Spark基于Bloom Filter算法的Runtime Filter Join优化机制
Apache Spark 3.3.0 引入了一个显著的特性——行级运行时过滤(Row-Level Runtime Filtering),该特性旨在提高查询性能,优化数据处理效率。在这一特性中,一种重要的实现方式是布隆过滤器(Bloom Filter)。
布隆过滤器是一种空间效率极高的数据结构,能够快速判断一个元素是否在一个集合中。通过利用布隆过滤器,Spark 可以在执行连接操作时,动态地过滤掉不必要的数据行,从而减少数据传输和计算的开销。具体来说,布隆过滤器可以在子查询或大表连接的过程中,快速排除掉那些不符合条件的数据行,从而提升查询的响应速度和整体性能。
1.原理阐述
1.1 什么是Bloom Filter?


布隆过滤器是一种空间高效的概率数据结构,用于测试某个元素是否属于一个集合。它能确定元素不在集合中,但可能会报告假阳性。
1.2 Bloom Filter 的主要特点
-
空间效率:相较于传统索引,布隆过滤器占用的空间显著更少。
-
快速性:插入和查找操作的时间复杂度为常数时间。
-
概率性:可能产生假阳性(即报告元素在集合中,但实际上不在),但绝不会产生假阴性(即报告元素不在集合中,但实际上在)。
1.3 Bloom Filter 的工作原理
-
初始化:创建一个长度为 m 的位数组,所有位初始设置为 0。
-
哈希函数:使用 k 个不同的哈希函数。
-
插入元素:
-
对于每个要插入的元素,计算其 k 个哈希值,并将对应的位设置为 1。
-
-
查找元素:
-
检查元素是否存在时,计算其 k 个哈希值。如果所有对应的位均为 1,则该元素可能在集合中;否则,元素一定不在集合中。
-
1.4 Spark 中的 Bloom Filter创建与应用原理
Bloom Filter 创建作为聚合函数
假设有两个表 R 和 S,连接键分别是 r_sk 和 s_sk,并且有一个选择性过滤条件 S.x = 5。
Q1: SELECT * FROM R JOIN S ON R.r_sk = S.s_sk WHERE S.x = 5
为了在较小的输入表 S 上创建布隆过滤器,我们引入以下聚合查询:
SELECT BloomFilterAggregate(XxHash64(S.s_sk), n_items, n_bits)FROM S WHERE S.x = 5BloomFilterAggregate 函数签名:输入:hash_value (long 类型):连接键的哈希值。n_items (long 类型):预期的项数。n_bits:位数。返回:binary 类型值,即布隆过滤器。
Bloom Filter 应用作为标量子查询过滤器
有了布隆过滤器聚合函数,可以概念上将查询 Q1 重写为 Q2:
Q2: SELECT *FROM R JOIN S ON R.r_sk = S.s_skWHERE S.x = 5 AND BloomFilterMightContain((SELECT BloomFilterAggregate(XxHash64(S.s_sk), n_items, n_bits) AS bloom_filterFROM S WHERE S.x = 5), -- 布隆过滤器创建XxHash64(R.r_sk) -- 布隆过滤器应用)BloomFilterMightContain 函数签名:输入:bloom_filter (binary 类型):布隆过滤器。hash_value (long 类型):过滤器应用侧列值的哈希。返回类型:bool:如果哈希值存在则返回 true,否则返回 false。该函数假设 bloom_filter 输入是常量,不会改变。

2.核心参数
| 参数 | 默认值 | 说明 |
spark.sql.optimizer.runtime.bloomFilter.applicationSideScanSizeThreshold | 10GB | 应用侧的表scan的文件大小超过该值才能注入布隆过滤器。 |
spark.sql.optimizer.runtime.bloomFilter.creationSideThreshold | 10MB | 创建侧的表大小小于这个阈值才能创建布隆过滤器。 |
spark.sql.optimizer.runtime.bloomFilter.enabled | false | 设置为 true 开启才会启用布隆过滤器 |
spark.sql.optimizer.runtime.bloomFilter.expectedNumItems | 1000000 | 运行时bloomfilter的默认预期项目数 |
spark.sql.optimizer.runtime.bloomFilter.maxNumBits | 67108864 | 用于运行时布隆过滤器的最大位数 |
spark.sql.optimizer.runtime.bloomFilter.maxNumItems | 400万 | 运行时布隆过滤器允许的最大预期项目数 |
spark.sql.optimizer.runtime.bloomFilter.numBits | 8388608 | 用于运行时布隆过滤器的默认位数 |
spark.sql.optimizer.runtimeFilter.number.threshold | 10 | 单个查询注入的运行时过滤器(非 DPP)的总数。这是为了防止驱动程序因布隆过滤器过多而出现 OOM。 |
3.触发条件
3.1 布隆过滤器相关源码



3.2 Bloom Filter 触发条件总结
-
运行时过滤器数量阈值:
-
filterCounter < numFilterThreshold:当前注入的运行时过滤器数量必须小于配置的阈值 numFilterThreshold,该阈值由 conf.getConf(SQLConf.RUNTIME_FILTER_NUMBER_THRESHOLD) 获取。
-
-
没有动态分区修剪(DPP)过滤器:
-
!hasDynamicPruningSubquery(left, right, l, r):连接键上没有已经存在的动态分区修剪(DPP)过滤器。
-
-
没有已有的运行时过滤器:
-
!hasRuntimeFilter(newLeft, newRight, l, r):连接键上没有已经存在的运行时过滤器(无论是布隆过滤器还是IN子查询过滤器)。
-
-
表达式简单且廉价:
-
isSimpleExpression(l) && isSimpleExpression(r):连接键表达式必须是简单且廉价的表达式。
-
-
连接类型允许剪枝:
-
canPruneLeft(joinType) 和 canPruneRight(joinType):连接类型必须允许在左表或右表上进行剪枝。
-
filteringHasBenefit(left, right, l, hint) 和 filteringHasBenefit(right, left, r, hint):过滤器在左表或右表上有益处。
-
-
布隆过滤器创建侧数据量限制:
-
filterCreationSidePlan.stats.sizeInBytes <= conf.runtimeFilterCreationSideThreshold:布隆过滤器创建侧的数据量必须小于配置的阈值 runtimeFilterCreationSideThreshold。
-
-
开启参数,默认值为 false:
-
require(conf.runtimeFilterBloomFilterEnabled || conf.runtimeFilterSemiJoinReductionEnabled) :这行代码确保至少启用了布隆过滤器或IN子查询过滤器中的一种。
-
if (conf.runtimeFilterBloomFilterEnabled) :如果布隆过滤器启用 (conf.runtimeFilterBloomFilterEnabled 为 true),调用 injectBloomFilter 方法注入布隆过滤器。
-
4.测试查询sql

测试代码:
package com.mob.spark3.aqeimport org.apache.spark.sql.{SparkSession, SaveMode}import org.apache.spark.sql.functions.colobject BloomFilterDemo {def main(args: Array[String]): Unit = {// 创建 Spark 会话val spark = SparkSession.builder().master("local[*]").appName("Bloom Filter Benchmark").config("spark.sql.autoBroadcastJoinThreshold", "2mb").config("spark.sql.optimizer.runtime.bloomFilter.enabled", "true").config("spark.sql.optimizer.runtime.bloomFilter.applicationSideScanSizeThreshold", "4mb").getOrCreate()// 定义表格式val tableFormat = "orc" // 使用 orc 格式// 创建并写入表 tb1spark.range(500000000).select(col("id").as("a"), col("id").as("b"), col("id").as("c")).write.format(tableFormat).mode(SaveMode.Overwrite).saveAsTable("tb1")// 创建并写入表 tb2spark.range(200000000).select(col("id").as("a"), col("id").as("b"), col("id").as("c")).write.format(tableFormat).mode(SaveMode.Overwrite).saveAsTable("tb2")// 创建并写入表 tb3spark.range(10000).select(col("id").as("a"), col("id").as("b"), col("id").as("c")).write.format(tableFormat).mode(SaveMode.Overwrite).saveAsTable("tb3")// 执行 SQL 查询 When the join has a shuffle below it:val result = spark.sql("""|SELECT t12.a, t12.b|FROM (| SELECT tb1.a, tb2.b| FROM tb1| INNER JOIN tb2 ON tb1.a = tb2.a|) t12|INNER JOIN tb3 ON t12.a = tb3.a AND tb3.b < 10""".stripMargin)// 显示结果result.show()// 停止 Spark 会话Thread.sleep(3000000)spark.stop()}}
5.测试结果对比分析图
未启用布隆过滤器

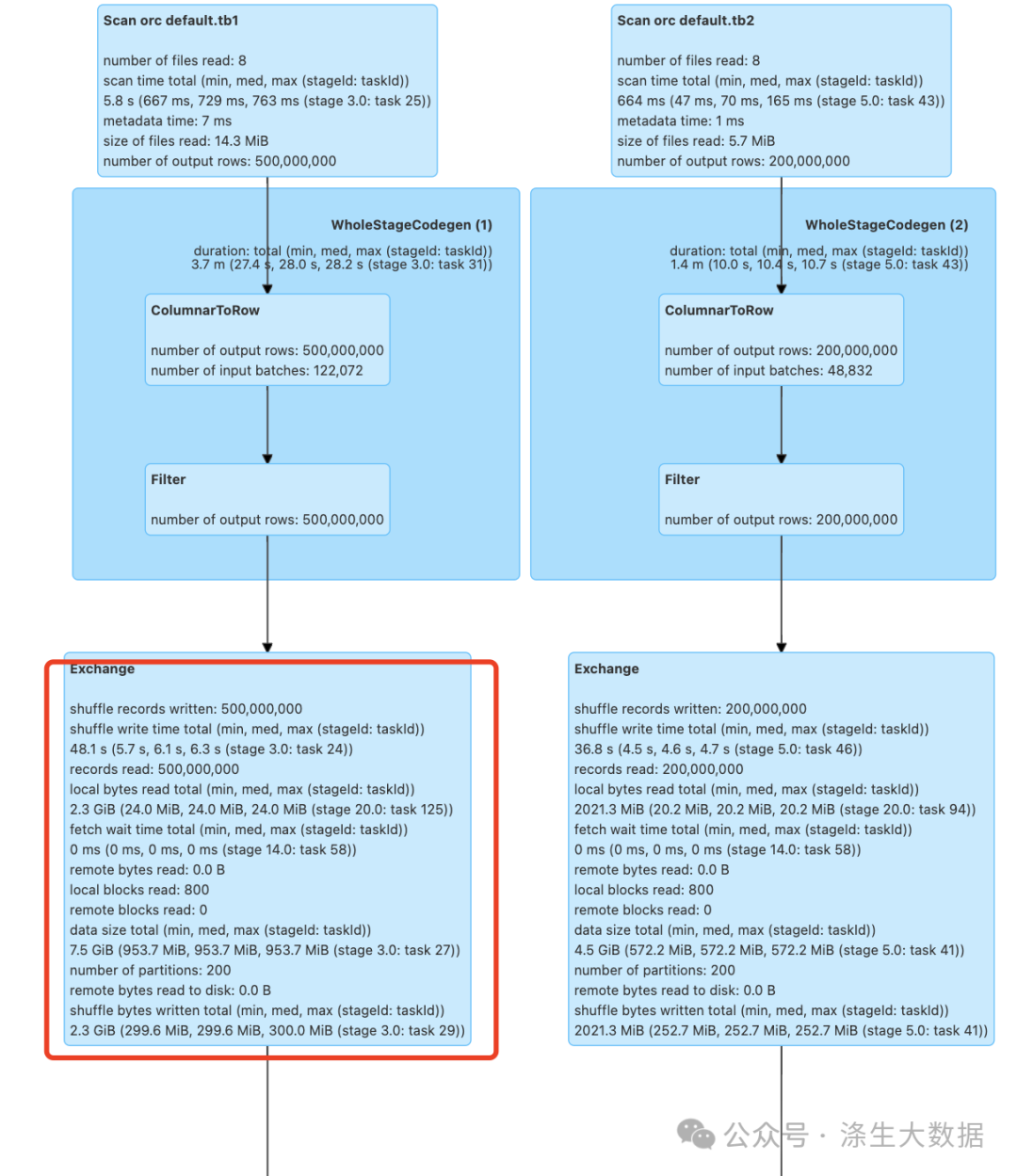
启用布隆过滤器

