课题学习笔记1——文本问答与信息抽取关键技术研究论文阅读(用于无结构化文本问答的文本生成技术)
上周对国防科技大学的论文进行了阅读,学习了问答的一些基本知识,以及精读了“基于知识图谱的问答”部分,这周继续阅读“用于无结构化文本问答的文本生成技术”部分,这周大部分时间在准备比赛,所以看的有些慢。
1 引言
语义解析是自然语言处 理中一个长期存在的难题。很多方法将自然语言描述 / 问题作 为输入,并使用不同的序列到序列框架以基于文本或基于语法的方式解码生成逻辑表达式。
然而,这些方法忽略了复杂问题在文本空间的可分解性。
而复杂问题通常由一组子问题组成。
所以本论文着眼于对每个子问题以及子问题中的关键信息的理解,通过这种方式帮助对原始复杂问题进行语义解析。

QD 表示问题分解(Question Decomposition),IE 表示子问题信息抽取(Information Extraction),SP 表示语义解析(Semantic Parsing)。阶段 1 中的相关子问题和 阶段 2中每个子问题对应的关系信息可以帮助获得阶段 3 中复杂问题的逻辑表达式。
1.1 此前问题分解方法
利用指针网络在复杂问题中产生分割点,并将复杂问题分离成一个简单问题序列
存在问题:
1)在某些问题中通过拆分点来分解复杂问题,可能找不到最佳的子问题,并损失一些信息。
2)这种方法需要指定子问题以及切分点的数量,对于多于两个子问题的复杂问题切分难度很高。
3)使用单独的基于检索的阅读理解进行后续子问题问答,增加了后续任务难度并带来了处理管道间的错误传播问题。
2 本文方法
层次语义解析 (HSP: Hierarchical Semantic Parsing)模型,层次化的序列到序列的框架
主要思路是文本空间的分解和向量空间的聚合

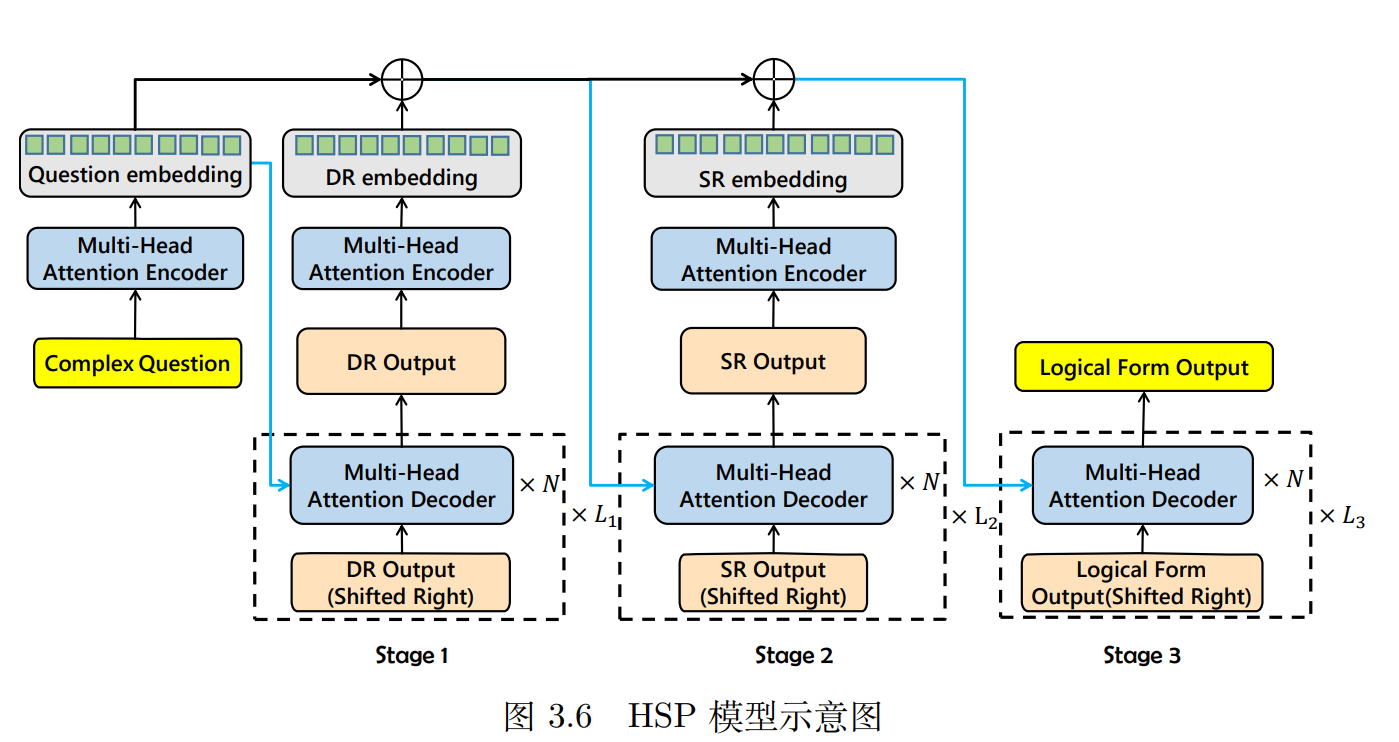
图3.6是模型示意图,我们接下来具体分析是如何实现的。
2.1 基本单元--解析单元 (Parsing Unit)
框架组成:序列到序列
输入:输入序列(字符序列)![]() 、约束信息(辅助信息编码后的向量序列)
、约束信息(辅助信息编码后的向量序列)![]()
输出:解析后的目标序列(字符序列)![]()
编码器部分
输入编码:
- 将输入序列中的每个单词映射为词向量(通过
EMB函数)。 - 使用 L 层 Transformer 编码器处理词向量,得到上下文表示
h = fenc(a) = fe(EMB(a))。
- 将输入序列中的每个单词映射为词向量(通过
约束信息融合:
- 将编码器输出
h与额外约束信息e进行向量拼接,得到融合表示h¯ = [h; e]。
- 将编码器输出
解码器部分
输入与解码方式:
解码器以融合信息
h¯为基础,采用自回归方式逐词生成输出序列。在时间步
t,根据历史输出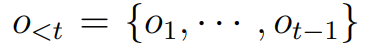 计算条件概率
计算条件概率 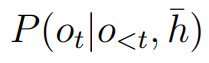 。
。
解码过程:
词嵌入与位置编码:将历史输出
o<t通过词向量和位置向量映射为解码器输入表示。L 层 Transformer 解码:
每一层
l的输出k_l_j依赖于上一层的输出k_{l-1}≤j和融合信息h¯,表示为k_l_j = Layer(k_{l-1}≤j, h¯)。Layer函数通过两种注意力机制实现:多头自注意力:捕获解码器内部的历史依赖关系。
编码器 - 解码器注意力:关联融合信息
h¯,引入输入序列和约束的上下文。
输出概率计算:
最后一层输出
k_L_j通过线性变换和 Softmax 函数得到词库V上的预测概率分布: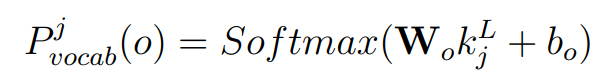
拷贝机制
拷贝机制是解码器中的一个增强模块,用于在生成过程中“直接复制输入中的某些词”到输出中,以解决生成词表中没有的实体、专有名词等问题。
产生原因:回答中包含实体(如“电影名”“人名”)这些词往往不在固定词表中(OOV问题)。
拷贝机制的核心思想
传统的序列到序列模型只能从固定词表中生成词,而拷贝机制允许模型:
- 生成(Generate):从预定义词表中选择词元;
- 拷贝(Copy):直接从输入序列中复制词元。
典型实现方式
拷贝机制通常是对解码器加的一层逻辑
解码器输出概率分布时分两路:
1. 生成概率 P_gen(o):
从词表中生成下一个词(通过 Softmax(W·k + b),即正常Transformer decoder输出)
2. 拷贝概率 P_copy(o):
根据注意力权重,指向输入中位置的概率,表示模型想“复制”输入中的哪个词
论文实现方式
扩展解码器输出层:在公式 3.5
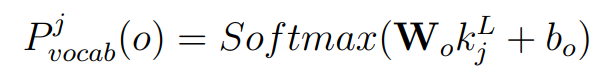 的基础上,增加一个生成 / 拷贝开关:
的基础上,增加一个生成 / 拷贝开关: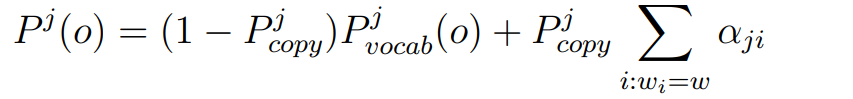
修改注意力机制:在解码器的多头注意力中,加入对输入序列的直接关注,计算拷贝位置的权重。
处理重复词:当输入序列中存在多个相同词元时,需累加它们的注意力权重。
2.2 HSP
HSP 是论文提出的一种用于复杂知识图谱问答的语义解析方法。它的目标是将复杂自然语言问题解析为结构化的逻辑表达式(如 SPARQL 查询),以便在知识图谱中执行查询并得到答案。
核心思想:
将复杂问题分解为多个子问题,逐步抽取各子问题中的语义信息(如关系、约束),最后聚合生成完整的逻辑表达式。
模块一:问题分解器(Question Decomposer)
作用:
将复杂问题 自动划分为多个子问题,每个子问题关注一个语义片段,如一个约束、一个目标关系。
举例:
问题:"Who is the tallest actor born in Canada?"
可能被分解为:
q₁: "Who is an actor?"q₂: "Who was born in Canada?"q₃: "Who is the tallest?"
方法实现:
使用 Pointer Network 模型找出问题切分点(训练时有标签,推理时模型预测分割位置)
模块二:语义提取单元(Semantic Extractor)
作用:
对每个子问题进行语义编码与结构信息抽取,例如识别其对应的谓词关系、实体类别、聚合操作。
技术细节:
使用论文中介绍的基本单元
融合子图信息(例如候选实体的邻居关系)
使用 拷贝机制 保留输入中的实体词
使用多头注意力机制进行上下文建模
输出:
对每个子问题 q_i,输出一个子逻辑单元(如:born_in(Canada), type=actor, argmax(height))
模块三:语义聚合器(Semantic Aggregator)
作用:
将多个子逻辑单元组合为一个完整的逻辑表达式,用于查询知识图谱。
方法实现:
根据子问题之间的逻辑顺序和依赖,构建语法树或SPARQL表达式结构
对聚合操作(如 argmax)、布尔运算(如 and, or)等特殊关系进行建模
现在,我们再来看文章开篇提到的HSP框架结构图
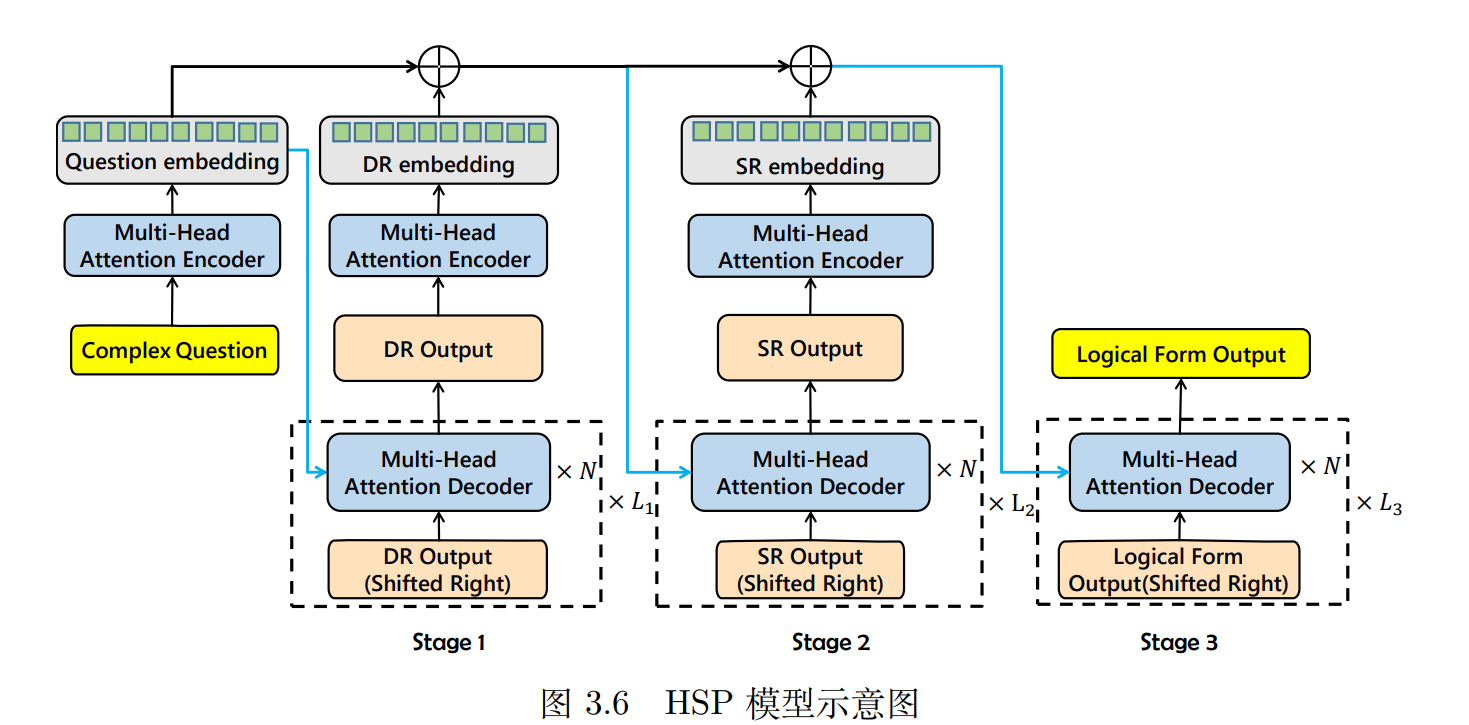
Stage 1 — DR:Decoding the Decomposed Relation (主要目标解析)
输入:
复杂自然语言问题
Complex Question
编码器:
对问题进行词嵌入 → Transformer 编码(Multi-Head Attention Encoder) → 得到上下文向量(
Question Embedding)
解码器:
使用多层 Transformer 解码器逐步生成一个结构化的中间表示
DR Output(代表主谓关系或主要查询目标)
特点:
是对问题的“初步理解”
比如:“Who is the tallest actor born in Canada?” → 可能提取出:“actor.height”
Stage 2 — SR:Decoding Sub-Relation (子约束解析)
输入:
上一阶段生成的 DR Output
原始问题 Question(蓝色箭头回传)
编码器:
对 DR Output 进行嵌入并再次编码,得到上下文表示
解码器:
使用 DR + Question 的信息解码,输出 SR Output,代表子约束信息
举例:
解码器:
输出:
“born in Canada” 这样的条件限制
Stage 3 — Logical Form:构建完整逻辑表达式
输入:
SR Output(嵌入编码)
蓝线回传的 DR Output 和原始问题(再次使用 Question Embedding)
使用所有前两阶段的信息,融合生成最终的逻辑表达式
Logical Form Output,可以直接转换为 SPARQL 或程序结构
蓝色箭头和 ⊕ 符号表示什么?
蓝色箭头: 表示信息从前一阶段传入下一阶段,作为额外上下文参考
⊕ 符号: 表示信息融合,例如多个向量拼接或加权平均等,用于增强解码器对上文的感知能力
下周我将会对论文继续阅读