YOLO算法原理
笔者喜欢直白的讲述方式,因此文中使用了大量比喻手法。
YOLO的起源
YOLO即you only look once,它一干活就是一整张图起干。以前也强调输入整张图,但是处理是局部的,每次只看窗口内的小块,做滑动窗口多次推理。YOLO做到了真正一次看整张图,只看一次,用卷积网络一次性预测所有位置的框和类别。
通俗点说,YOLO和滑动窗口对比就是分别用日光灯和手电筒在屋子里找东西的区别,手电筒要一个个找,YOLO直接开灯了。YOLO具有实时性优势,在实时检测场景中表现出色。
YOLOV1由Joseph Redmon等人于2015年提出,目标是兼顾速度和精度。
YOLO的一些基础原理
训练部分
1.YOLO的输入参数
图像以及目标框,还有标签以及置信度,这是YOLO的基础。
那么这是肉眼看见的图片,对于计算机而言,代码只处理数据,那么就要用一个合适的结构表示这张图片。
y=[Pc,bx,by,bh,bw,C1,C2,C3]y=[P_c,b_x,b_y,b_h,b_w,C_1,C_2,C_3]y=[Pc,bx,by,bh,bw,C1,C2,C3]
当然,这只是一个向量表示的方法。其中P表示置信度概率,四个b相关的参数表示B-BOX框的位置,方法是(x,y)坐标表示,加上框的height和width,C表示的是类别概率,供该网格所有边界框共享。
例如c1为猫,c2是狗,c3是老鼠,那么如果一张图标注的是猫,那么他在c部分的参数应该是[1,0,0],这是one-hot vector表示法。
2.YOLO的图像和标签处理
一般会把一张图划分成N*N的网格单元(以下简称格子),如果在划分后的格子内有识别目标存在,那么对应向量的就会有具体值,否则为0。
在实际过程中,可以看见,识别框会跨越几个格子。
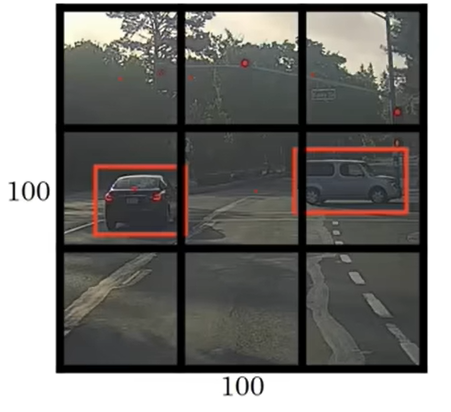
对此,YOLO以中心点为主,中心点落在那,就算在哪个格子里。而如果一个框内有多个目标呢?这里引入了NMS非极大值抑制,作用是解决多目标检测中框重叠的问题。如果两个框重合度高,大概率是同一个目标,只保留一个。判断的阈值是IOU,也就是交并比。
IOU=交集面积÷并集面积
IOU=交集面积÷并集面积
IOU=交集面积÷并集面积
IOU高说明两个框是同一个东西,NMS会按置信度排序,逐一比较IOU,剔除重叠度过高的框。
另外需要说明的是,这里的bx,by都是对于小格子来说,是通过转换而来的相对坐标。假设图片尺寸是WH,网格划分为SS,那么绝对坐标X,Y经过
X÷(W/S)=bx∣Y÷(H/S)=by
X÷(W/S)=b_x |Y÷(H/S)=b_y
X÷(W/S)=bx∣Y÷(H/S)=by
最后得到了相对坐标。这个相对坐标会在推理时还原。
最终的输出形状可以表示为S∗S∗(B∗5+C)S*S*(B*5+C)S∗S∗(B∗5+C) ,其中B是每个网格预测的边界框数,C是类别数。
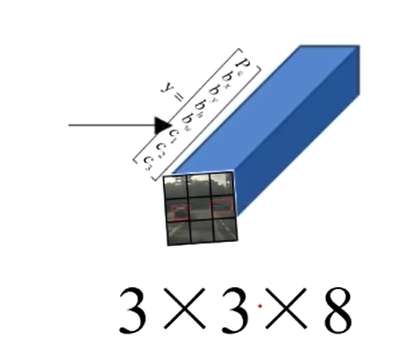
图中只有一个边界框,所以是8=(5∗1+3)8=(5*1+3)8=(5∗1+3)。
3.YOLO的训练过程
YOLO的整体结构为GoogleNet+24个卷积层+2个FC。

例如,YOLOv1常用 S=7S = 7S=7, B=2B = 2B=2, C=20C = 20C=20(PASCAL VOC数据集,除此之外另一个是COCO数据集),输出是 7∗7∗307* 7 * 307∗7∗30。
损失函数包括三部分:
- 定位损失:边界框坐标和大小的误差(平方和损失)。
- 置信度损失:预测框是否包含目标的误差。
- 分类损失:类别预测的误差。
通过反向传播最小化损失,优化网络参数,保存到 best.pt。
检测部分:
1.如何做检测
在训练中得到了best.pt,现在,我们输入图片,那么首先resize处理,划分网格。
随后运行卷积网络,CNN提取特征和预测,卷积部分负责提特征。全链接部分负责预测。
CNN提取特征后,我们得到了特征图,用边界框坐标确定B-BOX位置*(YOLOV2开始,利用Anchor思想对特征图中每个锚点都预定于B个B-BOX),之后全连接部分负责预测(在YOLOV3后改为全卷积网络)*,每个网格单元都会预测B各边界框和这些框的置信度分数。因此,对每个网格应用图像分类和定位处理,获得预测对象的边界框及其对应的类概率。
对CNN提取的特征和预测,并不是每个都需要,还要经过阈值处理筛查。
简单来说:YOLO把输入的图像划分完以后先“猜”出来几个框,然后筛掉那些不是的框,最后保留正确的框。即后处理步骤:
- 将相对坐标 bx,by,bh,bwb_x, b_y, b_h, b_wbx,by,bh,bw 转换回绝对坐标。
- 计算每个边界框的得分(Pc∗CiP_c * C_iPc∗Ci)。
- 应用置信度阈值过滤低分框。
- 用NMS去除冗余框。
怎么猜:
通过CNN提取特征图,然后每个网络根据特征“猜”出框的位置和类别。
如何猜:
通过回归直接输出对应向量。这些预测不是随机的,而是神经网络基于训练学到的权重直接回归出来的。训练时,模型通过最小化损失函数(比如平方误差损失)调整参数,使预测的框尽量贴近标注的真实框。在YOLOv1中,没有使用预定义的锚框(anchor boxes),模型直接预测坐标。而在YOLOv2及以后版本,引入了锚框,预测的是相对于锚框的偏移。
怎么筛:
NMS,目的是去除冗余框,确保每个目标只有一个代表性框。以IOU作为筛选标准。

最后经过以上的操作之后,得到的结果就是图像上标注出了检测目标框以及置信度和标签。
当然,这只是基本思想,当时还只是YOLOV1,尽管在当时具有划时代的性能和速度,但是也存在缺陷如对小目标和密集场景的检测较弱。而在V2和V3以及后续版本中,还存在很多的改进。