论文笔记:Repetition Improves Language Model Embeddings
ICLR 2025 6666
1 intro
-
语言模型生成文本向量的传统方式,就是将文本输入到语言模型中,然后获取对应的隐状态,最终通过某种pooling策略得到文本向量。
-
对于自回归语言模型而言,由于没有[CLS],所以没法采取基于[CLS]的pooling策略
-
另外,由于前面的token看不到后面的token信息,没办法更好的抽取到全局信息,所以基于mean pooling的方式很容易出错
-
而基于last token的mean pooling方式又很容易受到文本最后出现的那些token的影响,不够稳健
-
-
——>目前自回归语言模型生成句向量的方式都比较特殊
-
mistral-7b-instruct会在文本后面插入一个[EOS],将这个位置对应的隐状态作为句向量
-
PromptEOL会构建一个prompt,“This sentence:[X] means in one word:”,让语言模型将文本信息浓缩到一个词,将下一个生成的token隐状态作为句向量
-
2 方法
- 论文提出了echo embeddin
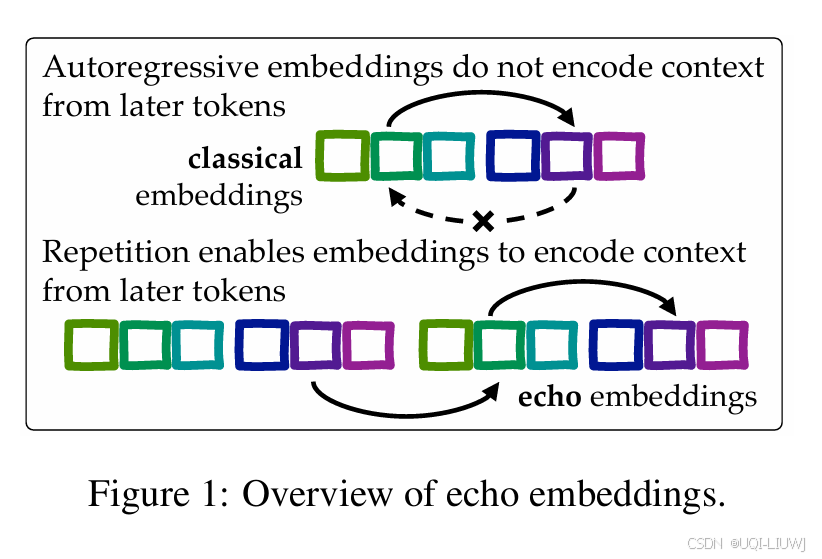

- prompt应该是到最后一个冒号
- 加粗的x的token就是text embedding
- 这样就能保证第二次出现的文本的每个token都能见到原文本所有的内容
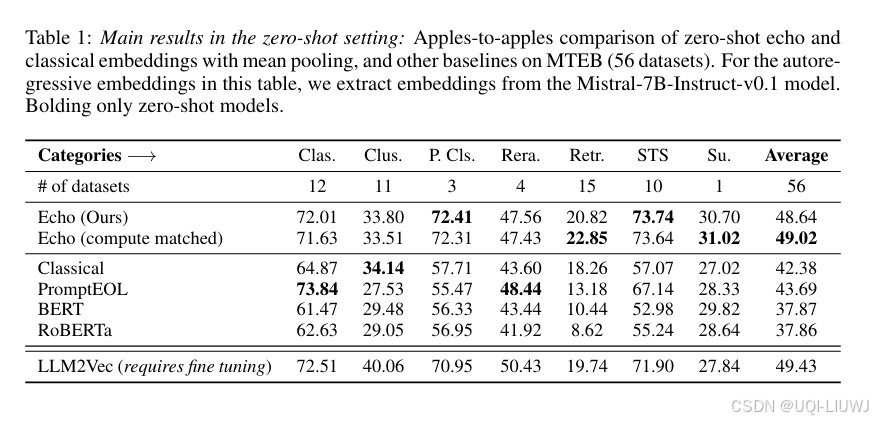
3 实验