使用canal同步分库分表数据,到 Elasticsearch
作者:小凯
沉淀、分享、成长,让自己和他人都能有所收获!
本文的宗旨在于通过简单干净实践的方式教会读者,配置出一套 Canal 工具服务,来同步分库分表的数据到 Elasticsearch 文件夹系统中。同时在 SpringBoot 工程中,配置出两套数据源,一套是 MySQL + MyBatis,一套是 Elasticsearch + MyBatis。【这是非常重要的设计手段】
虽然现在有 TiDB 这样的分布式数据库,但对于分库分表 + 数据同步ES,依然是非常主流的方案。同时也有一部分是把分库分表的数据同步到 TiDB 使用。
Github:https://github.com/alibaba/canal(opens new window)
#一、组件介绍
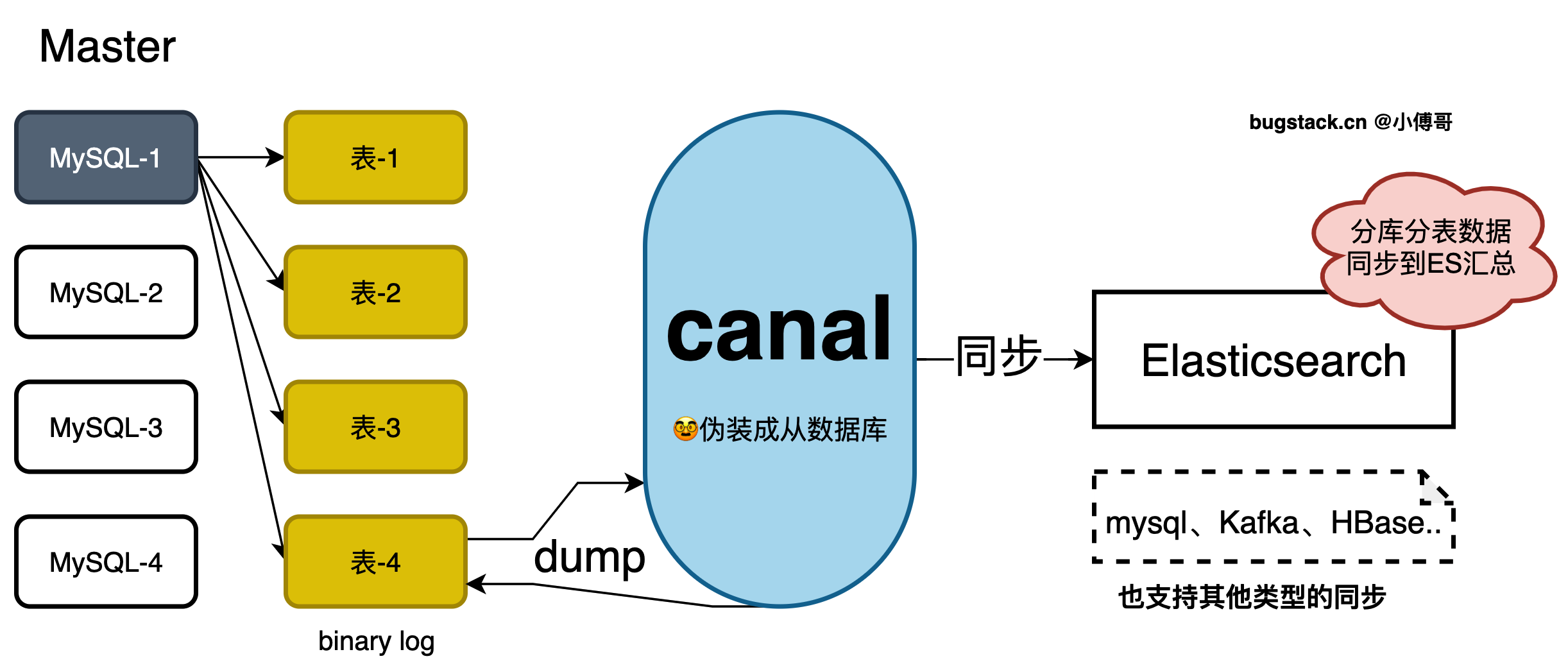
canal ,译为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
它的工作原理是,canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议。在 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) 这样 canal 再解析 binary log (binlog)进行配置分发,同步到 Elasticsearch 等系统中进行使用。
那么有了 canal 就可以把分库分表的数据同步到 Elasticsearch,提供汇总查询和聚合操作,也就不需要把轮训每个分库分表数据了。
二、测试预期
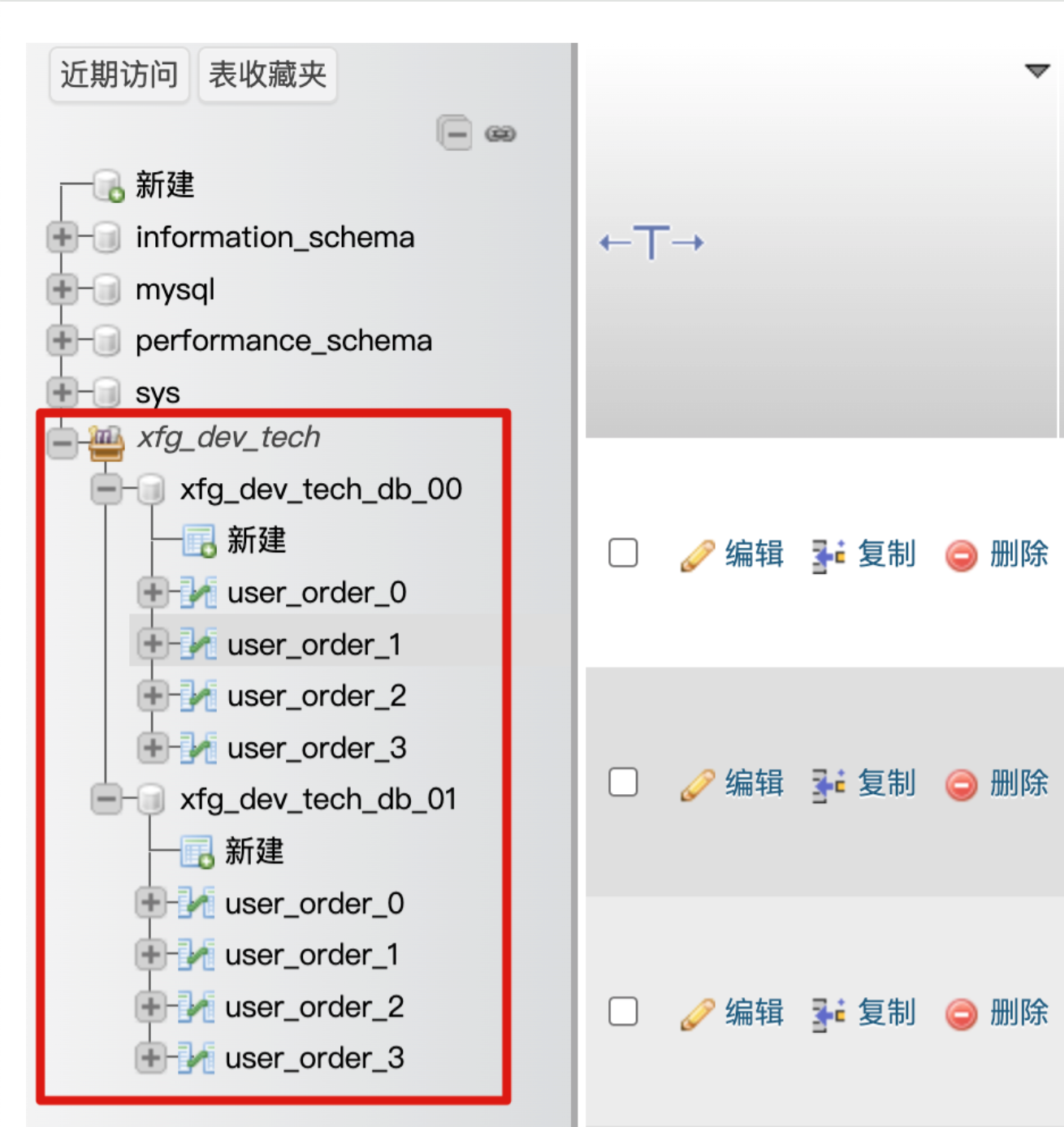
本文的案例会把MySQL,2库4表的数据,通过 Sharding 分库分表写入数据后,同步到 Elasticsearch。分库分表如下(环境安装中会自动安装数据库和设置库表);
三、环境安装
为了让读者伙伴更加简单的学习到这一项方案技能,这里把所需的环境都配置成一整套的 docker compose 脚本文件(ARM、AMD),你只要执行安装即可。安全前注意,无论是本机还是云服务器都需要安装 docker-ce(opens new window)
1. 环境脚本
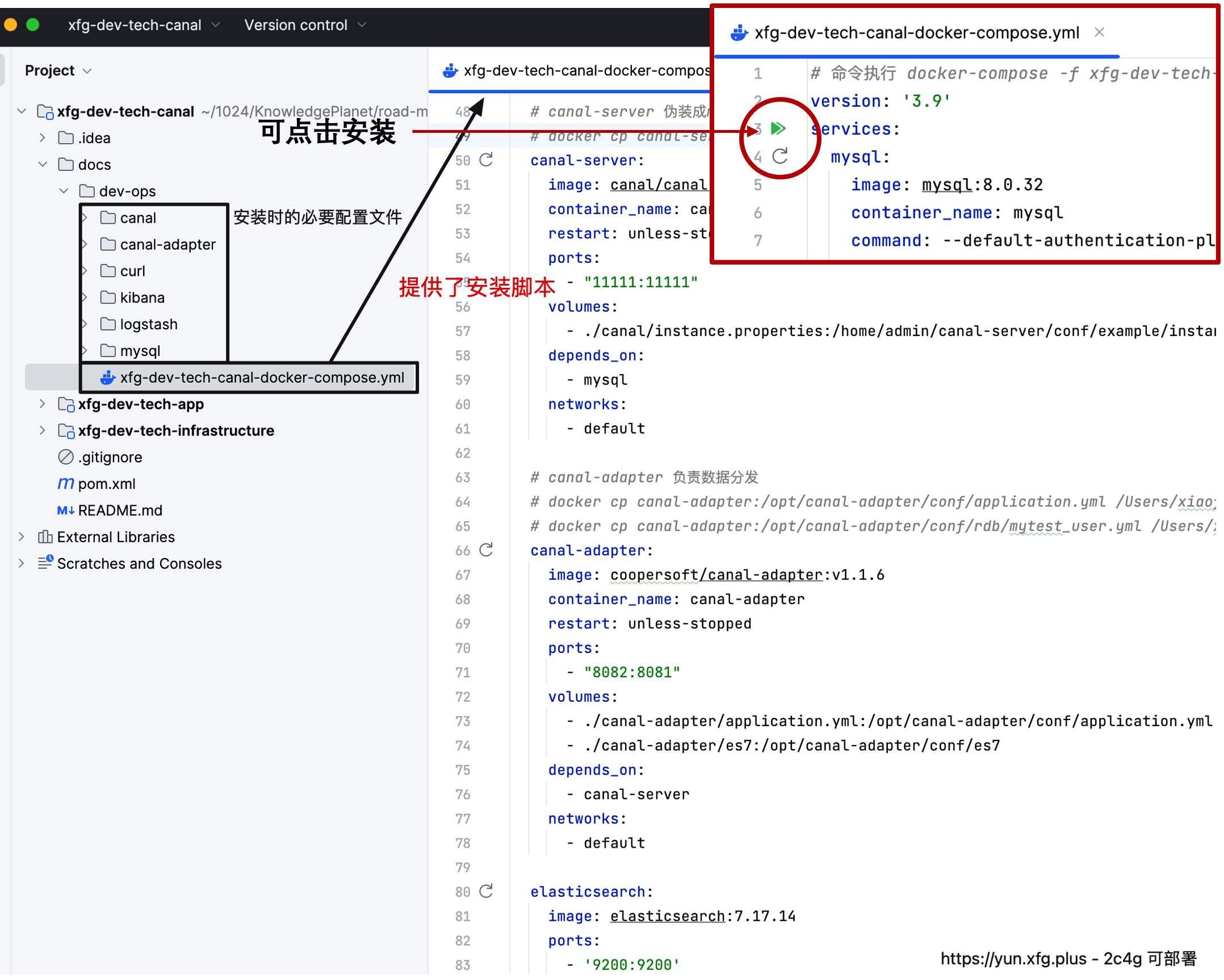
- 打开 xfg-dev-tech-canal 工程,下面就是 docker compose 的执行脚本。
- mac/windows 如果安装了 docker 可以直接点击如图的三角号安装。如果是在 Linux 安装了 docker 可以把 dev-ops 整个文件夹都上传到云服务器,之后通过脚本;docker-compose -f xfg-dev-tech-canal-docker-compose.yml up -d 进行安装。
1.1 开启 binlog
mysql 数据同步需要创建一个 canal 的账户,之后还需要开启 binlog 日志
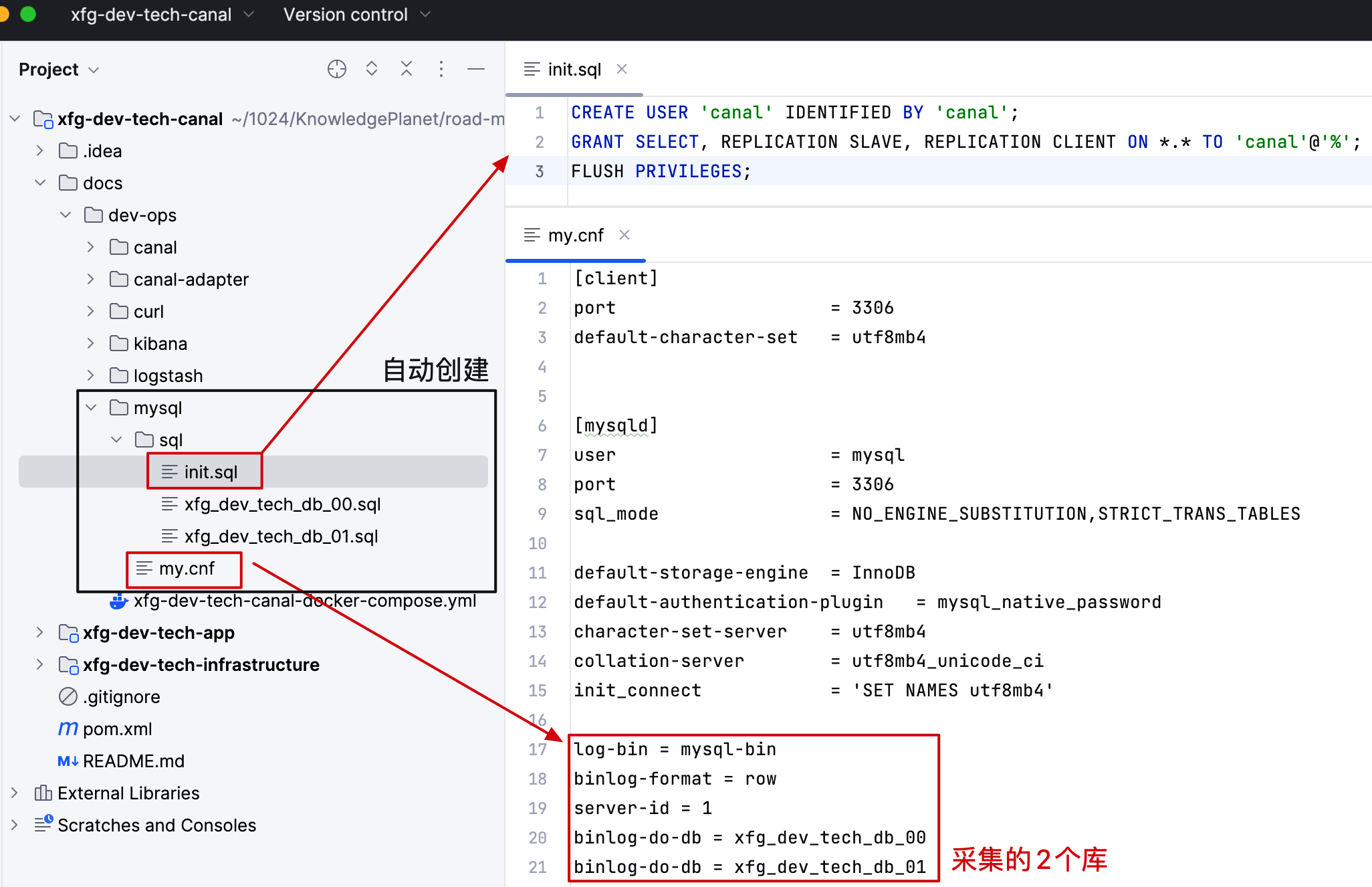
- 在 mysql 配置文件夹中,设置了初始化授权的账户、导入的库表,以及开启 mysql-bin 和配置要采集的库。
- 如果你有配置自己其他的库要同步也可以如此配置。
1.2 库表采集配置
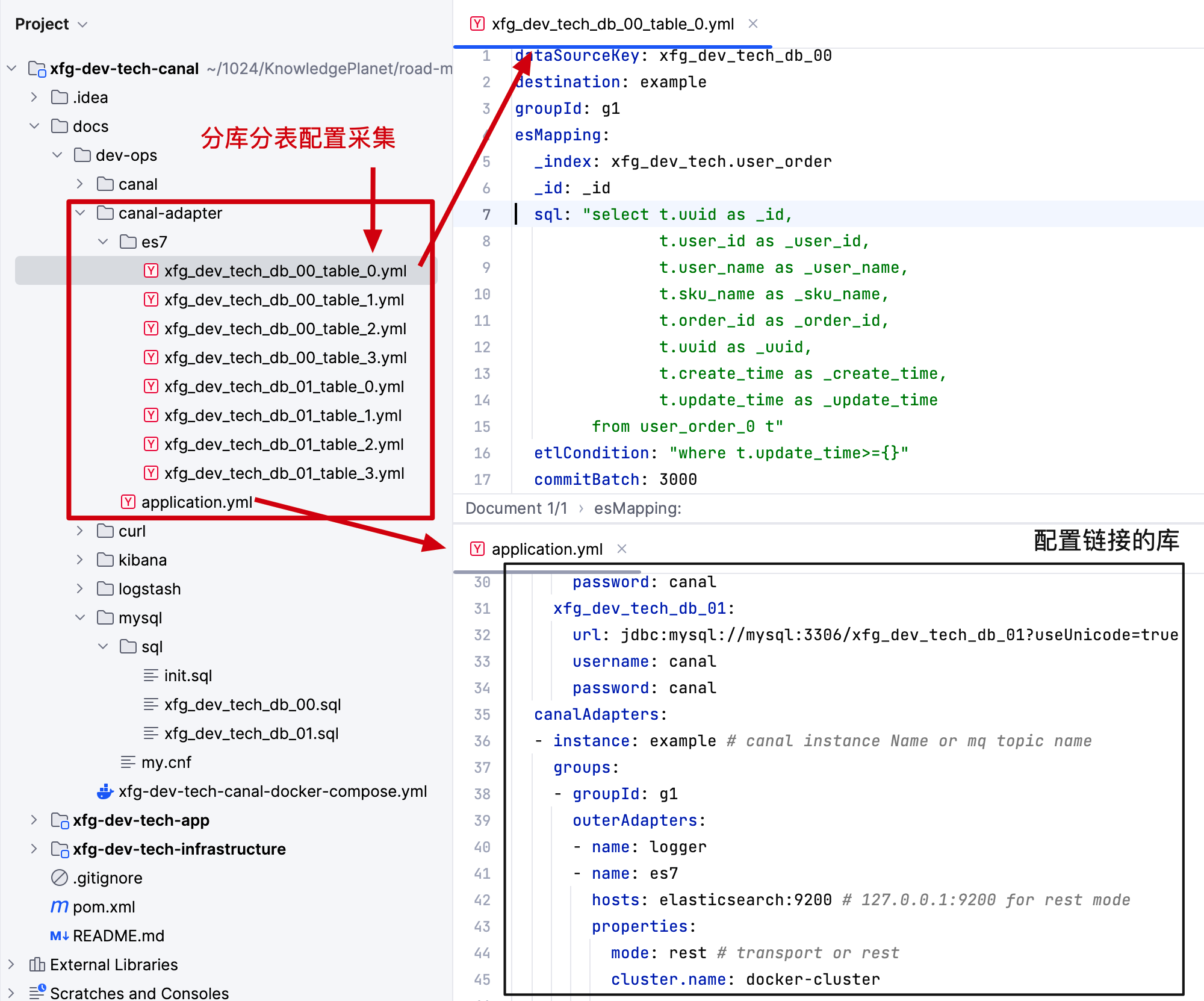
- 本文选择的是 es 同步方式,所以需要在 canal-adapter 中 es7 文件夹添加同步的库表 yml 配置。
- 以及在 application.yml 中配置出需要链接的库表以及同步的目标地址,也就是 es 的地址。【因为本文的案例是在同一个 docker compose 下安装,所以直接用名称 elsticsearch 即可访问】
2. 运行状态
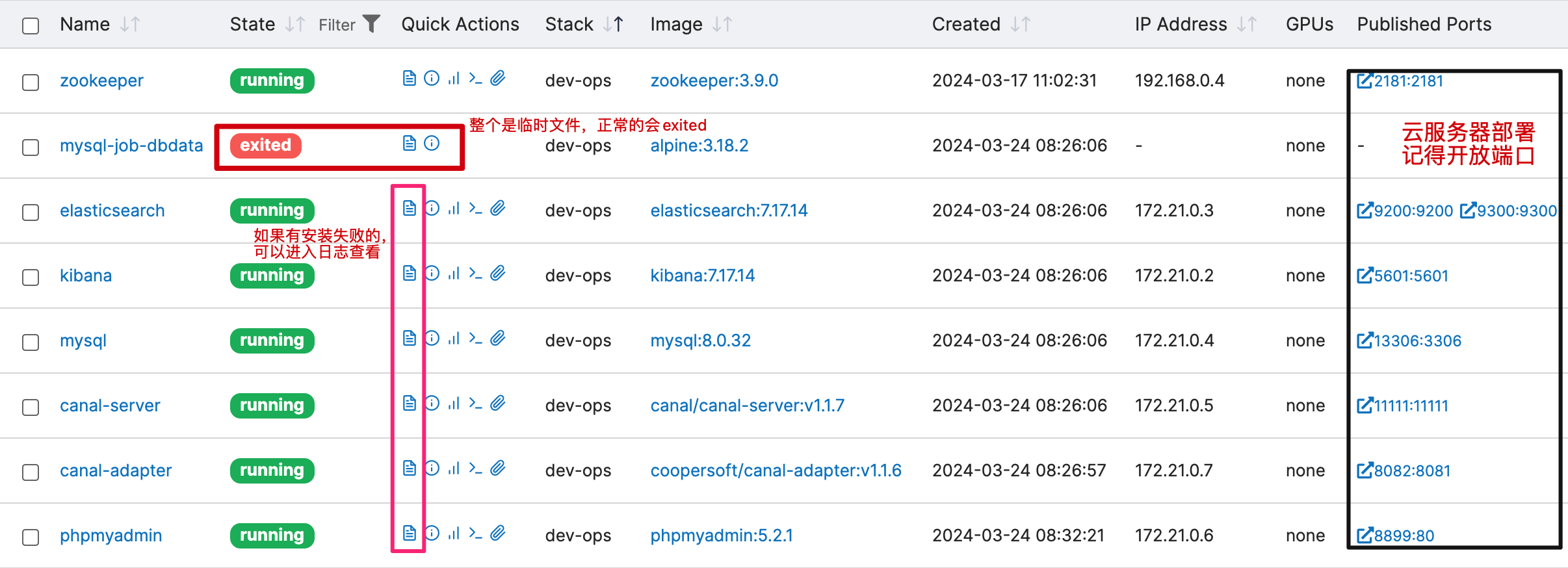
- 安装完成后可以进入 portainer 查看各个组件的运行,如果有哪个运行失败了,可以点击那个小文件的图标,它可以查看日志。
3. 创建索引
在 doc/dev-ops/curl 下提供了创建 Elasticsearch 的脚本;你可以点击执行或者直接复制执行,也可以复制导入到 ApiPost 里执行。
以上这些脚本是为了创建出数据库表同步到 Elasticsearch 后对应的索引和映射的字段。文章下面会用到。
3.1 创建
curl -X PUT "127.0.0.1:9200/xfg_dev_tech.user_order" -H 'Content-Type: application/json' -d'
{"mappings": {"properties": {"_user_id":{"type": "text"},"_user_name":{"type": "text"},"_order_id":{"type": "text"},"_uuid":{"type": "text"},"_create_time":{"type": "date"},"_update_time":{"type": "date"}}}
}'
3.2 添加
curl -X PUT "127.0.0.1:9200/xfg_dev_tech.user_order/_mapping" -H 'Content-Type: application/json' -d'
{"properties": {"_sku_name": {"type": "text"}}
}'
3.3 删除
curl -X DELETE "127.0.0.1:9200/xfg_dev_tech.user_order"
4. 创建索引(Kibana)
4.1 索引管理
地址:http://127.0.0.1:5601/app/management/kibana/indexPatterns(opens new window)
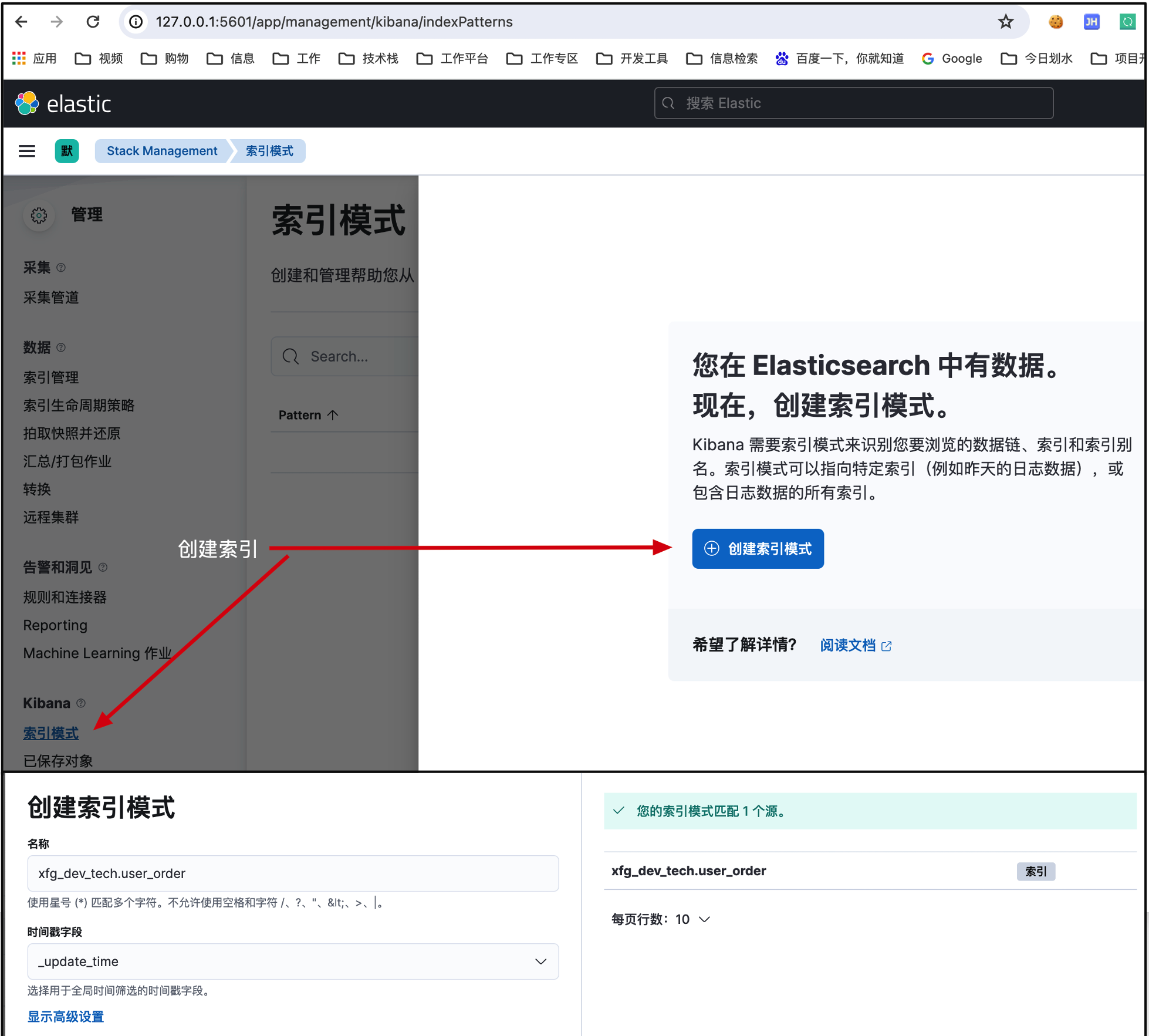
- 填写完,点击创建索引模式即可。
4.2 数据页面
地址:http://127.0.0.1:5601/app/discover(opens new window)
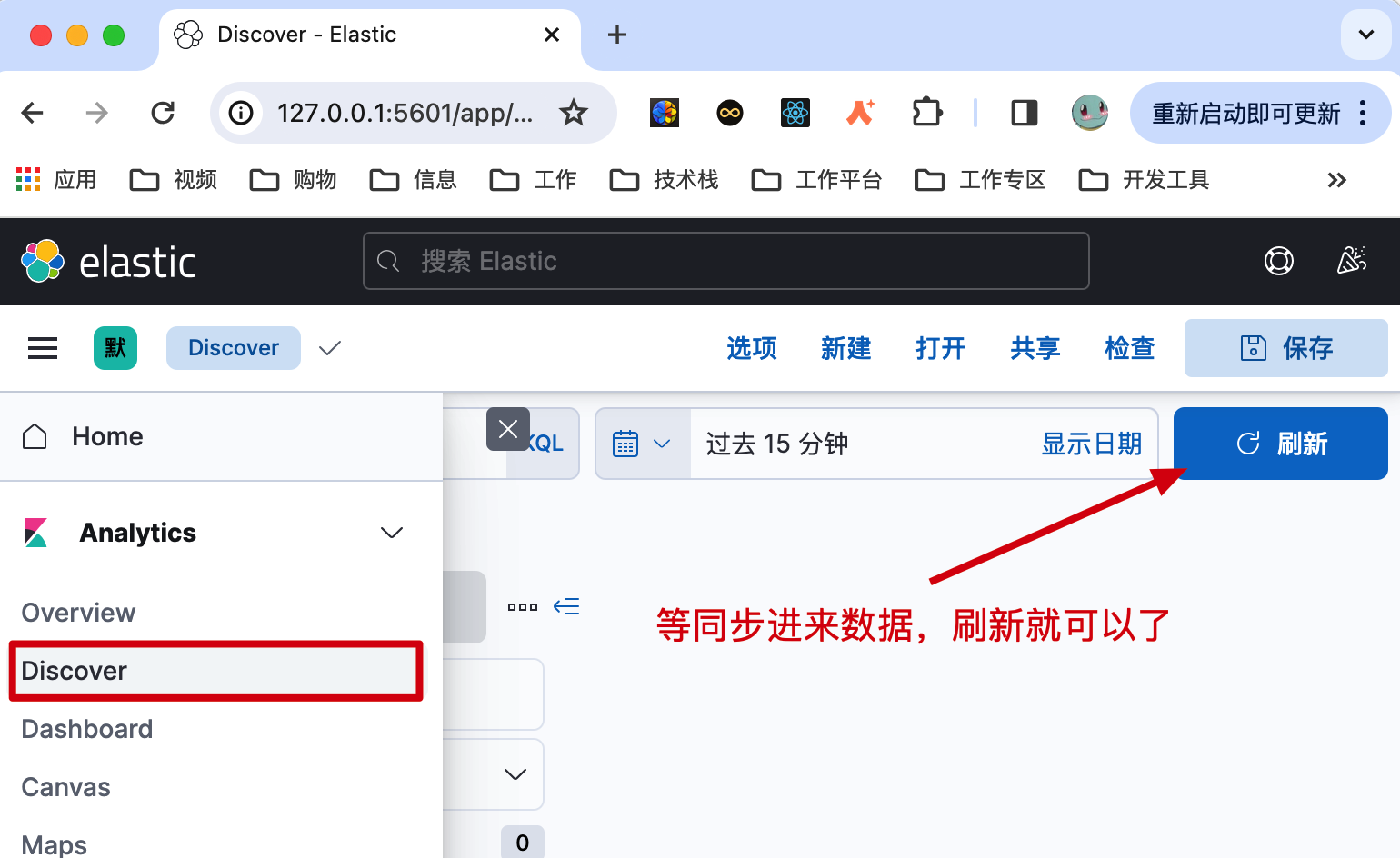
- 等后面同步数据了以后,直接在这里点刷新就可以看到了。
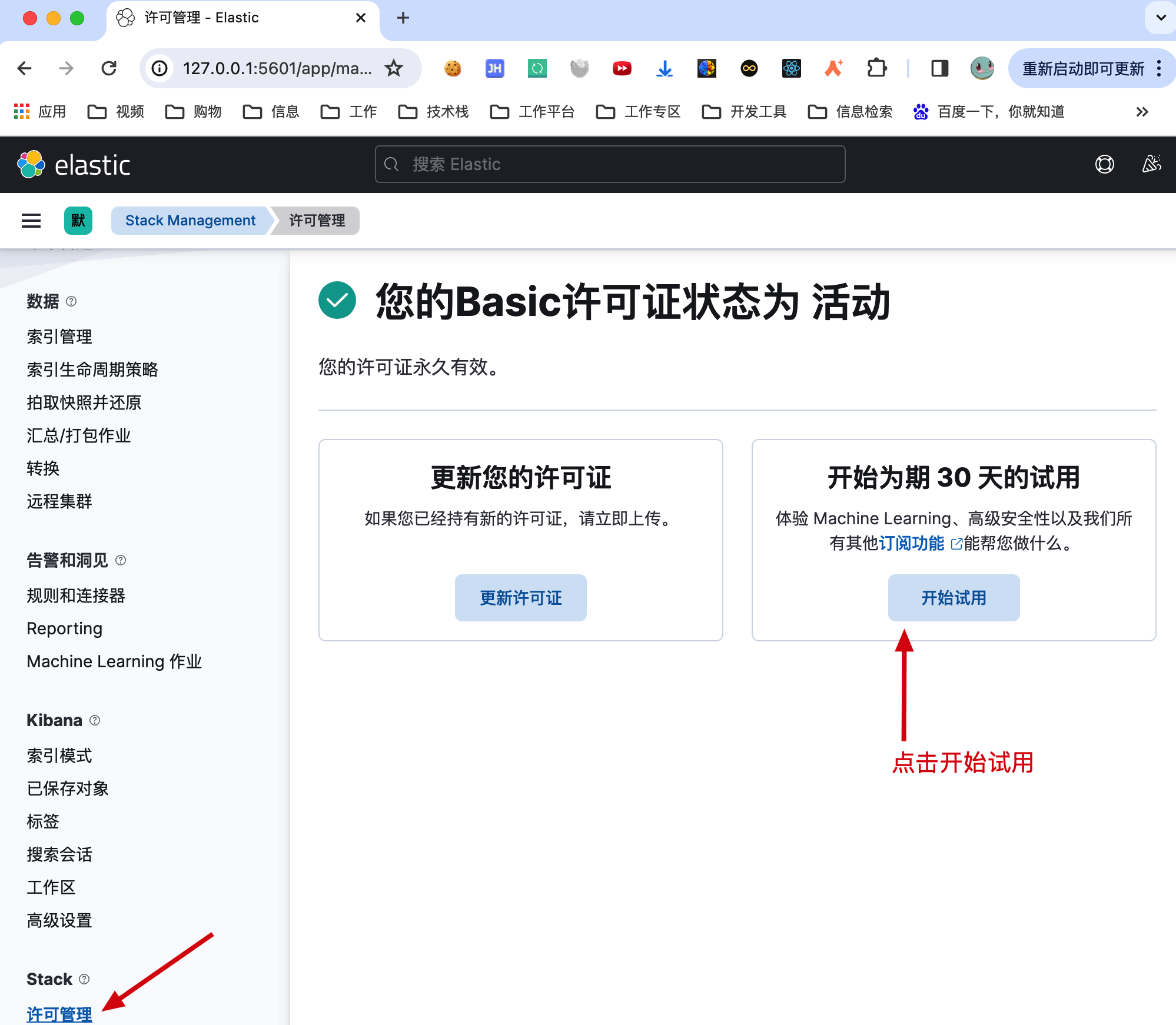
5. 许可证
kibana 提供了免费30天的试用许可,安装后可以使用 x-pack-sql-jdbc。它的好处是可以让我们通过 MyBatis 的方式查询 Elasticsearch 数据。
地址:http://127.0.0.1:5601/app/management/stack/license_management(opens new window)
Elasticsearch 提供了 x-pack-sql-jdbc,让对 Elasticsearch 的查询也可以像使用 MySQL 数据库一样通过 MyBatis 进行查询。但这个 x-pack-sql-jdbc 是付费的,免费可以使用 30 天。之后你可以选择使用重新安装,破解,或者使用 Elasticsearch 的查询方式。还可以自己开发一个 Elasticsearch JDBC,GitHub 上也有类似的组件。
使用时需要引入 POM 配置;
<!-- https://mvnrepository.com/artifact/org.elasticsearch.plugin/x-pack-sql-jdbc -->
<dependency><groupId>org.elasticsearch.plugin</groupId><artifactId>x-pack-sql-jdbc</artifactId><version>7.17.14</version>
</dependency>三、工程配置
本节涉及到了简明教程中所讲解的 Sharding 分库分表 (opens new window)的使用,因为我们需要把分库分表的数据通过 canal 同步到 Elasticsearch。(也可以使用其他分库分表组件)
在工程中配置一套 Sharding 分库分表映射的 MyBatis MyBatis,在配置一套 Elasticsearch x-pack-sql-jdbc 数据源映射的 MyBatis Mapper。这样可以读写分别走自己设定好的 Mapper 对象了。
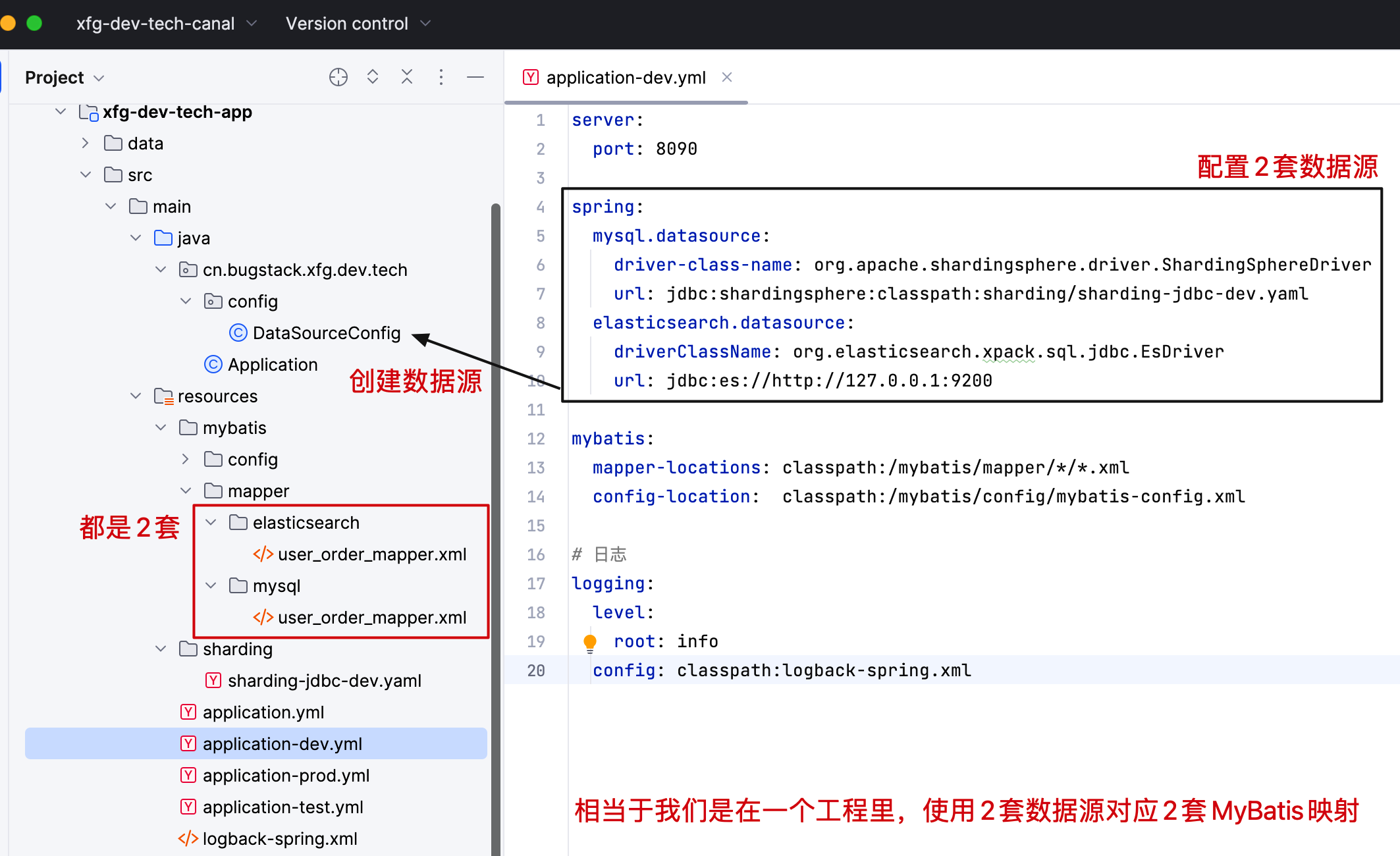
1. 创建数据源
@Configuration
public class DataSourceConfig {@Configuration@MapperScan(basePackages = "cn.bugstack.xfg.dev.tech.infrastructure.dao.elasticsearch", sqlSessionFactoryRef = "elasticsearchSqlSessionFactory")static class ElasticsearchMyBatisConfig {@Bean("elasticsearchDataSource")@ConfigurationProperties(prefix = "spring.elasticsearch.datasource")public DataSource igniteDataSource(Environment environment) {return new EsDataSource();}@Bean("elasticsearchSqlSessionFactory")public SqlSessionFactory elasticsearchSqlSessionFactory(DataSource elasticsearchDataSource) throws Exception {SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();factoryBean.setDataSource(elasticsearchDataSource);factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:/mybatis/mapper/elasticsearch/*.xml"));return factoryBean.getObject();}}@Configuration@MapperScan(basePackages = "cn.bugstack.xfg.dev.tech.infrastructure.dao.mysql", sqlSessionFactoryRef = "mysqlSqlSessionFactory")static class MysqlMyBatisConfig {@Bean("mysqlDataSource")@ConfigurationProperties(prefix = "spring.mysql.datasource")public DataSource mysqlDataSource(Environment environment) {return DataSourceBuilder.create().url(environment.getProperty("spring.mysql.datasource.url")).driverClassName(environment.getProperty("spring.mysql.datasource.driver-class-name")).build();}@Bean("mysqlSqlSessionFactory")public SqlSessionFactory mysqlSqlSessionFactory(DataSource mysqlDataSource) throws Exception {SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();factoryBean.setDataSource(mysqlDataSource);factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:/mybatis/mapper/mysql/*.xml"));return factoryBean.getObject();}}}
- ElasticsearchMyBatisConfig 使用 EsDataSource 创建数据源和映射 MyBatis Mapper 文件。
- MysqlMyBatisConfig 使用 DataSourceBuilder 创建 Sharding 提供的数据源和映射 MyBatis Mapper 文件。
2. Mapper 映射
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.bugstack.xfg.dev.tech.infrastructure.dao.elasticsearch.IElasticsearchUserOrderDao"><resultMap id="dataMap" type="cn.bugstack.xfg.dev.tech.infrastructure.po.UserOrderPO"><result column="_user_id" property="userId"/><result column="_user_name" property="userName"/><result column="_order_id" property="orderId"/><result column="_sku_name" property="skuName"/><result column="_update_time" property="updateTime"/><result column="_create_time" property="createTime"/></resultMap><select id="selectByUserId" resultMap="dataMap">select _user_id, _user_name, _order_id, _sku_namefrom "xfg_dev_tech.user_order"order by _update_timelimit 10</select></mapper>
- 这个是 Elasticsearch 映射的 Mapper 文件,映射的字段就是前面安装环境的时候设置的索引和字段。现在你使用 Elasticsearch 就不用在工程中硬编码查询语句了,变得非常方便。
四、工程测试
1. 写入数据
@Test
public void test_insert() throws InterruptedException {for (int i = 0; i < 3; i++) {UserOrderPO userOrderPO = UserOrderPO.builder().userName("小哥哥").userId("xfg_" + RandomStringUtils.randomAlphabetic(6)).userMobile("+86 13521408***").sku("13811216").skuName("《手写MyBatis:渐进式源码实践》").orderId(RandomStringUtils.randomNumeric(11)).quantity(1).unitPrice(BigDecimal.valueOf(128)).discountAmount(BigDecimal.valueOf(50)).tax(BigDecimal.ZERO).totalAmount(BigDecimal.valueOf(78)).orderDate(new Date()).orderStatus(0).isDelete(0).uuid(UUID.randomUUID().toString().replace("-", "")).ipv4("127.0.0.1").ipv6("2001:0db8:85a3:0000:0000:8a2e:0370:7334".getBytes()).extData("{\"device\": {\"machine\": \"IPhone 14 Pro\", \"location\": \"shanghai\"}}").build();userOrderDao.insert(userOrderPO);Thread.sleep(100);}
}
- 循环插入3条数据,按需你可以设置更多条数据。
- 这里的用户编号 userId 是随机的,也是切分键的 ID,所以会在不同的库表写入数据。
2. 数据验证
MySQL:http://127.0.0.1:8899/ (opens new window)docker compose 配置的管理后台,可以 root/123456 登录
Kibana:http://127.0.0.1:5601/app/discover (opens new window)查询写入的数据。
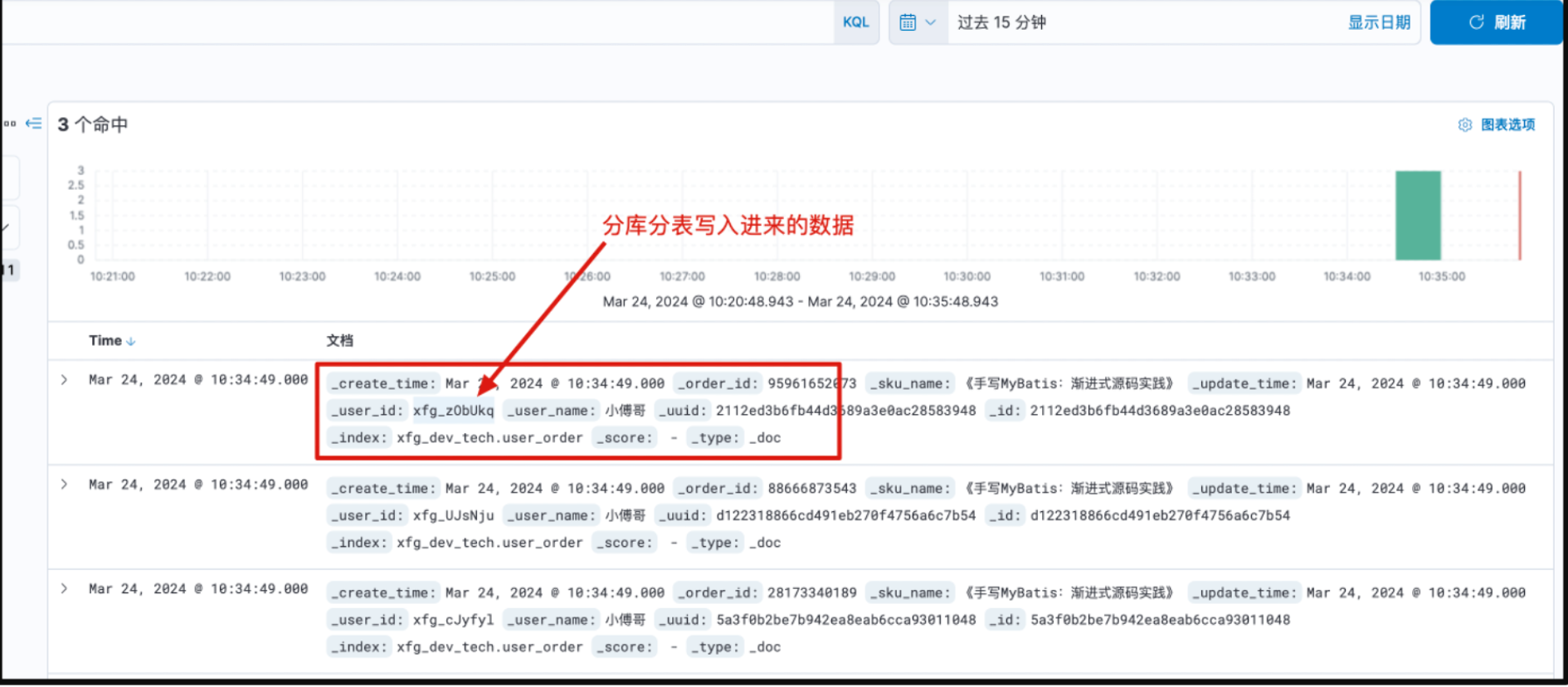
3. 查询数据
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class UserOrderDaoTest {@Resourceprivate IElasticsearchUserOrderDao userOrderDao;@Testpublic void test() {List<UserOrderPO> userOrderPOS = userOrderDao.selectByUserId();log.info("测试结果:{}", JSON.toJSONString(userOrderPOS));}}

- 通过 Elasticsearch 走 x-pack-sql-jdbc 的方式再把数据查询出来