DeepSeek 入门指南
什么是大语言模型(LLM)
大语言模型(英语:Large Language Model,简称LLM)是指使用大量文本数据训练的深度学习模型,使得该模型可以生成自然语言文本或理解语言文本的含义。这些模型可以通过在庞大的数据集上进行训练来提供有关各种主题的深入知识和语言生产。其核心思想是通过大规模的无监督训练学习自然语言的模式和结构,在一定程度上模拟人类的语言认知和生成过程。
- 核心特点
- 规模庞大:参数量通常在数十亿到数千亿之间,模型越大,表现通常越好。
- 预训练与微调:先在大量通用文本上预训练,再针对特定任务微调。
- 多功能性:适用于文本生成、翻译、问答、摘要等多种任务。
- 上下文理解:能够处理长文本并理解上下文关系。
- 关键技术
- Transformer架构:使用自注意力机制处理长距离依赖。
- 自监督学习:通过预测被掩码的词或下一句来进行预训练。
- 大规模计算资源:训练需要强大的计算能力和海量数据。
- 应用场景
- 文本生成:如写作、代码生成。
- 对话系统:如智能助手、客服。
- 信息提取:如问答、摘要。
- 翻译与多语言处理:如跨语言翻译。
- 挑战与问题
- 计算资源需求高:训练和推理成本大。
- 数据偏见:可能反映训练数据中的偏见。
- 可解释性差:决策过程不透明。
- 伦理风险:可能被滥用生成虚假信息。
本文由CSDN@Aray1234 原创,转载请注明出处。
什么是DeepSeek
公司简介
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司。DeepSeek 是一家创新型科技公司,成立于2023年7月17日,使用数据蒸馏技术,得到更为精炼、有用的数据。由知名私募巨头幻方量化孕育而生,专注于开发先进的大语言模型(LLM)和相关技术。
DeepSeek 网址:DeepSeek | 深度求索
DeepSeek模型简介
目前,大多数大模型都是基于Transformer。Transformer 是2017年google提出来的,最早提出self-attention机制,论文名称就是《attention is all you need》。大模型依靠的主要有数据、算力和算法,以往都是普遍认为数据量越大,算力越高,算法越先进,大模型的表达能力就会越好。而DeepSeek能够爆火的原因之一就是因为通过算法和训练机制的改进,使得用相对较少的算力能够取得与GPT相当甚至更好的性能。
以训练成本为例,OpenAI 训练 GPT-4 的成本高达 1 亿美元,而 DeepSeek 训练 V3 模型的成本仅为 557.6 万美元,不到 GPT-4 的十分之一。在 API 服务定价上,DeepSeek-R1 的输出 API 价格为每百万输出 tokens 16 元,而 OpenAI o1 模型的输出 API 价格为每百万输出 tokens 438 元,DeepSeek-R1 的价格仅为 OpenAI o1 的约 3% 。这种巨大的价格差异,使得 DeepSeek 在市场竞争中具有明显的成本优势,能够吸引更多对价格敏感的用户和企业。
DeepSeek-R1
发布并开源的DeepSeek-R1性能对标OpenAI-o1,DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。关于DeepSeek的论文链接:DeepSeek-R1/DeepSeek_R1.pdf
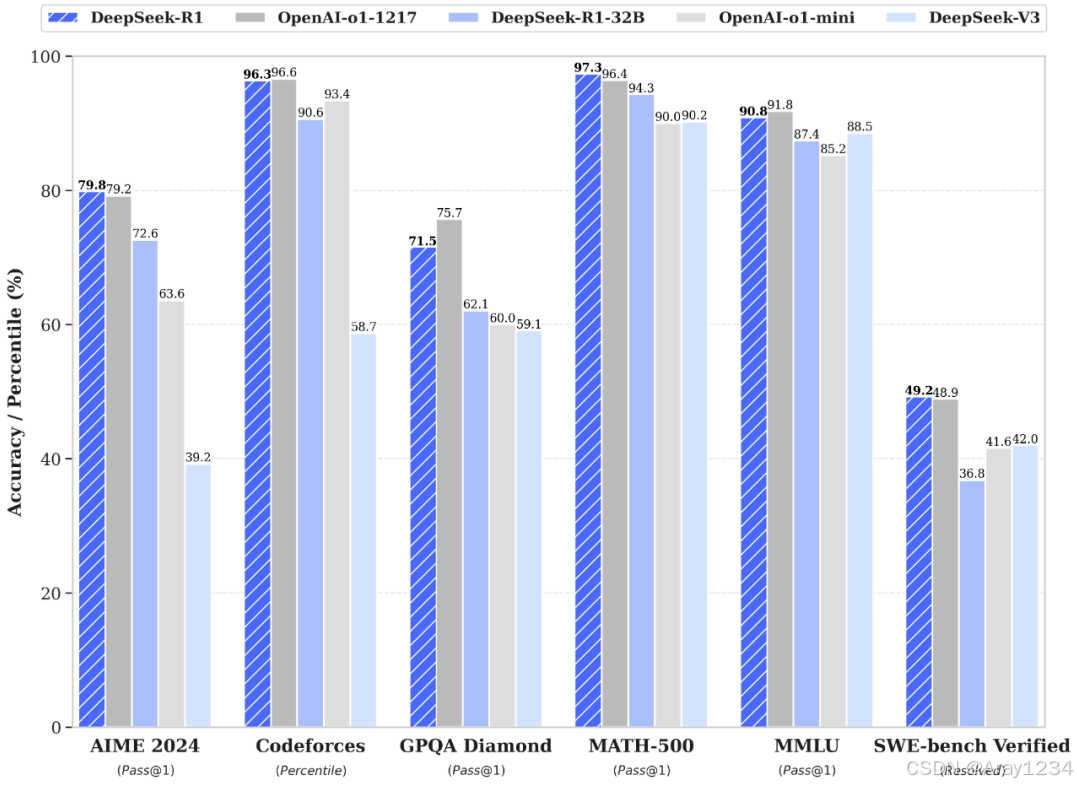
蒸馏小模型超越 OpenAI o1-mini
通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
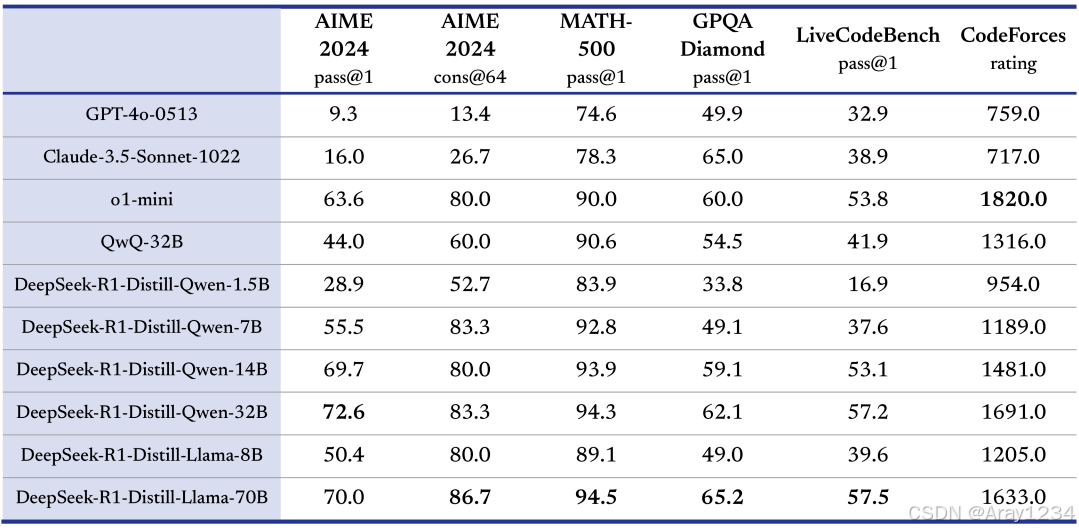
如何本地部署DeepSeek
本地运行
DeepSeek官方Github提供了本地部署的可选硬件和开源社区软件:https://github.com/deepseek-ai/DeepSeek-V3?tab=readme-ov-file#6-how-to-run-locally,但基本都是面向开发者,在下一章,我们将介绍使用Ollama+Open WebUI进行部署的示例。
本地化部署最好有GPU显卡, 完全使用CPU进行计算有可能会比较慢。
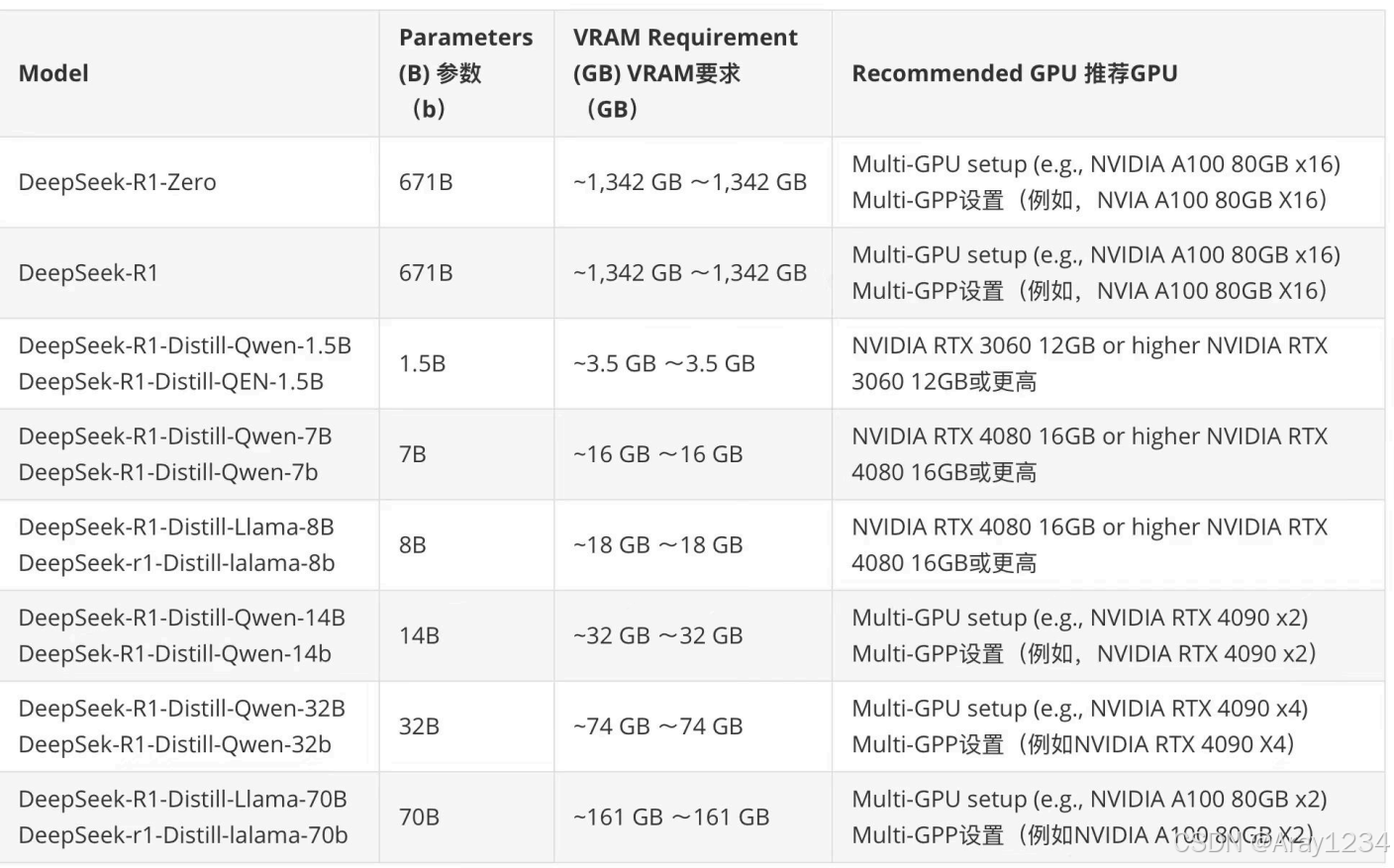
以下给出了DeepSeek各模型的推荐配置:
使用Ollama本地部署
推荐使用Ollama本地部署DeepSeek,使用Open WebUI(适用于Linux系统)或者Chatbox作为对话界面。需要先下载Ollama,可以使用 https://ollama.com/download 在不同操作系统(macOS, Linux, Windows)进行安装, 也可以使用Docker进行安装,Ollama在Docker Hub上传了官方镜像 ollama/ollama - Docker Image | Docker Hub。 Ollama有多种流行的开源大模型可供下载,如DeepSeek-r1, llama3.3, qwen。 更多模型查找链接 https://ollama.com/search。
下面介绍在Linux上使用Docker安装Ollama+Open WebUI, 以及在Windows上安装Ollama+Chatbox。
Linux: Docker安装Ollama+Open WebUI
使用Docker安装Ollama和Open WebUI十分方便,在安装好Docker和配置好镜像源以后,可以使用命令: docker pull ollama/ollama 拉取Ollama镜像 ollama/ollama - Docker Image | Docker Hub。
根据是否使用GPU,有不同的运行镜像步骤:
-
运行Ollama
- 只使用CPU,直接运行
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama - 使用Nvidia GPU, 需要先安装Nvidia Container Toolkit, 可以使用Apt或者Yum/Dnf安装。
-
安装Nvidia Container Toolkit
-
使用Apt
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \ | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \ | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \ | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get updatesudo apt-get install -y nvidia-container-toolkit -
使用Yum or Dnf
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo \ | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.reposudo yum install -y nvidia-container-toolkit
-
-
安装完Nividia Container Toolkit以后,就可以配置Docker使用Nvidia 驱动
sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker -
运行Ollama
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
-
- 只使用CPU,直接运行
-
运行Open WebUI
Ollama容器运行以后,就可以运行Open WebUI容器:docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open- webui/open-webui:main然后访问 127.0.0.1:3000 就可以访问对话界面了,Ollama内置了默认的基础模型,如果需要使用llama或者deepseek-r1,可以使用管理员账号在对话界面进行添加模型。
-
添加模型
可以使用管理员账号在新对话界面添加新模型,直接搜索并下载即可,比如下图正在下载deepseek-r1的8B模型,下载可能较慢,建议科学上网:
下载好后选择相应模型即可使用:
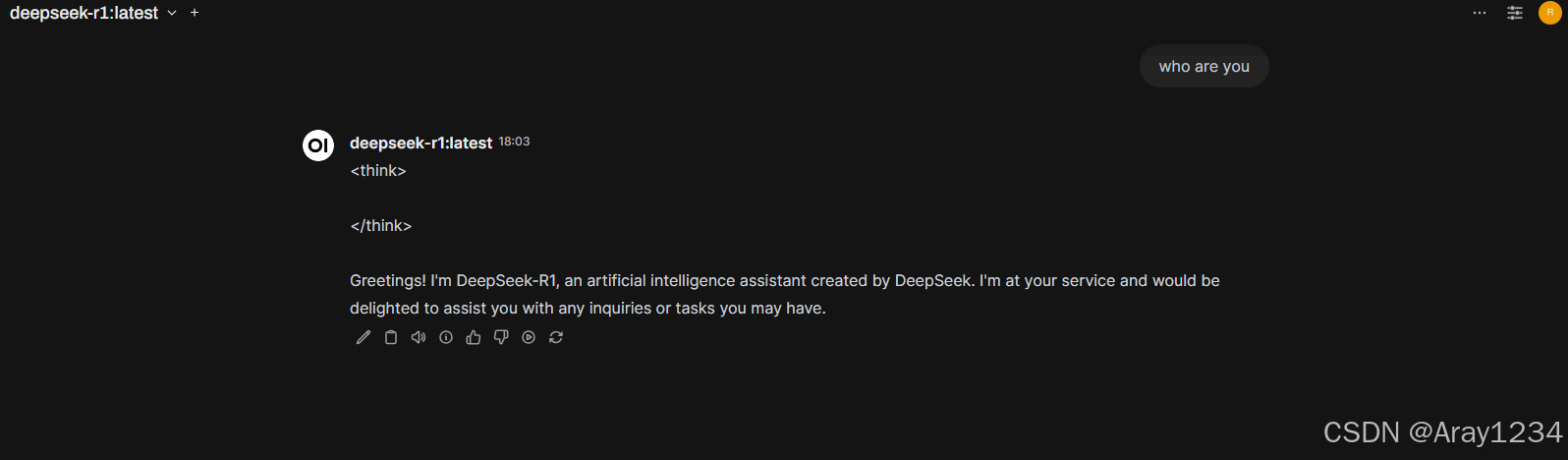
Windows: 安装Ollama+Chatbox
直接在Download Ollama on Windows下载Ollama的Windows版本,下载完成以后直接安装,安装完成后启动Ollama服务,然后命令行输入要部署的模型的运行命令。如:ollama run deepseek-r1:7b
然后会自动下载。如果下载较慢或中断,可以用魔塔 模型库首页 · 魔搭社区 (modelscope.cn)手动下载模型到.ollama/models目录下,再运行命令即可。
安装Ollama后就可以下载安装Chatbox了,Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载,完成后直接打开进入设置界面:
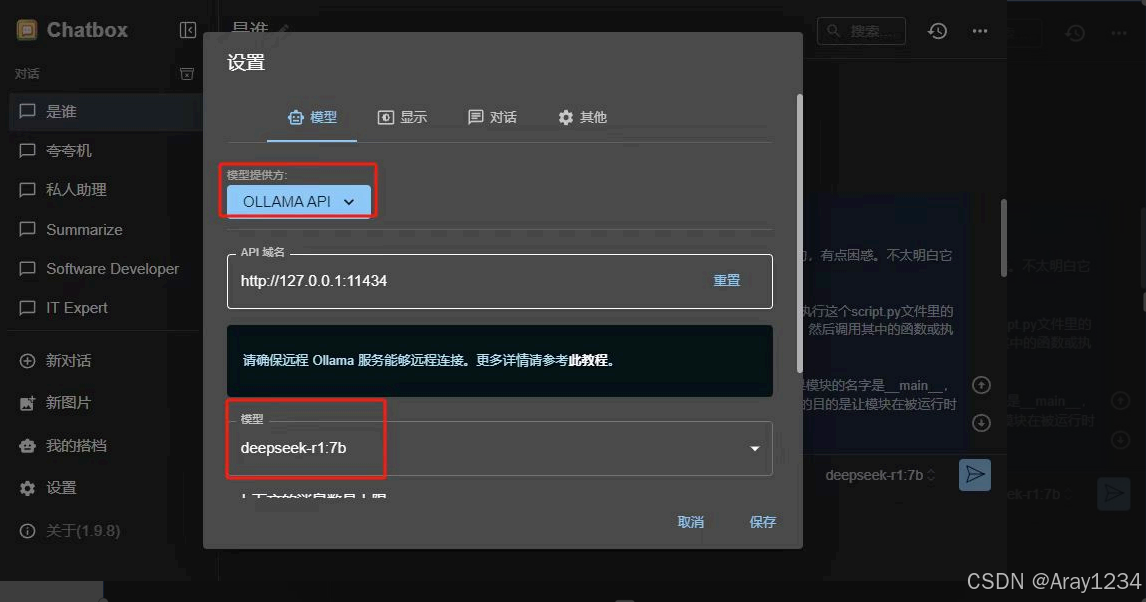
模型提供方选择OLLAMA API, 然后选择模型,保存后即可进行本地对话。
DeepSeek官方13个Prompt模板
Prompt 是指向模型提供的输入文本或指令,用于引导其生成特定类型的输出。在自然语言处理(NLP)
和生成式 AI 模型中,prompt 是用户与模型交互的核心方式。
- 定义
Prompt 是用户提供给 AI 模型的输入,通常是一个问题、指令或一段文本,用于引导模型生成符合
预期的响应。
例如,在 ChatGPT 中,输入“写一首关于秋天的诗”就是一个 prompt。 - 作用
引导模型行为:通过设计 prompt,可以控制模型生成的内容风格、格式或主题。
优化输出质量:清晰的 prompt 能帮助模型更好地理解任务,生成更准确的回答。
适应不同任务:通过调整 prompt,模型可以完成多种任务,如翻译、总结、问答等。 - 类型
指令型:明确告诉模型要做什么,例如“总结以下文章”。
开放式:允许模型自由发挥,例如“写一个故事”。
上下文型:提供背景信息,例如“假设你是一名医生,解释感冒的症状”。
示例型:通过示例引导模型,例如“像这样写:……”。
DeepSeek 官方提供了13个Prompt模板,具体模板请参考Prompt Library | DeepSeek API Docs,本文不再赘述。
DeepSeek API使用
使用官方API
DeepSeek官方提供了API,DeepSeek API Docs, 通过在DeepSeek开放平台https://platform.deepseek.com/申请token付费使用。
DeepSeek API 使用与 OpenAI 兼容的 API 格式,通过修改配置,可以使用 OpenAI SDK 来访问DeepSeek API,或使用与 OpenAI API 兼容的软件。
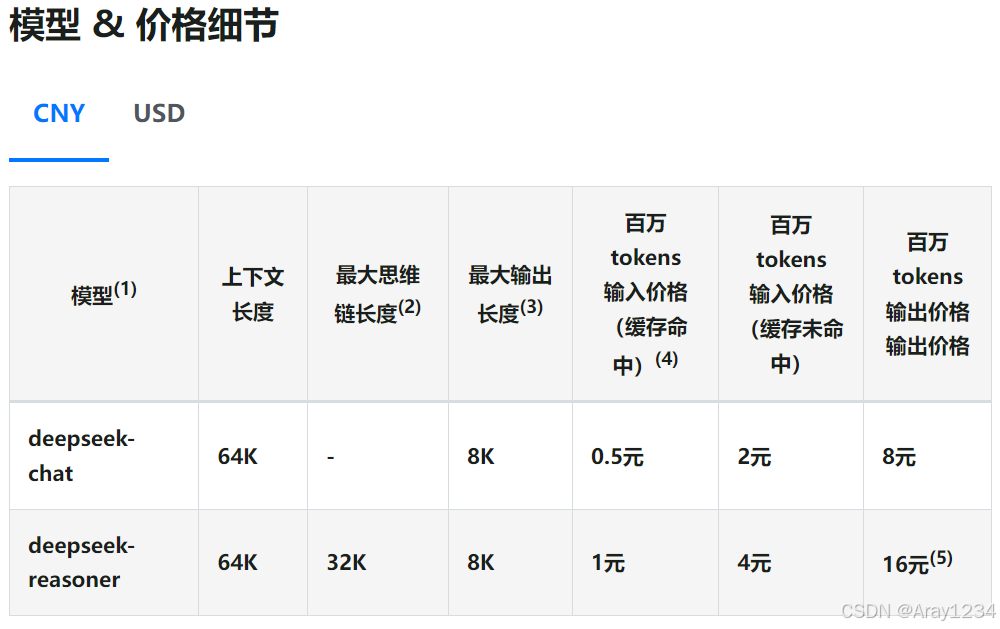
模型计费价格以“百万 tokens”为单位。token 是模型用来表示自然语言文本的基本单位,也是DeepSeek的计费单元,可以直观的理解为“字”或“词”;通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token。一般情况下模型中 token 和字数的换算比例大致如下:
1 个英文字符 ≈ 0.3 个 token。
1 个中文字符 ≈ 0.6 个 token。
截至2025年2月,价格如下:
在调用API前,需要先创建API Key, DeepSeek api_keys, 创建完成以后就可以使用DeepSeek 官方API了,示例如下,需要将 <DeepSeek API Key> 替换为你创建的API Key:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'
如果使用的是Python进行调用:
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>",
base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)
使用本地部署模型API
如果本地部署了DeepSeek模型,也可以直接调用本地模型的api,以使用Ollama部署DeepSeek为例,在Ollama下载了deepseek-r1模型以后,就可以使用Ollama的api进行模型的调用:
[root@localhost ~]# curl -X POST http://10.22.108.50:11434/v1/chat/completions \
-H "Content-Type: application/json" \ -d '{ "model": "deepseek-r1",
"messages": [{"role": "user", "content": "Hello, deepseek!"}] }
输出为:
{"id":"chatcmpl-
601","object":"chat.completion","created":1739615956,"model":"deepseekr1","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":
{"role":"assistant","content":"\u003cthink\u003e\n\n\u003c/think\u003e\n\nHello!
How can I assist you today? 😊"},"finish_reason":"stop"}],"usage":
{"prompt_tokens":8,"completion_tokens":16,"total_tokens":24}}
关于更多Ollama的api文档可以参考: ollama/docs/api.md
DeepSeek 集成应用
大模型的流行源于其对人类在生产、生活的辅助应用的良好前景。在本章我们简要介绍几种DeepSeek官方提到的模型的应用集成,GitHub - deepseek-ai/awesome-deepseek-integration,通过将DeepSeek与这些应用进行集成,可以实现更加先进的功能。仅是DeepSeek官方整理的“DeepSeek实用集成”名单,就有54款接入DeepSeek的应用,包括24个应用程序、3个AI Agent框架、1个RAG框架、1个Solana框架、3个即时通讯插件、8个浏览器插件、2个VS Code插件、3个neovim插件、2个JetBrains插件等。
以下为示例应用:
群组机器人
通过调用DeepSeek API,可以实现一个智能群组机器人,用户可以在群里随时@机器人,机器人进行领域知识回答。如"茴香豆"可以支持微信、飞书。通过在配置中添加申请的DeepSeek API Key, 实现智能机器人:
# config.ini
[llm]
enable_local = 0
enable_remote = 1
..
[llm.server]
..
remote_type = "deepseek"
remote_api_key = "YOUR-API-KEY"
remote_llm_max_text_length = 16000
remote_llm_model = "deepseek-chat"
python3 -m huixiangdou.main --standalone
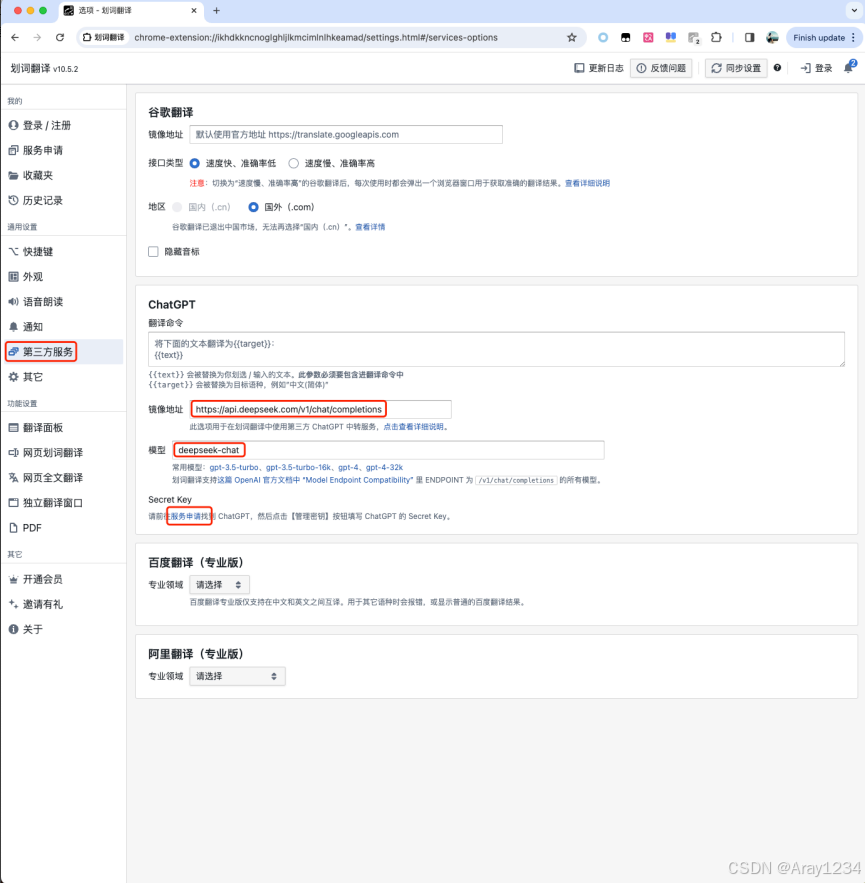
划词翻译
划词翻译 (hcfy.ai)
可以实现划词翻译,由于使用的是大模型的AI 翻译技术,相较于传统的翻译软件,更加的智能。
编程助手
通过集成AI,辅助开发人员进行代码编写和调优。如Continue
通过修改 config.json 与DeepSeek API 集成:
{
"completionOptions": {
"BaseCompletionOptions": {
"temperature": 0.0,
"maxTokens": 256
}
},
"models": [
{
"title": "DeepSeek",
"model": "deepseek-chat",
"contextLength": 128000,
"apiKey": "REDACTED",
"provider": "deepseek",
"apiBase": "https://api.deepseek.com/beta"
}
],
"tabAutocompleteModel": {
"title": "DeepSeek",
"model": "deepseek-chat",
"apiKey": "REDACTED",
"provider": "deepseek",
"apiBase": "https://api.deepseek.com/beta"
},
...
与其他AI平台集成
DeepSeek目前主要是用在推理阶段,所以我们可以使用DeepSeek生成较丰富的文本内容,然后将内容
复制到其他较为成熟的AI平台中进行生成。以下为示例应用:
-
生成PPT
可以先使用DeepSeek生成你想要的内容,然后复制到Kimi的PPT助手中,进行PPT一键生成。
Kimi.ai (moonshot.cn)
-
写歌
1、让deepseek创作歌词
2、suno ai制作歌曲:https://alpha.suno.ai
示例:-
输入提示词:
模仿周杰伦的风格写一首爱情歌曲,描述从初次相识,到热恋的喜悦到最后归于平淡的无奈,曲名要有深度,不要出现周杰伦代表作的名字 -
输出:
曲名:《时光的默片》 词:DeepSeek-V3 [Verse 1] 那天的风轻轻吹过街角 你微笑像阳光洒在我心跳 咖啡店的窗边,你低头翻着书页 我偷偷写下,属于我们的序言 [Pre-Chorus] 你说未来太远,像星星看不见 我却想带你走遍每个季节 从夏日的海边,到冬夜的雪 每一秒都想把你留在我的世界 [Chorus] 时光的默片,定格你的脸 从陌生到熟悉,爱像一场冒险 你是我唯一的焦点,无法忽略 可为何现在,只剩下沉默的语言 [Verse 2] 热恋的我们像烟火绚烂 每个夜晚都舍不得说晚安 你靠在我肩膀,数着星星许愿 我以为这就是永远,不会改变 [Pre-Chorus] 可时间像沙漏,悄悄流走温柔 我们开始习惯,不再牵手的理由 曾经的炙热,变成冰冷的借口 爱在平淡里,慢慢褪色成灰 [Chorus] 时光的默片,回放你的脸 从热烈到平淡,爱像一场幻觉 你是我唯一的执念,无法忘却 可为何现在,只剩下沉默的语言 [Bridge] 也许爱到最后,都是这样无奈 像风吹过的海,终究会归于平静 可我还记得,你曾说的那句“我在” 如今却成了,最遥远的对白 [Chorus] 时光的默片,模糊你的脸 从相遇到离别,爱像一场错觉 你是我唯一的遗憾,无法改写 可为何现在,只剩下沉默的语言 [Outro] 那天的风轻轻吹过街角 你微笑像阳光,却再也触不到 咖啡店的窗边,我独自翻着书页 原来爱到最后,只是时光的默片 -
然后将歌词输入到suno ai 进行歌曲一键生成:
生成效果:http://music.163.com/event?id=30301844482&uid=100233537
-
声明: 本文由CSDN@Aray1234 原创,转载请注明出处。