搜索二叉数(c++)
前言
在学习数据结构的时候我们学习过二叉树,那啥是搜索二叉树呢?我们知道单纯的二叉树没有增删查改的实际意义,因为没有任何限制条件的二叉树其实用处很局限。但是堆就不一样了,他就是一个二叉树加上了大小堆的限制条件,在排序方面很有作用,比如堆排序,时间复杂度是n*logN,效率挺高的。那搜索二叉数是加了上限制条件呢?搜索二叉数:本质是一颗二叉树+左子树的所有节点都小于根节点的值(左子树不为空的话)+右子树的所有结点的值都大于根节点的值(右子树不为空)+左右子树也分别为搜索二叉树。
总结下:搜索二叉树
- 若他的左子树不为空,左子树的所有节点的值都小于根节点的值
- 若他的右子树不为空,右子树的所有结点的值都大于根节点的值
- 他的左右子树也分别为搜索二叉树
我们管搜索二叉树也叫二叉搜索树,或者二叉排序树。这里提问下,他为啥可以叫二叉搜索树呢?
我们看一下这两个,SBTree(搜索二叉树),BSTree(二叉搜索树),你觉得SB好听呢?还是BSTree,让你更舒服点呢?这里开玩笑,其实叫啥都行,毕竟都有b树这种名字(听着就像在骂人)。可见取名字的人水平不是很高呀。好了,回到正文。
正文
在实现之前我们先看一颗搜索二叉树,如下图:

这棵树就是一颗二叉搜索树,你用中序遍历一遍会发现他是有序的,这也是他的实际用处。搜索二叉数主要运用在一些Kye搜索模型,快速判断在不在的场景,比如小区车辆出入系统。还有就是Key/Value模型,比如大名鼎鼎的高铁实名认证系统。
搜索二叉数的实现
基本代码
//结点
template<class K>
struct BSTreeNode
{BSTreeNode<K>* left;BSTreeNode<K>* right;K _key;BSTreeNode(const K& key):left(nullptr), right(nullptr), _key(key){}
};//二叉搜索树
template<class K>
class BSTree
{typedef BSTreeNode<K> Node;
public://构造BSTree():_root(nullptr){}//析构~BSTree(){Destroy(_root);}//拷贝构造BSTree(const BSTree<K>& t){_root = Copy(t._root);}//赋值重载 现代写法BSTree<K>& operator=(BSTree<K>& t){std::swap(_root, t._root);return *this;}//中序遍历void InOrder(){_InOrder(_root);cout << endl;}void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->left);cout << root->_key << " ";_InOrder(root->right);}private:
//拷贝
Node* Copy(Node* root)
{if (root == nullptr){return nullptr;}Node* copyRoot = new Node(root->_key);copyRoot->left = Copy(root->left);copyRoot->right = Copy(root->right);return copyRoot;
}
//后序删除 引用置空 方便很多
void Destroy(Node*& root)
{if (root == nullptr){return;}Destroy(root->left);Destroy(root->right);delete root;root == nullptr;
}Node* _root;
};
这里实现析构,拷贝构造,都是采用套娃的思路,定义一个私有方法,使用私有方法完成代码的逻辑,在public的方法就是调用这些方法,这样逻辑很清晰,库里很多代码都是这样实现。如果你学过一点java,会发现java里全是这样的设计。这里的赋值重载是用的现代写法,直接交换根节点,返回this指针,这也是推荐的写法,传统的一个一个赋值的写法,太麻烦了,这里不推荐。其实这里拷贝构造这样设计还有一个原因就是,你无法直接传一个_root,只能传一个树,但是我们有需要_root,因此只能采取这种方式,上传_root参数,实现拷贝效果。下面讲的是搜索二叉数里的核心代码,有两个版本,都要掌握。
非递归版
这里介绍了,查找,插入,删除,返回值都是bool值,表示成功与否。
//插入
bool Insert(const K& key)
{if (_root == nullptr) {_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->right;}else if (cur->_key > key){parent = cur;cur = cur->left;}else{return false;}}//记得链接 局部变量赋值 不会影响我们的链表cur = new Node(key);if (parent->_key > key){parent->left = cur;}else{parent->right = cur;}}
//查找
bool Find(const K& key)
{Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->right;}else if (cur->_key > key){cur = cur->left;}else{return true;}}return false;
}
//删除(重点) 思路先找后删除 删除有两种可能一个/没有孩子 或者 多个孩子>=2(替换法)
bool Erase(const K& key)
{Node* parent = nullptr;Node* cur = _root;//空树进不去while (cur){if (cur->_key < key){parent = cur;cur = cur->right;}else if (cur->_key > key){parent = cur;cur = cur->left;}//找到了 删除else{//左为空if (cur->left == nullptr){if (cur == _root){_root = cur->right;}else{if (parent->right == cur){parent->right = cur->right;}else{parent->left = cur->right;}} }//右为空else if (cur->right == nullptr){if (cur == _root){_root = cur->left;}else{if (parent->right == cur){parent->right = cur->left;}else{parent->left = cur->left;}} }//替换法else{//cur = 8;Node* leftParent = cur;Node* leftMax = _root->left;while (leftMax->right){leftParent = leftMax;leftMax = leftMax->right;}std::swap(leftMax->_key, cur->_key);if (leftParent->left == leftMax){leftParent->left = leftMax->left;}else{leftParent->right = leftMax->left;}cur = leftMax;}delete cur;return true;}}return false;
}Find实现
我们前面讲过,搜索二叉数的特点,适合排序。因此,我们在查找值的时候,可以根据左右子树大于/小于根这一特性,实现查找,这样查找的效率就不会是全部遍历一遍,如果比根小,那我们就可以直接在左子树里找,所以这里的时间复杂度就是高度次。我们这里非递归实现就是使用while循环cur指针,if else if分支语句,控制查找方向,在循环内找到,就进入else语句。如果循环解释还没找到,这时cur指针为空,那说明就没有,直接返回false 。提问下,这里的时间复杂是,O(n)还是logN,答案是O(n),不是查找高度次吗,二叉树的高度不是logN吗?这里二叉搜索树不一定就很满足完全二叉树的条件,他甚至可以这样,如下图

这种情况是肯定存在的,在这种情况几乎就是O(n),所以这里二叉搜索树,也没有很厉害,因此我们后面还要学习红黑树,他的底层就是二叉搜索树。这里我没有套值进去,大家可以自己套一下,这种情况是包存在的。
Insert实现
插入的代码的遍历树和查找是一个逻辑的,不同就是,插入是要循环外,当cur指针为空的时候再插入结点,所以这里需要new 一个结点,但是这并没有真正改变链表里的指向,我们需要引入一个父节点,来链接这里的关系。这里在根指针为空的时候,我们直接特殊处理,new结点赋值给root,然后返回true就行。这里注意二叉搜索树是不允许重复的值,这也符合他的特性。因此这里插入失败就是发现了重复的值。这里在用父节点,改变链接关系的时候,需要保证插入后还是一个二叉搜索树,因此,还需要判断一下他与父节点值的大小,再决定插入在左边还是右边。

入上图,这里插入-1还是2就是不同的结果,或者插入可能就会改变了这棵树,导致这棵树不再是二叉搜索树。
Erase实现
这里把这个删除放在最后讲,是因为删除是最难的一个实现,而且考的话也应该就是考这个(题目),这里删除是要分好几个情况
第一种情况:没有孩子或者一个孩子-->托孤
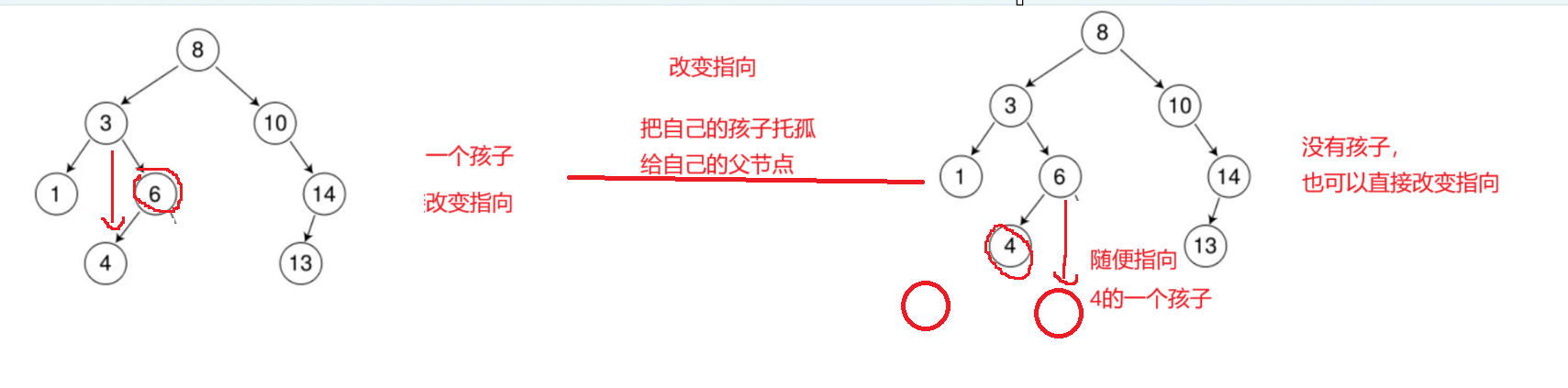
对于第一种情况,我们需要定义一个父节点,改变链接关系,那这里父节点是赋值给空指针呢还是赋值给cur指针呢,这里只能赋值cur指针,因为有一种情况会导致空指针引用问题,如下图

第二种情况:两个及两个以上的孩子-->替换法

这里也是需要一个父节点,再替换后,改变链接关系,但是注意这里是需要做一下判断的,不一定就是右子树改变关系,如下图

递归版
//递归实现bool FindR(const K& key){return _FindR(_root, key);}bool InsertR(const K& key){return _InsertR(_root, key);}bool EraseE(const K& key){return _EraseE(_root, key);}递归是需要上传一个root节点,但是我们只能上传一个个树,所以这里采取内部上传根节点,调用私有方法实现。
Find实现
bool _FindR(Node* root, const K& key){if (root == nullptr) return false;if (root->_key < key) {_FindR(root->right, key);}if (root->_key > key){_FindR(root->left, key);}else{return true;递归版就简单多了,使用二叉搜索树的特性判断,和上面循环的版本是一样的,只不过是吧循环该递归了而已
Insert实现
//这里引用 起到了自动链接的作用 bool _InsertR(Node*& root, const K& key){//为空链接 if (root == nullptr) {root = new Node(key);return true;}if (root->_key < key) {_InsertR(root->right, key);}if (root->_key > key){_InsertR(root->left, key);}//找不到else{return false;}}这里递归实现插入也很简单,非递归的版本是需要用父节点来链接,但是递归的版本我们可以不用这样子做,把参数改成引用,这样子改变的就不再是局部变量,而是直接改变本体。
Erase实现
//递归实现bool _EraseE(Node*& root, const K& key){if (root == nullptr) return false;//这里是if else if 一个执行了 另一个就不能执行 否则 你出错if (root->_key < key){_EraseE(root->right, key);}else if(root->_key > key){_EraseE(root->left, key);}//找到了else{Node* del = root;if (root->left == nullptr){root = root -> right;}else if (root->right == nullptr){root = root->left;}else{Node* leftMax = root->left;while (leftMax->left){leftMax = leftMax->right;}std::swap(root->_key, leftMax->_key);//这里不能传leftMax 指向改变会乱return _EraseE(root->left, key);}delete del;}return true;}这里递归实现删除相比于非递归的版本就简单多了,删除里面寻找代码的逻辑和查找是一样的,没啥好讲,主要是找到了之后我们该如何处理。上面插入的时候我们使用了引用直接改变了本体,不用再使用父节点改变链接关系,这里也是可以用引用,不用在搞一个父节点。删除的思路和非递归是一致的,也是分两种情况,不过这里有点复杂,因为你递归传的是一个节点的左子树或右子树的指针的引用,因此你是可以直接改变这个本体,所以在判断的时候,直接就用这个引用本身判断他的左子树还是右子树为空,然后在选择赋值给这个引用,就改变链接关系。然后替换也是找到节点交换节点的值,不过这里我们就可以再次递归,而不是直接删除,因为这里你没有父节点,也无法直接删除,否则链接关系也没法改变,我们干脆把递归思想贯彻到底,上传root->left去删除节点就行。注意这里不可以传leftMax,指向会直接改变,这里引用比较复杂,大家画图理解建议,这里刚开始看这里的代码,我也是没想通,但花了图,就想明白了。
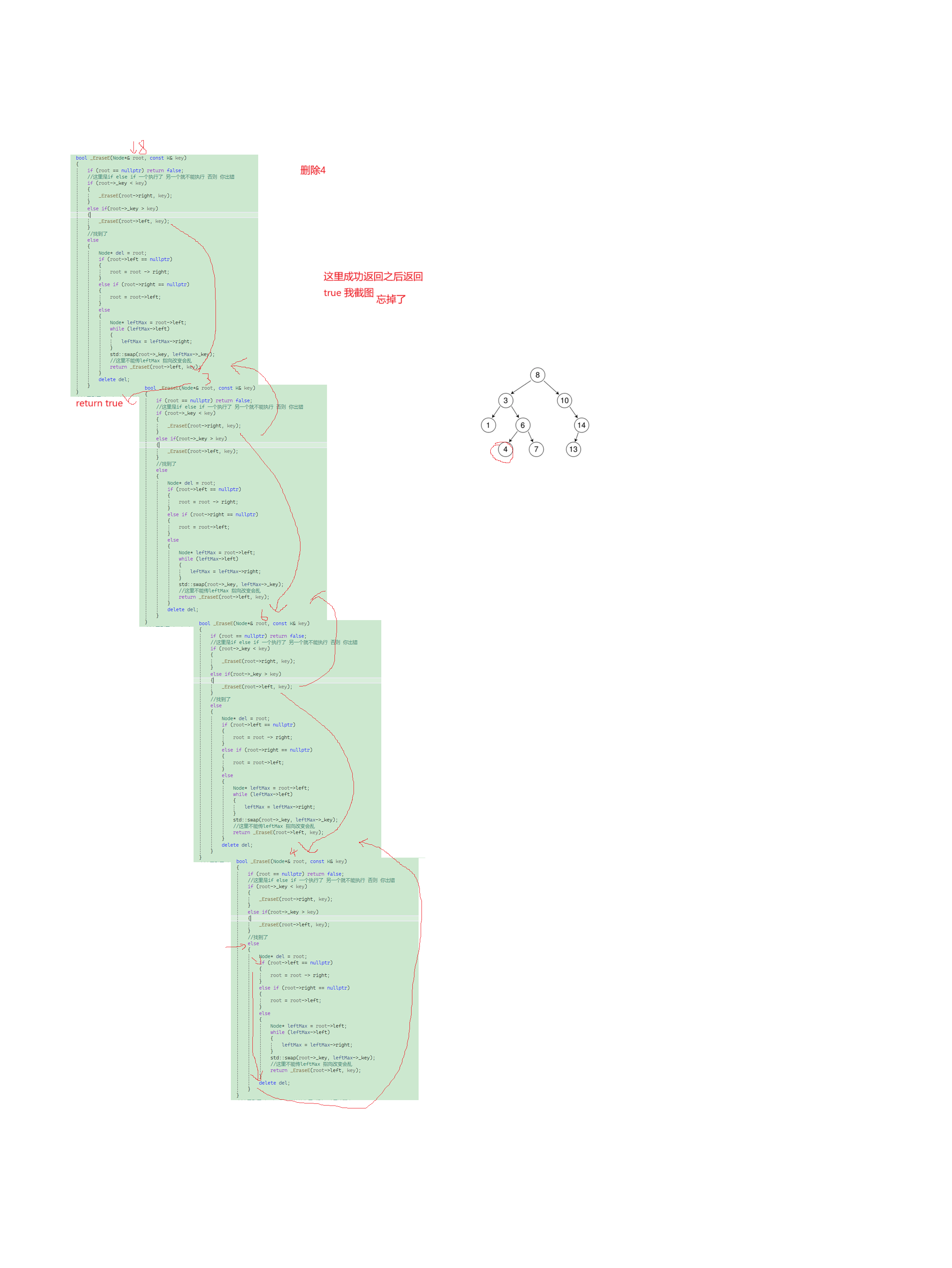
这里递归不理解,其实很好理解,画递归展开图,就可以解决大部分问题。
总结
搜索二叉树其实整体上讲还是比较简单的,主要是为后面的红黑树打基础,在学习C语言的时候我们发现有些数据结构很难写,但是学到c++之后,会发现这些数据结构直接放在STL容器里,而且他们的实现也好写多了,像这个二叉搜索树更适用于c++写,其实二叉树的学习,以及到后面的红黑树,都是更适用于c++。