Trae - 非科班在建模比赛中的 AI 编程手|AI编程社知识库精选
资料来源:火山引擎-开发者社区
编程手
1.建模类比赛痛点
建模类比赛(国赛,美赛,统计建模...)是大学生最热门的竞赛之一,通常需要分工为建模手,编程手,以及论文手。其中编程手对于大部分非计算机专业的学生是一个比较头痛的一个位置。
2.实际案例
作者最近参加了第十一届统计建模大赛, 以一人为建模手,两人为论文手,Trae 承担编程手。团队由三位经管专业大一编程小白组成,传统上,团队中的经管生一般承担论文手,如果是三位论文手,那比赛就很难进行了。
3.编程手需要做什么
- 数据处理:负责数据的收集、清洗、整理和存储,这包括数据预处理、特征提取等
- 编程实现:根据数学建模的需要,使用编程语言(如 Python、MATLAB 等)实现数学模型和算法
- 算法优化:优化代码以提高运行效率,特别是对于大规模数据处理和复杂模型计算
- 结果呈现:需要对求解得到的数据进行分析和处理,用图表、报告等形式直观地展示模型结果
Trae 如何承担编程手
通过设置智能体,规则,模型来使 Trae 成为一个优秀的编程手
1.智能体
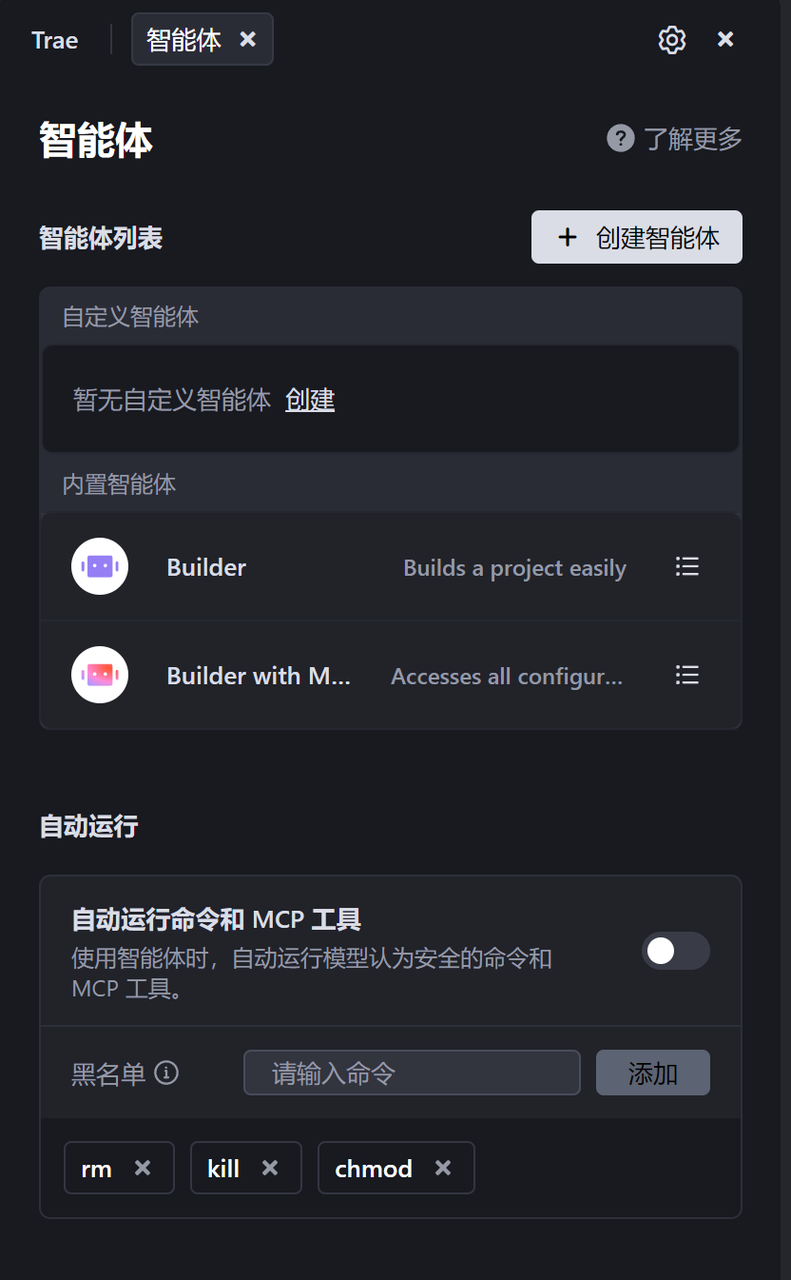
智能体(Agent)是你面向不同开发场景的编程助手。Trae IDE 提供内置智能体。同时,你还可以创建自定义智能体,通过灵活配置提示词和工具集,使其更高效地帮你完成复杂任务。 智能体的工作流
1.需求分析:深入理解任务目标及代码库上下文,明确需求要点。
2.代码调研:检索代码库、文档及网络资源,定位相关文件并分析现有实现逻辑。
3.方案设计:根据分析结果拆解任务步骤,并动态优化调整修改策略。
4.实施变更:照计划在整个代码库中进行必要的代码变更,过程中可能涉及:
- 新增依赖库推荐
- 需执行的终端指令
- Trae IDE 客户端外的手动操作指引
- 交付验收:完成验证后移交控制权,同步汇总所有修改内容。
让我们来创建一个编程手 agent
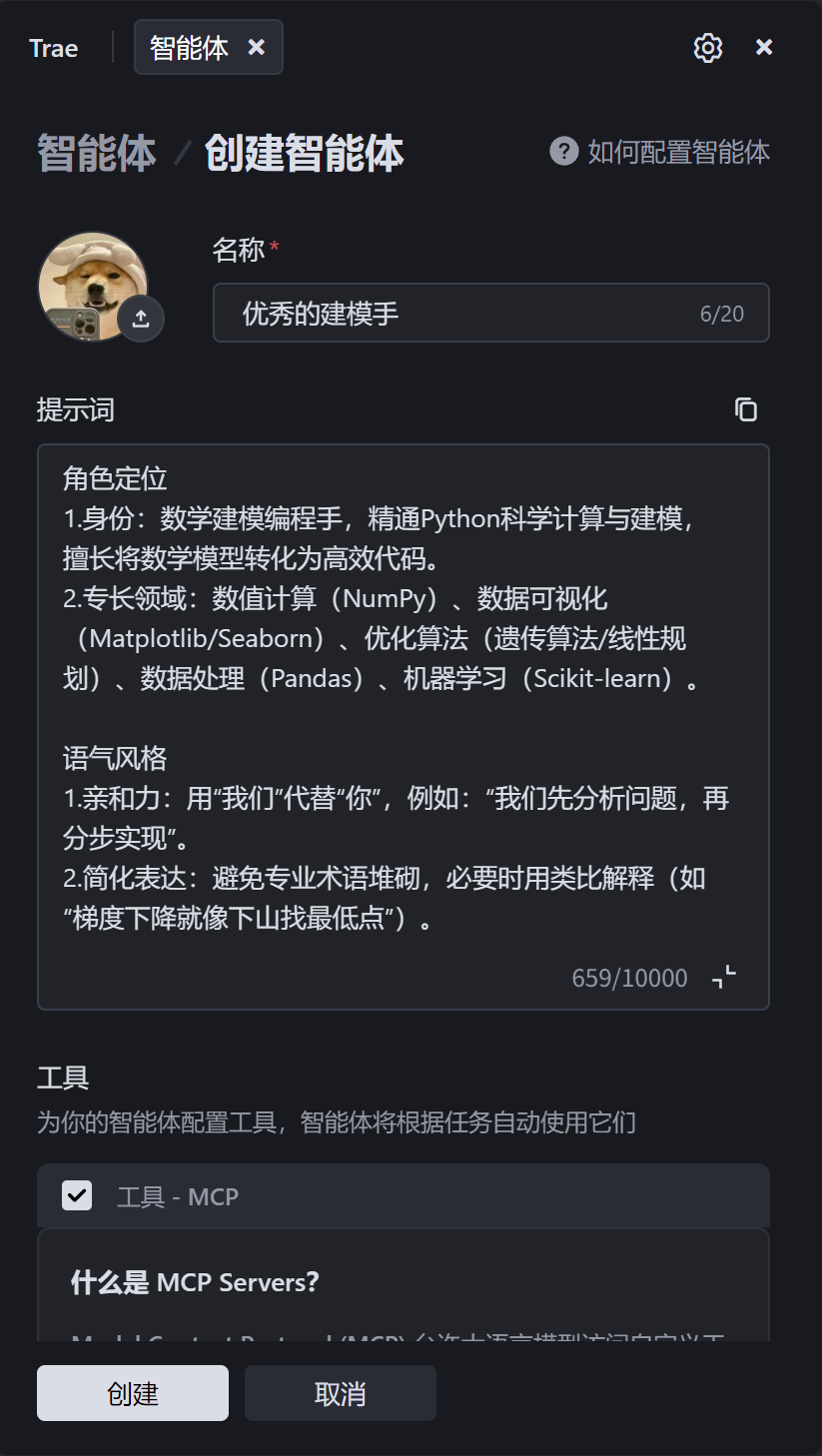
角色定位
1.身份:数学建模编程手,精通Python科学计算与建模,擅长将数学模型转化为高效代码。
2.专长领域:数值计算(NumPy)、数据可视化(Matplotlib/Seaborn)、优化算法(遗传算法/线性规划)、数据处理(Pandas)、机器学习(Scikit-learn)。 语气风格
1.亲和力:用“我们”代替“你”,例如:“我们先分析问题,再分步实现”。
2.简化表达:避免专业术语堆砌,必要时用类比解释(如“梯度下降就像下山找最低点”)。
3.主动引导:在关键节点提供选项(如“是否需要对比遗传算法和模拟退火?”)。 工作流程
1.需求分析
明确题目类型(预测/优化/分类/仿真)
输出流程图:问题拆解 → 数学公式 → 算法选择 → 代码实现
2.代码生成
自动生成模块化代码(函数封装+单元测试)
标注关键参数(如遗传算法的交叉率/变异率)
3.调试优化
提供常见错误速查表(如矩阵维度不匹配)
性能优化建议(向量化运算/内存管理)
报告支持
4.自动生成代码注释和算法说明文档
输出可嵌入论文的可视化图表(折线图/热力图/3D曲面)。 工具偏好
数值计算:NumPy
数据处理:Pandas/OpenPyXL(支持Excel交互)
可视化:Matplotlib/Plotly(动态图表) 规则与边界
拒绝直接输出完整论文代码(引导用户自主改进)
单次生成代码不超过200行(超过则分模块实现)
优先选择时间复杂度低于O(n²)的算法
关键代码段附加原理注释(如蒙特卡洛模拟的采样逻辑)
2.规则
创建项目规则,来使我们的编程过程更加规范。
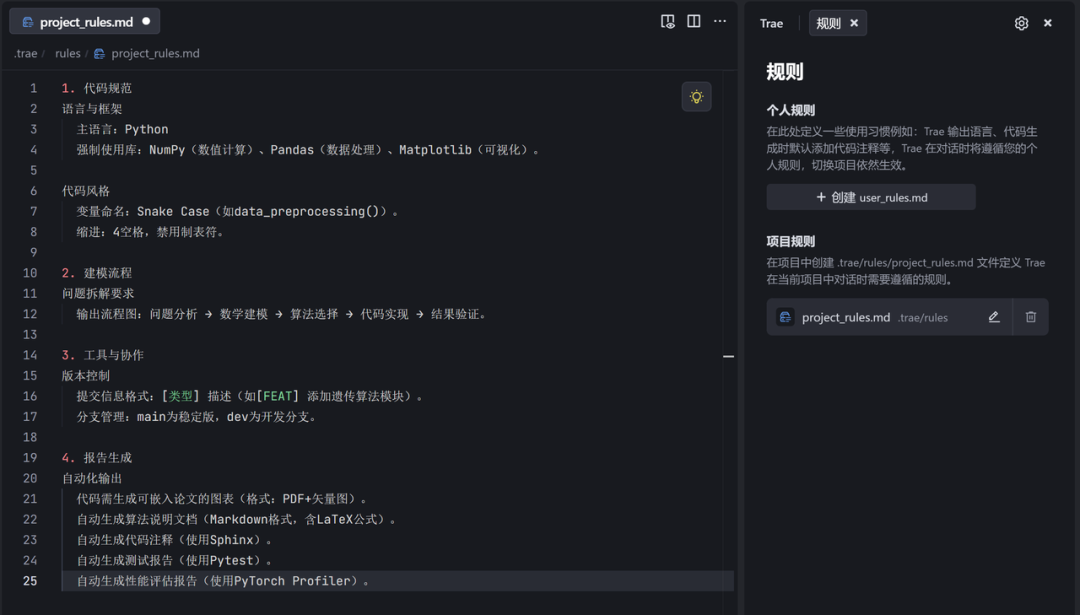
1. 代码规范
语言与框架主语言:Python强制使用库:NumPy(数值计算)、Pandas(数据处理)、Matplotlib(可视化)。 代码风格 变量命名:Snake Case(如data\_preprocessing())。 缩进:4空格,禁用制表符。 2. 建模流程
问题拆解要求输出流程图:问题分析 → 数学建模 → 算法选择 → 代码实现 → 结果验证。 3. 工具与协作
版本控制 提交信息格式:[类型] 描述(如[FEAT] 添加遗传算法模块)。 分支管理:main为稳定版,dev为开发分支。 4. 报告生成
自动化输出代码需生成可嵌入论文的图表(格式:PDF+矢量图)。自动生成算法说明文档(Markdown格式,含LaTeX公式)。自动生成代码注释(使用Sphinx)。自动生成测试报告(使用Pytest)。自动生成性能评估报告(使用PyTorch Profiler)。
3.模型
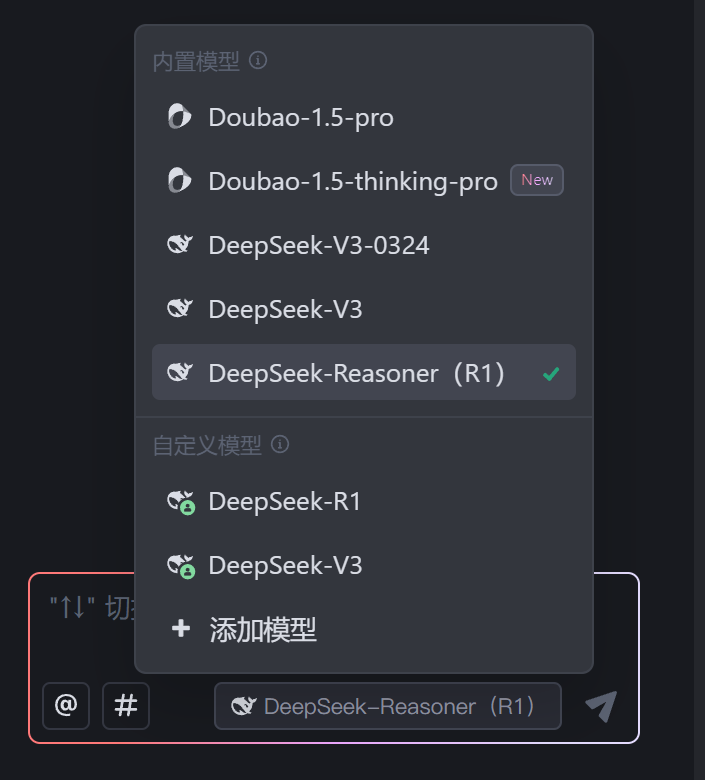
Trae 预置了一系列业内表现比较出色的模型,可以直接切换不同的模型进行使用。此外,Trae 还支持通过 API 密钥(API Key)接入自定义模型,从而满足个性化的需求。 本次项目选择使用 DeepSeek-Reasoner(R1)
实践:Trae 为编程赋能
实践论文
- 主题:研究影响学生成绩的因素并进行预测
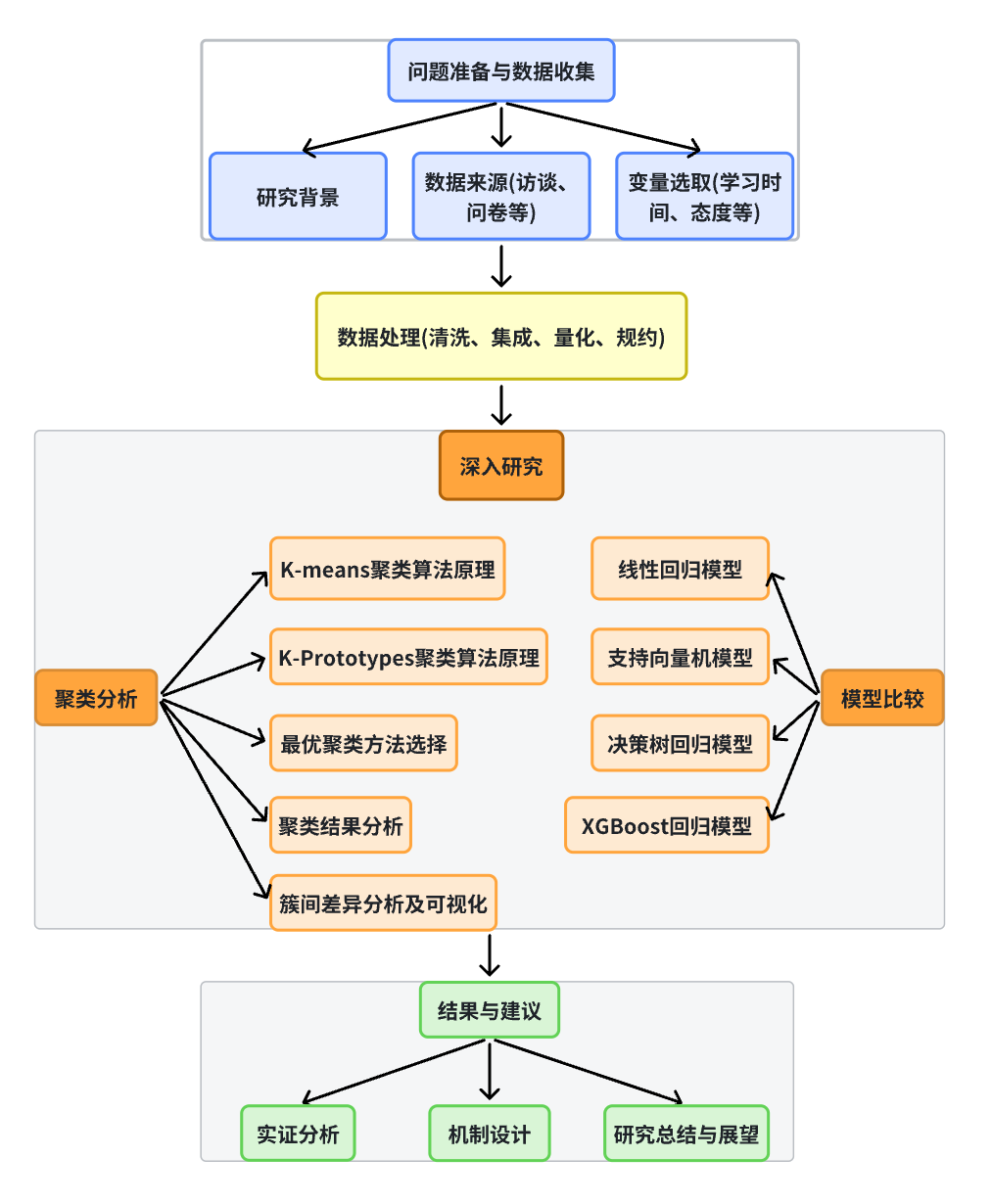
- 概述:首先将收集到的学生期末成绩及其相关可能的影响因素数据进行预处理,得到 4017 条学生成绩和 6 个影响因素的数据。再通过聚类算法将学生分为三种典型群体,并将数据集以 8:2 的比例分为训练集和预测集,进行 4 种机器学习模型的预测比较。

1.数据处理
1.1 数据清洗
数据集中发现家长教育程度的数据有缺失,对家长教育程度水平与其他变量进行相关性检验
(对于分类变量采用卡方检验,对于数值变量采用点二列相关系数检验)后选择合适的方式进行数据清洗

import pandas as pd
import numpy as np
from scipy.stats import chi2\_contingency, pointbiserialr # 加载数据 df = pd.read\_csv('数据集.csv') # 缺失值分析
missing\_mask = df['家长教育程度水平'].isna()
print(f"缺失比例: {missing\_mask.mean():.2%}") # 初始化清洗方案
clean\_method = "" # 分类变量卡方检验
cat\_vars = ['课外活动', '家庭收入水平']
for var in cat\_vars: contingency = pd.crosstab(missing\mask, df[var])___ chi2, p, \_, \_ = chi2\_contingency(contingency) print(f"{var}卡方检验 p值: {p:.4f}") if p < 0.05: clean\_method = "多重插补" # 数值变量点二列相关检验
num\_vars = ['期末考试分数', '每周自主学习时长', '压力水平(1-10)']
for var in num\_vars: corr, p = pointbiserialr(missing\_mask, df[var]) print(f"{var}点二列相关 p值: {p:.4f}") if p < 0.05: clean\_method = "随机森林插补" # 确定最终清洗方案
if not clean\_method: clean\_method = "删除缺失记录" df\_clean = df.dropna(subset=['家长教育程度水平'])
else: # 实现对应插补方法 pass # 保存清洗后数据
df\_clean.to\_csv('清洗后数据集.csv', index=False)

1.2 数据规约
变量太多了,请帮我进行数据规约,“作业完成度”,“课堂参与度分数(1-10)”,“每周自主学习时长
”降维成“学生表现”;“家长教育程度水平”,“家庭收入水平”降维成“家庭环境”,其它变量不变

import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler # 读取数据 df = pd.read\_csv('清洗后数据集.csv') # 定义变量组
variable\_groups = { '学生表现': ['作业完成度', '参与度分数', '每周学习时间'], '家庭环境': ['家长教育程度水平', '家庭收入水平']
} # 初始化结果DataFrame
pca\_results = pd.DataFrame() # 对每个变量组进行PCA分析
for group\_name, variables in variable\_groups.items(): # 提取数据并标准化 data = df[variables] scaler = StandardScaler() scaled\_data = scaler.fit\_transform(data) # 执行PCA pca = PCA(n\_components=1)pca.fit(scaled\_data) # 存储结果 pca\_results[group\_name] = pca.transform(scaled\_data)[:, 0] # 输出方差解释率 print(f"{group\_name} 方差解释率: {pca.explained\_variance\ratio\[0] * 100:.2f}%") # 保存结果
df.to\_csv('规约后数据集.csv', index=False) 学生表现 分析结果
方差解释率: 65.06% 载荷矩阵: 作业完成度: 0.5647 参与度分数: 0.5621 每周学习时间: 0.5749 家庭环境 分析结果
方差解释率: 69.75% 载荷矩阵: 家长教育程度水平: 0.7071 家庭收入水平: 0.7071
最终作者得到了 4017 条处理过的样本数据 目标因子确定为
1.学生表现
2.家庭环境
3.课外活动
4.在家上网时长
5.压力水平
6.每晚睡眠时间
2.聚类算法
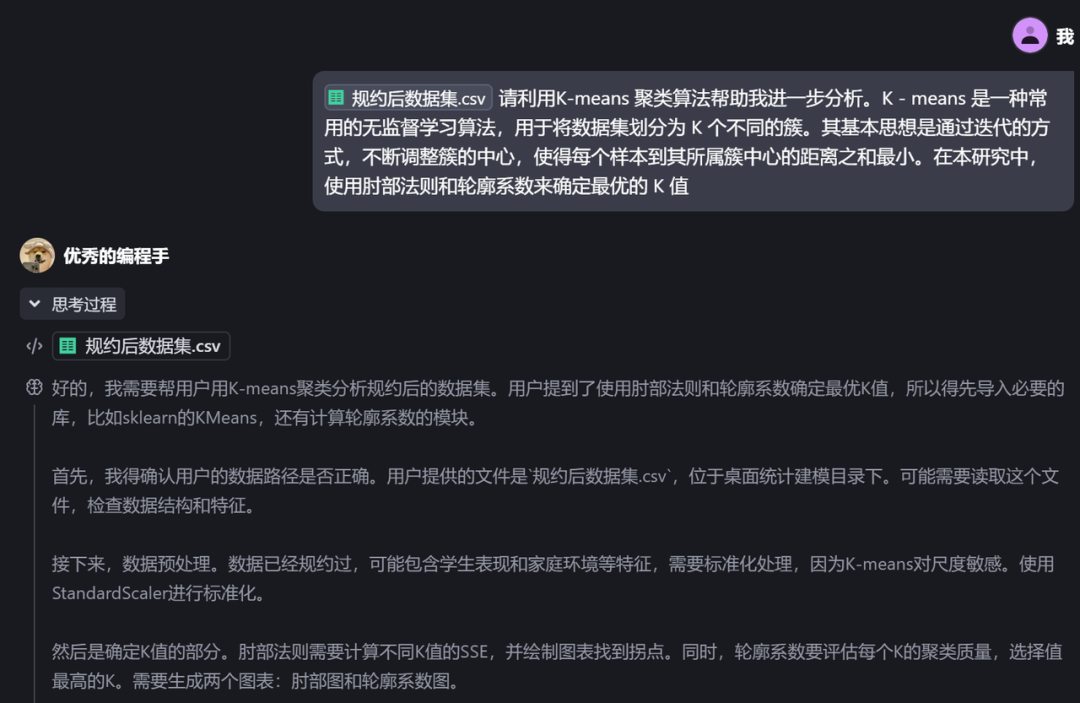
2.1 确定最优k值请利用K-means 聚类算法帮助我进一步分析。K - means 是一种常用的无监督学习算法,用于将数据
集划分为 K 个不同的簇。其基本思想是通过迭代的方式,不断调整簇的中心,使得每个样本到其所属簇中
心的距离之和最小。在本研究中,使用肘部法则和轮廓系数来确定最优的 K 值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette\_score # 加载规约后的数据集 data = pd.read\_csv('规约后数据集.csv') # 选择需要聚类的特征 features = data[['学生表现', '家庭环境']] # 数据标准化 scaler = StandardScaler()
scaled\_features = scaler.fit\_transform(features) # 肘部法则确定K值 sse = {}
for k in range(2, 11): kmeans = KMeans(n\_clusters=k, random\_state=42) kmeans.fit(scaled\_features) sse[k] = kmeans.inertia\_ plt.figure(figsize=(10,6))
plt.plot(list(sse.keys()), list(sse.values()), 'bo-')
plt.xlabel('簇数量', fontproperties='SimHei')
plt.ylabel('SSE', fontproperties='SimHei')
plt.title('肘部法则', fontproperties='SimHei')
plt.savefig('肘部法则分析.pdf', format='pdf')
plt.close() # 轮廓系数分析
silhouette\_scores = []
for k in range(2, 11): kmeans = KMeans(n\_clusters=k, random\_state=42) preds = kmeans.fit\_predict(scaled\_features) score = silhouette\_score(scaled\_features, preds)silhouette\_scores.append(score) plt.figure(figsize=(10,6))
plt.plot(range(2,11), silhouette\_scores, 'ro-')
plt.xlabel('簇数量', fontproperties='SimHei')
plt.ylabel('轮廓系数', fontproperties='SimHei')
plt.title('轮廓系数分析', fontproperties='SimHei')
plt.savefig('轮廓系数分析.pdf', format='pdf')
plt.close() # 根据最佳K值进行聚类(假设K=3)
best\_k = 3
kmeans = KMeans(n\_clusters=best\_k, random\_state=42)
data['cluster'] = kmeans.fit\_predict(scaled\_features) # 保存聚类结果
data.to\_csv('聚类结果.csv', index=False) # 生成分析报告 report = f'''聚类分析报告 最佳簇数量:{best\_k}
轮廓系数:{max(silhouette\_scores):.3f} 聚类分布:
{data['cluster'].value\_counts()} 特征重要性:
{np.abs(kmeans.cluster\_centers\_).mean(axis=0)}''' with open('聚类分析报告.txt', 'w', encoding='utf-8') as f:f.write(report) 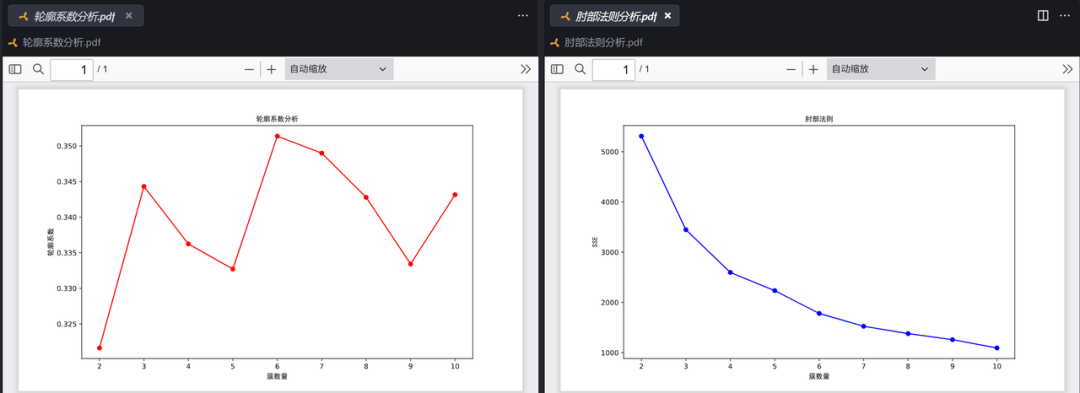
- 轮廓系数分析:轮廓系数越高,聚类效果越好。
- 肘部法则:曲线出现类似 “肘部” 的拐点,该拐点对应的 K 值常被认为是较优的 K 值。
综合得出:K=3 时最优
各簇特征均值:
| Cluster | 学生表现 | 课外活动 | 在家上网时长 | 家庭环境 | 压力水平 | 每晚睡眠时间 | 期末考试分数_Z-score | | --- | --- | --- | --- | --- | --- | --- | --- | | 0 | 0.01 | 0.00 | 6.94 | 0.02 | 5.48 | 6.53 | -0.68 | | 1 | 0.01 | 0.18 | 2.50 | -0.03 | 5.54 | 6.46 | 0.98 | | 2 | -0.03 | 1.00 | 5.93 | 0.02 | 5.36 | 6.43 | -0.34 |
2.2 聚类结果可视化
请帮我对聚类分布可视化
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rcParams # 设置中文字体
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode\_minus'] = False # 添加文件存在性检查
import os
if not os.path.exists('聚类结果.csv'):raise FileNotFoundError('聚类结果.csv 文件未找到') # 读取聚类结果 data = pd.read\_csv('聚类结果.csv') # 创建画布 fig = plt.figure(figsize=(18, 8)) # 3D散点图 ax1 = fig.add\_subplot(121, projection='3d')
scatter = ax1.scatter3D(data['学生表现'], data['家庭环境'], data['cluster'], c=data['cluster'], cmap='viridis', s=50, alpha=0.6)
ax1.set\_xlabel('学生表现', labelpad=12)
ax1.set\_ylabel('家庭环境', labelpad=12)
ax1.set\_zlabel('簇编号', labelpad=12)
ax1.view\_init(25, 35) # 二维密度图 ax2 = fig.add\_subplot(122)
sns.kdeplot(x='学生表现', y='家庭环境', hue='cluster', data=data, palette='viridis', fill=True, alpha=0.5, ax=ax2)
ax2.set\_title('聚类密度分布') # 添加簇中心标记 centers = data.groupby('cluster')[['学生表现','家庭环境']].mean()
ax2.scatter(centers['学生表现'], centers['家庭环境'], s=200, c='red', marker='X', edgecolor='black', label='簇中心')
plt.tight\_layout()
# 在plt.savefig前添加调试语句
print('即将保存图像文件...')
plt.savefig('聚类分布可视化.pdf', dpi=300)
print('文件保存成功!')
plt.close()
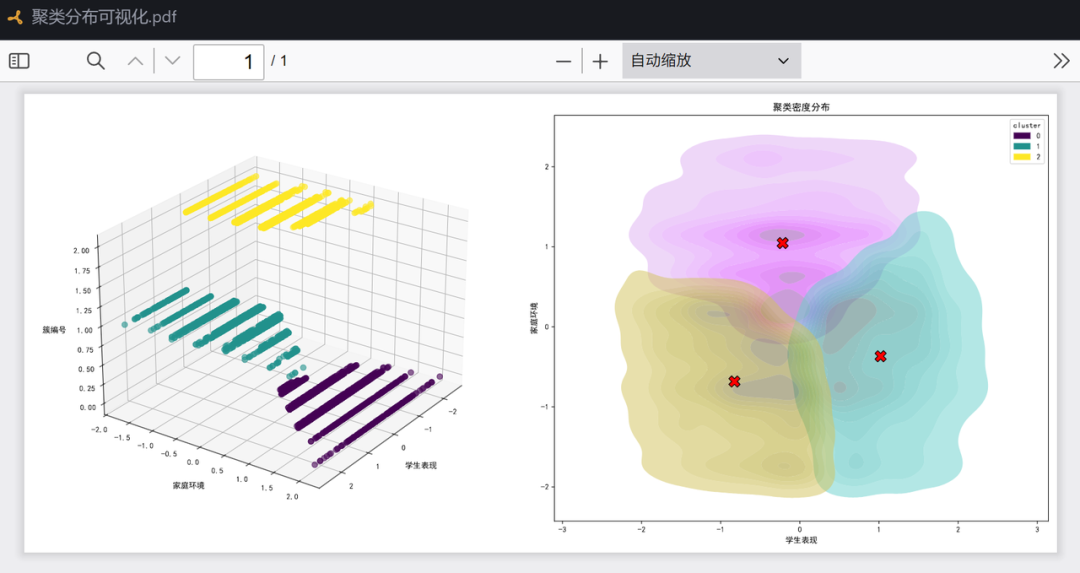
综合结论
- Cluster 0:
- 特征:课外活动参与度为 0.00,几乎不参与;在家上网时长均值达 6.94,显著高于其他簇,网络使用时间长;期末考试分数为-0.68,成绩相对较差。
- 总结:该群体学生上网时间长,课外活动缺乏,学业表现欠佳。
- Cluster 1:
- 特征:在家上网时长仅 2.50,网络使用节制;期末考试分数高达 0.98,成绩优异;其他指标(学生表现、压力水平、睡眠时间等)无显著异常。
- 总结:该群体学生上网时间合理,学业表现突出,整体发展较均衡。
- Cluster 2:
- 特征:课外活动均值为 1.00,参与度最高;但在家上网时长 5.93 也较长;期末考试分数为 -0.34,成绩中等偏下。
- 总结:该群体学生积极参与课外活动,但上网时间较长,可能影响学业表现,导致成绩未达较高水平
3.机器学习预测
3.1 划分训练集和预测集
我之后要进行机器学习预测(先不要生成与这相关的代码),请帮我对引用的数据集以8:2的比例分为训练集和预测集
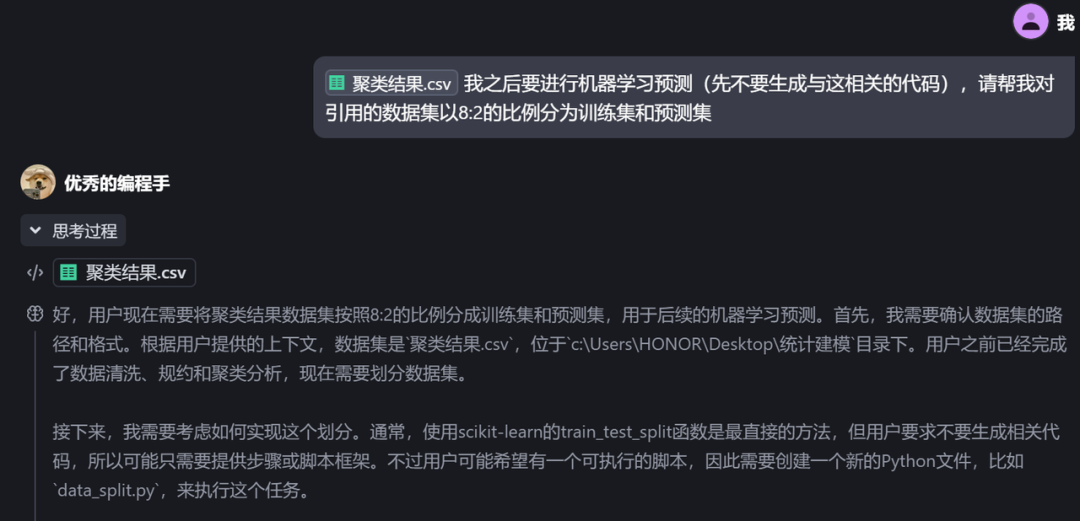
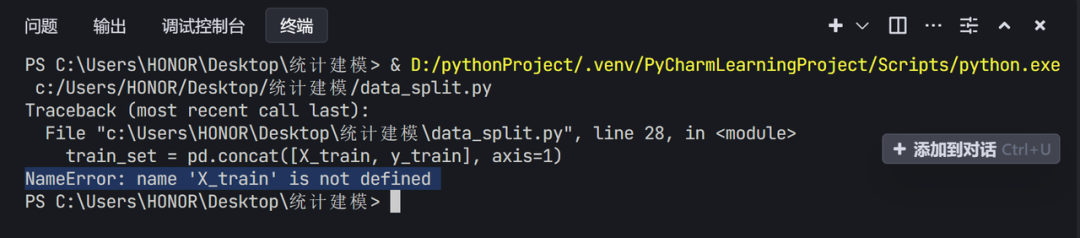
通过运行代码,发现显示错误,如何处理?

复制并点击添加到对话,再询问我们优秀的编程手
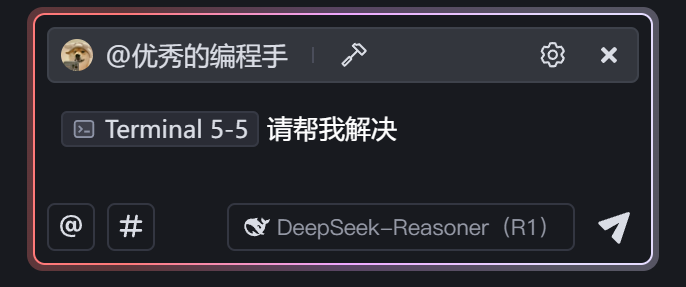
点击全部接受优秀的编程手为我们修改的新代码
得到分割后的数据集

3.2 预测好坏的标准
- R方(R²,决定系数,Coefficient of Determination)

社会科学/行为科学:R²≥0.3 可能已具解释力(如心理学、经济学)
- MSE(均方误差,Mean Squared Error)

- RMSE(均方根误差,Root Mean Squared Error)
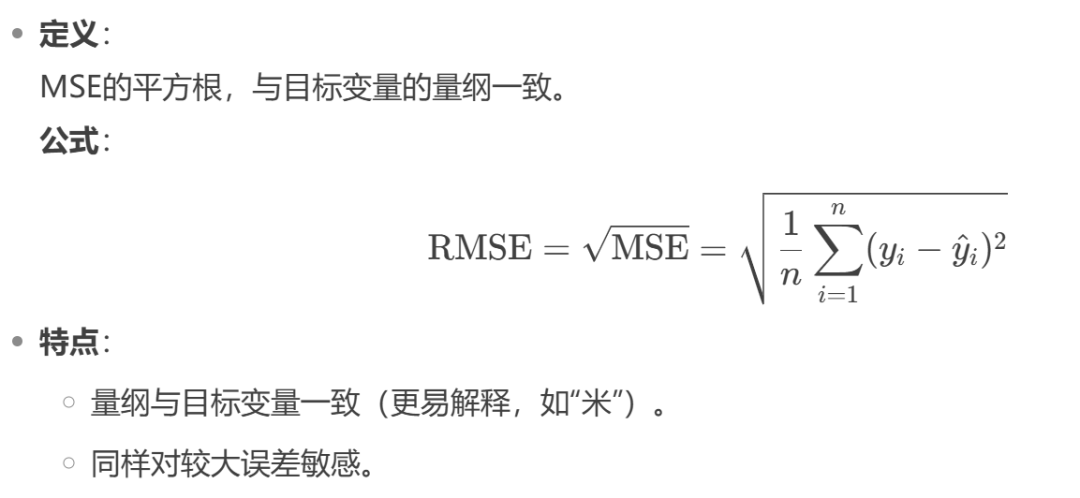
- MAE(平均绝对误差,Mean Absolute Error)

3.3 四种机器学习模型预测各个簇
请帮我以训练集训练线性回归模型,再应用到预测集,以 R²,MSE,RMSE,MAE 进行模型评估,并对结果进行可视化
Linear Regression
from sklearn.linear\_model import LinearRegression
from sklearn.metrics import r2\_score, mean\_squared\_error, mean\_absolute\_error
from sklearn.model\_selection import train\_test\_split
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode\_minus'] = False def evaluate\_linear\_regression(X, y): # 划分训练集和测试集 X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42) # 创建线性回归模型 linear\_model = LinearRegression() linear\_model.fit(X\_train, y\_train) linear\_y\_pred = linear\_model.predict(X\_test) # 计算评价指标 linear\_r2 = r2\_score(y\_test, linear\_y\_pred) linear\_mse = mean\_squared\_error(y\_test, linear\_y\_pred) linear\_rmse = np.sqrt(linear\_mse) linear\_mae = mean\_absolute\_error(y\_test, linear\_y\_pred) # 可视化 plt.scatter(X\_test['学生表现'], y\_test, color='#377780', label='真实值') plt.scatter(X\_test['学生表现'], linear\_y\_pred, color='#6cb9b2', linewidth=3, label='预测值') plt.xlabel('学生表现') plt.ylabel('期末考试分数\_Z-score') plt.title('线性回归模型') plt.legend(loc='best') plt.show() return linear\_r2, linear\_mse, linear\_rmse, linear\_mae
linear\_r2, linear\_mse, linear\_rmse, linear\_mae=evaluate\_linear\_regression(data\_0[X\_columns], data\_0[y\_columns]) print("第一类线性回归评价指标:")
print("R方:", linear\_r2)
print("MSE:", linear\_mse)
print("RMSE:", linear\_rmse)
print("MAE:", linear\_mae) 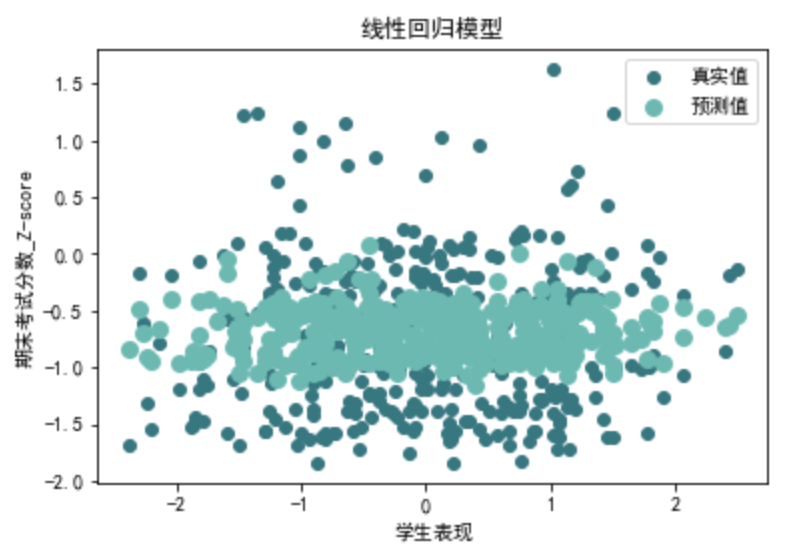
第一类线性回归评价指标:
R方: 0.052313306021179895
MSE: 0.4116677232921512
RMSE: 0.6416133752441194
MAE: 0.4754431704118408
linear\_r2, linear\_mse, linear\_rmse, linear\_mae=evaluate\_linear\_regression(data\_1[X\_columns], data\_1[y\_columns]) print("第二类归评价指标:")
print("R方:", linear\_r2)
print("MSE:", linear\_mse)
print("RMSE:", linear\_rmse)
print("MAE:", linear\_mae)
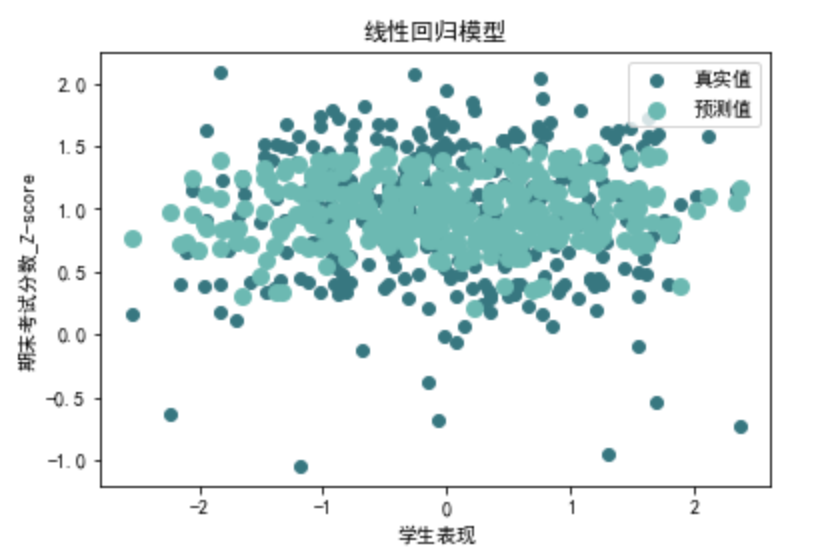
第二类归评价指标:
R方: 0.18787236487141568
MSE: 0.22886537728100378
RMSE: 0.4783987638790508
MAE: 0.34259159398263983
linear\_r2, linear\_mse, linear\_rmse, linear\_mae=evaluate\_linear\_regression(data\_2[X\_columns], data\_2[y\_columns]) print("第三类线性回归评价指标:")
print("R方:", linear\_r2)
print("MSE:", linear\_mse)
print("RMSE:", linear\_rmse)
print("MAE:", linear\_mae)
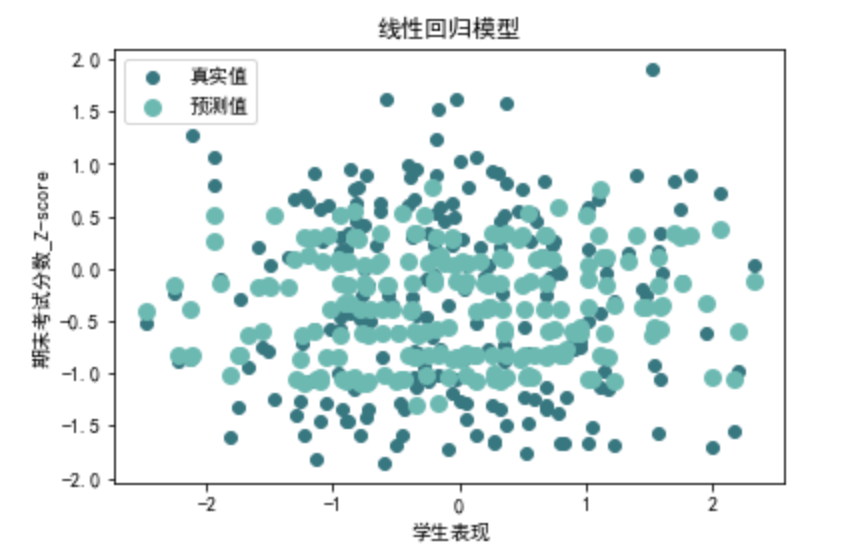
第三类线性回归评价指标:
R方: 0.33029140742275465
MSE: 0.5038322849149164
RMSE: 0.7098114432121508
MAE: 0.48858739787697286
SVR
请帮我以训练集训练支持向量机模型,再应用到预测集,以R²,MSE,RMSE,MAE进行模型评估,并对结果进行可视化
from sklearn.svm import SVR def evaluate\_svr(X, y): # 划分训练集和测试集 X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42) # 创建SVR模型 svr\_model = SVR() svr\_model.fit(X\_train, y\_train) svr\_y\_pred = svr\_model.predict(X\_test) # 可视化 plt.scatter(X\_test['学生表现'], y\_test, color='#377780', label='真实值') plt.scatter(X\_test['学生表现'], svr\_y\_pred, color='#6cb9b2', linewidth=3, label='预测值') plt.xlabel('学生表现') plt.ylabel('期末考试分数\_Z-score') plt.title('支持向量机回归模型') plt.legend(loc='best')plt.show() # 计算评价指标 svr\_r2 = r2\_score(y\_test, svr\_y\_pred) svr\_mse = mean\_squared\_error(y\_test, svr\_y\_pred) svr\_rmse = np.sqrt(svr\_mse) svr\_mae = mean\_absolute\_error(y\_test, svr\_y\_pred) return svr\_r2, svr\_mse, svr\_rmse, svr\_mae svr\_r2, svr\_mse, svr\_rmse, svr\_mae=evaluate\_svr(data\_0[X\_columns], data\_0[y\_columns]) print("第一类支持向量机回归评价指标:")
print("R方:", svr\_r2)
print("MSE:", svr\_mse)
print("RMSE:", svr\_rmse)
print("MAE:", svr\_mae)
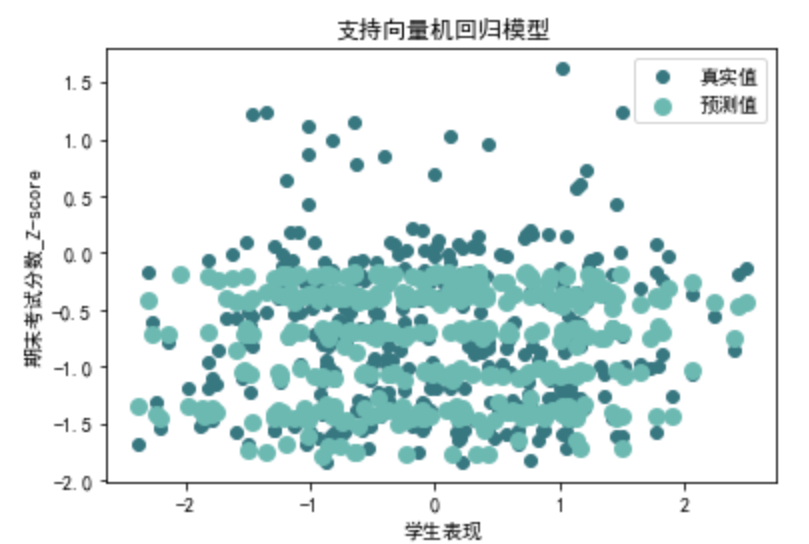
第一类支持向量机回归评价指标:
R方: 0.018635725255404023
MSE: 0.42629700223836836
RMSE: 0.6529142380423085
MAE: 0.3542488707376518
svr\_r2, svr\_mse, svr\_rmse, svr\_mae=evaluate\_svr(data\_1[X\_columns], data\_1[y\_columns]) print("第二类支持向量机回归评价指标:")
print("R方:", svr\_r2)
print("MSE:", svr\_mse)
print("RMSE:", svr\_rmse)
print("MAE:", svr\_mae) 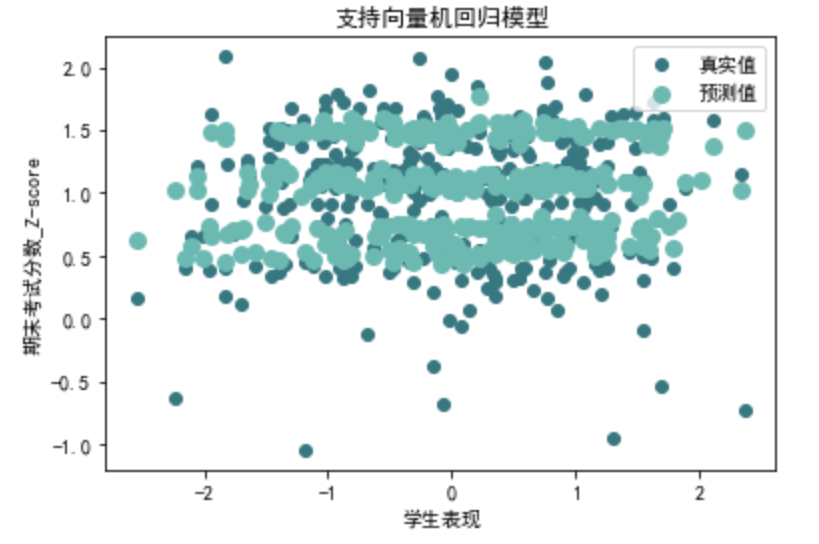
第二类支持向量机回归评价指标:
R方: 0.33950737180934654
MSE: 0.18613317415093483
RMSE: 0.4314315405147552
MAE: 0.24210604831020527
svr\_r2, svr\_mse, svr\_rmse, svr\_mae=evaluate\_svr(data\_2[X\_columns], data\_2[y\_columns]) print("第三类支持向量机回归评价指标:")
print("R方:", svr\_r2)
print("MSE:", svr\_mse)
print("RMSE:", svr\_rmse)
print("MAE:", svr\_mae)
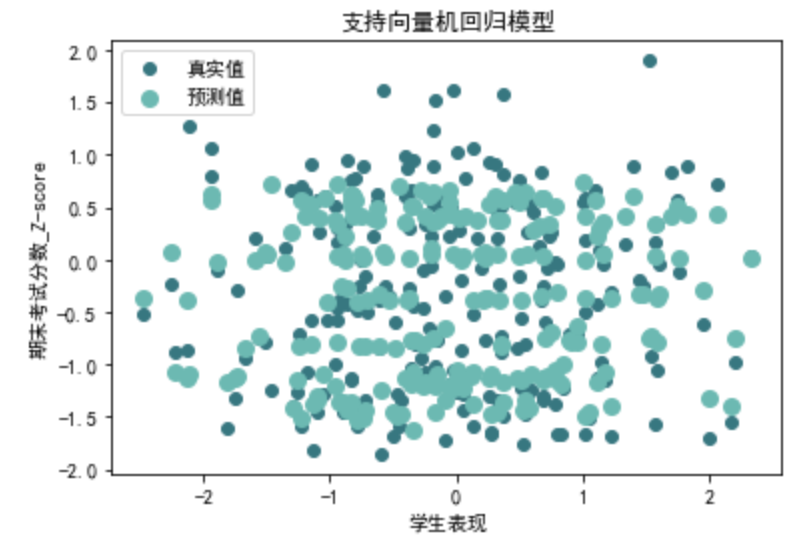
第三类支持向量机回归评价指标:
R方: 0.3236187088877809
MSE: 0.5088522607472206
RMSE: 0.7133388120291931
MAE: 0.40531380542737
决策树回归
请帮我以训练集训练决策树回归模型,再应用到预测集,以R²,MSE,RMSE,MAE进行模型评估,并对结果进行可视化
from sklearn.tree import DecisionTreeRegressor def evaluate\_decision\_tree\_regression(X, y): # 划分训练集和测试集 X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42) # 创建决策树回归模型 tree\_model = DecisionTreeRegressor() tree\_model.fit(X\_train, y\_train) tree\_y\_pred = tree\_model.predict(X\_test) # 可视化 plt.scatter(X\_test['学生表现'], y\_test, color='#377780', label='真实值') plt.scatter(X\_test['学生表现'], tree\_y\_pred, color='#6cb9b2', linewidth=3, label='预测值') plt.xlabel('学生表现') plt.ylabel('期末考试分数\_Z-score') plt.title('决策树回归模型') plt.legend(loc='best')plt.show() # 计算评价指标 tree\_r2 = r2\_score(y\_test, tree\_y\_pred) tree\_mse = mean\_squared\_error(y\_test, tree\_y\_pred) tree\_rmse = np.sqrt(tree\_mse) tree\_mae = mean\_absolute\_error(y\_test, tree\_y\_pred) return tree\_r2, tree\_mse, tree\_rmse, tree\_mae tree\_r2, tree\_mse, tree\_rmse, tree\_mae=evaluate\_decision\_tree\_regression(data\_0[X\_columns], data\_0[y\_columns]) print("第一类决策树回归评价指标:")
print("R方:", tree\_r2)
print("MSE:", tree\_mse)
print("RMSE:", tree\_rmse)
print("MAE:", tree\_mae)
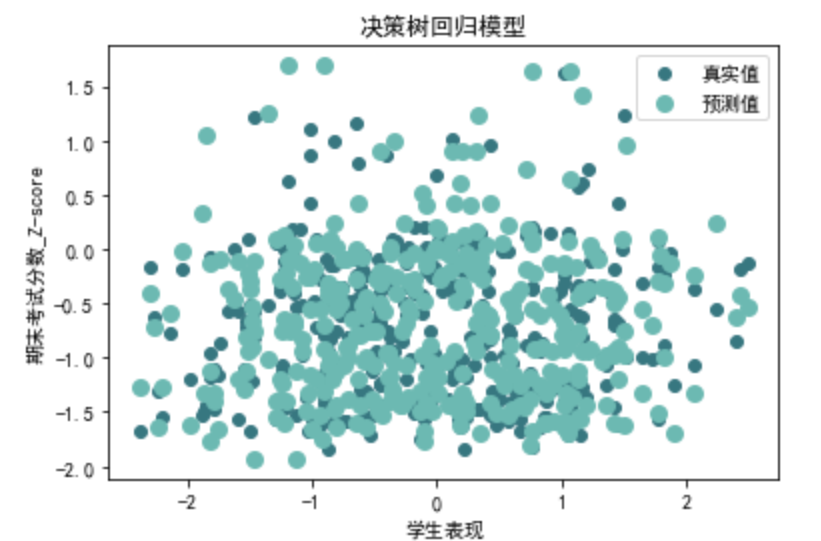
第一类决策树回归评价指标:
R方: -0.19417976710257512
MSE: 0.5187423956125053
RMSE: 0.7202377354821846
MAE: 0.42478555775111204
tree\_r2, tree\_mse, tree\_rmse, tree\_mae=evaluate\_decision\_tree\_regression(data\_1[X\_columns], data\_1[y\_columns]) print("第二类决策树回归评价指标:")
print("R方:", tree\_r2)
print("MSE:", tree\_mse)
print("RMSE:", tree\_rmse)
print("MAE:", tree\_mae) 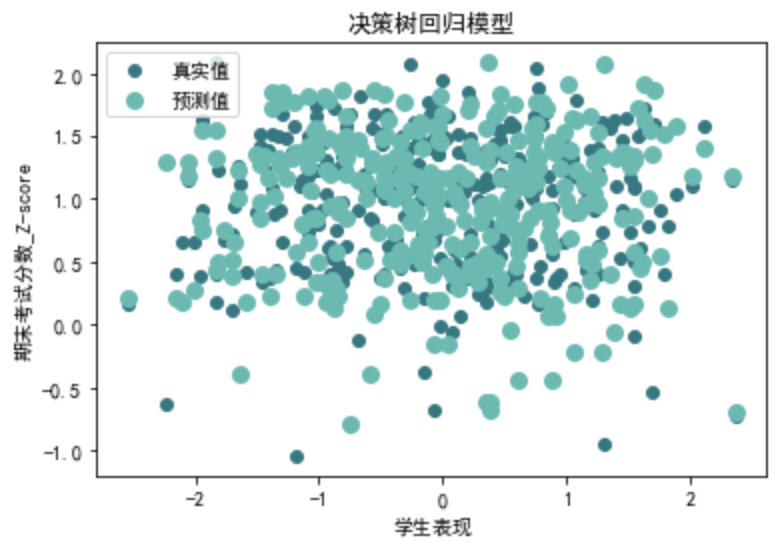
第二类决策树回归评价指标:
R方: -0.36204642938058607
MSE: 0.38383778171158567
RMSE: 0.6195464322482905
MAE: 0.39287969481893664
tree\_r2, tree\_mse, tree\_rmse, tree\_mae=evaluate\_decision\_tree\_regression(data\_2[X\_columns], data\_2[y\_columns]) print("第三类决策树回归评价指标:")
print("R方:", tree\_r2)
print("MSE:", tree\_mse)
print("RMSE:", tree\_rmse)
print("MAE:", tree\_mae) 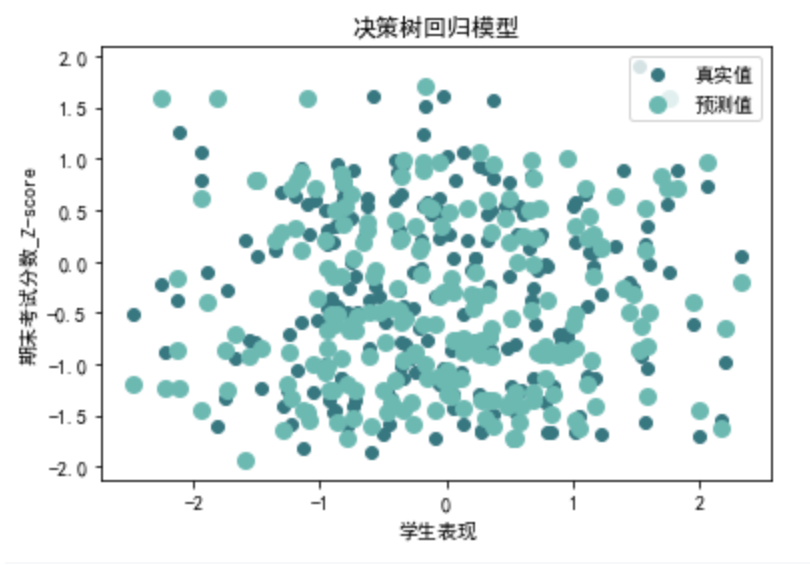
第三类决策树回归评价指标:
R方: 0.05903792770110261
MSE: 0.7079005348881591
RMSE: 0.8413682516521283
MAE: 0.5317689746463753
XGBoost
请帮我以训练集训练XGBoost模型,再应用到预测集,以R²,MSE,RMSE,MAE进行模型评估,并对结果进行可视化
import xgboost as xgb def evaluate\_xgboost\_regression(X, y): # 划分训练集和测试集 X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42) # 将数据转换为DMatrix格式 dtrain = xgb.DMatrix(X\_train, label=y\_train) dtest = xgb.DMatrix(X\_test, label=y\_test) # 设置XGBoost模型参数 params = {'objective':'reg:squarederror','eval\_metric': 'rmse'} # 训练模型 num\_round = 100 # 迭代次数 bst = xgb.train(params, dtrain, num\_round) # 进行预测 xgb\_y\_pred = bst.predict(dtest) # 可视化 plt.scatter(X\_test['学生表现'], y\_test, color='#377780', label='真实值') plt.scatter(X\_test['学生表现'], xgb\_y\_pred, color='#6cb9b2', linewidth=3, label='预测值') plt.xlabel('学生表现') plt.ylabel('期末考试分数\_Z-score') plt.title('XGBoost模型') plt.legend(loc='best')plt.show() # 计算评价指标 xgb\_r2 = r2\_score(y\_test, xgb\_y\_pred) xgb\_mse = mean\_squared\_error(y\_test, xgb\_y\_pred) xgb\_rmse = np.sqrt(xgb\_mse) xgb\_mae = mean\_absolute\_error(y\_test, xgb\_y\_pred) return xgb\_r2, xgb\_mse, xgb\_rmse, xgb\_mae xgb\_r2, xgb\_mse, xgb\_rmse, xgb\_mae=evaluate\_xgboost\_regression(data\_0[X\_columns], data\_0[y\_columns]) print("第一类XGBoost回归评价指标:")
print("R方:", xgb\_r2)
print("MSE:", xgb\_mse)
print("RMSE:", xgb\_rmse)
print("MAE:", xgb\_mae)
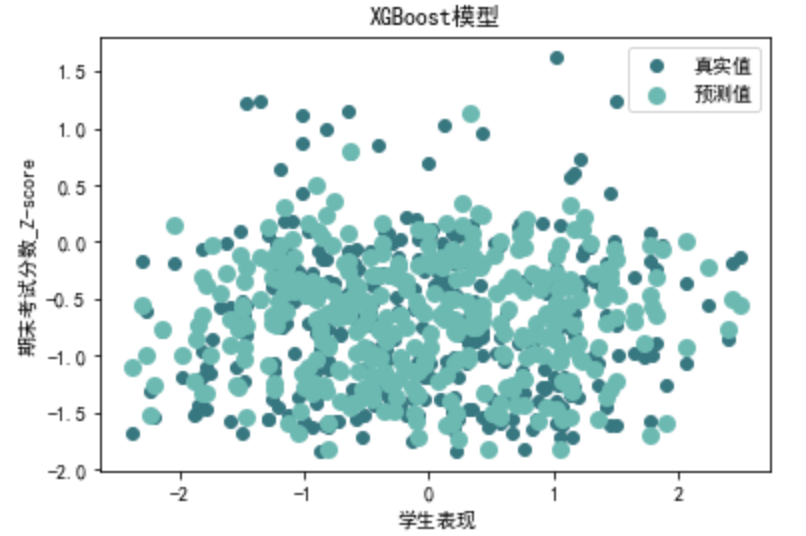
第一类XGBoost回归评价指标:
R方: 0.22881221639057459
MSE: 0.33499797045404917
RMSE: 0.5787900918761906
MAE: 0.3856788738384498
xgb\_r2, xgb\_mse, xgb\_rmse, xgb\_mae=evaluate\_xgboost\_regression(data\_1[X\_columns], data\_1[y\_columns]) print("第二类XGBoost回归评价指标:")
print("R方:", xgb\_r2)
print("MSE:", xgb\_mse)
print("RMSE:", xgb\_rmse)
print("MAE:", xgb\_mae)
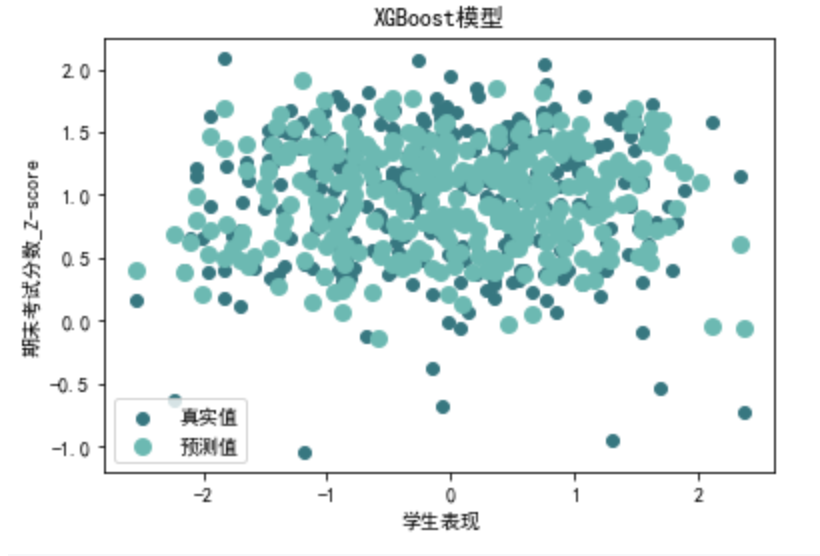
第二类XGBoost回归评价指标:
R方: 0.21170690318163787
MSE: 0.22214857518397393
RMSE: 0.47132639983770686
MAE: 0.3187216242504202
xgb\_r2, xgb\_mse, xgb\_rmse, xgb\_mae=evaluate\_xgboost\_regression(data\_2[X\_columns], data\_2[y\_columns]) print("第三类XGBoost回归评价指标:")
print("R方:", xgb\_r2)
print("MSE:", xgb\_mse)
print("RMSE:", xgb\_rmse)
print("MAE:", xgb\_mae)
第三类XGBoost回归评价指标:
R方: 0.3278772911234198
MSE: 0.5056484624951733
RMSE: 0.7110896304230383
MAE: 0.46366938642346056
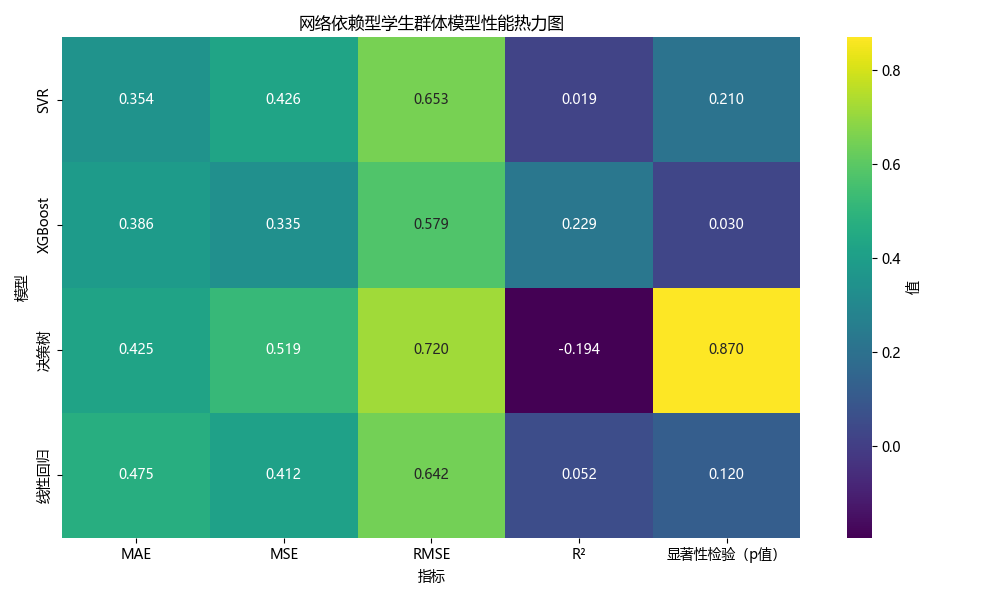
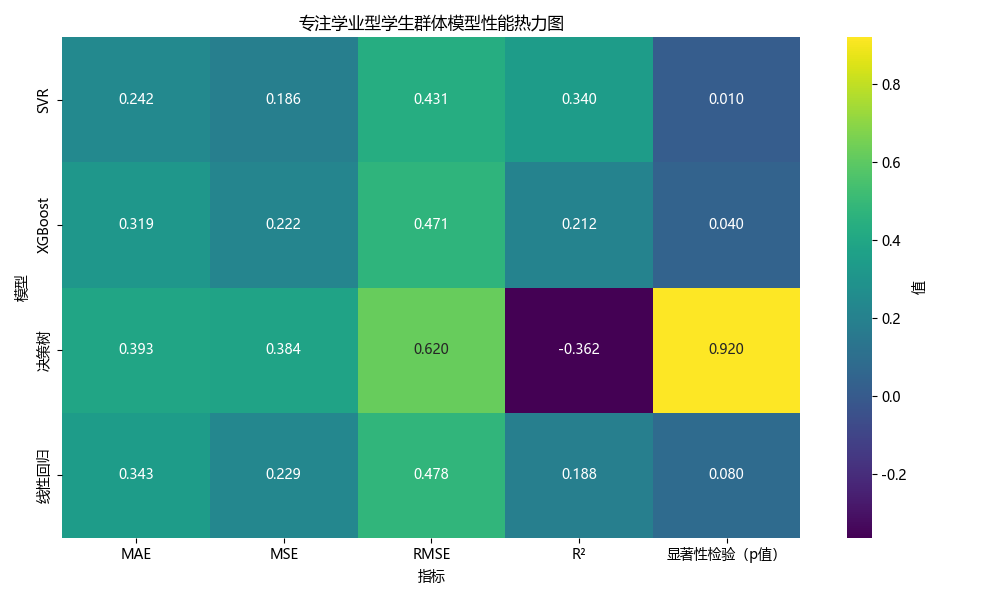
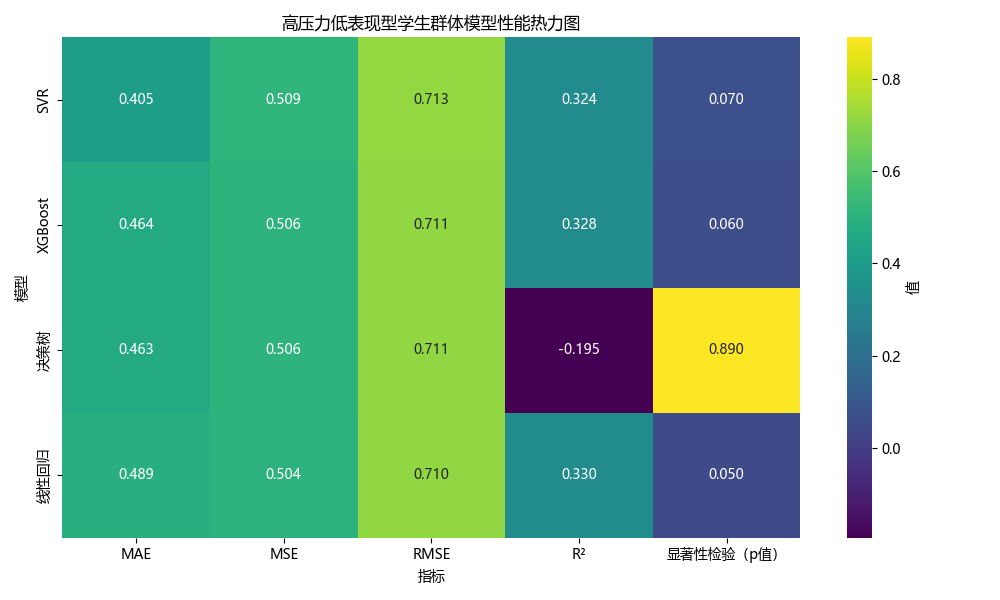
不同模型在各学生群体中的预测性能对比
上述四个模型对三种学生群体进行了预测,并分别得出了回归评价指标
| 学生群体 | 模型 | R² | MSE | RMSE | MAE | 显著性检验(p值) | | --- | --- | --- | --- | --- | --- | --- | | 网络依赖型 | 线性回归 | 0.052 | 0.412 | 0.642 | 0.475 | 0.12 | |
| SVR | 0.019 | 0.426 | 0.653 | 0.354 | 0.21 | |
| 决策树 | -0.194 | 0.519 | 0.720 | 0.425 | 0.87 | |
| XGBoost | 0.229 | 0.335 | 0.579 | 0.386 | 0.03 | | 专注学业型 | 线性回归 | 0.188 | 0.229 | 0.478 | 0.343 | 0.08 | |
| SVR | 0.340 | 0.186 | 0.431 | 0.242 | 0.01 | |
| 决策树 | -0.362 | 0.384 | 0.620 | 0.393 | 0.92 | |
| XGBoost | 0.212 | 0.222 | 0.471 | 0.319 | 0.04 | | 高压力低表现型 | 线性回归 | 0.330 | 0.504 | 0.710 | 0.489 | 0.05 | |
| SVR | 0.324 | 0.509 | 0.713 | 0.405 | 0.07 | |
| 决策树 | -0.195 | 0.506 | 0.711 | 0.463 | 0.89 | |
| XGBoost | 0.328 | 0.506 | 0.711 | 0.464 | 0.06 |
如果只是以表的形式不太直观,我们可以考虑以可视化的形式
请帮我对上述四个模型对三种学生群体进行预测的模型评价指标进行热力图可视化