You Only Look Once Unified, Real-Time Object Detection论文笔记
文章结构

统一检测框架(Unifiled Detection)
核心思想
YOLO 将目标检测视为一个端到端的回归问题,输入的图像经过Single Forward Pass,直接输出物体的信息(边界框的位置、边界框的置信度、类别概率);优势在于速度快,全局理解上下文,这里全局理解上下文的意思是识别物体和背景的关系,减少误检。
网络设计
- 网格划分(Grid Division)
将图像划分为一个 S×S 的网格,文中S=7;共 49 个 Grid Cell,每个 Grid Cell 负责预测 B 个边界框,论文中的 B 是 2 的意思, 每个边界框直接预测【1. 边界框的坐标:x,y】【尺寸:width,length】【置信度 conficdence】【20 个类别的概率】,总共 30 个数据 ( 2 × 5 + 20 = 30 ) (2 \times 5 + 20 = 30) (2×5+20=30);输出张量: S × S × 30 S \times S \times 30 S×S×30即 7 × 7 × 30 7 \times 7 \times 30 7×7×30。
网络架构
YOLO 的骨干网络是 24 个卷积层 + 2 层全连接层的 CNN,设计灵感来自于 GoogleNet;卷积层由 1 × 1 1\times 1 1×1和 3 × 3 3 \times 3 3×3组合提取特征;全连接层的作用就是整合各个卷积层识别出来的特征,负责输出最终结果(30 张量);FastYOLO 模型仅用了 9 层卷积,速度更快,达到了155FPS,但精度较低;24 个卷积层每个卷积层都有各自的作用,比如 5~10 层为浅层卷积,通过小卷积核( 1 × 1 1\times 1 1×1、 3 × 3 3\times 3 3×3)处理高分辨率,提取边缘、颜色和纹理这些低级特征;10~20 层是中层卷积,通过增大步长,降低分辨率来组合低级特征为中级特征,相当于识别一个初步的物体;20 层以上是深层卷积,通过堆叠卷积来实现大感受野,可以直接输出中层卷积识别的物体的置信度;感受野决定了网络中某一层神经元能够“看到”输入图像的多少区域,浅层的视野窄,能看到清晰的细节,深层视野广,能看到更大的范围;
补充一下感受野的计算->3 层 3 × 3 3 \times 3 3×3的卷积堆叠 3 层等效于 7 × 7 7 \times 7 7×7的单层感受野,计算公式如下:
R F n = R F n − 1 + ( k n − 1 ) × ∏ i = 1 n − 1 s i RF_n=RF_{n−1}+(k_n−1) \times ∏^{n−1}_{i=1}{s_i} RFn=RFn−1+(kn−1)×∏i=1n−1si
- 第 1 层( 3 × 3 3 \times 3 3×3)卷积,
R F 1 = 3 RF_1 = 3 RF1=3
- 第 2 层( 3 × 3 3 \times 3 3×3)卷积, R F 2 = R F 1 + ( 3 − 1 ) = 3 + 2 = 5 RF_2 = RF_1 + (3-1) = 3+2=5 RF2=RF1+(3−1)=3+2=5
- 第 3 层( 3 × 3 3 \times 3 3×3)卷积,
R F 3 = R F 2 + ( 3 − 1 ) = 5 + 2 = 7 RF_3 = RF_2 + (3-1) = 5+2=7 RF3=RF2+(3−1)=5+2=7
那为什么用 3 个 ( 3 × 3 3 \times 3 3×3)而不用 1 个 ( 7 × 7 7 \times 7 7×7)呢?因为通过堆叠小卷积核,能以更少的参数实现相同的感受野,同时可以引入更多非线性激活,增强表达能力;还有可以在计算时让 GPU 并行度更高,提高效率。
训练策略
- 预训练
先在 ImageNet (图片数据集) 上预训练 20 层卷积,然后增加 4 层卷积+2 层全连接层(FC 层);这里的全连接层有什么用?图像通过卷积层生成的是 $ 7 \times 7 \times 1024 $,这里的 1024 是有 1024 个通道(特征),通过全连接层压缩特征:拉平:把7×7×1024 变成 49×1024 = 50176 维的向量,相当于把7×7的网格拆开排成一条长数据。矩阵乘法:用权重矩阵 W(尺寸是 50176 × 4096)计算,得到 4096 维的中间向量,这一步可以看作特征压缩。再用另一个 权重矩阵 W’(尺寸是 4096 × 1470)计算,得到 1470 维的输出(1470 = 7×7×30)。最后的 reshape :把1470 维的向量重新整理成 7×7×30 的格式,作为最终输出。而为什么要用 20+4 卷积层而不是直接 24 层预训练呢?原因是 20 层预训练是让模型掌握通用的视觉特征提取能力,随后增加的 4 层卷积则专门针对检测任务优化。
2. 损失函数
YOLO 使用加权平均误差,但针对不同任务分配不同权重,详细见下;
推理阶段
推理阶段就是预测阶段,不是训练阶段。
- 输入图像,缩放至标准的 $ 448 \times 448 $分辨率;
- Single Forward Pass,输出 7 × 7 × 30 7\times 7 \times 30 7×7×30张量;所谓 Single Forwrad Pass,就是单次前向传播,前向是输出从输入->输出的,而反向是误差从输出->输入,调整模型参数,反向传播在训练阶段用,检测阶段不需要;
- 后处理:通过 NMS 非极大值抑制,保留 IOU 最高的预测,去除冗余;再通过阈值过滤,仅保留 confidence 高于阈值的结果;
损失函数(Loss Function)
总公式:
Loss = λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj [ ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 ] λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj ( C i − C ^ i ) 2 λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i − C ^ i ) 2 ∑ i = 0 S 2 1 i obj ∑ c ∈ classes ( p i ( c ) − p ^ i ( c ) ) 2 \text{Loss} = \lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} \left[ (x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2 \right] \lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} \left[ (\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2 \right] \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} (C_i - \hat{C}_i)^2 \lambda_{\text{noobj}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{noobj}} (C_i - \hat{C}_i)^2 \sum_{i=0}^{S^2} \mathbb{1}_i^{\text{obj}} \sum_{c \in \text{classes}} (p_i(c) - \hat{p}_i(c))^2 Loss=λcoord∑i=0S2∑j=0B1ijobj[(xi−x^i)2+(yi−y^i)2]λcoord∑i=0S2∑j=0B1ijobj[(wi−w^i)2+(hi−h^i)2]∑i=0S2∑j=0B1ijobj(Ci−C^i)2λnoobj∑i=0S2∑j=0B1ijnoobj(Ci−C^i)2∑i=0S21iobj∑c∈classes(pi(c)−p^i(c))2
公式分为5部分:
- 第一部分:边界框中心坐标损失
λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj [ ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 ] \lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} \left[ (x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2 \right] λcoord∑i=0S2∑j=0B1ijobj[(xi−x^i)2+(yi−y^i)2]
S 2 S^2 S2:输入图像被划分为 S 2 S^2 S2 的网格(例如,S=7,则有 7*7 = 49 个网格单元)。
B B B :每个网格单元预测 B个边界框(例如,B=2,每个单元预测 2 个边界框)。
1 i j obj \mathbb{1}_{ij}^{\text{obj}} 1ijobj:如果网格 i 中存在目标,并且第 j 个边界框预测器是“负责”该目标 的预测(即与真实边界框的 IoU 最高),则为 1,否则为 0。B=2,两个边界框选择IoU(交并比)高的那一个来“负责”,另外一个直接丢弃; 1 i j obj \mathbb{1}_{ij}^{\text{obj}} 1ijobj表示一个“开关”,比如第i个网格里有目标,并且在这个网格中的第j个边界框的IoU更高,那么此时 1 i j obj \mathbb{1}_{ij}^{\text{obj}} 1ijobj =1,否则等于0,等于1说明要用这个边界框来计算损失,反之不用它来计算损失;而两个预测框是怎么形成的呢?对于每个网格,输出包含: B × 5 B \times 5 B×5个值(x, y, w, h, C):每个边界框预测 5 个值C个类别概率(假设有 C个类别,比如 PASCAL VOC 有 20 类)。例如,如果C=20 ,每个网格输出 2 × 5 + 20 = 30 2 \times 5 + 20 = 30 2×5+20=30个值,整个输出张量是 7 × 7 × 30 7×7×30 7×7×30。在训练开始时,网络的权重是随机初始化的,因此,两个边界框(B=2)给的初始预测值看起来是随机的,因为网络还没有学到任何有意义的模式,但这些值不是完全随机的,而是由随机初始化的权重通过前向传播计算得来的,随着训练进行,两个边界框的预测会逐渐变得有意义。
- 第二部分:边界框宽高损失
λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i j obj [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] \lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} \left[ (\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2 \right] λcoord∑i=0S2∑j=0B1ijobj[(wi−w^i)2+(hi−h^i)2]
- 第三部分:有目标置信度损失
∑ i = 0 S 2 ∑ j = 0 B 1 i j obj ( C i − C ^ i ) 2 \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} (C_i - \hat{C}_i)^2 ∑i=0S2∑j=0B1ijobj(Ci−C^i)2
-
第四部分:无目标置信度损失
λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i − C ^ i ) 2 \lambda_{\text{noobj}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{noobj}} (C_i - \hat{C}_i)^2 λnoobj∑i=0S2∑j=0B1ijnoobj(Ci−C^i)2 -
第五部分:类别损失
∑ i = 0 S 2 1 i obj ∑ c ∈ classes ( p i ( c ) − p ^ i ( c ) ) 2 \sum_{i=0}^{S^2} \mathbb{1}_i^{\text{obj}} \sum_{c \in \text{classes}} (p_i(c) - \hat{p}_i(c))^2 ∑i=0S21iobj∑c∈classes(pi(c)−p^i(c))2
**每一部分前面有 ** λ coord \lambda_{\text{coord}} λcoord来控制权重。
卷积网络(CNN)
卷积网络设计
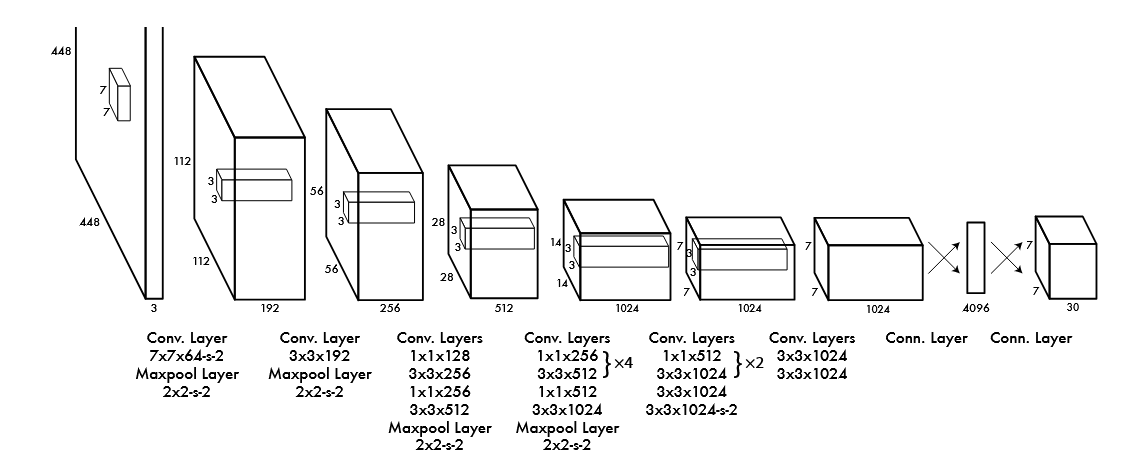
YOLOv1的卷积层工作是一个多阶段的特征提取和压缩过程,将输入的$ 448 \times 448 像素图像转化为适合目标检测的结构化输出过程始于输入图像,这张彩色图片具有 3 个通道( R G B ),通过 24 层卷积层和穿插其间的池化层逐步处理,最初的卷积(例如 像素图像转化为适合目标检测的结构化输出过程始于输入图像,这张彩色图片具有 3 个通道(RGB),通过 24 层卷积层和穿插其间的池化层逐步处理,最初的卷积(例如 像素图像转化为适合目标检测的结构化输出过程始于输入图像,这张彩色图片具有3个通道(RGB),通过24层卷积层和穿插其间的池化层逐步处理,最初的卷积(例如 7 \times 7 滤波器,步幅 2 )和池化,扫描图像后提取特征(如边缘、颜色梯度),将分辨率从 滤波器,步幅 2)和池化,扫描图像后提取特征(如边缘、颜色梯度),将分辨率从 滤波器,步幅2)和池化,扫描图像后提取特征(如边缘、颜色梯度),将分辨率从 448 \times 448 $降至 $ 112 \times 112 ,通道数从 3 增加到 64 ;以此类推,最后将像素降至 ,通道数从 3 增加到 64;以此类推,最后将像素降至 ,通道数从3增加到64;以此类推,最后将像素降至 7 \times 7 ,一共 49 个 g r i d s e l l ,每个 g r i d s e l l 包含 ,一共49个grid sell,每个grid sell包含 ,一共49个gridsell,每个gridsell包含 2 \times 5 + 20 = 30 个预测结果(特征信息);可以通俗理解成把原来的 个预测结果(特征信息);可以通俗理解成把原来的 个预测结果(特征信息);可以通俗理解成把原来的 448 \times 448 ,每个 g r i d s e l l 只存了颜色信息,通过卷积层转换成了 ,每个grid sell只存了颜色信息,通过卷积层转换成了 ,每个gridsell只存了颜色信息,通过卷积层转换成了 7 \times 7 $,每个grid sell存了很多新的特征;
卷积(Convolution)和池化(Pooling)的区别是什么?卷积:压缩尺寸,减少像素,增加通道数,让电脑多角度理解图片;池化:只压缩尺寸,不增加新特征,通道数保持不变,目的在于简化特征图,减少计算量和冗余细节,专注于主要趋势,计算的时候直接取最值或者平均值等,不涉及权重的计算;
卷积核的选择
3×3 卷积主要用于提取图像中的局部特征,比如边缘、形状等,因为它能覆盖相邻像素之间的关系;而 1×1 卷积不关注空间信息,只调整通道数,减少计算量或增强特征组合。举个例子来说,识别一个物体的时候,可以先用 3×3 卷积检测物体的轮廓,再用 1×1 卷积调整通道数来压缩或增强某些特征,这样既能高效提取信息,又能灵活控制计算成本。