【尝试】基于openai-whisper进行语音转文字windows版本
1、下载ffmpeg
https://ffmpeg.org/download.html#build-windows
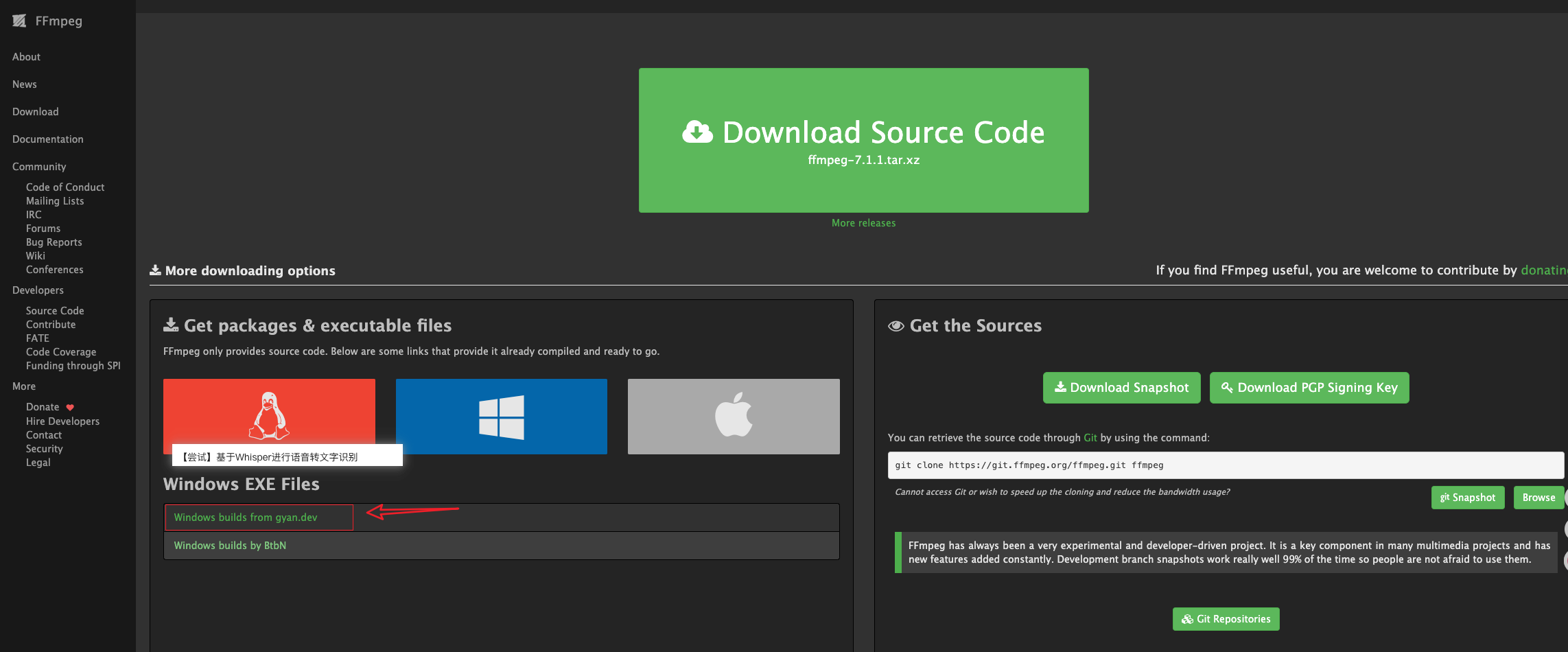
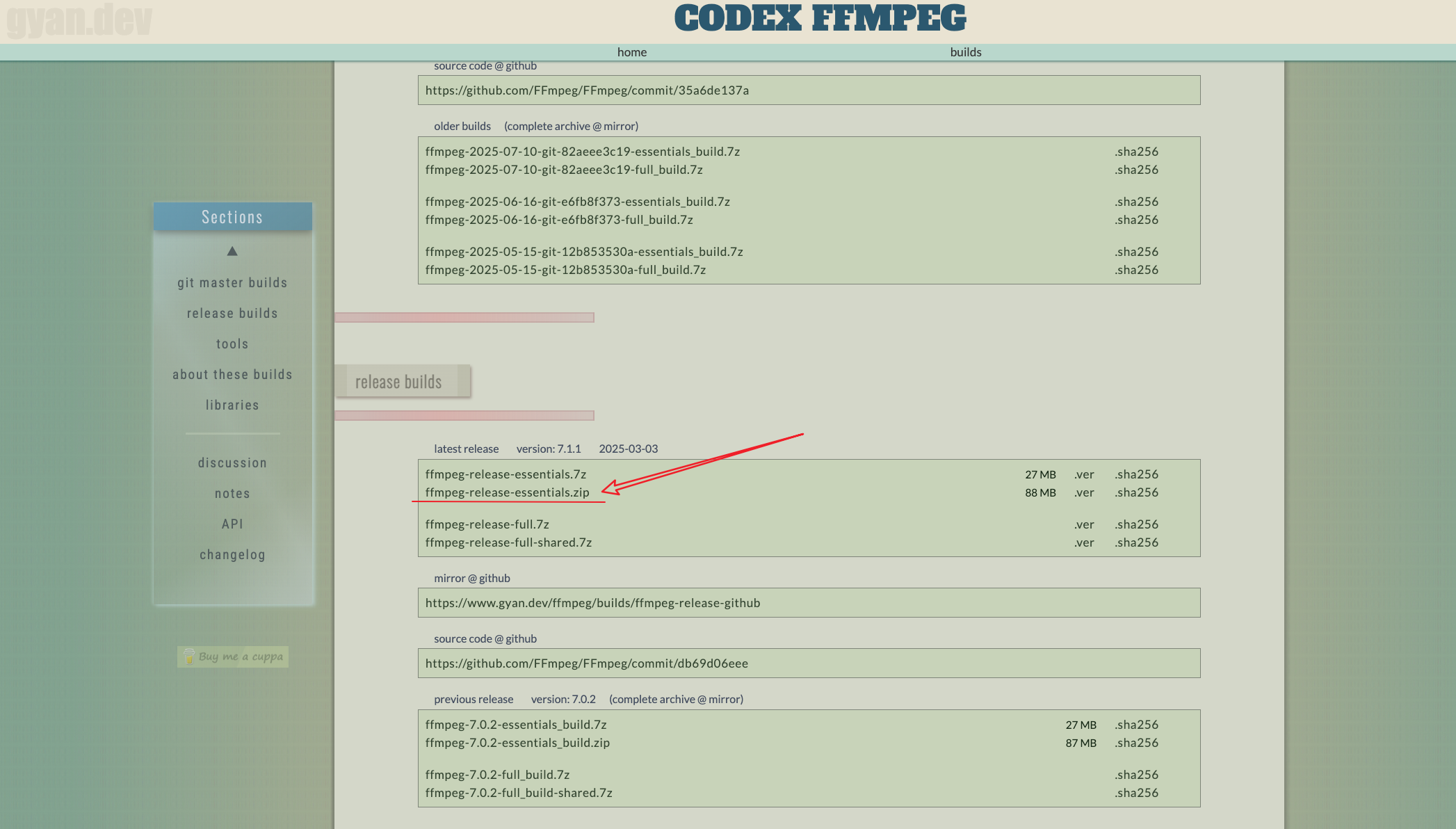
解压缩,并放置到指定位置
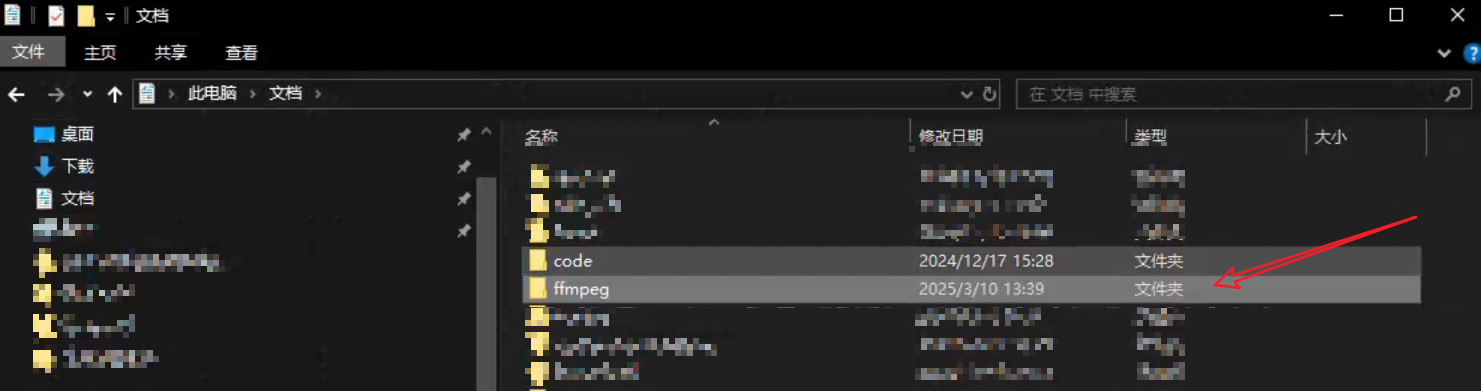
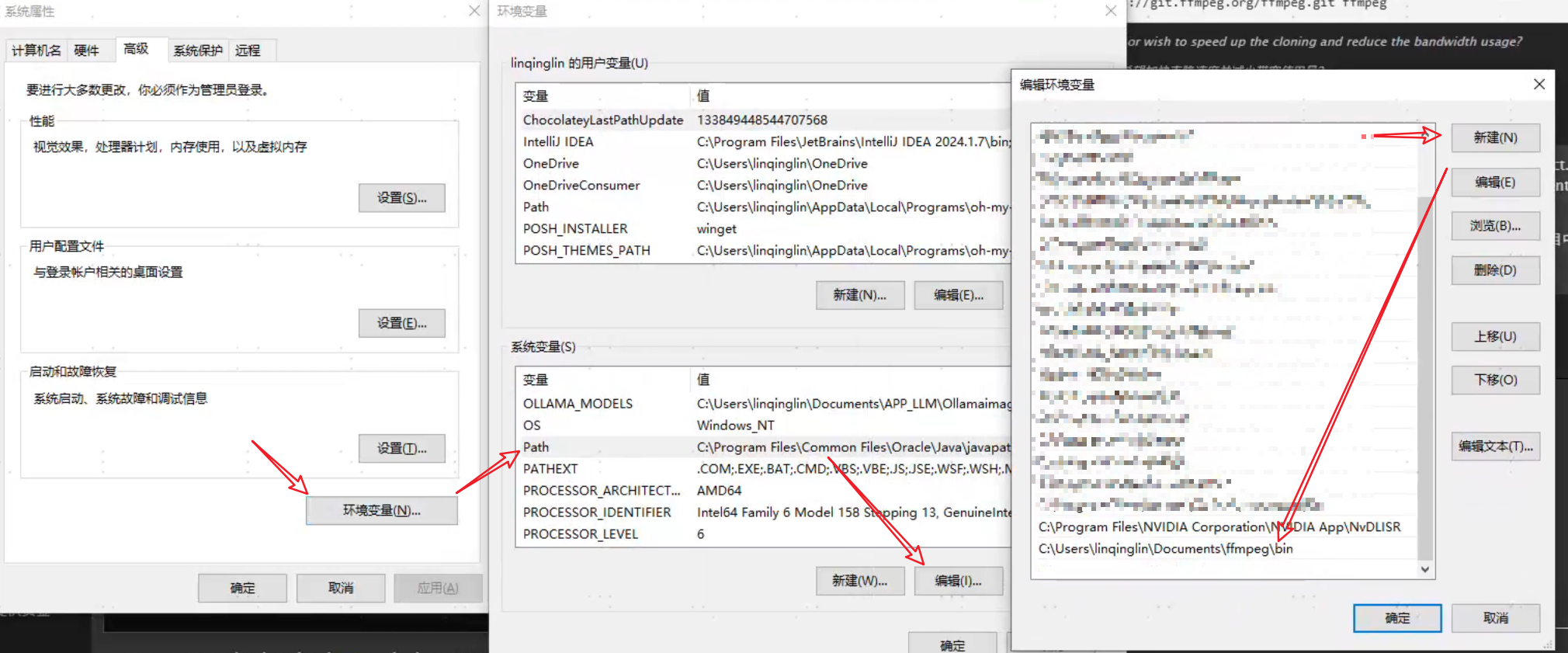
在环境变量中进行配置
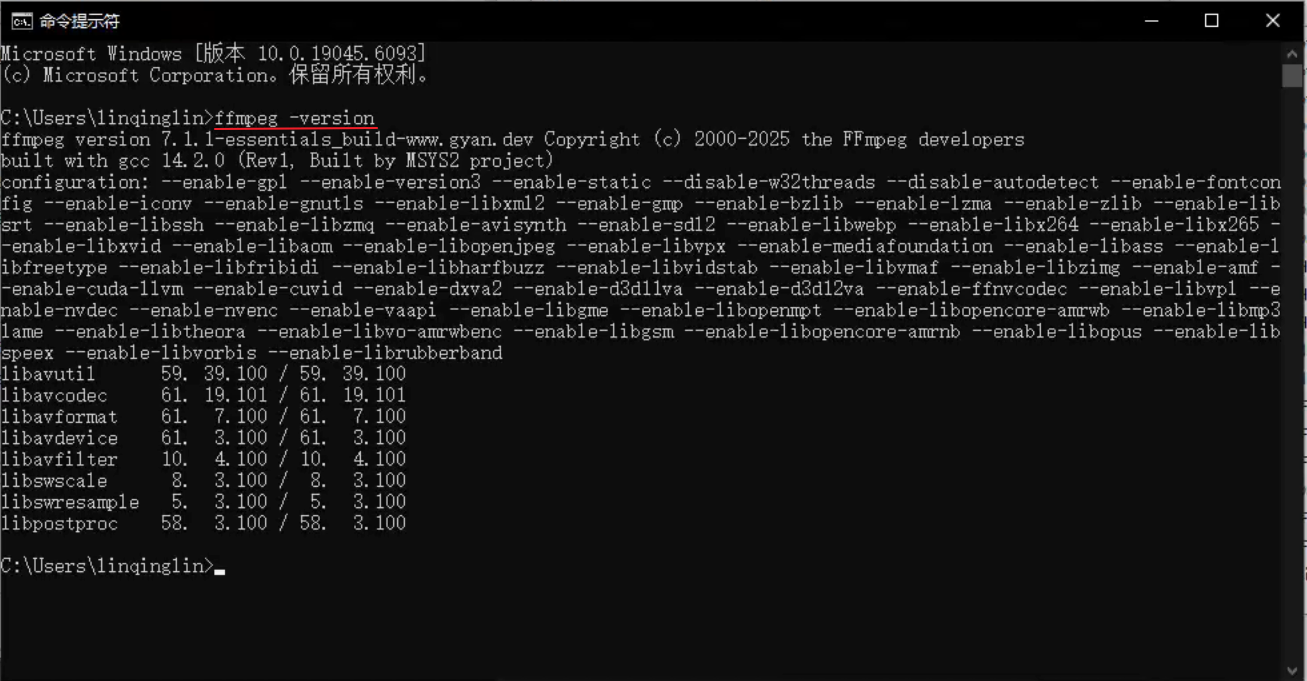
运行试看是否成功
2、确认电脑CUDA版本
下载Nvidia app
https://www.nvidia.cn/software/nvidia-app/
安装完成后,在终端输入:
nvidia-smi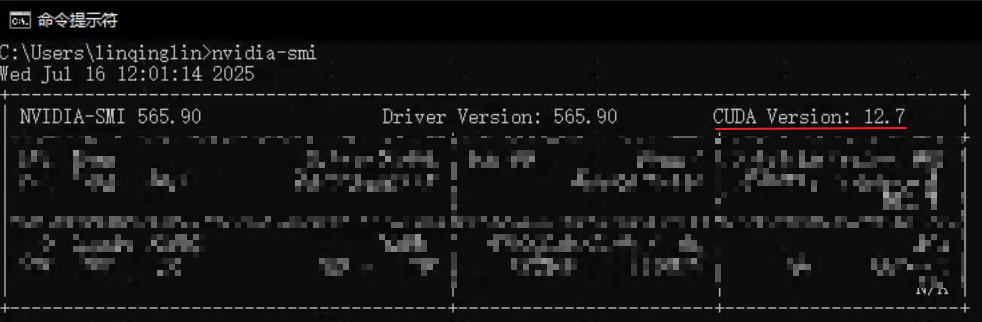
3、创建虚拟环境
(1)创建whisper虚拟环境
conda create -n whisper python=3.10 -y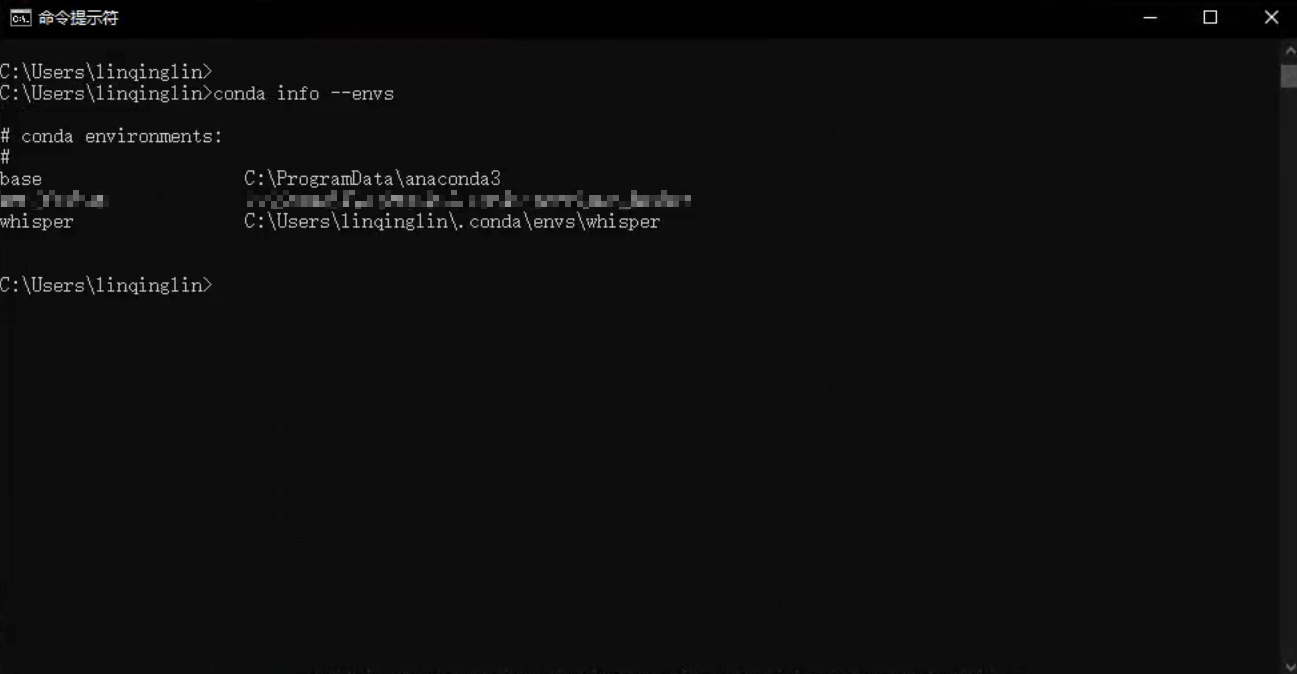
(2)激活whisper环境
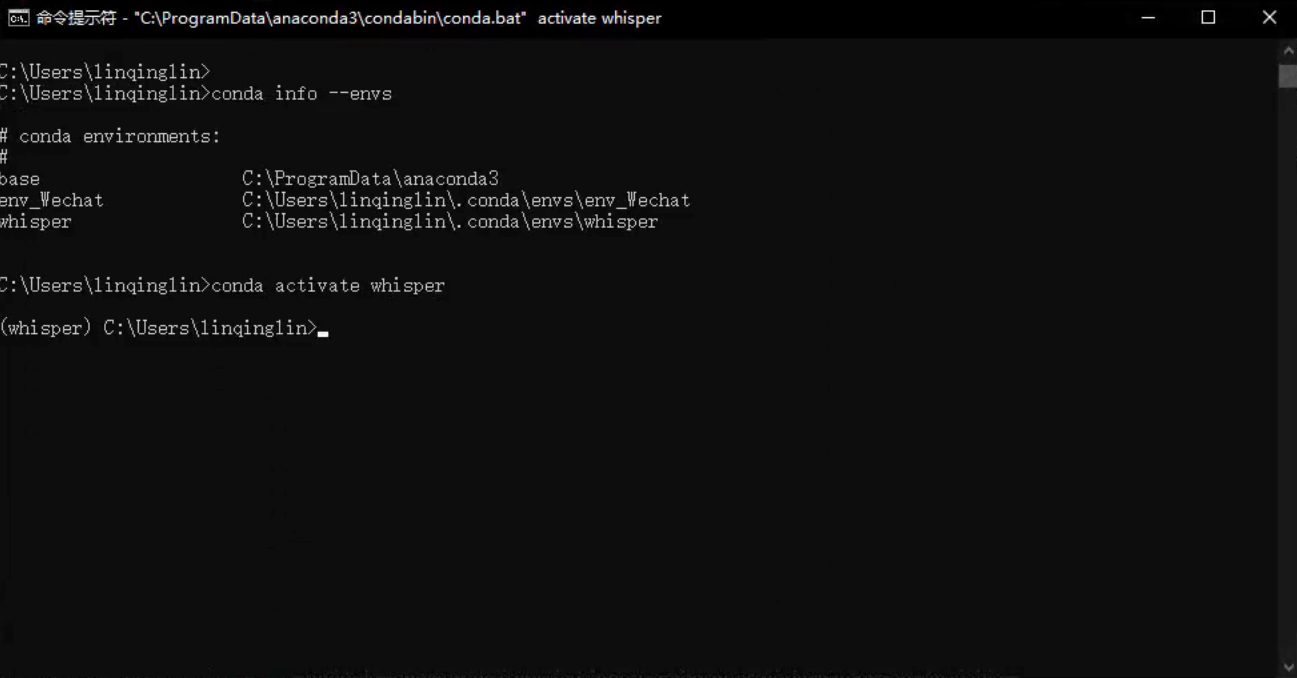
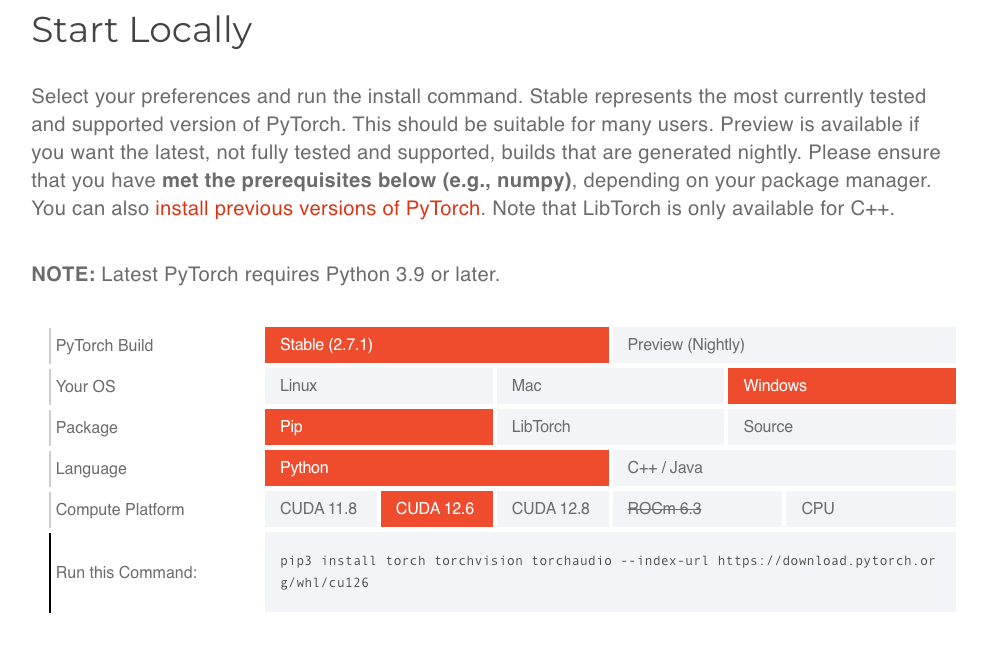
(3)安装pytorch等依赖
上pytorch官网:https://pytorch.org/get-started/locally/
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
 (4)安装whisper
(4)安装whisper
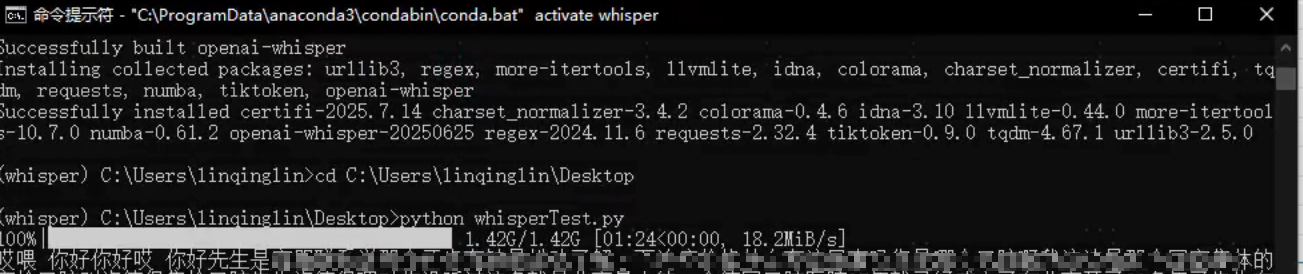
pip install -U openai-whisper -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple安装完成后,创建一个whisper.py文件
import whisper
model = whisper.load_model("base").to("cuda") # 明确用 GPU
result = model.transcribe("your-audio-file.mp3")
print(result["text"])运行,whisper.py文件
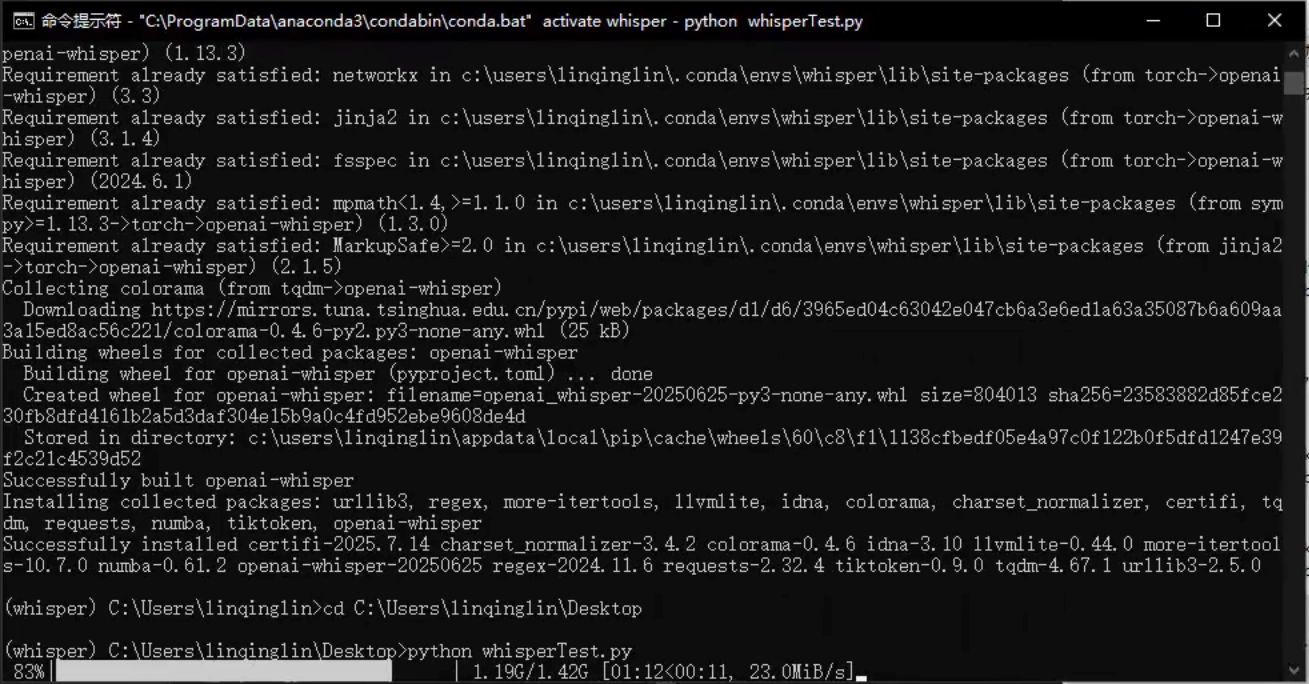
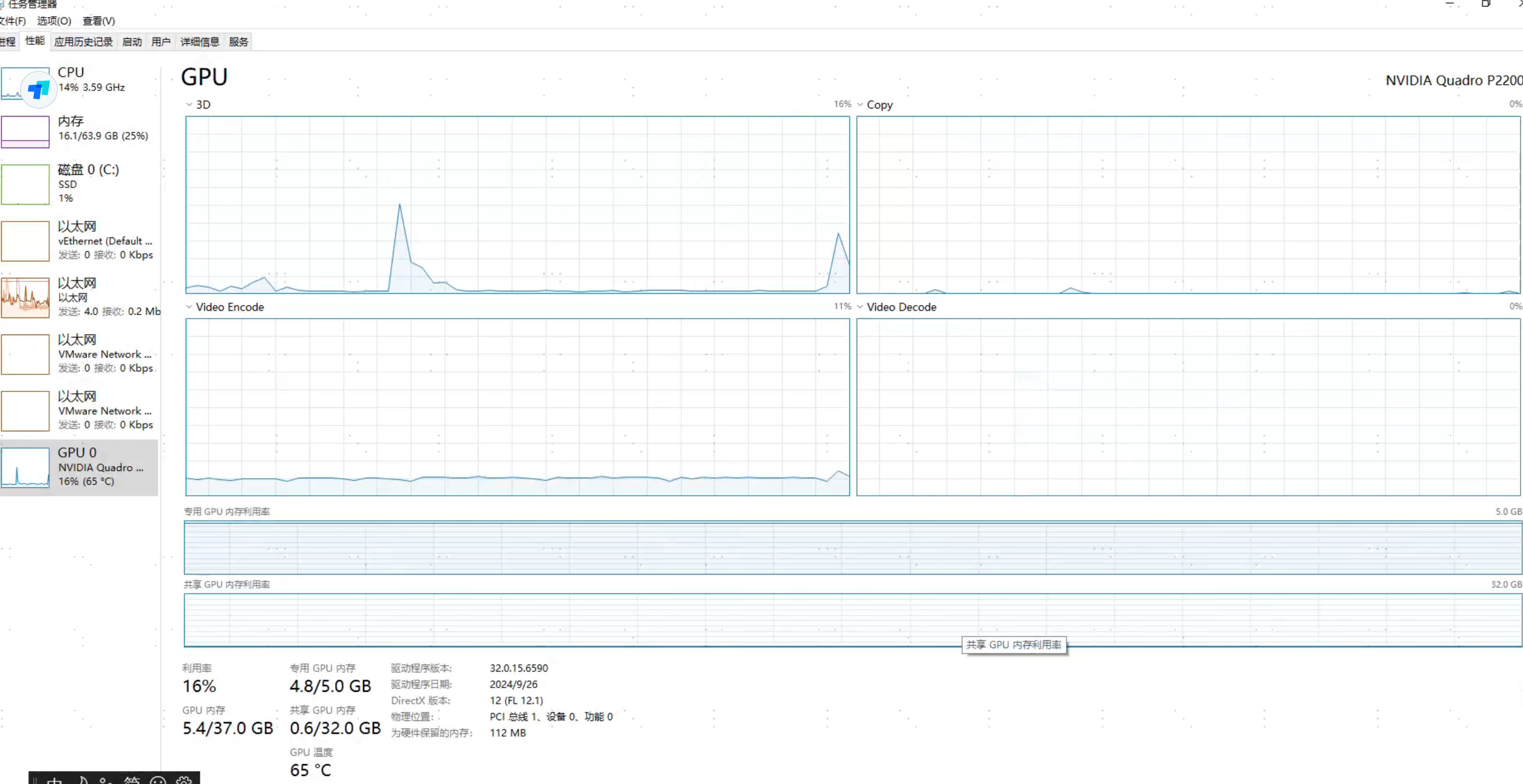
通过管理器,看GPU的运行情况