【C++】哈希表的实现(链地址法)

【C++】哈希表的实现(开放定址法)中我们介绍了一个哈希函数:除法散列法(除留余数法),还有一个处理哈希冲突的方法:开放定址法中的线性探测。
本篇继续讲解一些别的哈希函数和处理哈希函数的方法,以及如何用链地址法实现这个哈希表。
1.其他哈希函数
1.1 乘法散列法(了解)
- 第⼀步:⽤关键字 K 乘上常数 A (0<A<1),并抽取出 k*A 的⼩数部分
- 第⼆步:⽤M乘以k*A 的⼩数部分,再向下取整。
其实就是让M去乘一个[0, 1)之间的小数,这个小数要与K相关,K不同,这个小数就不同,就能映射的更分散。
经过大佬Knuth的分析,建议这个A取黄金分割点:
所以乘法散列法的公式为:h(key) = floor(M * (A * key) % 1.0)),其中floor表⽰对表达式进⾏向下取整,A∈(0,1)。
举个例子:乘法散列法对哈希表⼤⼩M是没有要求的,假设M为1024,key为1234,A = 0.6180339887, A*key = 762.6539420558,取⼩数部分为0.6539420558, M×((A×key)%1.0) = 0.6539420558*1024 = 669.6366651392,那么h(1234) = 669。
1.2 全域散列法(了解)
这个函数主要是为了抵御恶意攻击的。如果存在⼀个恶意的对⼿,他针对我们提供的散列函数,特意构造出⼀个发⽣严重冲突的数据集, ⽐如,让所有关键字全部落⼊同⼀个位置中。这种情况是可以存在的,只要散列函数是公开且确定的,就可以实现此攻击。
全域散列法的公式为: h(key) = ((a * key + b) % P) % M ,P需要选一个足够大的质数,a可以随机选[1, P-1]之间的任意整数,b可以随机选[0, P-1]之间的任意整数。
2.处理哈希冲突的方法
2.1 开放定址法
- 性探测的⽐较简单且容易实现,线性探测的问题假设,hash0位置连续冲突,hash0,hash1,hash2位置已经存储数据了,后续映射到hash0,hash1,hash2,hash3的值都会争夺hash3位置,这种现象叫做群集/堆积。
二次探测:
- 从发⽣冲突的位置开始,依次左右按加减⼆次⽅跳跃式探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果往右⾛到哈希表尾,则回绕到哈希表头的位置;如果往左⾛到哈希表头,则回绕到哈希表尾的位置。
- h(key) = hash0 = key % M, hash0的位置冲突了,则二次探测的公式为 hc(key, i) = hashi = (hash0
) % M, i = { 1, 2, 3, ... ,
}。
- 二次探测hashi = (hash0 -
把 {19,30,52,63,11,22} 等这⼀组值映射到M=11的表中。
h(19) = 8, h(30) = 8, h(52) = 8, h(63) = 8, h(11) = 0, h(22) = 0

代码就不实现了。
双重探测(了解):
线性探测是挨着找空位,二次探测是有规律的跳跃着找空位,双重探测就是再弄一个哈希函数,无规律的跳跃着找空位,减少堆积。
2.2 链地址法
前面的开放定址法不管是哪种探测,还是会出现相互挤占位置的情况,不能完全解决这个问题。更好的解决方法其实是链地址法。
链地址法中所有的数据不再直接存储在哈希表中,哈希表中存储⼀个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把这些冲突的数据 链接成⼀个链表 ,挂在哈希表这个位置下⾯,链地址法也叫做 拉链法或者哈希桶 。
h(19) = 8 , h(30) = 8 , h(5) = 5 , h(36) = 3 , h(13) = 2 , h(20) = 9 , h(21) = 10, h(12) = 1, h(24) = 2, h(96) = 8

- 负载因⼦越⼤,哈希冲突的概率越⾼,空间利⽤率越⾼;
- 负载因⼦越⼩,哈希冲突的概率越低,空间利⽤率越低;
- stl中unordered_xxx的最⼤负载因⼦基本控制在1,⼤于1就扩容。
2.2.1 insert代码实现
先把哈希桶的结构搞出来。
namespace hash_bucket // 链地址法/哈希桶
{template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next; //存放下一个节点的地址HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}};template<class K, class V>class HashTable{typedef HashNode<K, V> Node;public:HashTable():_table(11),_n(0){}private:vector<Node*> _table; // vector里面存HashNodesize_t _n;};
}这里选择vector里面其实也可以存list,但这里选择存自定义类型HashNode。
bool Insert(const pair<K, V>& kv)
{size_t hashi = kv.first % _table.size(); //映射位置Node* newnode = new Node(kv);}创建好结点之后,这里可以选择头插,也可以选择尾插,都是一样的 ,我在里就写头插的实现。
比如现在要插入这个96,96映射的位置是8。
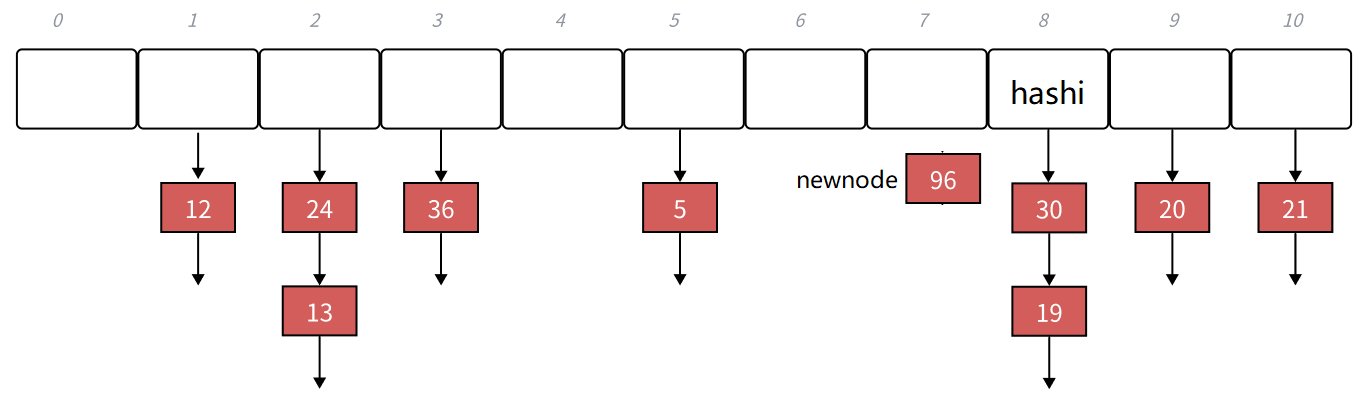
要让newnode的next链接到30,newnode成为新的头,而hashi在这个位置里面存的就是值为30的节点的地址,所以让newnode的next指向hashi里面存的地址就行,然后更新hashi。

插入数据之后要更新_n。
bool Insert(const pair<K, V>& kv)
{size_t hashi = kv.first % _table.size(); //映射位置Node* newnode = new Node(kv);//头插newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;
}我们要把负载因⼦基本控制在1,⼤于1就扩容。
在开放地址法的实现中,我们用了巧妙的写法针对扩容后旧数据的处理,就是insert里面复用insert,但是那种写法在这里并不推荐使用。
首先是因为我们vector里面挂的是HashNode,局部对象出作用域就销毁,但HashNode不特殊处理不会自己释放(如果vector里面存的是list就可以 ),
第二点就是,已经存在的节点,我们可以直接拿过来用,如果是开放定址法那样的写法,这些节点会被拷贝一份,连接到新表上,我们还要自己手动释放旧表的那些节点,还不如把原来的节点直接拿过来用。
实现如下。
bool Insert(const pair<K, V>& kv)
{if (_n == _table.size()) //扩容{vector<Node*> newtable(2 * _table.size());//创建新表for (int i = 0; i < _table.size(); i++) //遍历旧表{Node* cur = _table[i];while (cur) //遍历当前位置挂的所有节点{Node* next = cur->_next; //记录cur的下一个节点size_t hash0 = cur->_kv.first % newtable.size(); //计算在新表的位置//直接把节点头插到新表cur->_next = newtable[hash0];newtable[hash0] = cur;cur = next; //遍历这条链上的下一个节点}_table[i] = nullptr;}_table.swap(newtable);//旧表新表互换}size_t hashi = kv.first % _table.size(); //映射位置Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;
}先拿下面这组测试样例测试一下。
int main()
{int arr[] = { 19,30,5,36,13,20,21,12,24,96,4,17 };hash_bucket::HashTable<int, int> h;for (auto i : arr){h.Insert({ i, i });}return 0;
}如果通过,就可以在扩容部分换成用素数表。
素数表代码在 【C++】哈希表的实现(开放定址法)

2.2.2 find代码实现
find实现逻辑就是 先计算出要找的这个值映射的位置,然后遍历挂着的链表就行。
Node* Find(const K& key)
{size_t hashi = key % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur; //找到了}cur = cur->_next;}return nullptr; //没找到
}测试一下。
int arr[] = { 19,30,5,36,13,20,21,12,24,96,4,17 };
hash_bucket::HashTable<int, int> h;
for (auto i : arr)
{h.Insert({ i, i });
}if (h.Find(1))cout << "找到了" << endl;
elsecout << "没找到" << endl;if (h.Find(19))cout << "找到了" << endl;
elsecout << "没找到" << endl;return 0;
我们可以在insert里面添加一下find,把insert实现成不允许冗余的。
if (Find(kv.first))return false;
2.2.3 erase的代码实现
节点的删除要分情况讨论:删除节点为头节点;删除节点为中间节点或尾节点。
删除头节点,比如把这个96删了,96记为cur。
 直接让下标为8的这个位置存储cur的下一个节点的地址就行了。
直接让下标为8的这个位置存储cur的下一个节点的地址就行了。
如果删除中间节点,比如删除30,30记为cur。

我们要让96和19链接上,就是让cur的前一个指向cur的后一个,所以我们需要把cur的前一个记录下来。

bool Erase(const K& key)
{size_t hashi = key % _table.size();Node* cur = _table[hashi];while (cur){Node* prev = nullptr;if (cur->_kv.first == key) //找到了{if (prev == nullptr) //删除节点为头节点{_table[hashi] = cur->_next;}else //删除节点为中间节点或尾节点{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;cur = cur->_next;}}return false; //删除失败
}测试一下。
int arr[] = { 19,30,5,36,13,20,21,12,24,96,4,17 };
hash_bucket::HashTable<int, int> h;
for (auto i : arr)
{h.Insert({ i, i });
}if (h.Find(19))cout << "找到了" << endl;
elsecout << "没找到" << endl;h.Erase(19); //删除19if (h.Find(19))cout << "找到了" << endl;
elsecout << "没找到" << endl;
2.2.4 析构
这里涉及自定义类型的释放,可以自己手动写一个析构函数。
~HashTable()
{for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}
}拷贝构造这些也可以实现一下,这里就不写了。
2.2.5 K不能取模问题
这里也是和开放地址法一样的,要多加一个模板参数。
template<class K>
struct HashFunc
{bool operator()(const K& key){return (size_t)key;}
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{//...
}string类型经常用到,把string特化。
template<>
struct HashFunc<string>
{bool operator()(const string& s){size_t hashi = 0;for(auto ch : s){ hashi += ch;hashi *= 131;}return hashi;}
};然后其他需要改动的地方也要一起改。
Insert:


Find:

Erase:

测试一下。
int main()
{const char* arr[] = { "hello", "left", "sort", "passage" };hash_bucket::HashTable<string, string> s;for (auto& e : arr){s.Insert({ e, e });}return 0;
}如果没有错误就可以了,这个哈希桶就实现的差不多了。
本篇就分享到这里,我们下篇见~
