mm; // 内核线程借用前一个进程的地址空间 };- 用户进程:
mm指向自身的mm_struct。
内核线程:对于内核线程来说,mm字段通常为NULL。内核线程没有独立的用户空间地址,但它们可以使用任意进程的地址空间。此时,内核线程会使用active_mm字段来指向一个有效的地址空间。
- 用户进程:
可以说,mm_struct 结构是对整个用户空间的完整描述。在Linux内核中,每个进程都会拥有自己独立的mm_struct结构体实例,这个结构体包含了该进程所有内存管理相关的信息。正是由于这种独立性,才保证了每个进程都能拥有专属的虚拟地址空间,实现进程间的内存隔离。
从进程控制块(task_struct)到内存描述符(mm_struct)的关联关系如下:
- 在task_struct结构中,有一个名为"mm"的指针成员,它直接指向当前进程的内存描述符(mm_struct)
- 当进程创建时(fork系统调用),内核会为子进程分配一个新的mm_struct结构体实例
- 这个新的mm_struct会继承或复制父进程的地址空间布局,但实际物理内存会被标记为写时复制(COW)
进程的地址空间的分布情况:
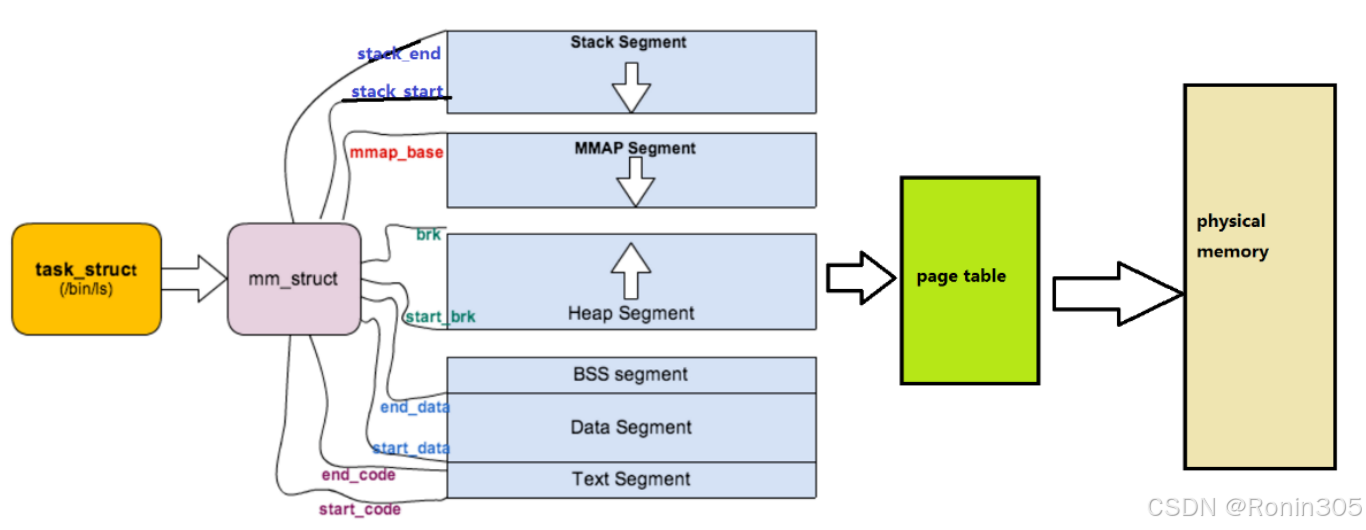
2. mm_struct 关键成员解析
(1) 虚拟内存区域管理
mmap:指向一个单链表 ——vm_area_struct链表的头部,链表中的每个节点都是一个vm_area_struct结构体,表示一个虚拟内存区域(VMA)。当进程的虚拟内存区域较少时,使用这种单链表的方式来组织。mm_rb:指向 红黑树根节点,树中的每个节点也是一个vm_area_struct结构体。当进程的虚拟内存区域较多时,使用红黑树来组织,以便更高效地进行查找、插入和删除操作。- 双结构协同:链表与红黑树同步维护,链表用于顺序遍历,红黑树用于快速查找 。
mmap_cache:缓存最近访问的 VMA,加速局部性访问 。
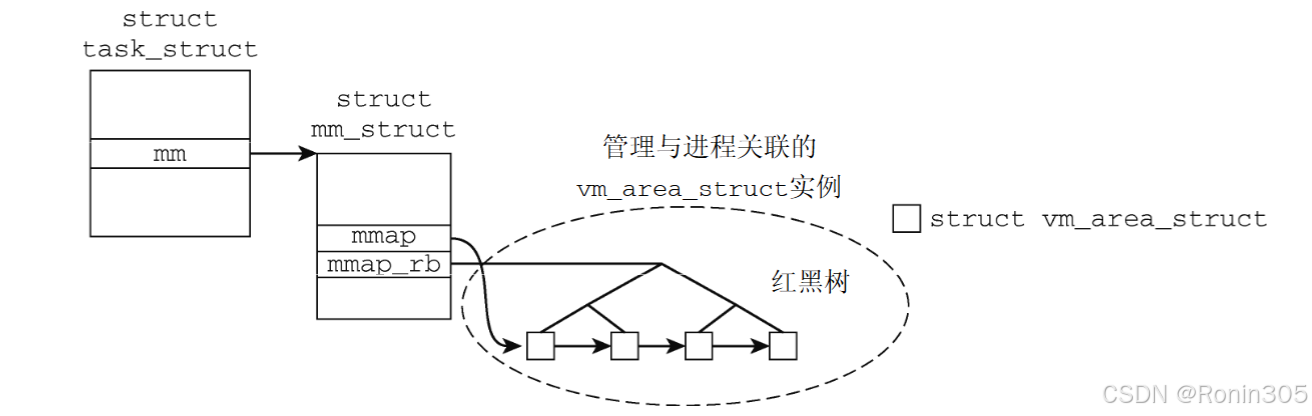
(2) 地址空间范围定义
task_size:用户空间大小(如 32 位系统为 3GB)。分段地址边界:
unsigned long start_code, end_code; // 代码段 unsigned long start_data, end_data; // 数据段 unsigned long start_brk, brk; // 堆(brk 动态扩展) unsigned long start_stack; // 栈起始地址 unsigned long arg_start, arg_end; // 命令行参数 unsigned long env_start, env_end; // 环境变量这些字段明确划分用户空间各区域 。
(3) 页表与计数
pgd:指向进程 页全局目录(Page Global Directory) ,管理虚拟到物理地址转换 。
mm_users:共享该地址空间的进程数(如线程共享)。mm_count:mm_struct的主引用计数,为 0 时释放结构体 。map_count:当前 VMA 的数量 。
(4) 同步与保护
mmap_sem:读写信号量,保护 VMA 修改操作(如mmap系统调用)。page_table_lock:自旋锁,保护页表和 RSS(常驻内存集)统计 。
struct mm_struct
{/*...*/struct vm_area_struct *mmap; /* 指向虚拟区间(VMA)链表 */struct rb_root mm_rb; /* red_black树 */unsigned long task_size; /*具有该结构体的进程的虚拟地址空间的⼤⼩*//*...*/// 代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。unsigned long start_code, end_code, start_data, end_data;unsigned long start_brk, brk, start_stack;unsigned long arg_start, arg_end, env_start, env_end;/*...*/
}3. 虚拟内存区域(VMA):vm_area_struct
vm_area_struct(简称 VMA)是 Linux 内核中描述进程虚拟地址空间中连续内存区域的核心数据结构。每个 VMA 代表一个具有相同属性(如访问权限、映射类型)的独立内存区间,例如代码段、堆、栈或内存映射文件。
VMA 的核心作用
内存区域抽象
将进程的虚拟地址空间划分为逻辑独立的区间(如代码段只读、堆可读写),每个区间对应一个 VMA。例如:- 代码段(
.text):VM_READ | VM_EXEC - 数据段(
.data):VM_READ | VM_WRITE - 共享库映射:
VM_READ | VM_SHARED
- 代码段(
缺页异常处理基础
当进程访问未分配物理页的虚拟地址时,内核通过 VMA 判断:- 该地址是否属于有效 VMA(
vm_start≤ 地址 <vm_end)。 - 访问权限是否匹配(通过
vm_flags校验)。 - 执行相应操作(如分配物理页、加载文件内容)。
(证据 1/9)
- 该地址是否属于有效 VMA(
支持高级内存操作
通过vm_ops函数表实现按需分配(Demand Paging)、写时复制(Copy-on-Write)等机制。
关键字段包括:
struct vm_area_struct {unsigned long vm_start; //虚存区起始unsigned long vm_end; //虚存区结束struct vm_area_struct *vm_next, *vm_prev; //前后指针struct rb_node vm_rb; //红⿊树中的位置unsigned long rb_subtree_gap;struct mm_struct *vm_mm; //所属的 mm_structpgprot_t vm_page_prot;unsigned long vm_flags; //标志位struct {struct rb_node rb;unsigned long rb_subtree_last;} shared;struct list_head anon_vma_chain;struct anon_vma *anon_vma;const struct vm_operations_struct *vm_ops; //vma对应的实际操作unsigned long vm_pgoff; //⽂件映射偏移量struct file * vm_file; //映射的⽂件void * vm_private_data; //私有数据atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMUstruct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMAstruct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endifstruct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;vm_start、vm_end:分别表示该虚拟内存区域的起始和结束地址。
vm_next、vm_prev:用于将多个vm_area_struct结构体连接成单链表。
vm_rb:用于将vm_area_struct结构体插入到红黑树中。
vm_mm:指向该虚拟内存区域所属的mm_struct结构体。
vm_page_prot、vm_flags:分别表示该虚拟内存区域的页面保护属性和标志位,用于控制对该区域的访问权限。
vm_ops:指向一个包含该虚拟内存区域操作函数的结构体,用于实现对该区域的特殊操作(如映射文件、共享内存等)。
vm_pgoff:表示文件映射的偏移量,当该虚拟内存区域映射到一个文件时,这个字段表示文件中的起始位置。
vm_file:指向该虚拟内存区域映射的文件对象(如果有的话)。
- 作用:将进程地址空间划分为不同属性的区域(如代码段只读、堆可读写)。
- 动态管理:通过
vm_ops实现按需分配物理页(Demand Paging)。
所以我们可以对上图在进行更细致的描述:
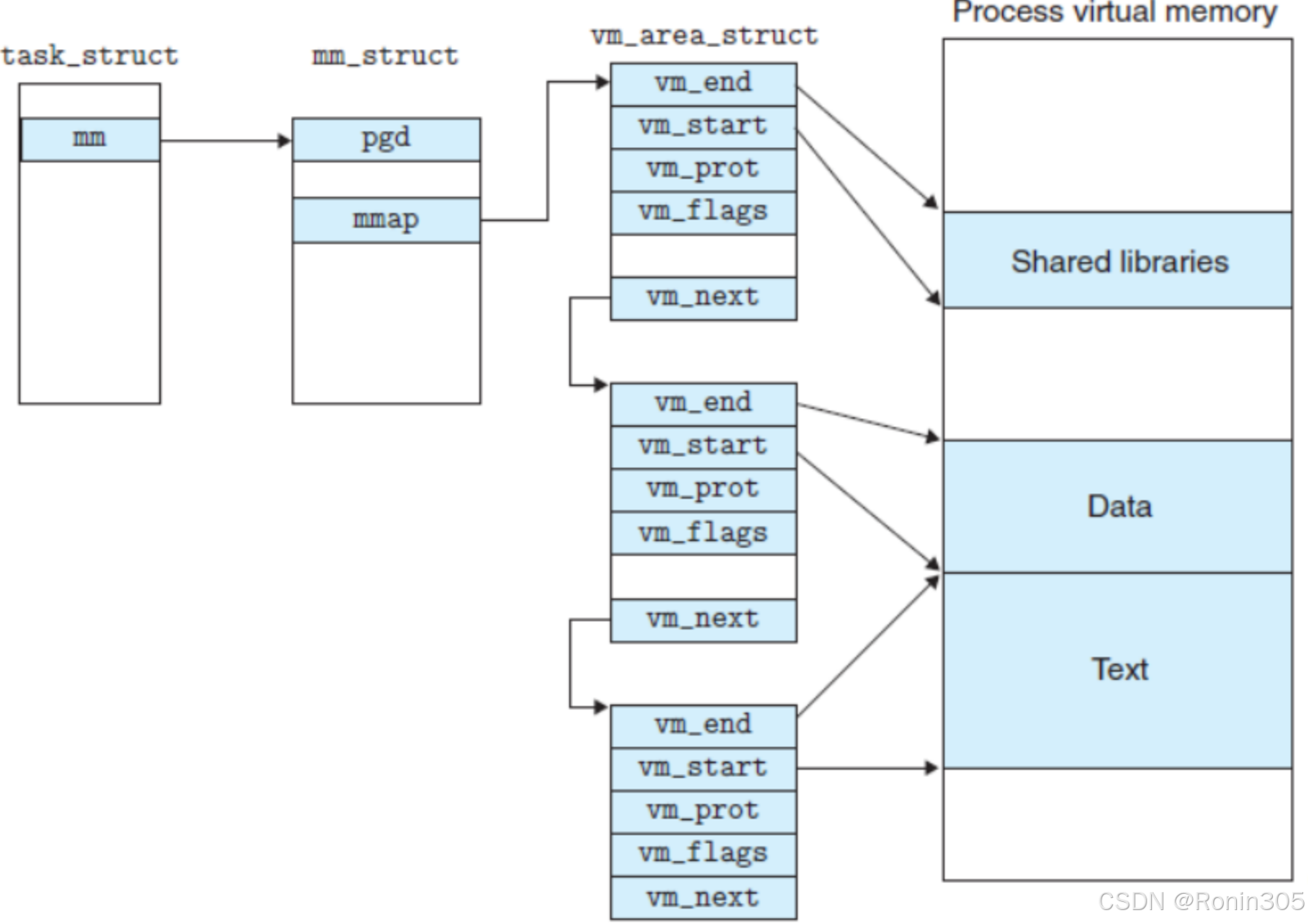
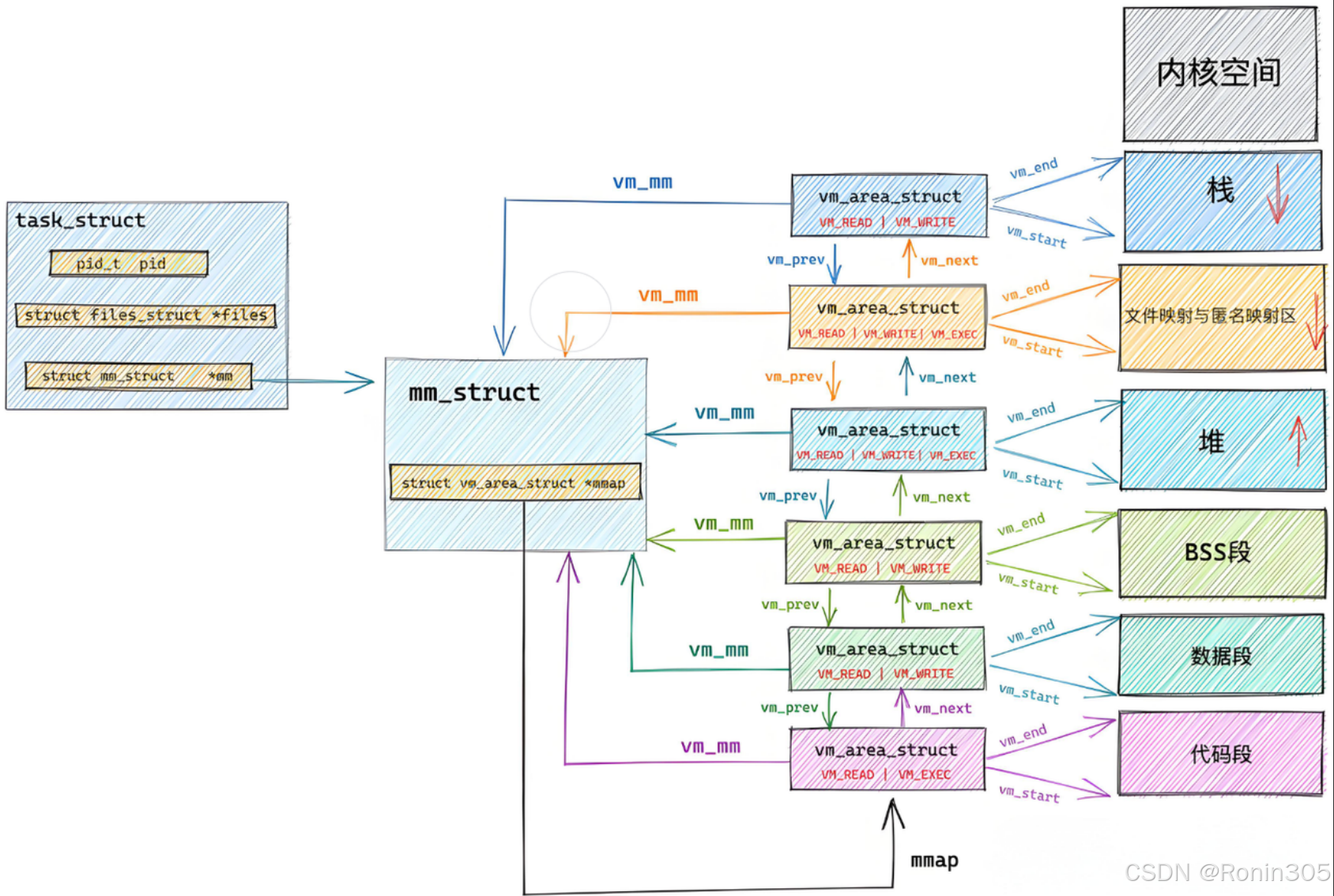
举例说明
假设一个进程调用了mmap系统调用,将一个文件映射到其虚拟地址空间中。此时,内核会执行以下步骤:
创建一个新的
vm_area_struct结构体,设置其vm_start和vm_end为映射区域的起始和结束地址。设置
vm_file指向该文件对象,并设置vm_pgoff为文件中的起始偏移量。根据文件的访问权限,设置
vm_flags和vm_page_prot。将该
vm_area_struct结构体插入到进程的mm_struct结构体中,可能是插入到单链表或红黑树中。更新进程的页表,使得用户空间的代码可以访问该映射区域。
通过vm_area_struct,Linux内核能够灵活地管理进程的虚拟内存区域,支持各种复杂的内存操作,如动态内存分配、文件映射、共享内存等。
5. 为什么要有虚拟地址空间
一、直接操作物理内存的三大问题
1. 安全风险:内存无隔离
- 问题:所有进程可直接读写任意物理内存,恶意程序可篡改系统内核或其他进程数据。
- 案例:木马病毒通过修改系统关键内存(如中断向量表)导致系统崩溃。
- 虚拟地址解决方案:
- 每个进程拥有独立的虚拟地址空间,通过页表映射到物理内存。
- 硬件(MMU)自动检查访问权限:进程只能访问自己页表映射的合法区域。
- 内核空间被标记为特权级(Ring 0),用户进程(Ring 3)无权访问。
2. 地址不确定性:程序加载位置随机
- 问题:程序每次运行时需加载到不同的物理地址,导致:
- 编译时无法确定变量/函数地址(需重定位)。
- 多进程运行时内存碎片化严重。
- 虚拟地址解决方案:
- 进程视角的虚拟地址空间连续且固定(如32位Linux进程从
0x08048000开始)。 - 实际物理内存通过页表分散映射,进程无需感知物理位置变化。
- 示例:程序代码段虚拟地址固定为
0x08048000,物理地址由OS动态分配。
- 进程视角的虚拟地址空间连续且固定(如32位Linux进程从
3. 效率低下:内存管理粗糙
- 问题:
- 交换效率低:物理内存不足时需将整个进程换出到磁盘,耗时极长。
- 内存浪费:进程即使只使用少量内存,也需预留连续物理空间。
- 虚拟地址解决方案:
- 按需分页(Demand Paging):
- 进程启动时仅分配虚拟地址空间,物理页在访问时动态分配。
- 如
malloc()申请1GB虚拟空间,实际物理内存可能为0。
- 页交换粒度细化:
- 以 页(通常4KB) 为单位换入/换出,而非整个进程。
- 写时复制(Copy-on-Write):
- 父子进程共享物理页,仅当修改时才复制新页,减少内存拷贝。
- 按需分页(Demand Paging):
二、虚拟地址空间的四大核心优势
1. 安全隔离:进程间零干扰
- 进程A无法访问进程B的虚拟地址空间,即使两者虚拟地址相同(如
0x4000)。 - 内核空间对用户进程不可见,防止恶意篡改。
2. 连续虚拟视图:简化程序开发
- 编译器可假设代码/数据从固定虚拟地址开始(如
.text段从0x08048000)。 - 程序员无需关心物理内存布局。
3. 物理内存超分配(Overcommit)
char *p = malloc(1024 * 1024 * 1024); // 申请1GB虚拟空间
// 实际物理内存可能尚未分配
- OS允许分配的总虚拟内存 > 物理内存 + 交换空间。
- 物理页仅在首次访问时分配(触发缺页异常)。
4. 高效内存管理
| 机制 | 作用 |
|---|---|
| 延迟分配 | 减少物理内存占用(如未初始化的数组不分配物理页) |
| 共享内存映射 | 多个进程通过页表映射到同一物理页(如共享库、IPC) |
| 内存碎片优化 | 物理页可分散存放,虚拟地址空间仍连续 |
三、关键机制:页表(Page Table)
虚拟地址空间的实现依赖硬件MMU和OS维护的页表:
虚拟地址 → MMU查询页表 → 物理地址
- 页表项(PTE) :存储虚拟页到物理页帧的映射及权限位(读/写/执行)。
- 多级页表:减少内存占用(如x86四级页表:PML4 → PDPT → PD → PT)。
四、案例解析
场景:进程A和B同时运行
- 虚拟视图:
- A的堆地址:
0x1a00000,B的堆地址:0x1a00000(相同虚拟地址)。
- A的堆地址:
- 物理实现:
- A的页表映射到物理页帧
100,B映射到物理页帧200。
- A的页表映射到物理页帧
- 访问流程:
- A访问
0x1a00000→ MMU通过A的页表找到物理页帧100。 - B访问相同虚拟地址 → MMU通过B的页表找到物理页帧
200。
- A访问
结论
虚拟地址空间通过 “间接层(Indirection)” 实现了:
- 安全隔离:硬件强制进程内存隔离。
- 地址确定性:虚拟地址固定,物理地址动态映射。
- 资源超分配:物理内存按需分配+页粒度交换。
- 管理解耦:进程管理(
task_struct)与内存管理(mm_struct)分离。
设计哲学:虚拟化是计算机系统的核心思想——用软件抽象(虚拟地址空间)解决硬件限制(物理内存缺陷),正如虚拟机抽象物理机器、文件抽象磁盘块。