轨迹降噪API及算法
一、高德猎鹰
官方介绍:猎鹰是一套轨迹管理服务,提供移动端SDK和后端API供开发者接入。猎鹰可以满足您追踪车辆等定位设备,其提供的丰富接口和云端服务,可以让开发者基于猎鹰迅速构建一套完全属于自己的精准、高效的轨迹管理系统,应用于车队管理、人员管理等领域。

1.1、Web服务API
| 接口 | 链接 | 功能 | 核心字段 | 备注 |
|---|---|---|---|---|
| 服务service | 创建:https://tsapi.amap.com/v1/track/service/add | key下添加一个service | key、name | 一个key最多创建15个 service,每个service最多管理10万终端;同一key下name不可重复 |
| 终端terminal | 创建:https://tsapi.amap.com/v1/track/terminal/add | 添加一个terminal,代表现实中的一个人、车或其他 | key、sid、name | 同一service下name不可重复。一旦创建name 不可更新 |
| 轨迹trace | 创建:https://tsapi.amap.com/v1/track/trace/add | 添加一个trace | key、sid、tid | 一个终端下最多可创建500000条轨迹 |
| 轨迹trace | 单点或批量上传:https://tsapi.amap.com/v1/track/point/upload | 单点或批量上传轨迹点 | key、sid、tid、trid、points | 单次上传轨迹点总数不超过100个,否则需分批上传;轨迹点坐标、时间戳是必要字段 |
| 轨迹track | 查询与纠偏:https://tsapi.amap.com/v1/track/terminal/trsearch | 查询某条轨迹或特定时间段内的所有轨迹,可进行纠偏,解决轨迹缺失与漂移问题 | key、sid、tid 、(trid、start_time、end_time至少有一项) | 起止时间差最多24小时,建议缩短每次请求的时间区间 |
- 其他API包括terminal更新、删除等,详见链接:https://lbs.amap.com/api/track/lieying-rumen
- 表格中核心API的使用方式,详见【1.2、代码示例】
- 创建terminal、创建trace、上传trace、查询trace
1.2、代码示例
import json
import requests
import os
import pandas as pdclass LieYing:def __init__(self,key, sid=None, tid=None, trid=None, data=None, preprocess_params=None):self.key = keyself.sid = sidself.tid = tidself.trid = tridself.data = dataself.preprocess_params = preprocess_paramsself.result_data = Nonedef add_service(self):# 每个Key下最多注册15个Serviceurl = 'https://tsapi.amap.com/v1/track/service/add'# 默认name为service_1default_name = 'service_1'params = {'key': self.key, 'name': default_name}response = requests.post(url, data=params)if response.status_code == 200:response = response.json()if response['errcode'] == 10000:sid = response['data']['sid']self.result_data = {'service': {'sid': sid, 's_name': default_name}}else:print(response['errmsg'])else:print('创建服务失败')def add_terminal(self):url = 'https://tsapi.amap.com/v1/track/terminal/add'# 默认name为terminal_1default_name = 'terminal_1'params = {'key': self.key, 'sid': self.sid, 'name': default_name}response = requests.post(url, data=params)if response.status_code == 200:response = response.json()if response['errcode'] == 10000:tid = response['data']['tid']self.result_data = {'terminal':{'tid': tid, 't_name': default_name}}else:print(response['errmsg'])else:print('创建终端失败')def add_track(self):url = f'https://tsapi.amap.com/v1/track/trace/add'params = {'key': self.key, 'sid': self.sid, 'tid': self.tid}response = requests.post(url, data=params)if response.status_code == 200:response = response.json()if response['errcode'] == 10000:trid = response['data']['trid']self.result_data = {'trace': {'trid': trid}}if 'trname' in response['data']:trname = response['data']['trname']self.result_data['trace']['tr_name'] = trnameelse:print(response['errmsg'])else:print('添加轨迹失败')def upload_track(self):if 'timestamp' not in self.data or 'lng' not in self.data or 'lat' not in self.data:print('轨迹数据格式错误')return Noneinput_data = self.data.rename(columns={'timestamp': 'locatetime'})# 构造轨迹查询所需输入(坐标格式为X,Y,其中小数点后最多6位)input_data['location'] = input_data.apply(lambda row: ','.join([str(round(row.lng, 6)), str(round(row.lat, 6))]), axis=1)# 假设direction、speed同时存在或不存在(可单独判断)if 'direction' in input_data and 'speed' in input_data:points = input_data[['location', 'locatetime', 'direction', 'speed']].to_dict(orient='records')else:points = input_data[['location', 'locatetime']].to_dict(orient='records')url = f'https://tsapi.amap.com/v1/track/point/upload'params = {'key': self.key, 'sid': self.sid, 'tid': self.tid, 'trid': self.trid}num = len(points)if num > 5000:print('超出个人用户每日限额')self.result_data = {'upload': {'total': num, 'upload_status': 'all', 'upload_num': num}}# 每次最多100个轨迹点,分批上传# 若有相同的unix时间戳则会覆盖旧的点i = 0while i < num:if num - i < 100:# 结束循环batch_data = points[i:]i = numelse:batch_data = points[i:i + 100]i += 100# 使用json.dumps()将轨迹点转换为json字符串params["points"] = json.dumps(batch_data)response = requests.post(url, data=params)if response.status_code == 200:response = response.json()if response['errcode'] != 10000:print('轨迹上传失败')print(response['errmsg'])self.result_data['upload']['upload_status'] = 'part'self.result_data['upload']['upload_num'] = num - len(batch_data)def search_track(self):url = 'https://tsapi.amap.com/v1/track/terminal/trsearch'params = {'key':self.key, 'sid': self.sid, 'tid': self.tid, 'trid': self.trid}params.update(self.preprocess_params)# 设置轨迹处理相关的参数# trid与starttime与endtime必填一项if self.trid is None and ('starttime' not in params or 'endtime' not in params):print('trid、starttime、endtime必填一项')return Noneresponse = requests.get(url,params=params)if response.status_code == 200:response = response.json()if response['errcode'] == 10000:points = []tracks = response['data']['tracks']for track in tracks:points.extend(track['points'])self.result_data = {'search': {'points': points}}# 后续可解析为dataframe:location、locatetime、speed、direction、accuracyreturn self.result_dataelse:print(response['errmsg'])def process(self):if self.sid is None:# 创建新的服务self.add_service()return self.result_dataif self.tid is None:# 创建新的终端self.add_terminal()return self.result_dataif self.trid is None:# 创建新的轨迹self.add_track()return self.result_dataif self.data is not None:# 上传轨迹(轨迹数据)self.upload_track()return self.result_data# 查询轨迹(包含预处理)self.search_track()return self.result_dataif __name__ == '__main__':path = r'data/raw_data'# 【孤立噪点】# file = '孤立噪点.json'# 【多个噪点分布集中】file = '多个噪点分布集中_1.json'# file = '多个噪点分布集中_2.json'# 【多个噪点反复横跳】# file = '多个噪点反复横跳.json'# 读取异常段轨迹信息,用于上传with open(os.path.join(path, file), 'r', encoding='utf-8') as f:data = json.load(f)data = pd.DataFrame(data['points'])# 高德猎鹰轨迹服务# 添加service# lie_ying = LieYing(key='0ea6bcXXXXXXXXXXXXXb67f575c26')# 添加terminal# lie_ying = LieYing(key='0ea6bcXXXXXXXXXXXXXb67f575c26',# sid=1049770)# 添加trace# lie_ying = LieYing(key='0ea6bcXXXXXXXXXXXXXb67f575c26',# sid=1049770,# tid=1322647895)# 上传轨迹(批量上传)# lie_ying = LieYing(key='0ea6bcXXXXXXXXXXXXXb67f575c26',# sid=1049770,# tid=1322647895,# trid=60,# data=data)# 轨迹预处理:降噪、纠偏...# 轨迹降噪/纠偏相关参数为correction;轨迹补全相关参数为recoup# 【注意】:起止时间差最多24小时preprocess_params = {'starttime': 1732239284000,'endtime': 1732239674000,'correction': 'denoise=1, mapmatch=1','recoup': 0}lie_ying = LieYing(key='0ea6bcXXXXXXXXXXXXXb67f575c26',sid=1049770,tid=1322647895,trid=60,preprocess_params=preprocess_params)result_data = lie_ying.process()print(result_data)print('finished')
二、百度鹰眼
官方介绍:鹰眼是一套轨迹管理服务,提供各端SDK和API供开发者便捷接入,追踪您所管理的车辆/人员等运动物体。基于鹰眼提供的接口和云端服务,开发者可以迅速构建一套完全属于您自己的完整、精准且高性能的轨迹管理系统,可应用于车队管理、人员管理等领域。

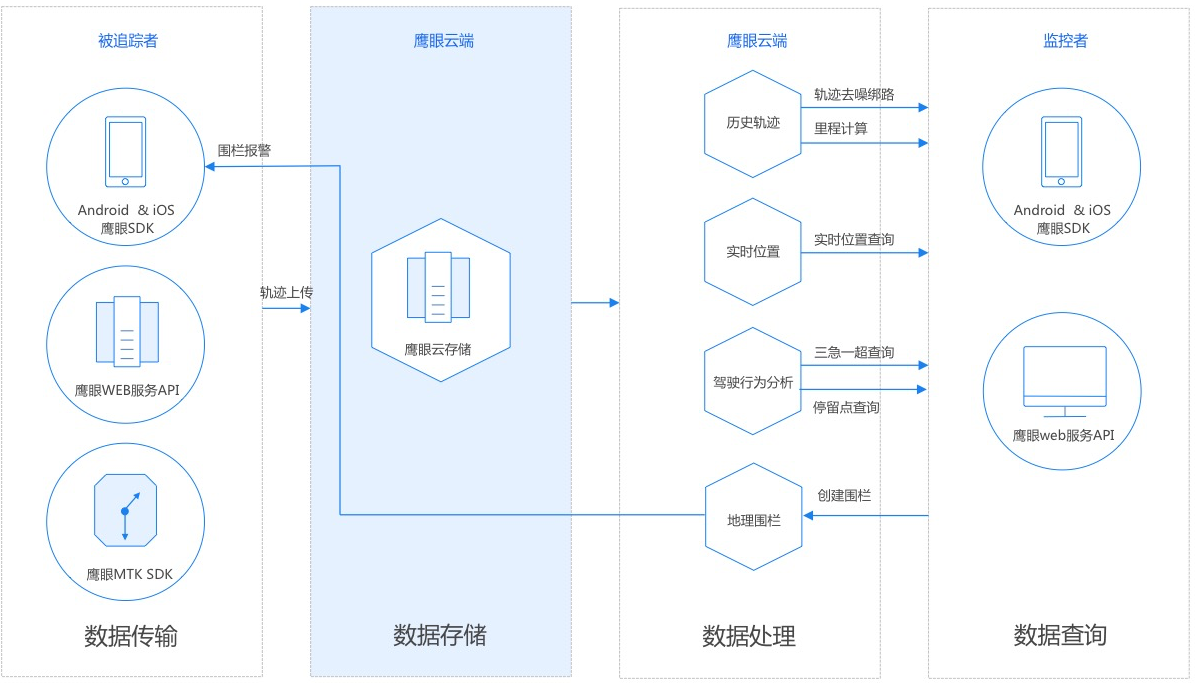
2.1、Web服务API
| 接口 | 链接 | 功能 | 核心字段 | 备注 |
|---|---|---|---|---|
| 服务service | 管理台:https://lbsyun.baidu.com/trace/admin/service | 存储、访问、管理终端和轨迹 | ak、service_id | 一个开发者最多可创建10个 service,每个service最多可管理100万终端 |
| 终端entity | 创建:https://yingyan.baidu.com/api/v3/entity/add | 添加一个entity,代表现实中的一个人、车或其他 | ak、service_id、entity_name | 同一service服务中entity_name不可重复。一旦创建entity_name 不可更新 |
| 轨迹track | 批量上传:https://yingyan.baidu.com/api/v3/track/addpoints | 上传一个 entity 的多个轨迹点,或多个entity的多个轨迹点 | ak、service_id、point_list | 单次上传轨迹点总数不超过100个,否则需分批上传;若entity不存在,则自动创建;轨迹点坐标、时间戳、坐标系类型是必要字段 |
| 轨迹track | 查询与纠偏:https://yingyan.baidu.com/api/v3/track/gettrack | 查询一段时间的轨迹并进行纠偏,解决轨迹缺失与漂移问题 | ak、service_id、entity_name 、start_time、end_time | 起止时间差最多24小时,建议缩短每次请求的时间区间 |
- 其他API包括entity更新、删除等,详见链接:https://lbsyun.baidu.com/faq/api?title=yingyan/api/v3/all
- 表格中核心API的使用方式,详见【2.2、代码示例】
- 创建entity、上传track、查询track
2.2、代码示例
import json
import requests
import urllib
import os
import pandas as pdclass YingYan:def __init__(self,ak, service_id=None, entity_name=None, data=None, preprocess_params=None):self.ak = akself.service_id = service_idself.entity_name = entity_nameself.data = dataself.preprocess_params = preprocess_paramsself.result_data = Nonedef add_entity(self):url = 'https://yingyan.baidu.com/api/v3/entity/add'# 默认name为entity_1if self.entity_name is None:self.entity_name = 'entity_1'params = {'ak':self.ak, 'service_id':self.service_id, 'entity_name':self.entity_name}response = requests.post(url, data=params)if response.status_code == 200:response = response.json()if response['status'] == 0:self.result_data = {'entity':{'e_name': self.entity_name}}else:print(response['message'])else:print('创建终端失败')def upload_track(self):# 构造轨迹查询所需输入self.data['coord_type_input'] = 'gcj02'self.data['entity_name'] = self.entity_name# 时间戳精确到秒self.data.rename(columns={'timestamp': 'loc_time', 'lng': 'longitude', 'lat': 'latitude'}, inplace=True)self.data['loc_time'] = self.data['loc_time'] // 1000self.points = self.data[['longitude', 'latitude', 'loc_time', 'direction', 'speed','entity_name','coord_type_input']].to_dict(orient='records')url = 'https://yingyan.baidu.com/api/v3/track/addpoints'# 表单形式提交headers = {'Content-Type': 'application/x-www-form-urlencoded'}params = {'ak':self.ak, 'service_id':self.service_id}num = len(self.points)if num > 5000:print('超出个人用户每日限额')self.result_data = {'upload': {'total': num, 'upload_status': 'all', 'upload_num': num}}# 每次最多100个轨迹点,分批上传# 若有相同的unix时间戳则会覆盖旧的点i = 0while i < num:if num - i < 100:# 结束循环batch_data = self.points[i:]i = numelse:batch_data = self.points[i:i + 100]i += 100# 使用json.dumps()将轨迹点转换为json字符串params['point_list'] = json.dumps(batch_data)payload = urllib.parse.urlencode(params)response = requests.post(url, headers=headers, data=payload)if response.status_code == 200:response = response.json()if response['status'] != 0:print('轨迹上传失败')print(response['message'])self.result_data['upload']['upload_status'] = 'part'self.result_data['upload']['upload_num'] = num - len(batch_data)def search_track(self):url = 'https://yingyan.baidu.com/api/v3/track/gettrack'params = {'ak':self.ak, 'service_id': self.service_id, 'entity_name': self.entity_name}params.update(self.preprocess_params)# 设置轨迹处理相关的参数# trid与starttime与endtime必填一项if 'start_time' not in params or 'end_time' not in params:print('starttime、endtime必填')return Noneresponse = requests.get(url,params=params)if response.status_code == 200:response = response.json()if response['status'] == 0:self.result_data = {'search': {'points': response['points']}}# 后续可解析为dataframe:longitude、latitude、loc_time、speed、direction、radiusreturn self.result_dataelse:print(response['message'])def process(self):if self.service_id is None:# 创建新的服务print('请先到鹰眼轨迹管理台创建service')print('https://lbsyun.baidu.com/trace/admin/service')return self.result_dataif self.entity_name is None:# 创建新的终端self.add_entity()return self.result_dataif self.data is not None:# 上传轨迹(轨迹数据)self.upload_track()return self.result_data# 查询轨迹(包含预处理)self.search_track()return self.result_dataif __name__ == '__main__':path = r'data/raw_data'# 【孤立噪点】# file = '孤立噪点.json'# 【多个噪点分布集中】file = '多个噪点分布集中_1.json'# file = '多个噪点分布集中_2.json'# 【多个噪点反复横跳】# file = '多个噪点反复横跳.json'# 读取异常段轨迹信息,用于上传with open(os.path.join(path, file), 'r', encoding='utf-8') as f:data = json.load(f)data = pd.DataFrame(data['points'])# 百度鹰眼轨迹服务# 添加entity# ying_yan = YingYan(ak='6Y13XXXXXXXXXXXXnAYh1uGHW',# service_id=241060)# 上传轨迹(批量上传)# ying_yan = YingYan(ak='6Y13XXXXXXXXXXXXnAYh1uGHW',# service_id=241060,# entity_name='entity_1',# data=sub_data)# 轨迹预处理:降噪、纠偏...# 轨迹降噪/纠偏相关参数为is_processed、process_option;轨迹补全相关参数为supplement_mode# 【注意】:起止时间差最多24小时preprocess_params = {'start_time': 1732239284,'end_time': 1732239674,'is_processed': 1,'process_option': 'denoise_grade=1, mapmatch=1','supplement_mode': 'no_supplement'}ying_yan = YingYan(ak='6Y13XXXXXXXXXXXXnAYh1uGHW',service_id=241060,entity_name='entity_1',preprocess_params=preprocess_params)result_data = ying_yan.process()print(result_data)print('finished')
2.3、鹰眼轨迹管理台
百度地图提供了【鹰眼轨迹管理台】
- 进入服务,选择某个终端的某条轨迹,点击“轨迹”即可进行可视化及预处理
- 核心功能:轨迹预处理(降噪、抽稀、补全、纠偏)、驾驶行为分析、轨迹回放
- 下图为某段具有“孤立噪点”的轨迹的降噪效果:能够识别噪点
- 说明:经测试,调整参数始终无法正确识别轨迹中“反复横跳的噪点”
- 详见“示例轨迹”中“多个噪点反复横跳”的轨迹文件】


- 详见“示例轨迹”中“多个噪点反复横跳”的轨迹文件】
三、基于距离的降噪算法
3.1、核心逻辑
噪点:与上下游正常轨迹点存在明显偏移的点,一般可通过间距、时间间隔、速度指标进行识别(设置阈值)
- 高德、百度地图轨迹查询API能够降噪,但对于【反复横跳】的噪点处理能力有限;
- 噪点处的时间戳相比于上下游轨迹点可能无突变(点之间的行程速度也不可用),因此只根据距离识别噪点
【Step1 噪点初筛】:若相邻轨迹点的间距大于等于【距离阈值】,则认为是噪点(进一步判断)
- 对于相邻的轨迹点A、B,若 d A B ≥ D i s t a n c e L i m i t d_{AB}\ge DistanceLimit dAB≥DistanceLimit,则称AB为一个噪点路段,进行二次判断
- 使用
Haversine公式计算距离: d = 2 r × arcsin ( sin 2 ( Δ ϕ 2 ) + cos ϕ 1 cos ϕ 2 sin 2 ( Δ λ 2 ) ) d = 2r \times \arcsin \left( \sqrt{ \sin^2 \left(\frac{\Delta \phi}{2}\right) + \cos \phi_1 \cos \phi_2 \sin^2 \left(\frac{\Delta \lambda}{2}\right)} \right) d=2r×arcsin(sin2(2Δϕ)+cosϕ1cosϕ2sin2(2Δλ))
【Step2 噪点二次判断】:对于相邻的噪点路段,计算“轴向间距”,若两个噪点路段的长度均大于等于“轴向间距”与【倍数阈值】的乘积,则认为是噪点
- 对于相邻的噪点路段
[[A, B], [D, E]], d A B ≥ T i m e s L i m i t × d A E 且 d D E ≥ T i m e s L i m i t × d A E d_{AB}\ge TimesLimit \times d_{AE} 且d_{DE}\ge TimesLimit \times d_{AE} dAB≥TimesLimit×dAE且dDE≥TimesLimit×dAE,则称AE之间的点为噪点 - 下图为噪点初筛、噪点二次判断的示例


【基本假设】初筛 + 二次判断适用于噪点分布较为集中(包括孤立噪点)的情况,允许反复横跳
- 【优点】
- 只使用距离识别噪点,适用性广;
- 通过设置【距离阈值】及【倍数阈值】可以调整降噪强度(阈值越小降噪强度越大)
- 二次判断能够避免将隧道附近的缺失以及轨迹采集设备造成的长距离缺失当作噪点

- 【不足】无法识别离散分布的噪点(此类噪点较少见,算法暂不处理此类情况)

3.2、输入及输出
3.2.1、输入及示例
| 参数名 | 类型 | 是否必填 | 含义 | 说明 | 默认值 |
|---|---|---|---|---|---|
| data | dataframe | 是 | 轨迹数据 | dataframe格式的轨迹数据,一定要有经度lng、纬度lat字段,其余非必要 | 无 |
| denoising_level | str | 否 | 结果坐标系 | 轨迹降噪力度,降噪力度越大,判断异常点的阈值越小(更容易触发) | low |
| save_path | str | 否 | 保存路径 | 默认保存在data/result_data文件夹下 | “” |
| save_name | str | 否 | 保存名称 | 可以指定文件名,需要符合命名规范,保存为json格式的文件 | denoising_points |
{"data": data,"denoising_level":"low""save_path": "data/result_data","save_name": "test_01",
}
【入参说明】
- 若未给定
save_path,则不保存轨迹文件 - 若轨迹数据为json格式,可先解析创建dataframe对象再调用降噪算法
- 可以根据降噪后的轨迹效果选择合适的denoising_level
3.2.2、输出及示例
| 参数名 | 类型 | 是否必填 | 含义 | 说明 | 默认值 |
|---|---|---|---|---|---|
| noise_num | int | 是 | 起点坐标 | 0 | |
| noise_points | list | 是 | 轨迹数据 | 识别到的噪点信息 | None |
| points | list | 是 | 轨迹数据 | 降噪后的轨迹点信息 | 与输入data相同的轨迹点信息 |
{"noise_num": 1,"noise_points": [{"lng": 104.21018, "lat":30.525391, "timestamp": 1728762988000, "speed": 15.3, "direction": 135}],"points": [{"lng": 104.21018, "lat":30.525391, "timestamp": 1728762988000, "speed": 15.3, "direction": 135},{"lng": 104.210473, "lat":30.525124, "timestamp": 1728763000000, "speed": 2.0, "direction": 141},{"lng": 104.210488, "lat":30.525114, "timestamp": 1728763012000, "speed":0.0, "direction": 120},...]
}
3.3、代码示例
import os
import json
import math
import numpy as np
import pandas as pddef cal_haversine_dis(cur_point, next_point):"""采用haversine公式,根据坐标计算距离:param cur_point: 点的坐标:param next_point: 另一个点的坐标:return: 距离(单位:m)"""AVG_EARTH_RADIUS = 6371.0088 # in kilometerslng1, lat1 = cur_pointlng2, lat2 = next_point# 转换为弧度lng1_rad, lat1_rad, lng2_rad, lat2_rad = map(math.radians, [lng1, lat1, lng2, lat2])d_lng = lng2_rad - lng1_radd_lat = lat2_rad - lat1_radd = math.sin(d_lat * 0.5) ** 2 + math.cos(lat1_rad) * math.cos(lat2_rad) * math.sin(d_lng * 0.5) ** 2d = 2 * AVG_EARTH_RADIUS * math.asin(math.sqrt(d)) # in kilometersreturn d * 1000def cal_haversine_dis_vector(df):"""向量化计算相邻点之间的球面距离(单位:m),返回距离数组:param df: 轨迹数据,要求有lng、lat列(用于计算距离):return: 距离数组"""AVG_EARTH_RADIUS = 6371.0088 # in kilometers# 确保数据按位置顺序处理(忽略原始索引)lon = np.radians(df['lng'].values)lat = np.radians(df['lat'].values)# 直接使用数组切片计算相邻差值(避免索引对齐问题)dlon = lon[1:] - lon[:-1]dlat = lat[1:] - lat[:-1]# Haversine 公式a = np.sin(dlat / 2) ** 2 + np.cos(lat[:-1]) * np.cos(lat[1:]) * np.sin(dlon / 2) ** 2c = 2 * np.arcsin(np.sqrt(a))# 计算距离distance = AVG_EARTH_RADIUS * creturn distance * 1000class Denoising(object):def __init__(self, data, save_path="", denoising_level="low"):self.data = dataself.save_path = save_pathself.pd_data = data.copy(deep=True)self.denoising_level = denoising_level# denoising_level越大,表示降噪力度越大,判断异常点的阈值越小(更容易触发)self.denoising_limit_info = {"low": {"distance_limit": 10000, "time_limit": 3},"mid": {"distance_limit": 8000, "time_limit": 2},"high": {"distance_limit": 5000, "time_limit": 1},}self.result_data = {"noise_num": 0,"noise_points": None,"points": self.data.to_dict(orient='records')}self.coordinates = self.data[['lng', 'lat']].valuesdef __denoising_core(self):# 轨迹降噪distance_limit = self.denoising_limit_info[self.denoising_level]["distance_limit"]time_limit = self.denoising_limit_info[self.denoising_level]["time_limit"]# 向量化计算距离distance_list = cal_haversine_dis_vector(self.pd_data)# 根据距离阈值确定噪点(初筛):记录轨迹点索引、距离detected_noise_segments = np.where(distance_list >= distance_limit)[0]segment_dis_list = distance_list[detected_noise_segments]# 调整为轨迹点对:列表表达式;广播机制 + 按列堆叠detected_noise_segments = np.column_stack((detected_noise_segments, detected_noise_segments + 1))# 根据相邻的noise_segment,判断要剔除的噪点# 记录要剔除的轨迹点noise_list = []for i in range(len(detected_noise_segments) - 1):left_index = detected_noise_segments[i][0]right_index = detected_noise_segments[i + 1][1]cur_point = self.coordinates[left_index]next_point = self.coordinates[right_index]dis = cal_haversine_dis(cur_point, next_point)if (segment_dis_list[i] >= time_limit * disand segment_dis_list[i + 1] >= time_limit * dis):noise_list.extend(list(range(left_index + 1, right_index)))if len(noise_list) == 0:print("未识别到噪点")returnelse:print(f"识别到{len(noise_list)}个噪点,信息如下:")self.result_data["noise_num"] = len(noise_list)self.result_data["noise_points"] = self.pd_data.iloc[noise_list].to_dict(orient='records')for i in sorted(noise_list):print(i, "\t", self.coordinates[i], "\t")# 确定降噪后的轨迹点、坐标remained_points = sorted(set(range(len(self.coordinates))) - set(noise_list))self.coordinates = self.coordinates[remained_points]self.pd_data = self.pd_data.iloc[remained_points]self.pd_data.reset_index(drop=True, inplace=True)self.result_data = {"points": self.pd_data.to_dict(orient='records')}if self.save_path != "":with open(os.path.join(self.save_path, 'denoising_points.json'), 'w', encoding='utf-8') as f:json.dump(self.result_data, f, ensure_ascii=False, indent=4)def process(self):self.__denoising_core()return self.result_dataif __name__ == '__main__':path = r'data/raw_data'save_path = r'data/result_data'# 【孤立噪点】file = '孤立噪点.json'# 【多个噪点集中分布】# file = '多个噪点集中分布_1.json'# file = '多个噪点集中分布_2.json'# 【多个噪点反复横跳】# file = '多个噪点反复横跳.json'# 读取异常段轨迹信息,用于上传with open(os.path.join(path, file), 'r', encoding='utf-8') as f:data = json.load(f)data = pd.DataFrame(data['points'])denoising = Denoising(data, save_path)denoising.process()print("finished")
四、示例轨迹
示例轨迹以json格式保存,轨迹点核心字段为:经度lng、纬度lat、时间戳timestamp、速度speed、航向角direction,可转换为DataFrame格式然后调用高德或百度的API进行轨迹上传、处理
完整轨迹文件:孤立噪点、多个噪点分布集中、多个噪点反复横跳
{"points": [{"lat": 36.14096584254603,"lng": 120.20169651959084,"timestamp": 1732239164000,"speed": 81.3,"direction": 59},{"lat": 36.143973510867134,"lng": 120.2080220097293,"timestamp": 1732239194000,"speed": 76.8,"direction": 59},{"lat": 36.14695313674736,"lng": 120.21430375913472,"timestamp": 1732239224000,"speed": 78.7,"direction": 59}]
}