机器学习sklearn入门:归一化和标准化
bg:归一化(Normalization)通常指将数据按比例缩放至某个特定范围,但具体范围并不一定是固定的 0到1。标准化是将数据转换成均值为0,标准差为1的分布。
使用场景:
用归一化:
需要严格限定范围(如神经网络输入、图像处理)。
数据分布均匀且无极端值。
用标准化:
数据服从正态分布(或需要转换为正态分布)。
算法假设数据均值为 0(如 PCA、线性回归、SVM)。
归一化
1、pandas构建二维数组
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
import pandas as pd
pd.DataFrame(data)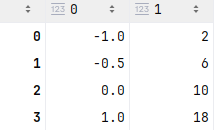
2、实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #通过接口导出结果
result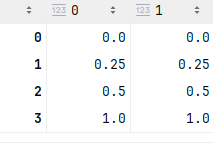
--也可以使用fit_tranform一步到位
3、反归一化就用scaler.inverse_transform(result)
4、上面默认转换为0-1之间的数据,如果需要其它范围的就在实例化MinMaxScaler的时候加上参数feature_range
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5,10])
result = scaler.fit_transform(data) #fit_transform一步导出结果
result标准化
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler() #实例化
scaler.fit(data) #fit,本质是生成均值和方差
scaler.mean_ #查看均值的属性mean_
scaler.var_ #查看方差的属性var_
x_std = scaler.transform(data) #通过接口导出结果
x_std.mean() #导出的结果是一个数组,用mean()查看均值
x_std.std() #用std()查看方差
scaler.fit_transform(data) #使用fit_transform(data)一步达成结果
scaler.inverse_transform(x_std) #使用inverse_transform逆转标准化