Java面试题025:一文深入了解数据库Redis(1)
欢迎大家关注我的JAVA面试题专栏,该专栏会持续更新,从原理角度覆盖Java知识体系的方方面面。
一文吃透JAVA知识体系(面试题)![]() https://blog.csdn.net/wuxinyan123/category_7521898.html?fromshare=blogcolumn&sharetype=blogcolumn&sharerId=7521898&sharerefer=PC&sharesource=wuxinyan123&sharefrom=from_link
https://blog.csdn.net/wuxinyan123/category_7521898.html?fromshare=blogcolumn&sharetype=blogcolumn&sharerId=7521898&sharerefer=PC&sharesource=wuxinyan123&sharefrom=from_link
1、Redis简介
Redis是一种基于键值对(key-value)的NoSQL数据库。
支持string(字符串)、hash(哈希)、 list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、 HyperLog、GEO(地理信息定位)等多种数据结构,因此Redis可以满足很多应用场景,常用于缓存、消息队列、会话存储等应用场景。
2、Redis数据结构
Redis有五种基本数据结构。
(1)String
字符串类型的值可以是字符串(简单的字符串、复杂的字符串(例如JSON、 XML))、数字 (整数、浮点数),甚⾄至是二进制(图片、音频、视频),但最大不能超过512MB。
常用命令
-
SET key value:设置键的值。 -
GET key:获取键的值。 -
INCR key:将键的值加 1。 -
DECR key:将键的值减 1。
redis 127.0.0.1:6379> SET rutime "20250621"
OK
redis 127.0.0.1:6379> GET rutime
"20250621"(2)hash
hash 是一个键值(key=>value)对集合。
常用命令
-
HSET key field value:设置哈希表中字段的值。 -
HGET key field:获取哈希表中字段的值。 -
HGETALL key:获取哈希表中所有字段和值。 -
HDEL key field:删除哈希表中的一个或多个字段。
redis 127.0.0.1:6379> HMSET ddd field1 "Hello" field2 "World"
"OK"
redis 127.0.0.1:6379> HGET ddd field1
"Hello"(3)List
用来存储多个有序的字符串。
常用命令
-
LPUSH key value:将值插入到列表头部。 -
RPUSH key value:将值插入到列表尾部。 -
LPOP key:移出并获取列表的第一个元素。 -
RPOP key:移出并获取列表的最后一个元素。 -
LRANGE key start stop:获取列表在指定范围内的元素。
(4)Set
Set 是 string 类型的无序集合。
常用命令
-
SADD key value:向集合添加一个或多个成员。 -
SREM key value:移除集合中的一个或多个成员。 -
SMEMBERS key:返回集合中的所有成员。 -
SISMEMBER key value:判断值是否是集合的成员。
(5)zset(sorted set:有序集合)
有序集合中的每个元素都需要指定一个分数,根据分数对元素进行升序排序,如果多个元素有相同的分数,则以字典序进行升序排序,sorted set因此非常适合实现排名。
常用命令
-
ZADD key score value:向有序集合添加一个或多个成员,或更新已存在成员的分数。 -
ZRANGE key start stop [WITHSCORES]:返回指定范围内的成员。 -
ZREM key value:移除有序集合中的一个或多个成员。 -
ZSCORE key value:返回有序集合中,成员的分数值。
3、Redis速度快的原因
单机的Redis就可以支撑每秒十几万的并发,相对于MySQL来说,性能是MySQL的几十倍。
原因主要有几点:
(1)开发语言。使用C语言开发,C语言是非常贴近操作系统的语言,所以执行会比较快。
(2)纯内存访问。Redis将所有数据放在内存中,非数据同步正常工作中,是不需要从磁盘读取数据的,0次IO。内存响应时间大约为100纳秒,这是Redis速度快的重要基础。
(3)单线程。单线程避免了线程切换以及加锁释放锁带来的消耗,对于服务端开发来说,锁和线程切换通常是性能杀手。
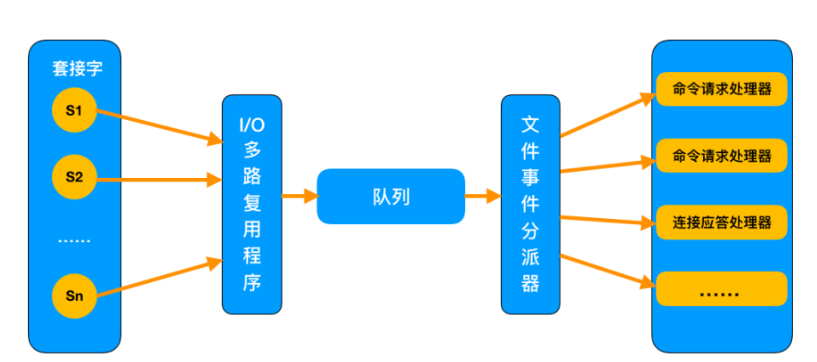
(4)非阻塞多路I/O复用机制。
- 第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。如果有一个学生卡住,全班都会被耽误。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
- 第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者多线程处理。
- 第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,你下去依次检查 C、D的答案,然后继续回到讲台上等。E、A又举手,然后去处理E和A。
I/O 多路复用其实是在单个线程中通过记录跟踪每一个socket(I/O流) 的状态来管理多个I/O流。
4、Redis应用场景
(1)缓存
是Redis应用最广泛地⽅。由于redis访问速度块、支持的数据类型比较丰富,Web应用会使用Redis作为缓存来存储热点数据,来降低数据源压力,提高响应速度。另外结合expire,我们可以设置过期时间然后再进行缓存更新操作,这个功能最为常见。
(2)计数器
redis的incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
(3)消息队列
(4)排行榜
借助redis的SortedSet进行热点数据的排序。
(5)分布式锁
主要利用redis的setnx命令实现。
(6)限时场景
比如验证码过期,利用Redis的过期操作。
5、缓存击穿

解决方案:
(1)加互斥锁
该方法是比较普遍的做法,即,在根据key获得的value值为空时,先锁上,再从数据库加载,加载完毕,释放锁。若其他线程发现获取锁失败,则睡眠50ms后重试。
至于锁的类型,单机环境用并发包的Lock类型就行,集群环境则使用分布式锁( redis的setnx)。

优点
1、数据的实时性较高,不需要其他外部系统依赖,利用了redis自己的特性,实现分布式锁,保证了同样的数据库查询同时只会查询1次,对数据库的压力较小
2、不会侵入业务代码,spring的aop就能很好的实现
1、阻塞等待分布式锁是个自旋阻塞操作,对应用服务器来说非常浪费cpu的分片时间,如果大量请求打过来, 应用服务器反而会先扛不住。
2、如果用户的查询是由多个系统的结果构成,每个系统的查询依赖上一个系统查询的结果,各个查询是串行的,那么自旋的睡眠时间可能会成为拖慢请求的罪魁祸首,多个系统都这么设计都在自旋睡眠,明显效率很低。
(2)定时任务主动刷新缓存

适用情况
1、已有一套现成的高可靠分布式定时任务系统
2、查询的数据变化不大
3、用户的请求量非常大的情况下
(3)布隆过滤器
布隆过滤器 (Bloom Filter) 是 1970 年由布隆提出的,是一种非常节省空间的概率数据结构,运行速度快,占用内存小,但是有一定的误判率且无法删除元素。它实际上是一个很长的二进制向量和一系列随机映射函数组成,主要用于判断一个元素是否在一个集合中。【单独一节详细介绍】
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。打个比方,当它说不认识你时,肯定就不认识;当它说见过你时,可能根本就没见过面,不过因为你的脸跟它认识的人中某脸比较相似 (某些熟脸的系数组合),所以误判以前见过你。

使用过程:
1.离线数据加载到布隆过滤器
2.布隆过滤器查询
3.布隆过滤器不存在,直接返回
4.布隆过滤器存在,cache不存在,从数据库查询
5.数据返回
(4)不过期
包含两层意思:
从缓存层面来看,没有设置过期时间,不会出现热点key过期后产生的问题,也就是“物理”不过期。
从功能层面来看,当发现热点key的值发生变化时,使用单独的线程去更新缓存。
6、缓存穿透
缓存穿透是指数据在redis不存在,数据库也不存在,返回空,一般来说空值是不会写入redis的,如果反复请求同一条数据,那么则会发生缓存穿透。

(1)缓存空值/默认值
在数据库不命中之后,把一个空对象或者默认值保存到缓存,之后再访问这个数据,就会从缓存中获取,这样就保护了数据库。
但是如果每次请求不同的key,同时这个key在数据库中也是不存在的,依然会发生缓存穿透。
(2)布隆过滤器
首先初始化项目的时候从数据库查询出来所有的key值,然后放到布隆过滤器中,当应用访问的时候,先去布隆过滤器中判断kedy值,如果发觉没有key值不存在,直接返回;如果key值在布隆过滤器存在,则去访问redis,由于是有误判率的,所以redis也有可能不存在;那么这时候就去访问数据库,数据库不存在,那就直接返回空就行。

如果误判率为3%,当有100万个请求同时过来的时候,布隆过滤器已经挡住了97万个请求,剩下3万个请求假如是误判的,这时候再访问数据库可以通过加锁的方式实现,只有竞争到锁了就去访问数据库,这样就完全可以解决缓存穿透问题。
7、缓存雪崩
某一时刻发生大规模的缓存失效的情况,例如缓存服务宕机、大量量key在同一时间过期,这样的后果就是大量的请求进来直接打到DB上,可能导致整个系统的崩溃,称为雪崩。

(1)提高缓存可用性
1. 集群部署:通过集群来提升缓存的可用性,可以利用Redis本身的Redis Cluster或者第三方集群方案如Codis 等。
2. 多级缓存:设置多级缓存,第一级缓存失效的基础上,访问二级缓存,每一级缓存的失效时间都不同。
(2)过期时间
1. 均匀过期:为了避免大量的缓存在同一时间过期,可以把不同的 key 过期时间随机生成,避免过期时间太过集中。
2. 热点数据永不不过期。
(3)熔断降级
1. 服务熔断:当缓存服务器宕机或超时响应时,为了防止整个系统出现雪崩,暂时停止业务服务访问缓存系统。
2. 服务降级:出现大量缓存失效,而且处在高并发高负荷的情况下,在业务系统内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的 fallback(退路)错误处理信息。
8、缓存预热
缓存预热,就是提前把数据库里的数据刷到缓存里,通常有这些方法:
1、直接写个缓存刷新页面或者接口,上线时手动操作。
2、数据量不大,可以在项目启动的时候自动进行加载。
3、定时任务刷新缓存。
9、redis 过期策略
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的 key。
redis 采用两种策略:定期删除+惰性删除。
(1)定期删除
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
-
从过期字典中随机 20 个 key;
-
删除这 20 个 key 中已经过期的 key;
-
如果过期的 key 比率超过 1/4,那就重复步骤 1;
同时,为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
如果Redis 实例中所有的 key (几十万个)在同一时间过期,Redis 会持续扫描过期字典 (循环多次),直到过期字典中过期的 key 变得稀疏,才会停止 (循环次数明显下降)。内存管理器需要频繁回收内存页,此时会产生一定的 CPU 消耗,必然导致线上读写请求出现明显的卡顿现象。
当客户端请求到来时(服务器如果正好进入过期扫描状态),客户端的请求将会等待至少 25ms 后才会进行处理,如果客户端将超时时间设置的比较短,比如 10ms,那么就会出现大量的链接因为超时而关闭,业务端就会出现很多异常。
一定要注意不宜全部在同一时间过期,可以给目标过期时间的基础上再加一个随机范围(redis.expire_at(key, random.randint(86400) + expire_ts)),分散过期处理的压力。
集群环境中从库不会进行过期扫描,从库对过期的处理是被动的。主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。因为指令同步是异步进行的,所以主库过期的 key 的 del 指令没有及时同步到从库的话,会出现主从数据的不一致,主库没有的数据在从库里还存在,分布式锁的算法漏洞就是因为这个同步延迟产生的。
(2)惰性删除
在客户端访问key时再进行检查如果过期了就立即删除。
10、Redis内存回收策略
如果定期删除漏掉了很多过期key,然后也没及时去查,也就没走被动处理,导致大量过期key堆积在内存里,当 Redis 已使用内存超出物理内存限制时,内存中的数据开始和磁盘产生频繁的交换 (swap),Redis 的性能急剧下降,此时Redis存取效率基本上等于不可用。
在生产环境中这是不允许的,为了限制最大使用内存,Redis 提供了配置参数 maxmemory 来限制内存超出期望大小。
redis.conf中配置
maxmemory <bytes> #最大内存(单位字节)
maxmemory-policy noeviction #默认 如果实际内存超出 maxmemory ,Redis提供了几种可选策略 (maxmemory-policy) 来让用户自己决定如何腾出新的空间(即回收内存)以继续提供读写服务。

-
volatile-xxx 策略只会针对带过期时间的 key 进行淘汰,
-
allkeys-xxx 策略会对所有的 key 进行淘汰
如果只是拿 Redis 做缓存,那最好使用 allkeys-xxx,客户端写缓存时不必携带过期时间。
如果还想同时具备持久化功能,那就使用 volatile-xxx 策略,好处就是,没有设置过期时间的 key 不会被 LRU 算法淘汰。