ImageNet 上的安全外包神经网络推理
大家读完觉得有帮助记得及时关注和点赞!!!
抽象
外包神经网络推理的广泛采用带来了重大的隐私挑战,因为敏感的用户数据在不受信任的远程服务器上处理。安全推理提供了一种保护隐私的解决方案,但现有框架存在高计算开销和通信成本,使其无法用于实际部署。我们介绍秒ONNds,一种针对大型 ImageNet 规模卷积神经网络进行优化的非侵入式安全推理框架。秒ONNds集成了一个新颖的全布尔 Goldreich-Micali-Wigderson (GMW) 协议,用于安全比较 - 解决 Yao 的百万富翁问题 - 使用从 Silent Random Oblivious Transfer 生成的预处理的 Beaver 位三元组。我们的新方案实现了 17 倍的在线加速×与最先进的解决方案相比,在非线性作中,同时减少通信开销。为了进一步提高性能,秒ONNds采用数论变换 (NTT) 预处理,并利用 GPU 加速进行同态加密作,从而将速度提高 1.6×在 CPU 和 2.2 上×在 GPU 上进行线性运算。我们还提供秒ONNds-𝖯,一种位精确变体,可确保在安全计算中获得可验证的全精度结果,与纯文本计算的结果相匹配。在 37 位量化 SqueezeNet 模型上评估,秒ONNds在 GPU 上实现 2.8 秒的端到端推理时间,在 CPU 上实现 3.6 秒的端到端推理时间,总通信量仅为 420 MiB。秒ONNds' 效率和减少的计算负载使其非常适合在资源受限的环境中部署隐私敏感型应用程序。秒ONNds是开源的,可以从以下网址访问:
https://github.com/shashankballa/SecONNds。
1介绍
机器学习 (ML) 已经变得无处不在,预先训练的神经网络 (NN) 在塑造我们日常交互的众多应用中发挥着关键作用,例如图像识别、自然语言处理和推荐系统。为了处理这些模型的计算需求,尤其是深度神经网络 (DNN) 等大型模型,通常的做法是将计算外包给远程云服务器。这种方法允许资源受限的设备(例如移动和嵌入式系统)通过卸载繁重的计算并接收最终结果来利用强大的模型。但是,这种做法会带来重大的隐私风险,因为敏感的用户数据是在可能不完全受信任的远程服务器上处理的。

图 1:正统外包推理(左)与安全推理(右)
为了应对这些隐私问题,安全和隐私研究社区引入了安全推理框架,如图 1 所示。这些框架使用加密技术,确保保护所有相关方的所有私人数据:NN 推理的用户输入和输出,以及服务提供商的专有模型参数。这些解决方案允许用户在预先训练的 NN 上进行推理,而无需暴露他们的数据。
神经网络的架构多种多样,但本质上由一系列交替的多维线性运算和非线性运算组成,它们大多是一元的。卷积神经网络 (CNN) 是最受欢迎的架构类别之一,已成为计算机视觉任务所必需的。CNN 具有多维卷积作,用于将学习的空间特征与输入图像进行匹配,使用 ReLU作来选择与任务相关的匹配项,以及池化作来对匹配项进行下采样。CNN 开启了深度学习时代[45]随着模型在参数方面越来越大。
为了实现高效实用的安全推理,考虑到双方的资源分配,为低级神经网络作设计计算算法,并使用提供隐私的高效加密原语至关重要。采用零信任模型进行安全推理要求框架不泄露任何私有数据,并且只涉及用户和服务提供商,因此需要纯粹的2- 参与方安全模型。这需要用于安全 2 方计算 (2PC) 协议的加密原语:遗忘传输 (OT)[57]、乱码电路 (GC)[65], Goldreich-Micali-Wigderson (GMW)[27]和同态加密 (HE)[25].
OT 允许安全地交换消息,并支持安全的查找表 (LUT) 评估。与 FPGA 板的编程方式类似,OT 的表现力是通用的,是 GC 和 GMW 的基础。GC 是一种用于安全评估布尔电路的单轮协议,是第一个为 2PC 提出的解决方案。GMW 可以在布尔电路之上对定点数据上的算术电路进行安全评估,但它是一种高度交互的协议,需要各方之间对每项作进行持续通信。GC 和 GMW 都假设双方的资源分配对称,并且需要在两端进行相等数量的本地计算。
HE 是一种加密方案,它在加密数据中保留了一些代数结构,允许对密文进行计算,这些计算反映为对底层明文的简单作。虽然部分 HE 方案[62,55]提供一组有限的作,完全 HE 计划[25,22,17]启用任意计算,但速度非常慢。
分级 HE 方案[12,13,23,16]通过支持算术电路 (,+×) 对具有可用性能的固定大小(乘法深度)的固定点数据进行分配。HE 的主要优点是安全地外包计算;用户将加密发送到服务器,服务器执行所有计算并将加密结果返回给用户。这使得 HE 最适合涉及使用资源受限设备的用户和拥有强大云服务器的服务提供商的非对称场景。
2PC 基元 (GC, GMW, HE) 是为定点电路量身定制的,因此将神经网络作转换为定点表示是很常见的。这项任务已经通过量化神经网络 (QNN) 在机器学习中进行了深入研究[35].QNN 对所有数据使用定点表示,包括经过训练的模型参数。
模型的几乎所有训练参数都属于其线性层,仅用于计算输入的线性组合。因此,模型的大小直接对应于所涉及的线性运算的数量。使用 GC 或 GMW 时,线性层的通信占用空间随总标量乘法的数量而变化。相比之下,使用 HE 时,通信足迹仅随输入和输出向量的大小而变化。今天,平准 HE 在评估加密数据的高维线性代数运算方面优于任何其他 2PC 原语[5].
非线性运算构成了计算的其余部分,在神经网络中是必不可少的。这些非线性运算涉及比较,事实上,这是 Andrew Yao 在安全计算中研究的首批问题之一[65],他将其称为百万富翁的问题,磨=1{我0>我1}返回1如果一方-0的输入 (我0) 大于 party-1的输入 (我1).在最先进的安全推理协议中,这些作的大部分在线运行时来自安全比较(百万富翁协议)。
解决百万富翁问题涉及安全地评估需要 GC 或 GMW 的布尔运算。GC 涉及O(λb)11λ是计算安全参数,通常128用于比较一对b位秘密。使用 Silent OT Extension 初始化的 GMW 协议[11]执行相同的任务,开销仅为O(b),大大提高了它的性能,优于 GC。然而,现有的 GMW 协议仍然会产生高计算开销,尤其是对于像 ImageNet 这样的大规模数据集,这使得它们对于实际应用不切实际。
我们的方法:我们介绍秒ONNds,一个非侵入式安全推理框架,为 GMW 协议内的百万富翁问题开发新算法,并使用数论变换预处理和 GPU 加速增强基于 HE 的线性运算。通过全面改进非线性比较和线性计算,秒ONNds显著提高了安全推理的性能,使其适用于 ImageNet 等大规模应用程序。我们的主要贡献如下:
+ 百万富翁问题的新解决方案:我们介绍ℱ磨为了进行安全比较,使用具有 Beaver 位三元组 (triples) 的完全布尔 GMW 协议[7]使用静默随机 OT (ROT) 生成[64]与以前的工作相比,它实现了更快的运行时间和更低的通信,并且另一种变体只产生对数轮数,计算和通信成本略高。两者都通过离线三重缓冲区和针对静默 OT 优化的分块生成器得到进一步增强。
+ 神经网络作的高效协议:我们使用 ReLU、Max Pooling 和 Truncation 开发了新的 2PC 协议ℱ磨与离线三元组。对于线性代数运算,我们采用 BFV HE 方案[13,23]具有使用数论变换 (NTT) 的一次性预处理[5]和服务器端 GPU 加速[46].我们的方案实现了17×对于 Max Pooling,11×对于 ReLU,2.1×for 截断,以及2.2×用于在 GPU 上使用 HE 进行卷积,超过现有技术。
+ 端到端实施和评估:我们在37比特量化 SqueezeNet 模型[36]用于 ImageNet[20].秒ONNds实现的 E2E 运行时间仅为2.8seconds 和3.6秒,用于安全推理,涉及420总通信的 MiB。其 E2E 性能为4.2×与最先进的相比,在线速度更快。我们还实施秒ONNds-𝖯,与纯文本相比,这是一种位精确变体,可确保在安全计算中获得全精度、可验证的结果。
2背景
2.1数学符号
在本节中,我们将介绍本文中使用的数学符号。整数向量字段用ℤQN哪里N是向量空间的维数,Q是场模量。多项式环表示为ℛQN=ℤQ[X]国防部(XN+1)对于次小于N系数来自ℤQ.这里N是多项式模量,Q是系数模数。
标量ℤN由普通文本表示x或Y.向量ℤNm用粗体小写字母表示𝐱和ℤNp×q由粗体大写字母𝐗.中的 多项式ℛQN由带有上划线的粗体小写字母表示𝐩¯.编码密钥的 HE 明文𝐦表示为铂¯𝐦,其密文表示为电脑断层扫描 (CT)¯𝐦.
标量的按位补码x表示为x′.运营商⊕和∧保留用于加法 (XOR) 和乘法 (AND)ℤ2.为p∈{0:服务器,1: 客户端、派对}𝒫p的线性秘密份额我多ℤN表示为⟨我⟩pN,即我=⟨我⟩0N+⟨我⟩1N国防部N.指标函数,返回1如果满足条件,否则0表示为1{条件}.
2.2安全的 2 方计算 (2PC)
安全的 2 方计算使双方能够根据其私有输入联合计算函数,同时对它们保密。不同的加密原语支持 2PC,每个原语在效率、通信开销和计算复杂性方面都提供了独特的权衡。
遗忘转账 (OT) [57]是一种加密原语,它允许发送方将许多信息中的一条传输给接收方,而无需知道传输了哪一条信息,并确保对其他信息一无所知。根据功能,有各种类型的 OT。
相关 OT (COT):在相关 OT 中,用婴儿 床b中,发送者输入b位字符串m,接收方会获得一个b位字符串mc=m+c⋅δ哪里δ是固定的b发送方已知的位相关性,以及c∈ℤ2是接收方的选择位。输出根据发送方的输入进行关联δ.COT 是一种基础协议,通常用于生成相关随机数。
随机 OT (ROT):在随机 OT 中,发送方的消息是随机生成的,接收方根据其选择位获取其中一条消息。在(N1)–腐烂b,发送方会获取N随机b位字符串{r0,…,rN−1},接收方获取一个字符串rc哪里c∈ℤN是接收方的选择位。ROT 通常用于在安全协议中生成对称加密密钥或掩码。
Chosen OT:这是 OT 最具表现力的形式,通常简称为 OT。在(N1)–OT 系列b中,发送方输入N消息{m0,…,mN−1},并且接收器只学习mc哪里c∈ℤN是它的选择。当一方需要根据接收方的选择向另一方发送特定消息时,选择 OT 是必不可少的。例如,要评估安全 LUT,发送方设置 LUT 的值,接收方使用其私有选择进行索引,并且仅学习输出值。
这些 OT 原语可以根据需求以各种样式实现。高效的 OT 扩展协议[37,11]提供最佳的通信性能。它们允许从少量的基础 OT 生成大量 OT,从而显著提高效率。我们在附录 A 中详细讨论了 OT 扩展。
乱码电路 (GC) [65]是一种 2PC 协议,其中一方(垃圾人)加密布尔电路,允许另一方(评估者)在不学习中间值或输入的情况下计算它。每条导线都分配了两个λ-bit 随机键(标签),用于逻辑 0 和 1。garbler 对每个门的真值表进行加密,并将其连同自身输入的电线标签一起发送给赋值器。赋值器使用婴儿 床λ,确保 garbler 始终不知道 garuator 的输入。然后,它使用这些标签按顺序解密每个门,最终获得输出线标签。虽然 GC 通过单个通信轮次提供安全性,但由于需要加密电路中的每个门并处理大型乱码表,其中每个位都用大型λ位密文。
戈尔德赖希-米卡利-维格德森 (GMW) [27]是一种交互式协议,可以使用线性秘密共享方案 (LSSS) 构建[18].每个派对𝒫p持有机密共享⟨我⟩pN对于每个私有输入我在电路中。对于安全加法(XOR 门),计算在本地执行,无需交互,而安全乘法(AND 门)需要各方通过 OT 进行安全通信,以获得产品的秘密份额。GMW 的通信量随乘法运算的数量而变化,每次乘法需要一轮。然而,电路随机化和相关伪随机性的使用等技术,特别是通过 Beaver 的三元组,可以显著降低轮次的复杂性。
Beaver's Bit 三元组 [6,7]在在线阶段实现 AND 门的快速计算,而无需依赖 Chosen OT。Beaver 的 bit triple 包括{⟨一个⟩p2,⟨b⟩p2,⟨c⟩p2}哪里一个和b是随机位,而c=一个∧b.这可以使用 2 次调用(21)–腐烂1.在联机阶段,给定密钥共享输入⟨x⟩p2和⟨y⟩p2,各方使用预先共享的三元组值计算局部校正,并交换这些校正位以调整其输出份额(如附录 A.2 的算法 4 所示)。
虽然 GC 和 GMW 都提供了执行任何计算的能力,但它们的主要挑战是双方要求的计算工作量几乎相等,因此它们不提供外包计算的能力。
同态加密 (HE) 允许客户端在本地加密数据,将计算外包给对加密数据进行作的服务器,然后自己解密结果。这大大降低了通信开销,因为只传输输入和输出数据,而服务器处理大部分计算。完全同态加密 (FHE),例如 Gentry 方案[25]、TFHE[17]或 FHEW[22],通过引导提供无限的加密计算,但会产生较长的运行时间。Leveled HE 使用大量输入密文,并放弃了引导,这限制了加密计算并显著改善了运行时间。BGV[12]、BFV[13,23]和 CKKS[16]是基于 Ring Learning With Errors (RLWE) 的流行分级 HE 方案[48]难题。
RLWE HE 方案支持对密文进行加法、乘法和旋转运算。HE 乘法具有较大的噪声增长,影响加密计算量,而加法和旋转的影响可以忽略不计。在运行时方面,由于具有特殊公共评估键的密钥切换过程,轮换是最慢的EK¯,后跟涉及O(N2)卷积作,而添加相对较快。HE 乘法可以使用 NTT 进行优化,NTT 将其复杂性降低到O(N日志N).我们将在附录 C 中详细讨论 RLWE HE 和 NTT 的作用。
表 1:2PC 性能N×N矩阵-向量积
| 2 件 | 离线 | 在线 | ||||
|---|---|---|---|---|---|---|
| 协议 | 轮 | 通讯。 | 比较。 | 轮 | 通讯。 | 比较。 |
| 气相色谱 | 0 | 0 | 服务器 | 1 | O(λN2) | 客户 |
| 通用汽车 | 1 | O(N2) | 双 | 1 | O(N2) | 双 |
| 他 | 0 | 0 | 服务器 | 1 | O(N) | 服务器 |
2PC 成本比较。表 1 突出显示了不同的 2PC 协议(GC、带有 Beaver 三元组的 GMW 和 HE)的成本,用于执行大小为N×N.在此设置中,客户端持有私有输入向量,服务器持有私有输入矩阵(例如,支持向量机模型中的训练权重)。目标是让客户端在不显示其输入或学习服务器矩阵的情况下获取输出向量。
GC 要求服务器在 offline 阶段对 circuit 进行本地 garing ,从而产生计算成本。此脱机阶段不需要任何通信。在线阶段,服务器将乱码电路发送给客户端,导致通信成本与λN2哪里λ是 security 参数。此外N在在线阶段,相关 OT 用于共享与客户端的输入向量相对应的输入线标签。然后,客户端使用其输入标签评估乱码电路并学习输出。
GMW 涉及生成N2Beaver 的三元组使用2N2离线阶段的随机 OT,1矩阵向量积中所需的每个标量乘法的三倍。在此阶段,双方都会产生对称计算和通信成本。在在线阶段,各方在一轮通信中交换更正位,导致通信成本与N2以及保持双方之间的对称计算。
在离线阶段,HE 可能涉及服务器使用 NTT 对其矩阵进行预处理[5].在在线阶段,客户端对其 input 向量进行加密并将其发送到服务器。服务器使用其私有矩阵与 HE 执行矩阵向量乘法,并将加密后的输出向量返回给客户端。通信成本与N,计算负担主要在服务器上,服务器在本地执行同态作。
2.3安全推理框架
许多主要科技公司,例如 Apple[3]谷歌[28]、Microsoft[52]和 Amazon[2]正在大力推动以隐私为中心的 AI 推理解决方案,但他们选择使用可信执行环境 (TEE)。例如,Apple 的私有云计算 (PCC) 使用内置于定制 Apple 芯片中的 TEE 在基于云的 AI 处理期间保护用户数据。PCC 确保以无状态方式安全地处理数据,从而降低与数据保留相关的风险。这种外包推理系统的主要问题(如图 1 的左半部分所示)是它们仅在传输过程中通过加密保护数据;计算仍以明文形式执行,但由于硬件权限而无法访问。尽管 TEE 的设计很安全,但 TEE 固有的限制(如潜在的侧信道漏洞)阻碍了它们对隐私关键型应用的适用性[43,66,38].
用于安全推理的基于 2PC 的加密方法(如图 1 的右半部分所示)没有任何依赖关系,并利用强大的加密保证来保护所有阶段(位置)的数据:rest(内存)、传输(网络)和计算(处理器)。这些框架支持对私有数据进行神经网络计算,而不会向任何参与者透露任何敏感信息。多年来,已经开发了多个框架,利用各种加密技术来平衡效率和隐私。
加密网络 [26]是第一个在 MNIST 上运行卷积神经网络的安全推理框架[21].它完全由 HE 构建,并在1圆。它使用算术化的 CNN,这些 CNN 分别使用矩阵乘法和多项式激活来代替卷积和 ReLU。
迷你 ONN [47]是第一个非侵入性的22不需要任何模型定制或微调。,用于在 CIFAR-10 上执行推理的混合协议框架[44].它使用 GC、GMW 和 HE 来实施大多数常用 CNN作的协议。它实现了 (分段) 线性函数(如 (ReLU) 卷积)的精确协议,并且平滑函数是用样条函数(分段多项式)近似的。迷你 ONN具有离线预处理阶段,用于设置 Beaver 的位三元组[7]使用 HE。在在线阶段,涉及评估私有图像的推理结果,他们使用 GMW 和预处理的三元组进行所有线性运算,并使用 GC 进行比较。迷你 ONN新颖的混合协议设计要求在每一层之后进行通信,引入了额外的通信轮次,但性能比加密网络.所有后来的框架,严格针对 E2E 性能,都遵循这种混合协议设计。
瞪羚 [40]实现第一个专门构建的算法,用于对3-D 数据使用 HE。它将线性层的 HE 协议与 GC 协议相结合,以便在ℤP哪里P是 HE 纯文本素模量,并且显示的性能比迷你 ONN在 CIFAR-10 上。这促使线性层向前发展,回到 HE。
CrypTFlow2 [60]为百万富翁的问题引入新协议,利用最先进的优化和技术实现 IKNP 风格的 OT 扩展[42,4].它具有基于 OT 的所有非线性运算的高效实现ℤP以及ℤ2b使用这个百万富翁协议。作者观察到,用于ℤP比相应的协议更昂贵ℤ2b,但为了利用 HE 提供的优势,他们实现并集成了用于非线性运算的协议ℤP跟瞪羚的 HE 协议。CrypTFlow2在以下方面优于非线性运算的 GC 方案ℤP和ℤ2b一个数量级,并且是第一个在 ImageNet 上显示推理的公司[20].它采用忠实的截断,与纯文本相比,它确保在安全计算中获得位精确结果。
猎豹 [34]为 线性代数运算实现全新的算法ℤ2b使用 HE。它建立在 HE 乘法(基本上是多项式乘法)隐式计算系数上的向量点积的观察之上。为了利用这一点,猎豹实现一种编码方案,该方案绕过了 BFV/BGV 等方案的传统编码空间,而是将消息直接编码为多项式的系数。消息被战略性地放置在多项式中,以便使用单个多项式乘法计算一个矢量点积。此策略会产生稀疏输出,其中包含实际结果的系数非常少。猎豹通过从输出中提取相关系数来解决此问题。猎豹的线性代数协议不涉及任何 HE 旋转(最慢的 HE作),并且性能优于瞪羚的协议由5×在计算和通信方面。
猎豹使用CrypTFlow2的算法与源自 Ferret Silent OT 的 silent OT 基元[64]对于其非线性运算ℤ2b.为了减轻静默 OT 的计算开销,猎豹实现一个1位近似截断,特别针对已知密钥值为正的场景进行了优化。截断延迟到 ReLU 之后,而不是在卷积或矩阵乘法之后立即执行,以利用新的优化协议。猎豹达到3×更快的 E2E 运行时间,小于10×通信CrypTFlow2.
HELiK 系列 [5]是针对利用 HE 对高维数据进行 CNN 安全线性代数运算的工作系列的最新工作。它为安全线性代数运算 HE over 提出了新协议ℤP在猎豹在计算和通信方面,同时保持相同的精度,同时严格遵守所使用的 HE 方案的定义。猎豹的线性运算 HE 协议生成非常稀疏的 HE 结果,系数提取过程偏离 HE 方案定义,并且协议生成的最终输出与其相应的输入相比在结构上没有相似性。猎豹的 HE 结果不能被服务器轻易用于任何后续的 HE作(如果需要)。
HELiK 系列提供模块化内核,这些内核在输出中保持与 input 相同的编码格式。通过利用许多 HE 和算法优化,这些内核的性能得到了显著提高,例如降噪增长、1步长旋转、NTT 预处理、大输入的平铺和对称密钥加密。HELiK 系列使用CrypTFlow2进行非线性运算以执行安全推理。
最近,使用 2PC 的 Transformer Inference 在研究领域取得了巨大的推动,例如:SIRNN [59],铁 [30],螺栓 [56]和大黄蜂 [39].所有这些 transformer works 都重用了上述框架中的模块作为基础协议,并使用它们来构建更高级别的作,例如 softmax、GeLU、attention 等。
2.4计算瓶颈
尽管取得了进步,但安全推理框架仍面临重大的计算挑战,尤其是在涉及安全比较的非线性运算中。百万富翁协议(Millionaires' Protocol)用于确定一个私有值是否大于另一个私有值,这对于 ReLU 等激活函数和 Max Pools 等作至关重要。为了量化开销,我们评估了CrypTFlow2,猎豹和HELiK 系列per protocol 来运行37位 SqueezeNet[36]模型(如第 8 节所述)。我们使用相同的 Silent OT 扩展[64]back-end 的所有框架。图 2 所示的图表显示了每个协议的总运行时间和通信分布:Millionaires'(安全比较)、Convolution 和 Other。

图 2:每个协议的 Secure Inference 成本。
Millionaires' Protocol 是所有框架中对 runtime 的最重要贡献者,占61−76%的总数。CrypTFlow2和HELiK 系列忠实的截断花费140秒进行安全比较,而猎豹将此减少到大约60秒,通过采用1位近似截断和延迟计算。然而,即使有了这些改进,安全比较仍然是主要瓶颈,因为它们依赖于位级作和多轮交互。在沟通方面,比较的成本非常低7−8%跟猎豹需要不到CrypTFlow2.
卷积运算是下一个主要瓶颈,运行时贡献范围在17%和30%.猎豹将卷积时间缩短到17秒,与70seconds 用于CrypTFlow2和34seconds 用于HELiK 系列.随着 HE 旋转的消除,它的性能得到了显著提高,并且可以进一步受益于HELiK 系列就像数论变换 (NTT) 预计算一样。卷积运算也有助于11−43%的总通信。HELiK 系列,通信成本为124MiB 的表现优于两者CrypTFlow2 (217MiB) 和猎豹 (205MiB),因为计算过程中有效的噪声管理会导致密文大小更小。
其他作,包括本地明文作和二进制到算术共享转换 (B2A),对所有框架的运行时贡献不大,但会带来大量的通信开销。B2A作涉及翻译,因此通信成本很高1bit inputs 设置为b位域元素。
对变压器的影响。安全比较带来的计算挑战不仅限于基本的 CNN作,还延伸到更复杂的架构,如变压器。最近的 transformer 安全推理框架严重依赖百万富翁协议在激活函数中进行范围检查。框架,如SIRNN [59]和螺栓 [56]直接雇佣CrypTFlow2的协议替换为 IKNP 风格的 OT 扩展,而铁 [30]和大黄蜂 [39]用猎豹的变体。虽然这些框架引入了使用样条函数近似非线性运算的新方法——主要侧重于减少多项式段的数量,从而减少对百万富翁协议的调用——但它们保持基本比较协议不变。这种对现有比较协议的广泛依赖,加上我们的分析中显示它们的巨大性能开销,凸显了在隐私保护神经网络推理中对新方法进行安全比较的迫切需求。
3威胁模型
秒ONNds在两方半诚实 (诚实但好奇) 安全模型下运行,涉及具有私有输入数据的客户端和具有私有模型的服务器。该框架假设双方都正确执行协议,但可以记录所有观察到的值,各方之间不存在串通,并且网络对手可以观察但不能修改通信。在此安全模型下,该框架确保:(1) 客户端隐私:服务器对客户端的输入图像或推理结果一无所知,(2) 模型隐私:除了从输出标签中可以推断出的内容外,客户端对模型参数一无所知,以及 (3) 计算安全性:128基于标准加密假设的 bit security 参数。该模型排除了可能偏离协议的活跃攻击者。
4百万富翁协议

图 3:使用 LUT(Chosen OT)的百万富翁协议。
百万富翁的问题是由姚明概念化的[65]作为两个百万富翁,他们想在不向对方透露财富的情况下了解谁更富有。百万富翁问题的解决方案对应于安全地评估涉及两方的比较作,每方各有一个私人输入。Rathee 等人在 Rathee 等人在CrypTFlow2 [60].该算法的核心部分来自 Garay 等人的工作。[24],他提出了一种将两个大b位输入 /x一方 (𝒫0) 和y对方 (𝒫1)、到q=b/m连续的m每个位段,{x0,…,xq−1},{y0,…,yq−1},并使用算术电路计算结果m位号。该算法如图 3 所示,其中8位输入 (b=8),其中段大小为m=2位。
计算从计算不等式开始lt0,我=1{x我<y我}和相等eq0,我=1{x我=y我}所有 Segment-Pairs 的结果我∈[0,q).接下来是一个算术电路,该电路将这些结果以具有深度的二叉树方式组合在一起⌈日志q⌉−1.的q不等式和相等式比较在根级别 (j=0),对于每个级别,j≥1、两位、ltj,我和eqj,我,将针对所有节点进行计算我以后:

每个级别中的第一个节点都会跳过相等比较,最高节点的不等式结果将作为协议的最终输出返回。Garay 等人。[24]由于他们选择了加密原语,例如使用 Paillier 密码系统,因此使用了算术电路[55]用于安全整数乘法。后来,Blake 等人。[8]展示了如何使用 OT 评估整数比较。
CrypTFlow2的算法混合了 Blake 等人的基于 OT 的整数比较。[8]与 Garay 等人的对数深度算术电路。[24]来组合整数比较的结果。它通过将一对的比较 inequality 和 equality 折叠到对(2m1)–OT 系列2总通信成本q(λ+2m+1)bits 的q对。由于整数比较的结果是秘密共享位,因此 Garay 等人的对数深度电路的布尔版本。[24]通过替换为 bit-XOR (+⊕) 和×使用 bit-AND (∧).这∧–该布尔电路中的门限使用 GMW 协议进行评估ℱ和使用位三元组。它使用相关的位三元组优化位三元组的生成,并观察到输出2位 (j≥1,我≥1)、2调用ℱ和共享一个作数 (eq0,3在图 3 中)。生成三元组的总通信成本为(⌈日志q⌉−1)(λ+16)+(q−⌈日志q⌉)(λ+8),计算布尔电路的总成本是三重生成成本 和4(q−1)+4(q−⌈日志q⌉)要共享校正位 (4每ℱ和).
猎豹通过将 OT 基元移植到无提示 OT 扩展来优化此作[64]这将通信成本降低到q×(2m+1+m)对于q调用(2m1)–OT 系列2并且只到4(q−1)+4(q−⌈日志q⌉)对于布尔电路。它遵循 Asharov 等人提出的策略。[4]并生成一个位 triple 和 2 次调用(21)–腐烂1.由于这些 ROT 使用静默 OT 扩展,因此(21)–腐烂1在通信方面几乎是免费的。猎豹遵循CrypTFlow2设置 Segment Size 时m=4并使用(161)–OT 系列2以获得最佳性能。为m=4,通信需要9bbits 进行整数比较,使用2b+4−4⌈日志b⌉布尔电路的 bits 的 bits,总计约为11bbits,而m=1需要5b用于比较的位和8b−4−4⌈日志b⌉用于电路评估的位,总计约为13bbits (一个18%增加)。在我们的评估中,使用213比较32位号,而(2m1)–OT 系列2作采用90ms 用于两个设置,(21)–腐烂1作差异很大:110ms 的m=1; 15ms 的m=4.
4.1全布尔算法
秒ONNds具有完全布尔 GMW 协议ℱ磨如算法 1 所示,它消除了 LUT 评估(所选的 OT)。对于大小m=1,而之前的作品则使用重(21)–OT 系列2对于比较一对位的简单任务,秒ONNds建立在1{x我=y我}=(1⊕x我)⊕y我和1{x我<y我}=(1⊕x我)∧y我.评估位对的相等比较是免费的,𝒫0设置其在 EQUALS 结果中的份额⟨eq0,我⟩02=1⊕x我和𝒫1设置其份额⟨eq0,我⟩12=y我,无需通信。对于不平等,双方都调用ℱ和对于每个位,其中𝒫0输入1⊕x我,𝒫1输入y我并设置他们的份额lt0,我到ℱ和.此方法仅使用(21)–腐烂1(对于三代代)且花费的时间小于40ms 的213与32位号。它只需要4位数ℱ和和总计4b位。
对于对数深度电路,我们得到的总通信成本小于12bBits for the Millionaires' 协议。虽然这比16b在使用(2m1)–OT 系列2为m=1,它仍然高于11b在m=4.请注意,除了对数深度策略之外,我们还可以按以下方式按顺序组合整数比较结果:
遵循此线性策略lt0=0,最终结果将在值ltq−1,并且整体计算只需要b−1调用ℱ和这大约是2b−1−⌈日志b⌉对于具有 log 深度策略的m=1.此策略仅产生4(b−1)并使百万富翁协议的总通信足迹低于8b位,即27%低于11b的 Bits 成本(161)–OT 系列2跟m=4.
输入: 数据位宽b;不等式g:{0,1}→{<,>};
输入我p输出: 输出密钥共享⟨o⟩p2b12 为 我=0 自 b−1 做/* 位提取和共享生成 */3 ⟨b0⟩p2=((我p/2我国防部2)⊕g′)∧p′4 ⟨b1⟩p2=((我p/2我国防部2)⊕g)∧p/* 位相等和不等式比较 */56 ⟨𝐛EQL⟩p2[我]=⟨b0⟩p2⊕⟨b1⟩p27 ⟨𝐛𝐥/𝐠⟩p2[我]=ℱ和(⟨b0⟩p2,⟨b1⟩p2)/* 组合 Bit 结果 */8 为 我=0 自 b−2 做910 ⟨b一个nd⟩p2=ℱ和(⟨𝐛EQL⟩p2[我+1],⟨𝐛𝐥/𝐠⟩p2[我])11 ⟨𝐛𝐥/𝐠⟩p2[我+1]=⟨𝐛𝐥/𝐠⟩p2[我+1]⊕⟨b一个nd⟩p212⟨o⟩p2=⟨𝐛𝐥/𝐠⟩p2[b−1]算法 1 ℱ磨百万富翁秒ONNds 表 2:百万富翁协议的费用
| 协议 | 通信 | 运行 (213调用) |
| 猎豹 | 13b−4−4⌈日志b⌉ | ≈200女士 |
| (m = 1) | ||
| 猎豹 | 11b+4−4⌈日志b⌉ | ≈105女士 |
| (m = 4) | ||
| 秒ONNds | <8b | <(70+5)女士 |
| (我们的) | 线下 线上+ |
线性方法需要对(21)–腐烂1且占用的电量小于35ms 的213与32位号。在表 2 中,我们显示了在秒ONNds,则报告213运行b=32.我们用于百万富翁协议的新全布尔算法的总计算时间小于75MS 与在线三代,即28%小于(161)–OT 系列2版本与m=4.请注意,虽然线性策略将通信占用空间和计算成本减半,但它会导致轮数呈指数级增长。应用程序开发人员可以实施一个简单的切换,根据可用的网络资源在两种策略之间切换,以确保最佳服务质量。在下一节中,我们将展示如何显著降低在线运行时间75ms 到 under5MS 与离线三代。
4.2离线三代
为了有效地生成具有静默 OT 扩展的位三元组并将三元组生成安全地转移到离线阶段,我们实现了一个带有内部缓冲区的离线三元组生成器,灵感来自 cryptoTools 库中的 PRNG 实现[61].一旦与用户建立网络连接,triple generator 就会自动生成足够的 triple in in them them of fixed size size 来填充其缓冲区。当请求查询时,所有底层协议都使用三元组生成器的 get 功能来访问预处理的三元组。triple generator 自动生成新的 triple 并在在线计算过程中耗尽缓冲区时重新填充缓冲区。如果协议请求的三元组卷大于缓冲区大小,则缓冲区大小将增加,并且生成器会以固定大小的块生成新的三元组以填充缓冲区。
分块会增加n调用(21)–腐烂1从O(日志n)转换为次线性O(nm日志m)哪里m是一个块的大小。对于任何大型m,我们的分块策略的通信足迹与生成n (21)–腐烂1一气呵成。分块策略的真正优势在于计算时间,这实际上是静默 OT 的主要关注点。天真生成所涉及的计算复杂性n (21)–腐烂1的 是O(n2),源于静默 OT 的 LPN 编码阶段中涉及的矩阵乘法。使用分块策略,计算复杂度显著降低到O(nm)现在是线性的n.
5非线性运算
在本节中,我们将回顾 ReLU 和 Truncation 协议秒ONNds对于量化的 CNN。Max Pooling 和 Average Pooling 协议在附录 B.1 和 B.2 中讨论。
5.1ReLU 系列
函数ReLU 系列(Rectified Linear Unit) 是神经网络中广泛使用的激活函数,定义为ReLU 系列(我)=麦克斯(0,我).在秒ONNds,我们雇用猎豹的基于 Silent OT 的CrypTFlow2协议与第 4 节中描述的百万富翁协议。该协议表示为ℱReLU 系列,如算法 2 所示。
输入: 输入 secret 分享⟨我⟩p2b输出: 输出密钥共享⟨o⟩p2b12MSB的(⟨我⟩p2b)=⟨我⟩p2b/2b−13|⟨我⟩p2b|=⟨我⟩p2b−MSB的(⟨我⟩p2b)⋅2b−14我m我ll=(−1)p|⟨我⟩p2b|+p⋅(2b−1−1)5⟨w⟩p2=ℱ磨(b−1,1,我m我ll)⟨我drelu⟩p2=MSB的(⟨我⟩p2b)⊕⟨w⟩p2⊕p′// dReLU 结果6δ=(1−2⋅⟨我drelu⟩p2)⋅⟨我⟩p2b// COT 的 Deltac=⟨我drelu⟩p2// COT 的选择78ms=婴儿 床b–发送(δ) ; mr=婴儿 床b–收到(c)⟨o⟩p2b=(⟨我⟩p2b⋅⟨我drelu⟩p2+mr−ms)国防部2b算法 2 ℱReLU 系列ReLU 系列
该协议将进入ReLU 系列层,并返回ReLU 系列结果。协议首先评估dReLU 系列=1{我>0}并返回我如果dReLU 系列是1和秘密股份0如果dReLU 系列为零。请注意我>0在ℤ2b对应于我<2b−1,相当于:

这种不等式仅取决于环绕环中最大绝对值的份额的绝对值之和2b−1−1,由 bit 表示w在算法 2 中,以及份额的最高有效位 (MSB) 相等。特别是,它仅在以下情况下成立w是0并且两个 MSB 相同,或者如果w是1并且两个 MSB 不同:

这里,包裹位w使用第 4 节中描述的百万富翁协议安全地计算。计算后dReLU 系列,该协议使用安全的多路复用器功能,MUX (多路复用器,通过对婴儿 床b.这dReLU 系列result 用作选择位。如果dReLU 系列result 为1这MUX (多路复用器输出 input 的新份额;如果dReLU 系列result 为0这MUX (多路复用器输出 0 的份额。
输入: 右移量s ;
位我msb指示 ifMSB的(我)是已知的;
输入 secret 分享⟨我⟩p2b哪里我<2b−1输出: 输出密钥共享⟨o⟩p2b12MSB的(⟨我⟩p2b)=⟨我⟩p2b/2b−1/* Wrap Bit 计算 */3 如果 我msb 然后4 ⟨w⟩p2=ℱ和(p⋅MSB的(⟨我⟩p2b),p′⋅MSB的(⟨我⟩p2b))56 还7 ⟨w⟩p2=ℱ磨(b,1,[(−1)p⟨我⟩p2b+p⋅(2b−1)])/* Wrap B2A 股票转换 */8 如果 p=0 然后δ=−2⋅⟨w⟩p2// COT 的 Delta9 ms=婴儿 床b–发送(δ)10 ⟨w⟩p2b=⟨w⟩p2−ms11 还c=⟨w⟩p2// COT 的选择12 mr=婴儿 床b–收到(c)13 ⟨w⟩p2b=⟨w⟩p2+mr/* 最终截断结果 */14 ⟨o⟩p2b=⟨我⟩p2b/2s−⟨w⟩p2b⋅2b−s算法 3 ℱ截断截断
5.2截断
在定点计算的上下文中,截断是防止乘法后数据尺度升级的关键作。我们介绍了秒ONNds,表示为ℱ截断,在算法 3 中。此方法的核心概念是以未签名的形式表示数据,如下所示:

此计算是近似值,因为它没有考虑 secret 共享的 dropped 部分的潜在进利。但是,这仅在结果的最低有效位和之前的工作中引入错误[19,34]已经表明,神经网络对这种特定的1截断中的 bit 错误,对性能的影响可以忽略不计。包裹位w是使用ℱ磨,但是当 secret 值的符号已知时,例如 post-ReLU 当值为正时,w=MSB的(⟨我⟩02b)∧MSB的(⟨我⟩12b),并且可以通过对ℱ和双ℱ磨和ℱ和使用 offline bit triples。总的来说,该协议中的主要安全计算作是2b−1调用ℱ和为ℱ磨和一次对婴儿 床b若要转换w从二进制到算术,或只有一个ℱ和和 1 个婴儿 床b如果密钥共享的 MSB 已知。
5.3Secret 共享ℤ2b与。ℤP
秘密分享戒指的选择,ℤ2b(2 的幂) 或ℤP(其中P是质数)会显著影响非线性运算的实现和性能。在ℤP,任何需要比较的协议(如 wrap bit 计算)也必须检查 secret 是否溢出P并且必须为处理它做好准备。另一方面,在ℤ2b受益于与二进制系统的自然对齐;中的 Boolean Circuitℱ磨还仅处理显式指定的 bitwidth 和 overflows natural wrap around。

图 4:服务器(左)和客户端(右)设置的工作流程秒ONNds.
6线性作
CNN 中的典型线性层包括卷积层、全连接/矩阵乘法层和批量归一化。大部分线性运算来自矩阵乘法的卷积,这些矩阵乘法仅出现在 CNN 的末尾。批量规范化通常出现在卷积之后,通常的做法是将批量规范化与卷积融合在一起[49]在推理期间。
6.1HE 内核
线性代数运算可以由向量乘法、旋转和加法组成,所有这些都由明文空间的现代 HE 方案支持ZPN哪里P是 HE 纯文本模数素数。HELiK 系列 [5]提供最先进的内核,以最有效的方式组合这些作。这些协议的核心是一种迭代算法,其中每次迭代都涉及输入向量与权重的 HE 乘法,将乘积累加到上一次迭代的结果中,最后是 HE 旋转以移动累积值以调整下一次迭代。这种策略大大减少了所需的 HE 旋转次数。HELiK 系列通过使用 NTT 预处理权重来进一步提高性能,从而实现非常快的在线运行时间。虽然HELiK 系列为线性代数运算提供尖端性能,为了实现安全推理,它需要使用ZP进行非线性运算或使用共享转换协议将 Secret 共享从ZP到 Secret 共享Z2b.
猎豹的 HE 内核在明文空间中运行Z2bN.它将秘密数据编码为多项式系数,从而通过 HE 乘法和加法实现多项式乘法和秘密数据的加法。猎豹的 HE 核纯粹通过迭代 HE 乘法累加 (MAC) 运算来计算线性代数运算,没有任何 HE 旋转。它们在 HE 中产生稀疏结果,然后从这些结果中提取相关系数,以产生线性代数运算的最终结果。
6.2NTT 预处理
我们优化猎豹的 HE 内核Z2bN使用 NTT 预处理。HE 乘法涉及多项式乘法,即O(N2)在计算复杂性中。多项式模量N通常为数千或更高,并且会导致乘法的运行时间非常长。HE 库通常通过使用 NTT 转换两个作数,在转换后的作数上执行 Hadamard 积,并使用 iNTT(逆 NTT)将乘积转换回其自然表示来优化此作。每个 HE 乘法都涉及两个 NTT 运算和一个 iNTT 运算,这两个运算都涉及O(N日志N).
Balla 等人。[5]观察到,对于线性代数运算,同一查询中对 HE 乘法的大多数调用都重用了一个作数(输入向量),而另一个作数(权重)在不同的查询中重用,并且为服务器(计算方)所知。在秒ONNds,则在编码过程中使用 NTT 自动对权重进行预处理,并始终保留在 NTT 表示形式中。在线查询时,服务器收到输入的密文后,首先用 NTT 对每个密文进行转换,在 NTT 中执行所有 HE MAC作,只从 NTT 转换回最终的 HE 结果。由于这些 HE 结果是稀疏的,因此仅提取包含输出向量元素的系数并将其发送回客户端进行解密。
6.3GPU 加速
HE作是本地和非交互式的,这使它们成为硬件加速的主要候选者。HE 协议的单端计算只需要计算方能够访问硬件加速器。在远程云计算中,服务器拥有 GPU 是很常见的。此外,多项式数据类型用向量表示,非常适合 GPU SIMD 计算。
特洛伊 [46]是实施 SEAL HE 库的新软件库[51]在 CUDA 中[54].秒ONNds使用 Troy 的 HE 评估器对服务器的 HE 计算进行 GPU 实施。客户的所有计算都使用标准 SEAL 库执行;新的 GPU 实现不处理任何与密钥相关的作,并且仅对已加密的数据进行纯粹的计算。
7框架概述
表 3:非线性运算的运行时间(以秒为单位)和通信(以 MiB 为单位)
| 非线性 | CrypTFlow2 | HELiK 系列 | 猎豹 | 秒 NN−𝖯(LR) | 秒ONNds-𝖯 | 秒 NN(LR) | 秒ONNds | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 操作 | 时间 | 通讯。 | 时间 | 通讯。 | 时间 | 通讯。 | 时间 | 通讯。 | 时间 | 通讯。 | 时间 | 通讯。 | 时间 | 通讯。 |
| 截断 | 4.65 | 307 | 4.65 | 307 | 0.12 | 4.86 | 0.81 | 284 | 0.51 | 267 | 0.07 | 4.79 | 0.06 | 4.62 |
| ReLU 系列 | 6.73 | 302 | 6.73 | 302 | 2.53 | 110 | 1.72 | 246 | 0.87 | 186 | 0.72 | 116 | 0.23 | 88.7 |
| 最大池化 | 7.10 | 398 | 7.10 | 398 | 4.34 | 154 | 2.04 | 326 | 1.03 | 247 | 0.89 | 151 | 0.26 | 117 |
| 平均池化 | 0.03 | 4.19 | 0.03 | 4.23 | 0.06 | 4.43 | 0.02 | 4.20 | 0.02 | 4.19 | 0.06 | 4.42 | 0.05 | 4.45 |
| Arg Max | 0.06 | 0.21 | 0.06 | 0.19 | 0.02 | 0.11 | 0.02 | 0.19 | 0.02 | 0.20 | 0.01 | 0.11 | 0.01 | 0.11 |
表 4:离线 Triple Generation 成本
| 框架 | 三元组 | 运行时间 (s) | 通讯 (MiB) |
|---|---|---|---|
| 秒ONNds-𝖯(LR) | 1.2×109 | 27.16 | 60.41 |
| 秒ONNds-𝖯 | 8.2×108 | 22.43 | 43.12 |
| 秒ONNds(LR) | 4.9×108 | 10.61 | 26.36 |
| 秒ONNds | 3.4×108 | 8.31 | 17.01 |
秒ONNds遵循模块化设计,服务器和客户端具有不同的设置阶段,如图 4 所示。服务器的设置涉及三个关键步骤:(1) 将预训练模型量化为定点表示,使用 NTT 变换将权重打包和编码为 HE 明文,以实现高效的多项式乘法,(2) 将网络架构编译为配置文件,指定协议参数,包括秘密共享位宽,ℱ磨变体(对数深度/线性)、卷积的 NTT 预处理设置和三重缓冲区配置,以及 (3) 生成包含服务器 (SecNetS.prg) 和客户端 (SecNetC.prg) 实现的完整计算图和逐层执行顺序的程序文件。此预处理阶段与查询无关,除非更新模型参数,否则只需执行一次。
请求安全推理服务的客户端首先接收特定于模型的配置和程序文件。根据这些规范,客户端使用静默 ROT 生成必要数量的 Beaver 位三元组,由模型架构和计划的推理数量决定。三重生成过程与输入无关,完全是预处理,可以在实际推理请求之前离线执行。这些三元组存储在缓冲区中,当计算过程中耗尽时,该缓冲区会自动重新填充,具有动态大小调整功能,可处理不同的协议要求。
在线推理协议逐层执行,双方在整个网络中维护中间激活的秘密共享。非线性运算 (ReLU, Max Pooling) 采用带有预处理三元组的 GMW 协议,只需要对各方交换校正位的 AND 门进行交互。对于线性运算(卷积、全连接层),客户端加密并将其激活共享发送到服务器,服务器将自己的共享添加到这些密文中,使用 NTT 预处理的权重执行线性作,应用随机掩码以确保安全,并将加密结果返回给客户端以解密为输出共享。这种混合协议方法可以最佳地平衡计算和通信开销。
秒ONNds确保半诚实模型下的完美安全性 - 客户端只学习最终的分类标签,而服务器不学习 input 或 intermediate 值。其模块化设计允许通过配置文件选择运行时协议和参数配置,从而针对不同的网络条件和性能要求进行优化。例如,开发人员可以在ℱ磨基于网络延迟,或者根据可用的计算资源启用/禁用卷积的 NTT 预处理。
8评估
秒ONNds在 OpenCheetah 中实现[1]安全与正确推理 (SCI) 库的变体[53].我们实施秒ONNds用于 secret 共享ℤ2b和秒ONNds-𝖯为ℤP哪里P是 BFV-SIMD 明文素模量。秒ONNds使用1-bit 近似截断,而秒ONNds-𝖯采用忠实的截断法,并返回与纯文本模型相比的精确结果。两者都使用快速版本的ℱ磨默认使用 Linear 策略。如果框架采用低轮变体,则用括号中的 LR 表示,例如,秒ONNds(LR) 的
对于我们所有的评估,我们配备了所有被比较的框架:Ferret Silent OT Extension[64]来自 EMP-OT 库[63];BFV HE 方案[13,23]来自 SEAL 库[51];以及使用 Troy 库中的 HE Evaluator 进行服务器端 GPU 加速[46].双方的所有 CPU作均在16Intel Xeon Gold 6338 处理器的线程,辅以1TB 的 RAM 并利用 AES-NI 和 AVX-512 指令集扩展。服务器端 GPU 评估是在 NVIDIA RTX A6000 系统上进行的。
我们评估秒ONNds在预训练的 SqueezeNet 上[36]来自 OpenCheetah 的 CNN 模型[1].SqueezeNet 模型被统一量化为位宽为37和12用于缩放的位,实现79.6%前 5 名的准确率,与之前的作品相同。秒ONNds-𝖯执行精确位计算并生成与明文模型相同的输出 logits。秒ONNds使用1-bit 近似截断;只需0.0015%平均绝对百分比误差(MAPE) 的 SET 时,它对准确性没有影响。我们还评估了 ResNet50 模型[31],该92.3%前 5 名精度相同37-bit 设置和12-bit 缩放,并在附录 C.2 中显示结果。
8.1离线预处理
秒ONNds对模型权重执行 NTT 预处理,以实现快速在线 HE 计算。此过程不需要任何密钥信息,而且,它完全独立于查询;无需通信。对于 SqueezeNet,秒ONNds需要0.73秒进行 NTT 预处理,而秒ONNds-𝖯需要2.62秒ℤP从HELiK 系列.服务器可以在多个查询中重用 NTT 预处理的权重,除非更新或修改模型参数。
秒ONNds还会为每个查询离线生成 Beaver 三元组,这显著提高了非线性运算的在线性能。秒ONNds-𝖯需要2.4×与秒ONNds,因为与ℤP.如第 4.1 节所述,ℱ磨(LR) 涉及最多2×更多 AND (∧) 门。这导致每轮通信量更大,从而导致总通信量增加约1.5×对于对ℱ磨在非线性运算中,运行时间更长,运行时间延长了1.6×,与更快的ℱ磨使用线性电路。
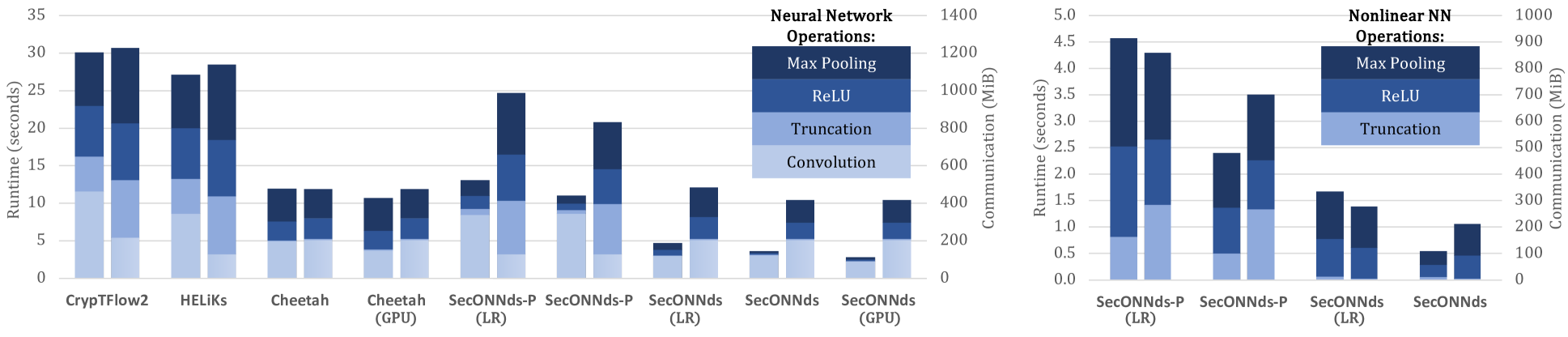
图 5:SqueezeNet 中神经网络 (NN)作的每个框架的端到端 (E2E) 运行时(左条)和通信(右条)性能,以及秒ONNds在右侧。
8.2非线性层
在表 3 中,我们显示了 SqueezeNet 上单个安全推理中所有非线性运算的累积性能: ReLU 、 Max Pooling 、 Average Pooling 、 ArgMax 和 Trunccation 。秒ONNds实现实质性改进猎豹在非线性运算中,使用17×更快的 Max Pooling,11×更快的 ReLU 和2×更快的截断。此外,通信成本最多可降低20%,在 ReLU 和 Max Pooling 中观察到的增益最大。
与CrypTFlow2和HELiK 系列,秒ONNds-𝖯显著缩短运行时间 –8×faster for ReLU,7×faster for Max Pooling,以及 faster9×更快的截断。通信成本秒ONNds-𝖯都低了大约27%相对于这些框架。的 LR 版本秒ONNds和秒ONNds-𝖯演示由于添加的∧-gates,并且仍然提供有竞争力的性能,使其适用于在不同网络条件下为不同轮次复杂性平衡延迟和通信。
8.3线性层
表 5:HE 卷积的成本
| 框架 | 脱机 (s) | 在线 (s) | 通讯 (MiB) |
|---|---|---|---|
| CrypTFlow2 | 0.00 | 11.59 | 217.10 |
| HELiK 系列 | 2.51 | 8.62 | 129.18 |
| 猎豹 | 0.00 | 4.94 | 204.84 |
| 猎豹(图形处理器) | 0.00 | 3.72 | 204.84 |
| 秒ONNds-𝖯/(LR) | 2.62 | 8.47 | 129.18 |
| 秒ONNds/(LR) | 0.76 | 3.09 | 204.84 |
| 秒ONNds(图形处理器) | 0.72 | 2.26 | 204.84 |
SqueezeNet 模型仅包含线性层的卷积,并针对 CPU 和 GPU 执行进行了评估。在表 5 中,我们显示了模型中所有卷积的每个框架的性能。秒ONNds与猎豹由于 NTT 预处理。在 CPU 上,秒ONNds实现 runtime3.09秒、1.6×改进猎豹的4.94秒。使用 GPU,秒ONNds将运行时间减少到2.26秒,实现1.4×多猎豹(GPU) 的 GPU 中。在沟通方面,秒ONNds实现与猎豹对于卷积层,两者都需要204.84米布 .然而赫利克斯和秒ONNds-𝖯展现最佳通讯效率,仅需130MiB 受益于 HE作中改进的噪声管理。
8.4E2E 评估
在端到端 (E2E) 评估中,如图 5 所示,秒ONNds在运行时间和通信效率方面表现出最佳性能,实现3.70秒和2.87秒。这是对其他框架的重大改进,具有3.24×speedup 与猎豹在 CPU 上,其在线运行时为12秒。即使使用 GPU,秒ONNds表现出大约3.8×与猎豹的运行时为10.79秒。对于通信,秒ONNds总共产生420MiB 显示大约12%与猎豹 (478.93MiB 的 Paypal 文件)。秒ONNds-𝖯,它通过全精度截断确保位精确精度,与HELiK 系列在运行时和通信指标中。秒ONNds-𝖯实现11.06秒,即2.46×加速超过HELiK 系列,其在线运行时为27.20秒。在沟通方面,秒ONNds-𝖯实现834.17MiB 的27%reduction from (降低自1141.95所需的 MiBHELiK 系列.
对于对数深度 (LR) 变体,两者秒ONNds和秒ONNds-𝖯旨在以略微增加计算量和通信量为代价,最大限度地减少通信轮次的数量。具体说来秒ONNds(LR) 实现了1084而秒ONNds-𝖯(LR) 与1542轮。与非 LR 版本相比,这些数字显著减少秒ONNds和秒ONNds-𝖯,这些4630和5800轮次。与猎豹,它使用900回合中,LR 变体表现出有竞争力的性能,但每轮的权衡涉及更高的计算工作量和通信量。
9分析与未来展望
9.1系统限制
秒ONNds在半诚实安全模型下运行,假设遵守诚实协议,这限制了它在恶意对抗设置中的使用,而不会产生额外的开销。此外,与纯文本推理相比,安全推理仍然会带来相当大的计算开销,这仍然给资源受限的实时应用程序带来挑战。尽管 GPU 库 Troy [46]显著加速基本同态加密作,与高度优化的多线程 CPU 实现相比,卷积等高级复合函数的性能改进适中。这凸显了针对复合运算(如线性代数内核)的专用硬件加速以实现全面性能提升的需求。
9.2替代解决方案
与纯 HE 框架相比,纯 HE 框架以最少的交互实现安全推理,但由于 FHE 引导而承受了大量的计算开销[25],秒ONNds通过降低这些成本来提供更平衡的解决方案。可信执行环境 (TEE),如 Intel SGX[50]在安全 Enclaves 中提供低延迟推理,但依赖于硬件信任假设,并且容易受到旁道攻击[14,15].秒ONNds利用应用加密技术和混合协议策略来优化线性和非线性作,在不依赖可信硬件的情况下实现实用性能。
9.3创新领域
潜在的增强功能秒ONNds可能包括集成神经网络压缩技术,例如修剪[29]、知识蒸馏[33]或更新的方法来降低模型复杂性并提高效率。扩展秒ONNds到更高级别的函数,例如用于安全计算复杂非线性函数(如 GeLU)的样条函数[32]和 Swish[58])将支持更广泛的神经网络架构。此外,扩展安全模型以适应恶意对手并进一步优化复合作的硬件加速可以提高安全推理任务的安全性和性能。
10结论
秒ONNds通过解决关键性能瓶颈并展示在大规模数据集上的实际适用性,推进安全神经网络推理。它非常适合在资源受限的环境中启用隐私敏感型 ML 应用程序。它允许服务提供商安全地外包 NN 计算,为用户提供实用的性能和强大的安全性,并减轻了计算负载。此外,作为一个非侵入式框架,它提供了适用于任何神经网络的基础模块,无论媒体类型如何,都不需要任何模型微调,并减少了对训练数据的任何依赖。秒ONNds高度兼容 – 它是完全开源的、模块化的和动态的,允许在运行时混合不同的预处理和协议优化,例如,具有在线/离线/无 NTT 预处理的线性层、百万富翁协议的切换轮次复杂性等。