串口通信性能优化
背景:
1.一个中型项目,选择的是“软件定时器+状态机”的任务调度方案;
2.其中定时器的时基依赖定时器5的溢出中断,1ms一次(中断优先级最高(0,0))
3.串口中断优先级最高(0,0),//这里有1个坑,待会说
4.串口解析依赖自定义的软件框架(判断\r\n和EVENT_ID,以及查表,具体方法以后再谈)
**
需求:
**
1.客户需要5ms能解析一包,并且连续测试100000次,不丢包。
我设计的是串口解析的任务是1ms触发一次。【从这个角度看似乎没问题,应该能满足要求】
**
问题:
**
1. 5ms一次通信测试,任何指令都可能丢包
2. 5ms一次通信测试,但是关闭软件定时器,把串口解析放到main的死循环里,大多数指令不丢包,只有查表算法的相关指令丢包
**
问题分析
**:
1.软件定时器的定时器中断,冲掉了串口中断【不确定是不是这个原因,但是肯定和中断或调度器有关】
2.查表算法太慢
**
解决方案探索:
**
解决问题当然是先解决底层再解决应用层。
所以,先把中断处理好,再处理算法;
【简单粗暴的方法 处理中断】:把串口中断的优先级 高于 定时器中断//验证结果:似乎不起作用
///经过接近1个小时的排查,发现中断优先级的影响不大,是任务调度耗时导致的问题。
//经过接近两个半小时的排查,发现
任务调度的问题有两个:1)原先的调度方案的核心函数有缺陷
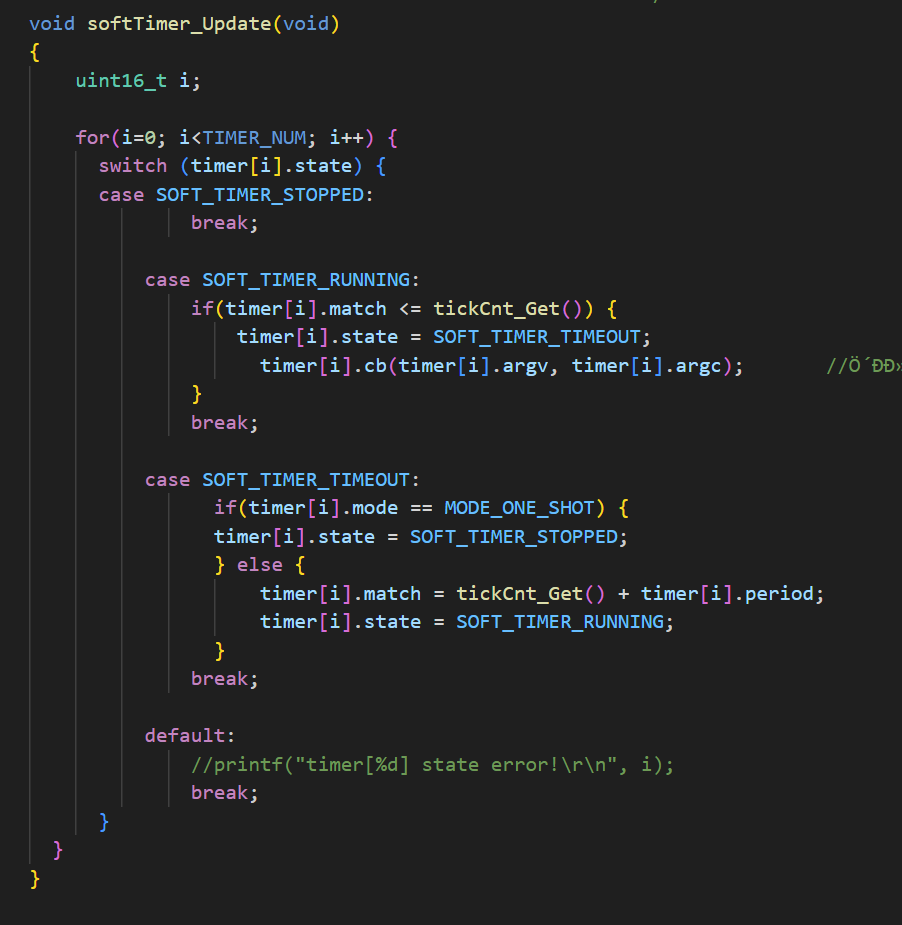
这是原先的调度器核心函数
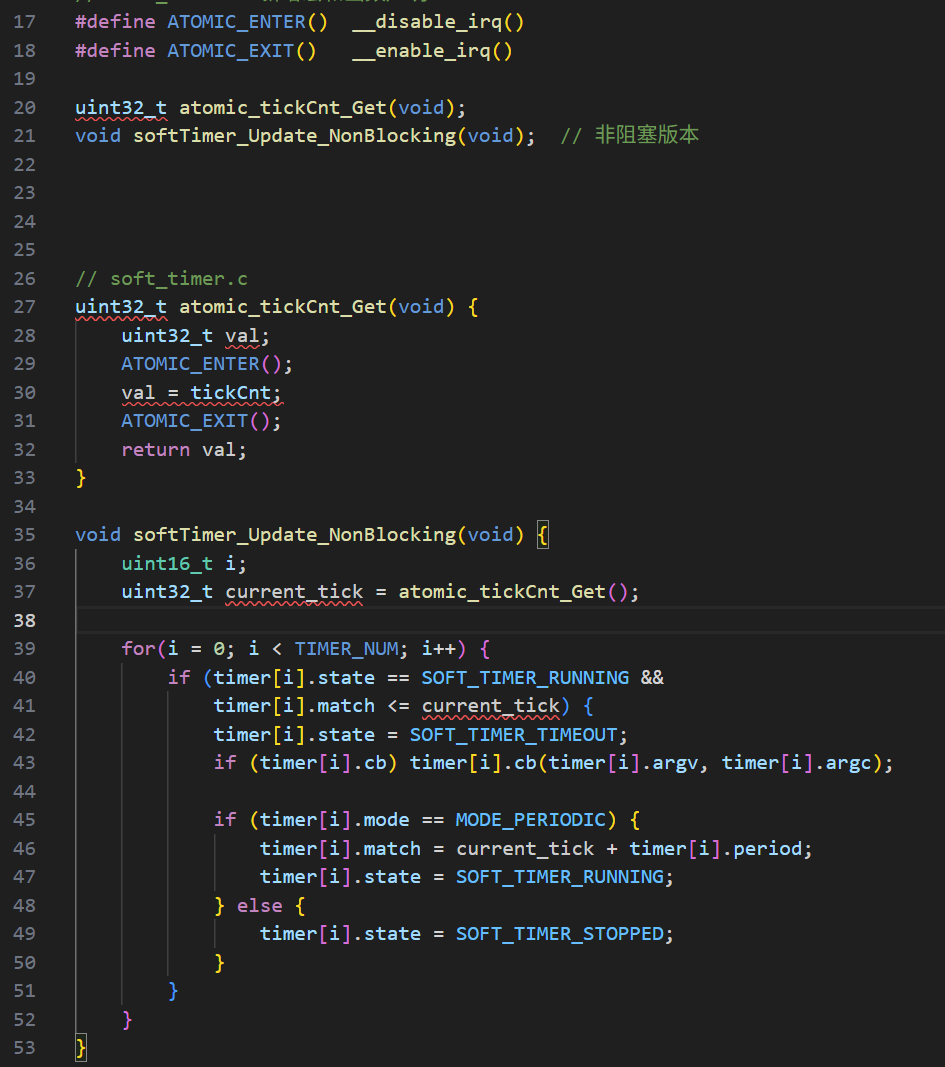
这是新的调度器核心函数
两份调度器核心函数的对比
// softTimer_Update(传统实现)
void softTimer_Update(void) {for (int i = 0; i < TIMER_NUM; i++) {switch (timer[i].state) {case SOFT_TIMER_RUNNING:if (timer[i].match <= tickCnt_Get()) {timer[i].state = SOFT_TIMER_TIMEOUT;timer[i].cb(); // 直接执行回调}break;case SOFT_TIMER_TIMEOUT:if (timer[i].mode == MODE_ONE_SHOT) {timer[i].state = SOFT_TIMER_STOPPED;} else {timer[i].match = tickCnt_Get() + timer[i].period;timer[i].state = SOFT_TIMER_RUNNING;}break;}}
}// softTimer_Update_NonBlocking(优化版)
#define ATOMIC_ENTER() __disable_irq()
#define ATOMIC_EXIT() __enable_irq()uint32_t atomic_tickCnt_Get(void);
void softTimer_Update_NonBlocking(void); // 非阻塞版本
uint32_t atomic_tickCnt_Get(void) {uint32_t val;ATOMIC_ENTER();val = tickCnt;ATOMIC_EXIT();return val;
}
void softTimer_Update_NonBlocking(void) {uint32_t current_tick = atomic_tickCnt_Get(); // 原子读取for (int i = 0; i < TIMER_NUM; i++) {if (timer[i].state == SOFT_TIMER_RUNNING && timer[i].match <= current_tick) {timer[i].state = SOFT_TIMER_TIMEOUT;if (timer[i].cb) timer[i].cb(); // 执行回调// 周期性任务:立即重置,避免漏检if (timer[i].mode == MODE_PERIODIC) {timer[i].match = current_tick + timer[i].period;timer[i].state = SOFT_TIMER_RUNNING;}}}
}

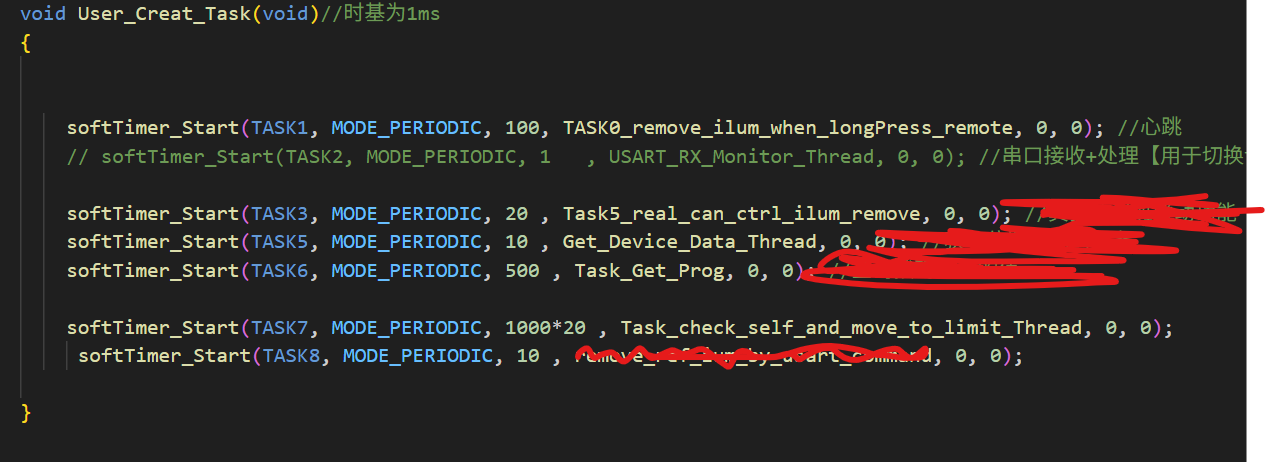
2)在软件定时器里添加的任务里,串口解析是1ms1次,这个频率对于自定义的调度器来说压力比较大。解决方法是把时间短的任务抽离调度器,直接放到死循环里;
如图:
在User_Creat_Task()里把,USART_RX_Monitor_Thread()注释掉;
把USART_RX_Monitor_Thread()放到main的死循环里
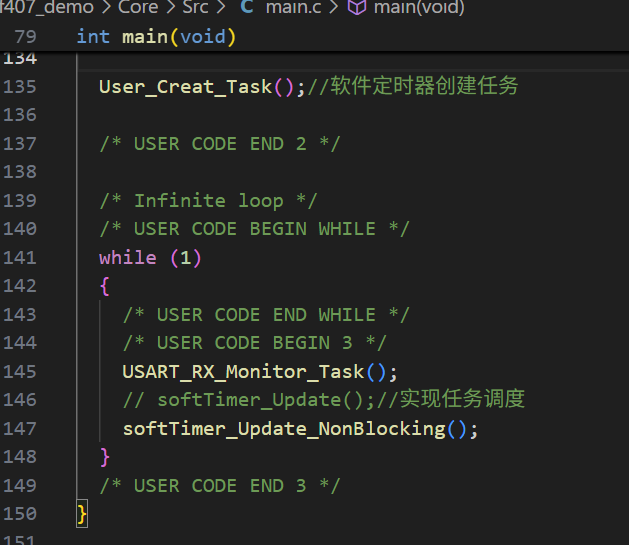
经过测试,5ms通信丢包概率明显降低‘,但依然存在(偶发)。
继续分析,出现问题的时候通常是一包数据在接收的数据被打断了,可以新增环形缓冲区应对。
**
接下来是串口空闲中断+DMA接收+环形缓冲区的解决方案:(经过测试:该方案“调整调度器核心函数+中断优先级+环形缓冲区”,可以实现不丢包(5ms))
调整调度器核心函数+中断优先级 已经在前面说过了;
“串口空闲中断+DMA接收+环形缓冲区”示例代码如下:
USART_APP.h文件声明变量和函数
#define RING_BUF_SIZE 512typedef struct {uint8_t buf[RING_BUF_SIZE];volatile uint16_t head; // 原子操作或关中断保护volatile uint16_t tail;volatile bool overflow; // 溢出标志
} RingBuffer;extern RingBuffer uart_rx_ring;
/* USER CODE BEGIN Prototypes */
bool ring_buffer_write(RingBuffer* rb, uint8_t* data, uint16_t len) ;
uint16_t ring_buffer_read(RingBuffer* rb, uint8_t* dest, uint16_t max_len);
void Task_ring_buffer_init();
在USART_APP.c里添加环形缓冲区函数
初始化,写入,读取
// 初始化
void ring_buffer_init(RingBuffer* rb) {rb->head = rb->tail = 0;rb->overflow = false;
}// 安全写入(关中断版)
bool ring_buffer_write(RingBuffer* rb, uint8_t* data, uint16_t len) {uint32_t primask = __get_PRIMASK();__disable_irq();uint16_t free_space = (rb->tail > rb->head) ? (rb->tail - rb->head - 1) : (RING_BUF_SIZE - rb->head + rb->tail - 1);if (len > free_space) {rb->overflow = true;__set_PRIMASK(primask);return false;}uint16_t space_until_wrap = RING_BUF_SIZE - rb->head;uint16_t chunk = (len <= space_until_wrap) ? len : space_until_wrap;memcpy(&rb->buf[rb->head], data, chunk);rb->head = (rb->head + chunk) % RING_BUF_SIZE;if (chunk < len) {memcpy(&rb->buf[rb->head], data + chunk, len - chunk);rb->head = (rb->head + len - chunk) % RING_BUF_SIZE;}__set_PRIMASK(primask);return true;
}// 安全读取
uint16_t ring_buffer_read(RingBuffer* rb, uint8_t* dest, uint16_t max_len) {uint32_t primask = __get_PRIMASK();__disable_irq();uint16_t avail = (rb->head >= rb->tail) ? (rb->head - rb->tail) : (RING_BUF_SIZE - rb->tail + rb->head);uint16_t len = (max_len <= avail) ? max_len : avail;uint16_t space_until_wrap = RING_BUF_SIZE - rb->tail;uint16_t chunk = (len <= space_until_wrap) ? len : space_until_wrap;memcpy(dest, &rb->buf[rb->tail], chunk);rb->tail = (rb->tail + chunk) % RING_BUF_SIZE;if (chunk < len) {memcpy(dest + chunk, &rb->buf[rb->tail], len - chunk);rb->tail = (rb->tail + len - chunk) % RING_BUF_SIZE;}__set_PRIMASK(primask);return len;
}void Task_ring_buffer_init()
{ring_buffer_init(&uart_rx_ring);
}usart.c
串口DMA接收改为: hdma_usart3_tx.Init.Mode = DMA_CIRCULAR;
if(uartHandle->Instance==USART3){/* USER CODE BEGIN USART3_MspInit 0 *//* USER CODE END USART3_MspInit 0 *//* USART3 clock enable */__HAL_RCC_USART3_CLK_ENABLE();__HAL_RCC_GPIOD_CLK_ENABLE();/**USART3 GPIO ConfigurationPD8 ------> USART3_TXPD9 ------> USART3_RX*/GPIO_InitStruct.Pin = GPIO_PIN_8;GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;GPIO_InitStruct.Pull = GPIO_NOPULL;GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;GPIO_InitStruct.Alternate = GPIO_AF7_USART3;HAL_GPIO_Init(GPIOD, &GPIO_InitStruct);GPIO_InitStruct.Pin = GPIO_PIN_9;GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;GPIO_InitStruct.Pull = GPIO_PULLUP;GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;GPIO_InitStruct.Alternate = GPIO_AF7_USART3;HAL_GPIO_Init(GPIOD, &GPIO_InitStruct);/* USART3 DMA Init *//* USART3_RX Init */hdma_usart3_rx.Instance = DMA1_Stream1;hdma_usart3_rx.Init.Channel = DMA_CHANNEL_4;hdma_usart3_rx.Init.Direction = DMA_PERIPH_TO_MEMORY;hdma_usart3_rx.Init.PeriphInc = DMA_PINC_DISABLE;hdma_usart3_rx.Init.MemInc = DMA_MINC_ENABLE;hdma_usart3_rx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;hdma_usart3_rx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;// hdma_usart3_rx.Init.Mode = DMA_NORMAL;hdma_usart3_tx.Init.Mode = DMA_CIRCULAR;hdma_usart3_rx.Init.Priority = DMA_PRIORITY_LOW;hdma_usart3_rx.Init.FIFOMode = DMA_FIFOMODE_DISABLE;if (HAL_DMA_Init(&hdma_usart3_rx) != HAL_OK){Error_Handler();}__HAL_LINKDMA(uartHandle,hdmarx,hdma_usart3_rx);/* USART3_TX Init */hdma_usart3_tx.Instance = DMA1_Stream3;hdma_usart3_tx.Init.Channel = DMA_CHANNEL_4;hdma_usart3_tx.Init.Direction = DMA_MEMORY_TO_PERIPH;hdma_usart3_tx.Init.PeriphInc = DMA_PINC_DISABLE;hdma_usart3_tx.Init.MemInc = DMA_MINC_ENABLE;hdma_usart3_tx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;hdma_usart3_tx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;hdma_usart3_tx.Init.Mode = DMA_NORMAL;hdma_usart3_tx.Init.Priority = DMA_PRIORITY_LOW;hdma_usart3_tx.Init.FIFOMode = DMA_FIFOMODE_DISABLE;if (HAL_DMA_Init(&hdma_usart3_tx) != HAL_OK){Error_Handler();}__HAL_LINKDMA(uartHandle,hdmatx,hdma_usart3_tx);/* USART3 interrupt Init */HAL_NVIC_SetPriority(USART3_IRQn, 0, 0);HAL_NVIC_EnableIRQ(USART3_IRQn);/* USER CODE BEGIN USART3_MspInit 1 *//* USER CODE END USART3_MspInit 1 */}
串口解析APP层
void Usart3_Handle() //USART3对接收的�???帧数据进行处�???
{//旧版丢包逻辑{// Command_handler(rx3_buffer,rx3_len);//串口指令集解析}//新版子新增环形缓冲区的逻辑{uint16_t len_rx = 0;len_rx = rx3_len;uint8_t data[64];ring_buffer_write(&uart_rx_ring, rx3_buffer, len_rx);len_rx = ring_buffer_read(&uart_rx_ring, data, sizeof(data));Command_handler(data,len_rx);//串口指令集解析}memset(rx3_buffer,0,BUFFER_SIZE);rx3_len = 0;//清除计数rec3_end_flag = 0;//清除接收结束标志�???huart3.RxState = HAL_UART_STATE_READY;HAL_UART_Receive_DMA(&huart3,rx3_buffer,BUFFER_SIZE);//重新打开DMA接收}
**
总结(这个不用看,后来测试发现不行):
1)中断优先级调整:串口中断要高于定时器中断
2)软件定时器核心函数优化,实现无阻塞切换
3)把实时性高的任务剥离出来,放到main函数的死循环,不放在调度器里
4)串口DMA初始化改为hdma_usart3_tx.Init.Mode = DMA_CIRCULAR; 5)增加环形缓冲区
**
**
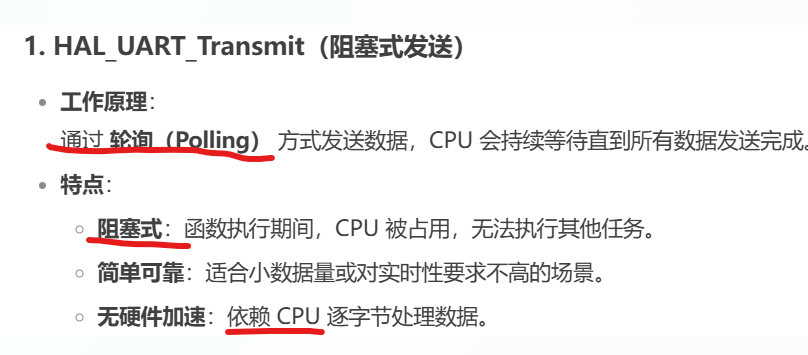
注意: 经测试环形缓冲区也不行, 还有其他因素在阻塞! 经过排查发现,串口发送调用的是HAL_UART_Transmit; 这个接口是阻塞式发送,它会占用CPU!
MCU串口接收数据后要回复,回复用到HAL_UART_Transmit。cpu被阻塞了
**
把串口发送从HAL_UART_Transmit换成HAL_UART_Transmit_DMA后,不再丢包,能承受1ms一次的通信不丢包

总结(这个有用!!!!!):
0)串口空闲中断+DMA 用于接受一包数据
1)中断优先级调整:串口中断要高于定时器中断
2)软件定时器核心函数优化,实现无阻塞切换
3)把实时性高的任务剥离出来,放到main函数的死循环,不放在调度器里
4)把串口发送从HAL_UART_Transmit换成HAL_UART_Transmit_DMA,不占用CPU