ByteToMessageDecoder详解
学习链接
吃透Netty源码系列三十八之ByteToMessageDecoder详解
聊一聊 Netty 数据搬运工 ByteBuf 体系的设计与实现(上):
聊一聊 Netty 数据搬运工 ByteBuf 体系的设计与实现(下)
Netty 核心原理剖析与 RPC 实践-完
- 18 源码篇:解密 Netty Reactor 线程模型
文章目录
- 学习链接
- ByteToMessageDecoder
- 简介
- MERGE_CUMULATOR 累加器
- COMPOSITE_CUMULATOR 累加器
- 成员变量
- channelRead方法
- callDecode中的循环处理
- decodeRemovalReentryProtection
- channelReadComplete
- 子类做法
- 简单实现文件传输
- 自定文件传输协议
- 服务端
- UploadNettyServer
- UploadFileDecoder
- UploadFileHandler
- 客户端
- UploadNettyClient
- 测试
ByteToMessageDecoder
简介
ByteToMessageDecoder是netty中1个非常重要的解码器。
因为tcp协议将数据以流的方式传输,但这样就需要自己在应用层手动解决字节数据边界的问题,即拆包和粘包的问题。将流式数据按照商定的协议规则区分的1个完整数据称为帧。
数据由客户端发送过来到服务器端,服务端的selector将会收到1个可读事件,然后由netty中对应的socketChannel处理,socketChannel交给pipeline,pipeline交给流水线上所有的入站处理器,而pipeline上第1个入站处理器就是HeadContext,它就负责从socketChannel中读取数据到ByteBuf中,然后将这个ByteBuf传递给后面的入站处理器。
但是,注意:HeadContext中读取的数据可能包含了完整消息,也可能包含不完整的消息,这是不确定的,由底层网络传输决定,我们要做的就是区分出消息边界,然后将完整的消息交给后面的入站处理器,不然的话,入站处理器后面的业务拿到的不是1个完整的消息,就会出问题。
ByteToMessageDecoder就是其中1个比较重要的解码器抽象类,也叫一次解码器,它里面就有定义处理消息边界的方法,因为它是个抽象类,包含着消息解码的公共逻辑。因此,在学习其它解码器前,先学习它是十分有必要的。
ByteToMessageDecoder是个抽象类,且不可被共享,其子类上不可加@Sharable注解。
MERGE_CUMULATOR 累加器
默认就是该 MERGE_CUMULATOR 实现。
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {@Overridepublic ByteBuf cumulate(ByteBufAllocator alloc, // 内存分配器ByteBuf cumulation, // 累加缓冲区,用于缓冲数据ByteBuf in) { // 新读到的数据的缓冲区// 如果累加缓冲区的数据已经读完了 并且 新读到的数据的缓冲区是连续的// 就释放累加的缓冲区,并返回新读到的数据的缓冲区if (!cumulation.isReadable() && in.isContiguous()) {cumulation.release();return in;}try {// 新读到的数据的缓冲区 的可读数据 的字节数final int required = in.readableBytes();// 累加缓冲区 不足以 放下 新读到的数据的缓冲区 中的所有字节数据if (required > cumulation.maxWritableBytes() ||// writableBytes() =< maxFastWritableBytes() =< writableBytes() && 引用计数 > 1required > cumulation.maxFastWritableBytes() && cumulation.refCnt() > 1 ||// cumultation 只读cumulation.isReadOnly()) {// 扩容(通过分配1个新的累加缓冲区,并将旧的累加缓冲区中的数据 和 新读到的数据的缓冲区 拷贝到 新的累加缓冲区中,// 并返回新的累加缓冲区)return expandCumulation(alloc, cumulation, in);}// 说明当前 累加缓冲区下 能放下 新读到的数据的缓冲区 中的数据// 将 新读到的数据的缓冲区(从readerIndex数readableBytes个字节)读到 累加缓冲区cumulation.writeBytes(in, in.readerIndex(), required);// in将读指针 设置为 writerIndex,相当于 可读字节 都已经读完了in.readerIndex(in.writerIndex());// 返回累加缓冲区return cumulation;} finally {// 释放 新读到的数据的缓冲区in.release();}}
};static ByteBuf expandCumulation(ByteBufAllocator alloc, // 内存分配器ByteBuf oldCumulation, // 旧的累加缓冲区,用于缓冲数据ByteBuf in) { // 新读到的数据的缓冲区// 旧的累加缓冲区 的可读字节数int oldBytes = oldCumulation.readableBytes();// 新读到的数据的缓冲区 的可读自结束int newBytes = in.readableBytes();// 一共需要 的 字节数 容量int totalBytes = oldBytes + newBytes;// 分配1个新的累加缓冲区,能够容纳 totalBytes 字节数ByteBuf newCumulation = alloc.buffer(alloc.calculateNewCapacity(totalBytes, MAX_VALUE));// 待释放 先赋值为 新的累加缓冲区ByteBuf toRelease = newCumulation;try {// (所以扩容的实现就是内存拷贝)// 调用setBytes,将 旧的累加缓冲区(从readIndex数oldBytes个字节) 中的数据 复制到 newCumulation.setBytes(0, oldCumulation, oldCumulation.readerIndex(), oldBytes)// 调用setBytes,将 新读到的数据的缓冲区(从readIndex数newBytes个字节) 中的数据 复制到 newCumulation.setBytes(oldBytes, in, in.readerIndex(), newBytes)// newCumulation的writerIndex设置为(oldBytes + newBytes).writerIndex(totalBytes);// 设置in的readerIndex到writerIndex(因为经过上面操作,in相当于读完了),in在外层的finally块中释放in.readerIndex(in.writerIndex());// 如果前面不发生异常,那么该释放 旧的累加缓冲区toRelease = oldCumulation;// 返回新的累加缓冲区return newCumulation;} finally {// 释放(正常情况下,释放的是 旧的累加缓冲区)toRelease.release();}
}
COMPOSITE_CUMULATOR 累加器
public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {@Overridepublic ByteBuf cumulate(ByteBufAllocator alloc, // 内存分配器ByteBuf cumulation, // 累加缓冲区ByteBuf in) { // 新读到的数据的缓冲区// 如果累加缓冲区的数据已经读完了(无可读数据了),则释放 累加缓冲区,并返回 新读到的数据的缓冲区if (!cumulation.isReadable()) {cumulation.release();return in;}CompositeByteBuf composite = null;try {// 如果 累加缓冲区 是 CompositeByteBuf类型,并且 引用计数为1if (cumulation instanceof CompositeByteBuf && cumulation.refCnt() == 1) {composite = (CompositeByteBuf) cumulation;// 调整 累加缓冲区 的 capacity 到 writerIndex 位置处if (composite.writerIndex() != composite.capacity()) {composite.capacity(composite.writerIndex());}} else {// 如果 累加缓冲区 不是 CompositeByteBuf类型 或者 引用计数不为1// 则 分配1个新的 compositeBuffer,并添加 原来的累加缓冲区composite = alloc.compositeBuffer(Integer.MAX_VALUE).addFlattenedComponents(true, cumulation);}// 经过上面处理,只需要加上 新读到的数据的缓冲区composite.addFlattenedComponents(true, in);// in置为null in = null;// 返回 compositeBufferreturn composite;} finally {// 如果in不为null,则说明前面操作发生了异常if (in != null) {// 那么需要在这里主动释放inin.release();// 如果前面操作发生了异常,并且composite还是通过新分配得到的缓冲区,则要释放掉CompositeByteBufif (composite != null && composite != cumulation) {composite.release();}}}}
};
成员变量
public abstract class ByteToMessageDecoder// 累加缓冲区ByteBuf cumulation;// 累加器, 默认使用的就是上面的合并累加器private Cumulator cumulator = MERGE_CUMULATOR;// 每次触发可读事件时, 是否只解码1次//(默认false。在默认情况下每次触发可读时,会有1个死循环去解码,直接到解不出来了,再跳出死循环)private boolean singleDecode;// 当触发 channelRead 事件时,判断刚开始的 累加缓冲区 是否为 nullprivate boolean first;// 当 ChannelConfig.isAutoRead() 为false时,是否需要调用 ChannelHandlerContext.read() 去读取数据private boolean firedChannelRead;// 标识当前是否为ByteToMessageDecoder字节的解码过程(因为ByteToMessageDecoder如果处理的不是ByteBuf类型的消息,是直接传给后面的入站处理器处理)private boolean selfFiredChannelRead;// 解码状态: INIT、CALLING_CHILD_DECODE、HANDLER_REMOVED_PENDING//(当前正在使用的解码器在哪个状态, 是在初始化, 还是正在调用子类的解码方法, 还是等待移除)private byte decodeState = STATE_INIT;// 当解码次数超过该默认值时,会尝试丢弃已读数据,以避免OOMprivate int discardAfterReads = 16;// 累加缓冲区 进入调用解码的方法 的次数//(因为次数越多, 那么这个累加缓冲区就越大, 它还占着内存, 当这个次数不小于discardAfterReads时, 就丢弃一些字节, 来节省内存)private int numReads;protected ByteToMessageDecoder() {// 这种解码器不能共享, 因为它有 累加缓冲区 这种有状态的成员变量, 因此不能被共享ensureNotSharable();}
}
channelRead方法
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {// ByteToMesssageDecoder解码器, 只处理ByteBuf的消息类型if (msg instanceof ByteBuf) {selfFiredChannelRead = true;// 用于存放解码后的 完整消息 的ListCodecOutputList out = CodecOutputList.newInstance();try {// first 即 cumulation累加缓冲区 是否为nullfirst = cumulation == null;// 如果 cumulation累加缓冲区为null,则传入的是 Unpooled.EMPTY_BUFFER(初始容量为0,最大容量为0)作为cumulation参数,// 如果 cumulation累加缓冲区不为null,则传入的是 cumulation 作为cumulation参数,// msg 作为 新读到的数据 传给 累加器,用于将新读到的数据 复制到 cumulation累加缓冲区 // 或 创建1个新的cumulation缓冲区(把旧的累加缓冲区的数据和新读到的msg 缓冲区中的数据复制到新的cumulation缓冲区)// 返回 旧的累加缓冲区 或 新的累加缓冲区,然后赋值给 cumulation 属性cumulation = cumulator.cumulate(ctx.alloc(), first ? Unpooled.EMPTY_BUFFER : cumulation, (ByteBuf) msg);// 调用 callDecode(..) 用于解码,解码得到的消息放入out这个List中callDecode(ctx, cumulation, out);} catch (DecoderException e) {throw e;} catch (Exception e) {throw new DecoderException(e);} finally {try {// 如果cumulation不为null, 并且cumulation已经刚好读完了// (也就是说,子类解码后,刚好cumulation读完的话,这个时候就去释放cumulation累加缓冲区,并将cumulation置为null)if (cumulation != null && !cumulation.isReadable()) {// numReads 重置为 0numReads = 0;// 释放 cumulationcumulation.release();// cumulation引用 置为 nullcumulation = null;} else if (++numReads >= discardAfterReads) { // numReads用来计数,标识channelRead读取的次数,discardAfterReads默认为16,也就是默认读取16次。// // 解析参考:聊一聊 Netty 数据搬运工 ByteBuf 体系的设计与实现(上):https://zhuanlan.zhihu.com/p/714383432// Netty 设计的这个丢弃字节的方法在解码的场景非常有用,// 由于 TCP 是一个面向流的网络协议,它只会根据滑动窗口的大小进行字节流的发送,// 所以我们在应用层接收到的数据可能是一个半包也可能是一个粘包,反正不会是一个完整的数据包。// 这就要求我们在解码的时候,首先要判断 ByteBuf 中的数据是否构成一个完成的数据包,// 如果构成一个数据包,才会去读取 ByteBuf 中的字节,然后解码,随后 readerIndex 向后移动。// 如果不够一个数据包,那就需要将 ByteBuf 累积缓存起来,一直等到一个完整的数据包到来。// 一种极端的情况是,即使我们已经解码很多次了,但是缓存的 ByteBuf 中仍然还有半包,由于不断的会有粘包过来,这就导致 ByteBuf 会越来越大。// 由于已经解码了很多次,所以 ByteBuf 中可以被丢弃的字节占据了很大的内存空间,如果半包情况持续存在,将会导致 OutOfMemory。// 所以 Netty 规定,如果已经解码了 16 次之后,ByteBuf 中仍然有半包的情况,// 那么就会调用这里的 discardSomeReadBytes() 将已经解码过的字节全部丢弃,节省不必要的内存开销。numReads = 0;// 尝试丢弃可读字节,以节省空间 (防止OOM)discardSomeReadBytes();}// 解码出来的消息的数量int size = out.size();// insertSinceRecycled表示out被添加过消息,当调用out.recycle()时,insertSinceRecycled会重置为false// 所以fireChannelRead就表示此次子类解码的过程有没有解码出消息结果,来传给后面的入站处理器firedChannelRead |= out.insertSinceRecycled();// 其实就是: 循环遍历out中, 所有解码出来的消息, 把这些消息挨个的传给后面的入栈处理器fireChannelRead(ctx, out, size);} finally {// 回收该容器(数组),out#insertSinceRecycled属性置为falseout.recycle();}}} else {// 如果说前面的入站处理器传过来的消息类型不是ByteBuf的, 那就直接传给下1个入站处理器去处理ctx.fireChannelRead(msg);}
}protected final void discardSomeReadBytes() {// 如果 累加缓冲区 不为 null,并且 cumulation不是null(不是第一次分配的累加缓冲区,也就是可能已经累加了好几次了),并且 累加缓冲区的引用计数 为 1// 则尝试丢弃一些已读字节(相当于readerIndex和writerIndex相对位置的向前移)if (cumulation != null && !first && cumulation.refCnt() == 1) {cumulation.discardSomeReadBytes();}
}// AbstractByteBuf#discardSomeReadBytes()
public ByteBuf discardSomeReadBytes() {if (readerIndex > 0) {// 当 ByteBuf 已经不可读了,则无条件丢弃已读字节if (readerIndex == writerIndex) {adjustMarkers(readerIndex);writerIndex = readerIndex = 0;return this;}// 当已读的字节数超过整个 ByteBuf 的一半容量时才会丢弃已读字节if (readerIndex >= capacity() >>> 1) {setBytes(0, this, readerIndex, writerIndex - readerIndex);writerIndex -= readerIndex;adjustMarkers(readerIndex);readerIndex = 0;return this;}}return this;
}
callDecode中的循环处理
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {try {// 当 累加缓冲区 in 中有可读的数据时while (in.isReadable()) {// 1、刚开始进来的的时候, out的大小为0;// 2、循环1次后, 开始下一次循环前, 先拿到上一次解码出来的消息的数量final int outSize = out.size();// 如果上一次解码出来的消息的数量 大于 0, 那么及时的把解码出来的消息交给后面处理if (outSize > 0) {// 将上一次解码出来的消息, 都传给后面的入站处理器 去处理fireChannelRead(ctx, out, outSize);// 清空out(因为已经交给后面的入站处理器处理了)out.clear();// 检查下当前处理器是否被移除了, 移除了的话, 那就跳出循环了if (ctx.isRemoved()) {break;}}// 在开始真正解码操作前, 先记录下 当前 累加缓冲区 中可读字节 有多少个(那肯定后面还会检测一下解码后可读字节有没有变少)int oldInputLength = in.readableBytes();// 解码操作,由子类实现。解码的消息会存放到out中(可能1次解码,就会有多个消息)。decodeRemovalReentryProtection(ctx, in, out);// 在子类解完1次码之后,就去检查一下 当前解码器 是否被移除了if (ctx.isRemoved()) {break;}// 如果out是空的, 也就意味着经过子类1次解码, 1个消息都没解码出来//(那就是说当前累加缓冲区的字节数据中, 1个完整消息的后面的字节数据还没传过来,需要等后面的数据来了, 直到完整了,才能解码出消息) if (out.isEmpty()) {// 没有解码出消息, 并且 累加缓冲区 中 解码前的的可读字节数 与 解码操作后 的可读字节数 是相等的// 就只能等客户端将后面的字节传过来, 触发下一次可读事件, 并将数据复制到累加缓冲区, 凑够完整的消息再说了// 因此, 这里直接跳出循环if (oldInputLength == in.readableBytes()) {break;} else {// 没有解码出消息, 但是可读字节变少了(比如 丢弃无用的数据), 那就继续(目的就是消耗可读字节数)continue;}}// 解码出1个消息,但是可读字节数没有减少(没有消耗可读字节数),这是不正常的!// 比如: 子类在解码的过程中, 不能全程只使用byteBuf的getByte等不改变可读字节的操作,if (oldInputLength == in.readableBytes()) {throw new DecoderException(StringUtil.simpleClassName(getClass()) +".decode() did not read anything but decoded a message.");}// 是否只解码一次, 即检测到可读事件,触发的1次channelRead中只解码1次。// 那么就算累加缓冲区中的数据还足以解码出令1个完整的消息,那么也跳出循环, 不解码了, out由后面的代码来传给后面的入站处理器处理if (isSingleDecode()) {break;}}// 对于异常情况,直接抛出} catch (DecoderException e) {throw e;} catch (Exception cause) {throw new DecoderException(cause);}
}
decodeRemovalReentryProtection
final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {// 标记 解码状态 为 STATE_CALLING_CHILD_DECODEdecodeState = STATE_CALLING_CHILD_DECODE;try {// 抽象方法,交给子类去解码,in是缓冲区数据,out用于存放解码出来的消息对象(可容纳多个解码后的消息对象)decode(ctx, in, out);} finally {// 当前解码器 解码状态 是否为 STATE_HANDLER_REMOVED_PENDING//(当 正在调用子类解码期间 调用了当前ByteToMesssageDecoder的handlerRemoved(..)方法)boolean removePending = decodeState == STATE_HANDLER_REMOVED_PENDING;// 修改 解码状态 为 初始化decodeState = STATE_INIT;// 如果在子类解码1次之后,发现 当前解码器 的解码状态 为 STATE_HANDLER_REMOVED_PENDINGif (removePending) {// 将 out中 解码后的所有消息对象 传递给后面的 处理器的channelRead 方法处理fireChannelRead(ctx, out, out.size());// 清空 outout.clear();// 移除handlerRemoved(ctx);}}
}public final void handlerRemoved(ChannelHandlerContext ctx) throws Exception {// 如果 解码状态 为 STATE_CALLING_CHILD_DECODE,则说明当前解码器 正在调用子类解码,// 将 解码状态 设置为 STATE_HANDLER_REMOVED_PENDING,这会使得子类在解码1次完成后,再去移除 当前解码器if (decodeState == STATE_CALLING_CHILD_DECODE) {decodeState = STATE_HANDLER_REMOVED_PENDING;return;}// 如果子类不在解码(或者子类正在解码,然后调用了当前解码器的handlerRemoaved标记了 解码状态,等到子类解完1次码了,并更新了 解码状态 为 STATE_INIT 时)// 累加缓冲区ByteBuf buf = cumulation;// 如果累加缓冲区不为空if (buf != null) {// cumulation置为null, 不再访问cumulationcumulation = null;// numReads 重置为 0numReads = 0;// 累加缓冲区中的 可读数据 的 字节数int readable = buf.readableBytes();// 如果 累加缓冲区 中还有 可读数据,直接将 缓冲区(未解码) 传给后面入站处理器的channelRead方法处理// 并触发 后面入站处理器的fireChannelReadComplete方法if (readable > 0) {ctx.fireChannelRead(buf);ctx.fireChannelReadComplete();} else {// 如果 累加缓冲区 中 没有可读数据了,直接释放 该 累加缓冲区 即可buf.release();}}// 空实现,子类可覆盖该方法handlerRemoved0(ctx);
}
channelReadComplete
/* channelReadComplete触发时机测试1、通过channel.writeAndFlush(AAA), 紧接着channel.writeAndFlush(BBB), 发现对方收到了1次channelRead 和 channelReadComplete。2、通过channel.writeAndFlush(AAA), 紧接着睡3s,再channel.writeAndFlush(BBB), 发现对方收到了1次channelRead 和 channelReadComplete,又收到了1次channelRead 和 channelReadComplete。
*/
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {// 收完1次数据, numReads重置为0numReads = 0;// 收完1次数据了,尝试丢弃一些字节(见上面详解)discardSomeReadBytes();// selfFiredChannelRead刚开始默认初始化为false,若处理的是ByteBuf类型的消息,selfFiredChannelRead会被置为true,表示正在处理消息。// !firedChannelRead 由于在chanelRead中firedChannelRead |= out.insertSinceRecycled(),如果解码出过消息,则firedChannelRead 为true,如果未解码出消息,则firedChannelRead 为false// channel是否未开启自动读取// (也就是channel没有开启自动读取,但是前面又没解码出消息,并且处理的是ByteBuf类型的消息(因为当前抽象解码器可能接收到的不是ByteBuf类型的消息),则开关注读事件,以期望读到更多的消息)if (selfFiredChannelRead && !firedChannelRead && !ctx.channel().config().isAutoRead()) {ctx.read();}// 收完1次数据了,firedChannelRead 重置为falsefiredChannelRead = false;// 收完1次数据了,selfFiredChannelRead 重置为falseselfFiredChannelRead = false;// 传递 channelReadComplete事件ctx.fireChannelReadComplete();
}
子类做法
其实解码就是处理自定义协议,通过协议解析出消息的边界,将完整的消息交给后面处理。通过对ByteToMessageDecoder的代码学习,可以知道具体的解码过程是交给了子类来做的,而ByteToMessage所做的就是将累加缓冲区交给子类,在子类解码后,去检查可读字节数是否有变化。
因此,子类中会要经常使用:
- ByteBuf#readableBytes() 方法来获取 累加缓冲区中的可读字节数量,以此来判断可读字节数量是否足够。
- 如处理websocket协议时,WebSocket08FrameDecoder中是通过维护1个状态位,来记录当前解码到协议的哪个部分
- 如果不用状态位,那就在读之前记录一下读索引,读完之后,下次数据来的时候,消息完整时,再恢复到读索引处继续开始读,这也是一种方法。
子类由易到难,可以依次参考:
FixedLengthFrameDecoder、
LineBasedFrameDecoder、
DelimiterBasedFrameDecoder、
LengthFieldBasedFrameDecoder
简单实现文件传输
自定文件传输协议
第一步: 4字节command + 4字节文件名大小 + 文件名字节数据
第二步: 4字节command + 4字节文件名大小 + 文件名字节数据 + 文件内容字节数据长度 + 文件内容字节数据
服务端
就添加2个入站处理器,第1个入站处理器专门负责解析完整的帧数据(依次解码器),第2个入站处理器主要做业务(暂时没用到二次解码器),根据前面的解码器解码出来的消息的command指令来做业务。
UploadNettyServer
@Slf4j
public class UploadNettyServer {public static void main(String[] args) {NioEventLoopGroup bossGroup = new NioEventLoopGroup(1);NioEventLoopGroup workerGroup = new NioEventLoopGroup();try {ServerBootstrap serverBootstrap = new ServerBootstrap().group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) {ch.pipeline().addLast(new UploadFileDecoder());ch.pipeline().addLast(new UploadFileHandler());}});ChannelFuture channelFuture = serverBootstrap.bind(8888);log.info("服务器启动成功...");channelFuture.channel().closeFuture().sync();} catch (InterruptedException e) {bossGroup.shutdownGracefully();workerGroup.shutdownGracefully();}}}UploadFileDecoder
这里面核心的就是:
- 在进行每次读取操作之前,先去判断字节数是否足够用于后续的读取操作,如果不够,那么就等(直接return,让客户端你数据进入累加缓冲区,直到足够为止)
- 因为没有采用状态位的方式来记录当前已经是读到哪个阶段了,所以,在下面的实现中,有可能读到后面才发现字节不够读了,因此就需要重置读索引,因此,在上一次结束后,下一次开始之前,就需要先标记此时的读索引,方便重置读索引,但这种方法会让原本已经读过了的数据,又给读了一遍
- 一定要严格按照客户端发送的方式来解析,就是说客户端怎么发,服务端就怎么收,解析方式与发送方式要一致才可以
@Slf4j
public class UploadFileDecoder extends ByteToMessageDecoder {// 传输过程:// 第一步: 4字节command + 4字节文件名大小 + 文件名字节数据// 第二步: 4字节command + 4字节文件名大小 + 文件名字节数据 + 文件内容字节数据长度 + 文件内容字节数据@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {log.info("缓冲区中可读字节数: {}", in.readableBytes());// 是否够8个字节if(in.readableBytes() < 8){return;}// 读4个字节 作为 command//command 4int command = in.readInt();// 再读4个字节, 作为文件名大小int fileNameLen = in.readInt();// 剩下的可读字节是否小于文件名大小(文件名这部分的字节数据, 还未传过来)if(in.readableBytes() < fileNameLen){// 这里刚开始重置为0了//(也就是说, 如果不够读了, 那么经过当前子类的解码处理,// 累加缓冲区中的可读字节数在解码前与解码后仍然不变)// 后面就是重置到上次标记的读索引所在的位置(看这个方法最下面的标记都索引的地方)in.resetReaderIndex();return;}// 到这里说明至少: 4字节command + 4字节文件名大小 + 文件名字节数据byte[] data = new byte[fileNameLen];// 读取文件名字节数据in.readBytes(data);// 得到文件名String fileName = new String(data);// 至此, 已经获取文件名 和 客户端的当前操作命令commandFileDto fileDto = new FileDto();fileDto.setCommand(command);fileDto.setFileName(fileName);// 如果当前客户端的当前操作命令command是1, 那么在下面会标记一下, 当前读到了哪个字节了。// 然后, 下一次客户端再把command为2的数据传过来if(command == 2){// 不够4个字节, 重置索引, 下次重新读if (in.readableBytes() < 4) {// 重置索引in.resetReaderIndex();return;}// 4字节command + 4字节文件名大小 + 文件名字节数据 + 文件内容字节数据长度 + 文件内容字节数据int dataLen = in.readInt();log.info("文件内容长度: {}", dataLen);// 文件内容未全部传输过来, 重置索引, 下次重新处理if(in.readableBytes() < dataLen){in.resetReaderIndex();return;}// 读取文件数据byte[] fileData = new byte[dataLen];in.readBytes(fileData);fileDto.setBytes(fileData);}// 标记readerIndex(这就是所说的:在上一次结束后,下一次开始之前 的位置)in.markReaderIndex();out.add(fileDto);}
}UploadFileHandler
public class UploadFileHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelActive(ChannelHandlerContext ctx) throws Exception {}@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {if(msg instanceof FileDto){FileDto dto = (FileDto) msg;if(dto.getCommand() == 1){//创建文件File file = new File("D://test//"+dto.getFileName());if(!file.exists()){file.createNewFile();}}else if(dto.getCommand() == 2){//写入文件save2File("D://test//"+dto.getFileName(),dto.getBytes());}}}public static boolean save2File(String fname, byte[] msg){OutputStream fos = null;try{File file = new File(fname);File parent = file.getParentFile();boolean bool;if ((!parent.exists()) &(!parent.mkdirs())) {return false;}fos = new FileOutputStream(file,true);fos.write(msg);fos.flush();return true;}catch (FileNotFoundException e){return false;}catch (IOException e){File parent;return false;}finally{if (fos != null) {try{fos.close();}catch (IOException e) {}}}}}
客户端
UploadNettyClient
- 按照与服务端约定好的协议发送数据
- sync的用法:一般是调用1个方法,就相当于发送了1个命令,但是有时需要在命令完成时收到通知,可以是通过回调的方式,也可以是通过sync()方法的调用在当前线程阻塞直到收到命令完成的通知
- await与promise的用法:通过设置promise来主动通知操作是否完成
@Slf4j
public class UploadNettyClient {public static void main(String[] args) throws InterruptedException {Bootstrap bootstrap = new Bootstrap().channel(NioSocketChannel.class).group(new NioEventLoopGroup(1)).option(ChannelOption.TCP_NODELAY, true).handler(new ChannelInitializer<NioSocketChannel>() {@Overrideprotected void initChannel(NioSocketChannel ch) throws Exception {ch.pipeline().addLast(new ChannelOutboundHandlerAdapter() {@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {if (msg instanceof String) {msg = ((String) msg).replace("\u202A", "");System.out.println();String filePath = (String) msg;File file = new File(filePath);byte[] fileNames = file.getName().getBytes(Charset.defaultCharset());ByteBuf buf = ctx.alloc().buffer();// 第一步buf.writeInt(1);buf.writeInt(fileNames.length);buf.writeBytes(fileNames);// 等待这个操作完成(由netty来通知)ctx.writeAndFlush(buf).await();log.info("写出第1条消息");ByteBuf buf2 = ctx.alloc().buffer();// 第二步buf2.writeInt(2);buf2.writeInt(fileNames.length);buf2.writeBytes(fileNames);// 等待这个操作完成(由netty来通知)ctx.writeAndFlush(buf).await();log.info("写出第2条消息");int length = (int) file.length();ByteBuf byteBuf = Unpooled.buffer().writeInt(length);ctx.writeAndFlush(byteBuf);FileInputStream fis = new FileInputStream(file);int len;int total = 0;byte[] bytes = new byte[1024];while ((len = fis.read(bytes)) != -1) {ctx.writeAndFlush(Unpooled.wrappedBuffer(bytes, 0, len));total += len;log.info("写出数据: {}", len);}log.info("共计写出数据: {}", total);log.info("即将通知主线程任务完成");// 告知主线程, 这个任务已经完成了promise.setSuccess();log.info("通知主线程任务完成");} else {ctx.write(msg, promise);}}});}});// 客户端连上服务器之后, sync方法 才会停止阻塞//(注意此处的sync用法, connect方法就相当于发出1个连接的命令, 但是这个命令是否已经完成, 对于这个我们是不知道的,// 但是connect方法会返回1个channelFuture, 通过返回的这个channelFuture可以添加命令完成的回调,// 也可以在当前线程上调用sync方法, 来实现命令完成时的“通知”)ChannelFuture channelFuture = bootstrap.connect("127.0.0.1", 8888);channelFuture.sync();log.info("连接上了服务器...");Channel channel = channelFuture.channel();Scanner sc = new Scanner(System.in);while (true) {System.out.print("请输入要传输的文件路径: ");String filePath = sc.nextLine();// 发出写出这个数据的命令, 并且调用await方法等待告知当前线程命令完成, 否则会一直在这里等待//(这里换成sync也是一样的效果)//(其实就是在里面会先创建1个DefaultChannelPromise, // 然后把这个promise往后面传, 然后这里使用promise的方法, // 这样就在当前线程调用promise的await方法时阻塞, // 而这个promise可以在其它线程设置结果而让当前线程在此处停止阻塞,// 不过在当前线程调用await方法前, 还一直在当前线程往下调用哦)channel.writeAndFlush(filePath).await();log.info("传输: {} 完成....");System.out.println();}}
}
测试
- 客户端
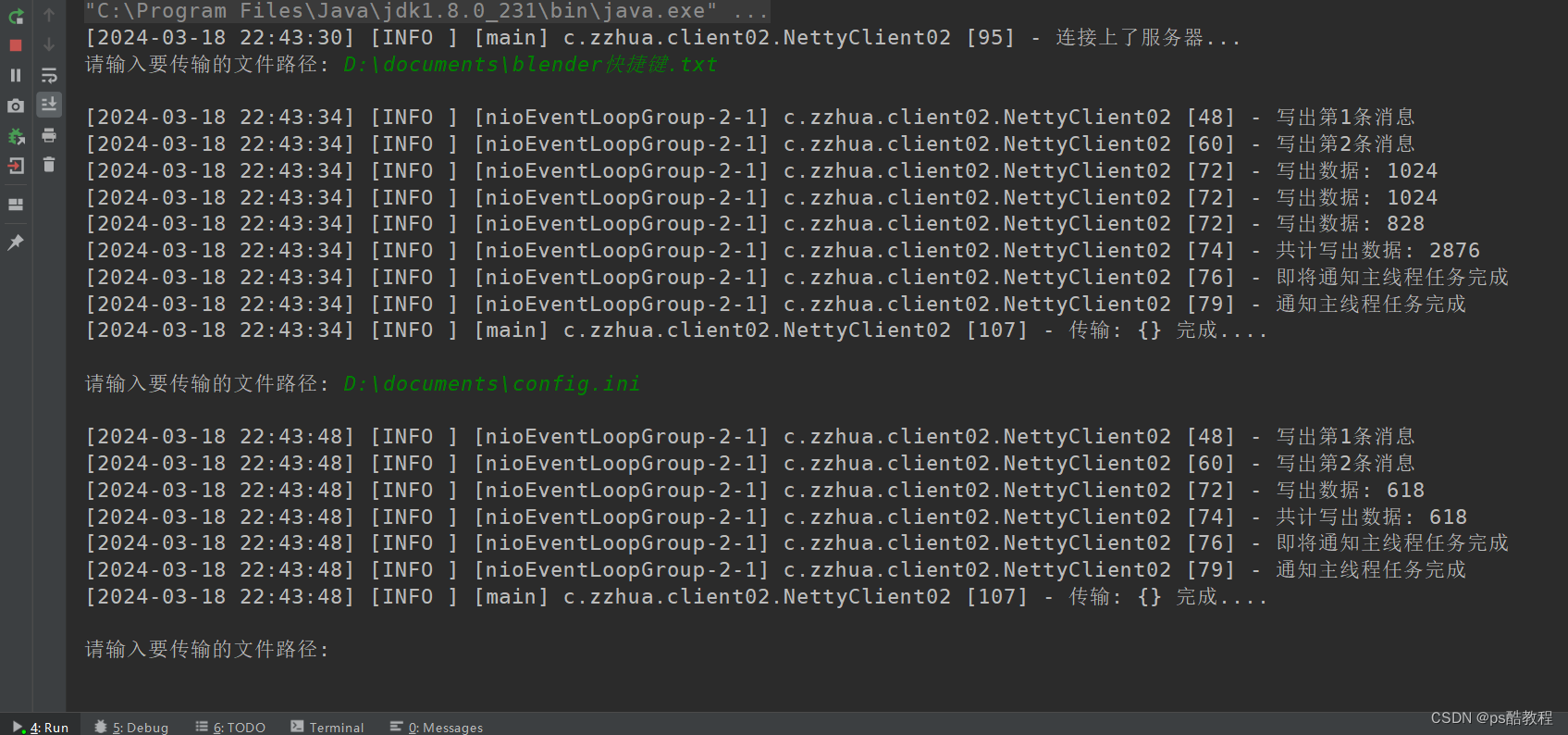
- 服务端