从规模到效率:大模型三大定律与Chinchilla定律详解
近年来,大语言模型(LLM)如 GPT、Claude、Gemini 等取得了惊人的突破,背后不仅是技术的堆叠,更有一套清晰的发展规律在支撑其演进。本文将系统性梳理被称为“大模型三大定律”的通用理论框架,并深入解析 DeepMind 提出的 Chinchilla 定律,它正深刻改变着我们对“模型训练策略”的理解。
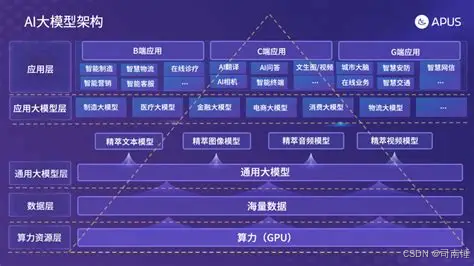
一、大模型三大定律:理解 LLM 的演化之道
1️⃣ 规模定律(Scaling Law)
模型越大,效果越好。
这一定律起源于 OpenAI 的研究(Kaplan et al., 2020),指出:随着模型参数量、训练数据量和计算资源的同步增长,模型性能(如语言理解、生成质量)呈幂律提升趋势。
公式形式:
Loss∝(Compute)−α\text{Loss} \propto (\text{Compute})^{-\alpha}
其中 α\alpha 是经验幂律系数,代表性能的提升速度。
典型例子: GPT-2 → GPT-3 → GPT-4,每一代都伴随参数规模和训练数据的飞跃。
2️⃣ 涌现定律(Emergence Law)
能力并非线性提升,而是“跃迁式”出现。
随着模型规模或训练 token 数超过某个临界点,大模型会突然展现出小模型不具备的新能力,如:
多轮对话理解
数学推理与代码生成
多模态对齐能力(如 GPT-4o)
这一现象被称为“能力涌现(Emergent Abilities)”,意味着模型具备了类人智能的某些关键特性。
3️⃣ 通用性定律(Generalization Law)
一个模型胜过千个模型。
大模型具有强泛化能力,能在多任务、多语言、多模态环境下展现统一的表现:
Zero-shot & Few-shot 迁移能力
无需特定微调就能执行复杂任务
统一 API 接口下处理图像、文本、音频等异构数据
这奠定了 AGI(通用人工智能)发展的技术基础。
二、Chinchilla 定律:重新定义“训练效率”
🐹 起源:DeepMind 的逆势思考
2022 年,DeepMind 在论文《Training Compute-Optimal Large Language Models》中提出了 Chinchilla 模型,首次系统地论证:
在固定计算预算下,更小的模型 + 更多的训练 token 更优。
与之相伴的经验规律,被称为“Chinchilla 定律”。
📈 定律公式(经验拟合)
N∝D0.73N \propto D^{0.73}
其中:
NN:模型参数量
DD:训练 token 总数
这个关系揭示了**“参数规模”与“数据量”应保持特定比例**,否则要么“训练不足”(undertrained),要么“资源浪费”。
🔬 实证对比:Chinchilla vs GPT-3
| 模型 | 参数量 | 训练数据量 | 训练效率 | 性能 |
|---|---|---|---|---|
| GPT-3 | 175B | 300B token | 未充分训练 | 一般 |
| Chinchilla | 70B | 1.4T token | 最优计算配置 | 更优表现 |
结果: Chinchilla 以更小的规模,在多个 benchmark 上全面超越 GPT-3。
🚀 为什么它颠覆了旧范式?
❌ 过去:只看参数越大越强
✅ 现在:重视数据 token 总量与训练轮次
这一观点已影响后续 LLaMA、Gemma 等新一代轻量大模型的设计。
三、总结:从“追大”到“追效”的转变
| 维度 | 大模型三定律 | Chinchilla 定律 |
|---|---|---|
| 目标 | 提升能力极限 | 提升训练效率 |
| 核心 | 越大越强 | 数据更重要 |
| 应用 | 多模态/通用智能 | 精算训练预算 |
| 代表 | GPT-4, Gemini, Claude | LLaMA, Chinchilla |