深入理解高性能字节池 bytebufferpool
文章目录
- 为什么需要字节池
- sync.Pool
- 容量固定
- 内存泄露
- 大对象长时间占用内存空间
- 源码走读
- 结构
- Get
- Put
为什么需要字节池
工程上有很多需要用到[]byte的场景,例如:
- 当处理 HTTP 请求时,需要创建一个字节切片 []byte 去读取请求体:先把请求数据读到[]byte中,再从[]byte反序列化成请求对象
- 在打日志时,需要先将日志encode成[]byte,再将[]byte输出到writer中
在高并发场景中,需要频繁的进行[]byte内存的申请和释放,增大了 GC 的压力,这时候需要采用 “字节池” 来优化
sync.Pool
Go 标准库中为我们提供了 sync.Pool,可以很简单地实现一个字节池:
pool := &sync.Pool{New: func() interface{} {return make([]byte, 256)},
}
但是这种方式实现的字节池有几个缺点:
容量固定
每次new一个slice,其容量cap是写死的,不会根据使用情况动态调整
- 如果cap定大了:可能有些场景不需要这么多的容量,导致 内存浪费
- 如果cap定小了:可能有些场景需要更多内存,导致 每次用到时都需要扩容,性能较低
内存泄露
偶尔出现非常大的数据时,会导致 []byte 扩容到很大。如果将该[]byte再放回pool中。而后续大部分Get() 操作可能只需要小对象,但获得了大对象,导致大内存被长期占用,无法释放, 进而导致 内存泄露
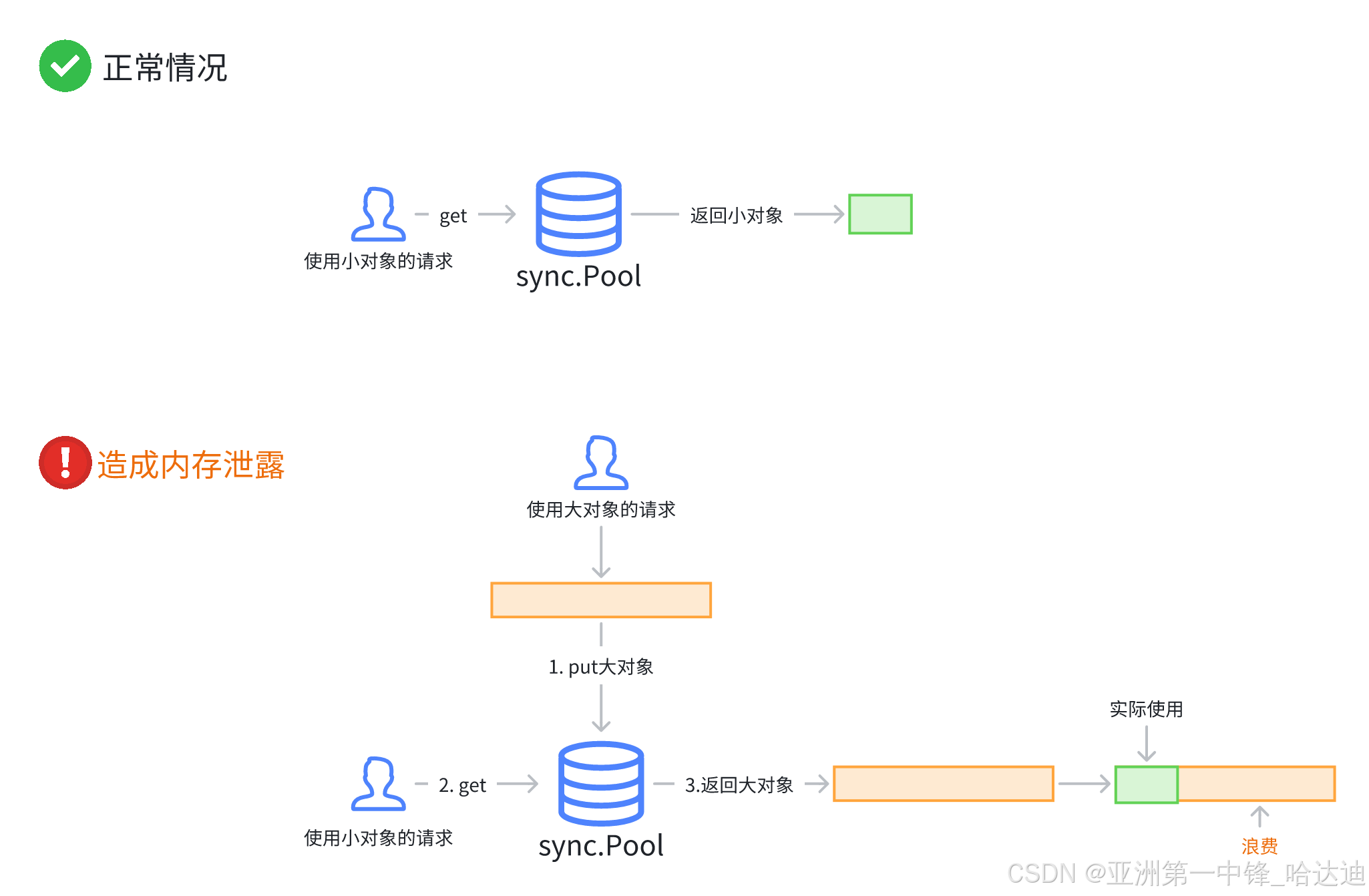
大对象长时间占用内存空间
这个问题从直觉上来说不好理解
熟悉sync.Pool原理的通信应该知道,sync.Pool在每次GC时会清空一部分数据。因此将容量很大的slice put回pool,和不放回pool,效果应该是一样的吧?毕竟其中的数据都会在下次GC时被回收
但实际上效果不一样:
sync.Pool 中的对象不会立即被 GC 清理,而是会在 GC 运行时被逐步清除。具体来说:
- 第一轮 GC:对象会从本地池(local pool)迁移到 victim 缓存(victim cache),但不会被直接释放。
- 第二轮 GC:victim 缓存中的对象才会被完全清除。
这意味着,大容量的 slice 在 sync.Pool 中会存活两轮GC,才会被完全清理**
而如果不把大容量的 slice放回pool,在下次GC就清理了。其**占用大量内存的时间更短**
源码走读
为了解决上面提到的几个问题,就引出我们本文的主角:bytebufferpool
其有以下特性:
- 根据对pool的使用情况,动态计算最常用的size作为
defaultSize,每次pool中没有需要new一个slice时,容量设置为defaultSize。这样大部分情况没有 内存 浪费,也不需要扩容 - 动态计算出
maxSize,Put时,slice的容量如果超过maxSize,就不放回pool中,而是等待下次GC被回收,避免了 内存 泄露和大对象长时间占用内存空间的问题
本文走读的源码地址:https://github.com/valyala/bytebufferpool,版本v1.0.0
结构
type Pool struct {// 记录不同大小类别的缓冲区被调用(放入池中的次数calls [steps]uint64// 标志位,表示当前是否正在进行校准操作// 防止多个 goroutine 同时执行校准逻辑,确保线程安全calibrating uint64// 对象池默认分配的缓冲区大小// 根据实际使用情况动态调整,默认情况下是最常用的缓冲区大小defaultSize uint64// 对象池允许的最大缓冲区大小// 控制内存使用上限,防止因缓存过多大对象而浪费内存maxSize uint64pool sync.Pool
}
其中每个step对应的容量大小如下:
| step i | 缓冲区大小(字节) | 说明 |
|---|---|---|
| 0 | 64 | 最小单位 |
| 1 | 128 | 64 * 2^1 |
| 2 | 256 | 64 * 2^2 |
| … | … | |
| 19 | 33,554,432 | 64 * 2^19 = 32MB |
Get
从pool中获取一个。如果获取不到,按照defaultSize new一个
func (p *Pool) Get() *ByteBuffer {v := p.pool.Get()if v != nil {return v.(*ByteBuffer)}return &ByteBuffer{B: make([]byte, 0, atomic.LoadUint64(&p.defaultSize)),}
}
Put
func (p *Pool) Put(b *ByteBuffer) {// 根据b的len,计算当前b属于哪个级别idx := index(len(b.B))// 增加对应索引 idx 的调用次数计数器 calls[idx]if atomic.AddUint64(&p.calls[idx], 1) > calibrateCallsThreshold {// 如果计数值超过了阈值,则调用 p.calibrate() 方法进行校准// 目的是调整池的行为以适应当前的负载情况。p.calibrate()}// 在放入池之前,会检查是否超出最大容量限制,确保不会因缓存过多大对象而浪费内存maxSize := int(atomic.LoadUint64(&p.maxSize))if maxSize == 0 || cap(b.B) <= maxSize {b.Reset()p.pool.Put(b)}
}func (p *Pool) calibrate() {// 确保只有一个 goroutine 调用 calibrate 方法if !atomic.CompareAndSwapUint64(&p.calibrating, 0, 1) {return}// 收集调用统计数据a := make(callSizes, 0, steps)var callsSum uint64for i := uint64(0); i < steps; i++ {calls := atomic.SwapUint64(&p.calls[i], 0)callsSum += callsa = append(a, callSize{calls: calls,size: minSize << i,})}// 对 a 切片进行排序,按照调用次数从高到低排列sort.Sort(a)// 将调用次数最多的缓冲区大小类别作为 defaultSize,这是对象池默认分配的缓冲区大小defaultSize := a[0].sizemaxSize := defaultSize// 计算maxSize:调用次数前95%的区间中,最大的size// 目的:防止将使用较少的大容量对象放回对象池,从而占用太多内maxSum := uint64(float64(callsSum) * maxPercentile)callsSum = 0for i := 0; i < steps; i++ {if callsSum > maxSum {break}callsSum += a[i].callssize := a[i].sizeif size > maxSize {maxSize = size}}atomic.StoreUint64(&p.defaultSize, defaultSize)atomic.StoreUint64(&p.maxSize, maxSize)atomic.StoreUint64(&p.calibrating, 0)
}