MySQL锁机制与SQL优化详解
MySQL锁机制与SQL优化详解
一、MySQL锁机制:并发控制的"交通规则"
看这篇文章之前请先务必了解 MySQL索引与事务
1.1 为什么需要锁?
想象一下十字路口没有红绿灯会怎样?车辆乱行导致事故。数据库中的锁就像红绿灯,控制并发操作的顺序,防止数据不一致。例如:
- 两个用户同时给同一商品下单扣库存,可能导致超卖
- 一个用户读取数据时,另一个用户删除了该数据,导致读到不存在的数据
1.2 锁的分类:从"锁范围"看锁类型
表锁 vs 行锁 vs 间隙锁
| 锁类型 | 锁定范围 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 表锁 | 整个表 | 实现简单,开销小 | 并发低,一锁全表堵 | MyISAM引擎、DDL操作 |
| 行锁 | 单行数据 | 并发高,只锁必要行 | 实现复杂,开销大 | InnoDB引擎、写频繁场景 |
| 间隙锁 | 索引范围间隙 | 防止幻读 | 可能导致死锁 | InnoDB可重复读隔离级别 |

表锁案例(MyISAM)
-- 会话1:获取表读锁
LOCK TABLES products READ;
SELECT * FROM products WHERE id=1; -- 成功
UPDATE products SET name='new' WHERE id=1; -- 失败(读锁不能写)-- 会话2:尝试写操作
UPDATE products SET name='new' WHERE id=1; -- 阻塞,直到会话1释放锁
行锁案例(InnoDB)
-- 会话1:锁定id=1的行
START TRANSACTION;
SELECT * FROM products WHERE id=1 FOR UPDATE; -- 获取行排他锁-- 会话2:操作不同行(不阻塞)
UPDATE products SET name='new' WHERE id=2; -- 成功-- 会话2:操作同一行(阻塞)
UPDATE products SET name='new' WHERE id=1; -- 阻塞,直到会话1提交
1.3 锁的兼容性:哪些锁可以共存?
InnoDB定义了多种锁类型,核心是共享锁(S锁)和排他锁(X锁):
- 共享锁(S锁):读操作时获取,多个S锁可共存
- 排他锁(X锁):写操作时获取,与任何锁不共存
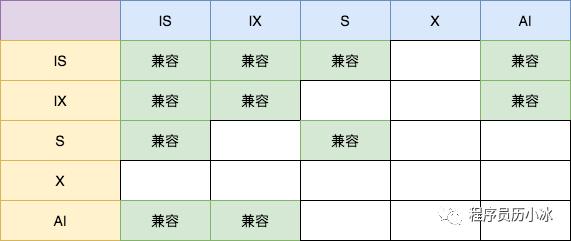
兼容性规则:
- S锁之间兼容:多个事务可同时读同一行
- S锁与X锁互斥:读时不能写,写时不能读
- X锁之间互斥:两个事务不能同时写同一行
1.4 死锁:如何避免"互相堵车"?
死锁产生示例
-- 会话1
START TRANSACTION;
UPDATE accounts SET balance=balance-100 WHERE id=1; -- 锁定id=1-- 会话2
START TRANSACTION;
UPDATE accounts SET balance=balance-100 WHERE id=2; -- 锁定id=2-- 会话1尝试锁定id=2
UPDATE accounts SET balance=balance+100 WHERE id=2; -- 等待会话2释放id=2-- 会话2尝试锁定id=1
UPDATE accounts SET balance=balance+100 WHERE id=1; -- 死锁!两个会话互相等待
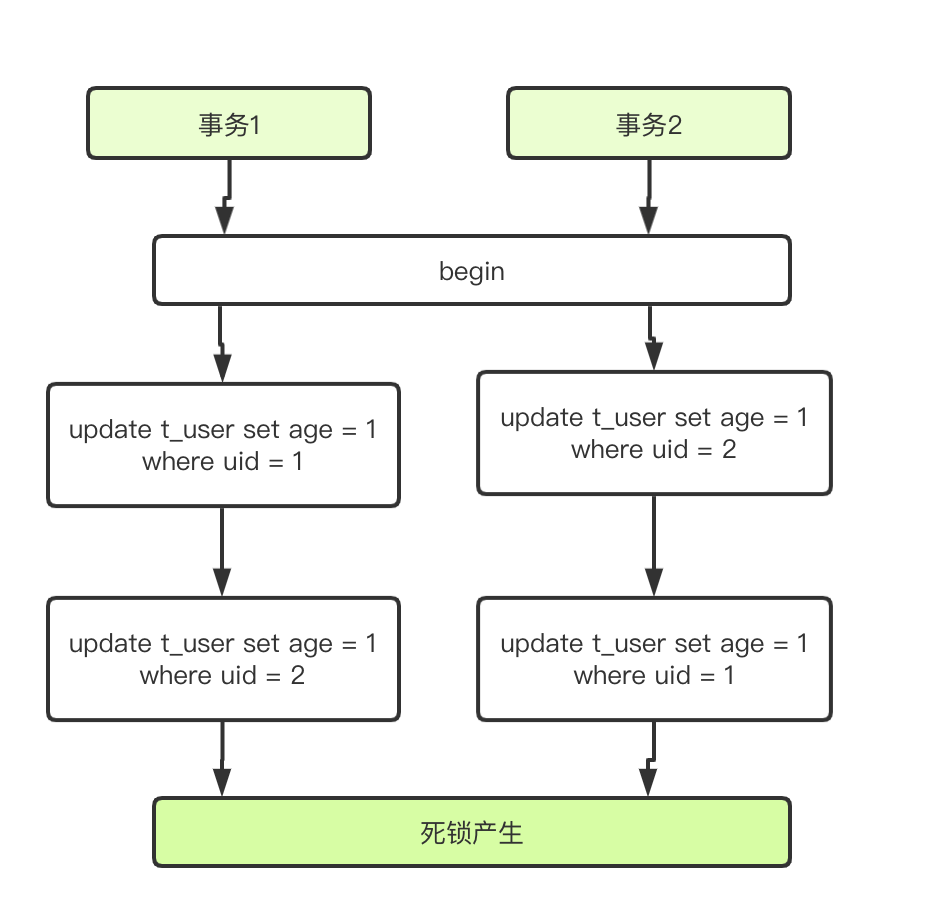
死锁避免方法
- 固定加锁顺序:所有事务按相同顺序锁定资源
- 控制事务大小:减少锁定资源数量和时间
- 使用低隔离级别:如读已提交可减少锁竞争
- 设置超时时间:
innodb_lock_wait_timeout=5(默认50秒)
1.5 间隙锁:防止"插队"的范围锁
当执行范围查询时,InnoDB会锁定整个范围的间隙,防止其他事务插入数据:
-- 表中现有id=5,10的记录
START TRANSACTION;
SELECT * FROM users WHERE id BETWEEN 5 AND 10 FOR UPDATE;
-- 锁定(5,10)间隙,以下操作会阻塞:
INSERT INTO users(id) VALUES(7); -- 阻塞
INSERT INTO users(id) VALUES(6); -- 阻塞
间隙锁的作用:在可重复读隔离级别下防止幻读,但可能增加锁冲突。
二、SQL优化:从"龟速"到"火箭"的蜕变
2.1 优化第一步:定位慢查询
开启慢查询日志
-- 临时开启
SET GLOBAL slow_query_log = ON;
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
SET GLOBAL long_query_time = 1; -- 记录执行时间>1秒的SQL-- 永久开启(my.cnf)
[mysqld]
slow_query_log=1
slow_query_log_file=/var/log/mysql/slow.log
long_query_time=1
分析慢查询日志
# 使用mysqldumpslow工具
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# -s t:按时间排序
# -t 10:显示前10条
2.2 优化核心:读懂EXPLAIN执行计划
EXPLAIN是SQL优化的"CT扫描仪",能显示MySQL如何执行查询:
EXPLAIN SELECT * FROM orders
WHERE user_id=1 AND create_time>'2023-01-01';
EXPLAIN关键字段详解
| 字段 | 含义 | 重要取值 |
|---|---|---|
| type | 访问类型 | ALL(全表扫描)→ ref(索引查找)→ range(范围扫描)→ const(常量查找) |
| key | 使用的索引 | NULL(未使用索引)→ 索引名(使用的索引) |
| rows | 预估扫描行数 | 数值越小越好 |
| Extra | 额外信息 | Using index(覆盖索引)、Using filesort(文件排序)、Using temporary(临时表) |

优化案例:从全表扫描到索引优化
慢SQL:
SELECT * FROM orders WHERE user_id=1; -- type=ALL(全表扫描)
优化步骤:
- 建索引:
CREATE INDEX idx_user_id ON orders(user_id); - 再次EXPLAIN:type=ref,key=idx_user_id,rows大幅减少
2.3 索引优化:打造"快速通道"
索引设计三原则
-
最左前缀原则:复合索引(a,b,c)仅支持a、a+b、a+b+c的查询顺序
-- 有效 SELECT * FROM users WHERE a=1 AND b=2; -- 无效(跳过a) SELECT * FROM users WHERE b=2 AND c=3; -
避免索引失效:
- 不在索引列使用函数:
WHERE SUBSTR(name,1,3)='abc'→ 失效 - 避免隐式转换:
WHERE phone=13800138000(phone是字符串)→ 失效 - 不用%开头的LIKE:
WHERE name LIKE '%mysql'→ 失效
- 不在索引列使用函数:
-
选择合适的索引类型:
- 频繁更新字段:用普通索引
- 唯一值字段:用唯一索引
- 文本搜索:用全文索引(FULLTEXT)
索引优化流程图
1. 分析慢查询日志 → 找到耗时SQL
2. 使用EXPLAIN分析执行计划
3. 检查type是否为ALL/range
4. 检查key是否为NULL(未用索引)
5. 检查Extra是否有Using filesort/Using temporary
6. 根据问题创建/调整索引
7. 重新执行EXPLAIN验证优化效果
2.4 SQL改写技巧:让查询"变聪明"
1. 避免SELECT *,只查需要的字段
-- 优化前
SELECT * FROM users WHERE id=1;
-- 优化后(使用覆盖索引)
SELECT id,name FROM users WHERE id=1;
2. 用UNION替代OR(针对非索引列)
-- 优化前(可能全表扫描)
SELECT * FROM users WHERE age=25 OR address='北京';
-- 优化后(分别使用索引)
SELECT * FROM users WHERE age=25
UNION
SELECT * FROM users WHERE address='北京';
3. 批量操作替代循环单条操作
-- 优化前(100次IO)
FOR i IN 1..100 LOOPINSERT INTO logs VALUES(i, 'log');
END LOOP;
-- 优化后(1次IO)
INSERT INTO logs VALUES(1,'log'),(2,'log'),...,(100,'log');
2.5 案例:从3秒到30毫秒的优化实战
原始SQL(执行3秒):
SELECT o.id, o.order_no, u.name
FROM orders o
LEFT JOIN users u ON o.user_id=u.id
WHERE o.create_time>'2023-01-01' AND o.status=1;
优化步骤:
-
查看执行计划:
- type=ALL(orders表全表扫描)
- Extra=Using filesort(排序耗时)
-
创建复合索引:
CREATE INDEX idx_create_status ON orders(create_time, status); -
优化JOIN和排序:
SELECT o.id, o.order_no, u.name FROM orders o LEFT JOIN users u ON o.user_id=u.id WHERE o.create_time>'2023-01-01' AND o.status=1 ORDER BY o.create_time DESC; -- 利用索引排序,避免filesort -
优化后效果:执行时间从3秒降至30毫秒,提升100倍!
三、总结:锁与优化的核心原则
锁机制核心要点
- 最小锁范围:能用行锁不用表锁,能用间隙锁不用全表锁
- 避免死锁:固定加锁顺序,控制事务大小
- 隔离级别选择:读已提交(高并发)vs 可重复读(强一致)
SQL优化核心要点
- 索引是王道:为查询条件、排序、JOIN字段建索引
- 读懂EXPLAIN:关注type、key、rows、Extra字段
- 减少IO操作:批量操作、覆盖索引、避免全表扫描
掌握锁机制让你避免并发问题,精通SQL优化让查询飞起来。两者结合,才能打造高性能的MySQL应用!