分布式系统全链路监控之一:分布式全链路监控基础概念和OpenTelemetry
文章目录
- 前言
- 什么是OpenTelemetry
- 核心概念
- 可观测性
- 可靠性和指标
- 理解分布式链路追踪
- 日志
- 跨度
- 链路
- 上下文传播
- 上下文
- 传播
- 信号
- 日志
- OTel日志
- 在 OTel Collector 中的 OTel日志
- 应用程序的OTel日志
- 结构化、非结构化和半结构化日志
- 结构化日志
- 非结构化日志
- 半结构化日志
- OTel日志组件
- 指标
- 指标提供器
- 指标导出器
- 指标仪器
- 聚合
- 视图
- 链路
- 链路提供器
- 链路导出器
- 上下文传播
- 跨度
- 跨度上下文
- 属性
- 跨度事件
- 跨度链接
- 跨度状态
- 跨度种类
- 上下文携带的数据
- 示例
- OTel Baggage 的用途
- 安全注意
- Baggage 与 Attributes 不同
- 监控埋点
- 资源
- 监控范围
- 采样
- 采样的重要性
- 头采样
- 尾采样
前言
官方文档
什么是OpenTelemetry
OpenTelemetry(简称 OTel)是一个开源、与厂商无关的可观测性框架,用于对系统进行埋点、生成、收集并导出追踪、指标和日志等遥测数据。作为业界标准,OpenTelemetry 得到了 40 多家可观测性厂商的支持,广泛集成于各类库、服务和应用中,并被众多用户采用。
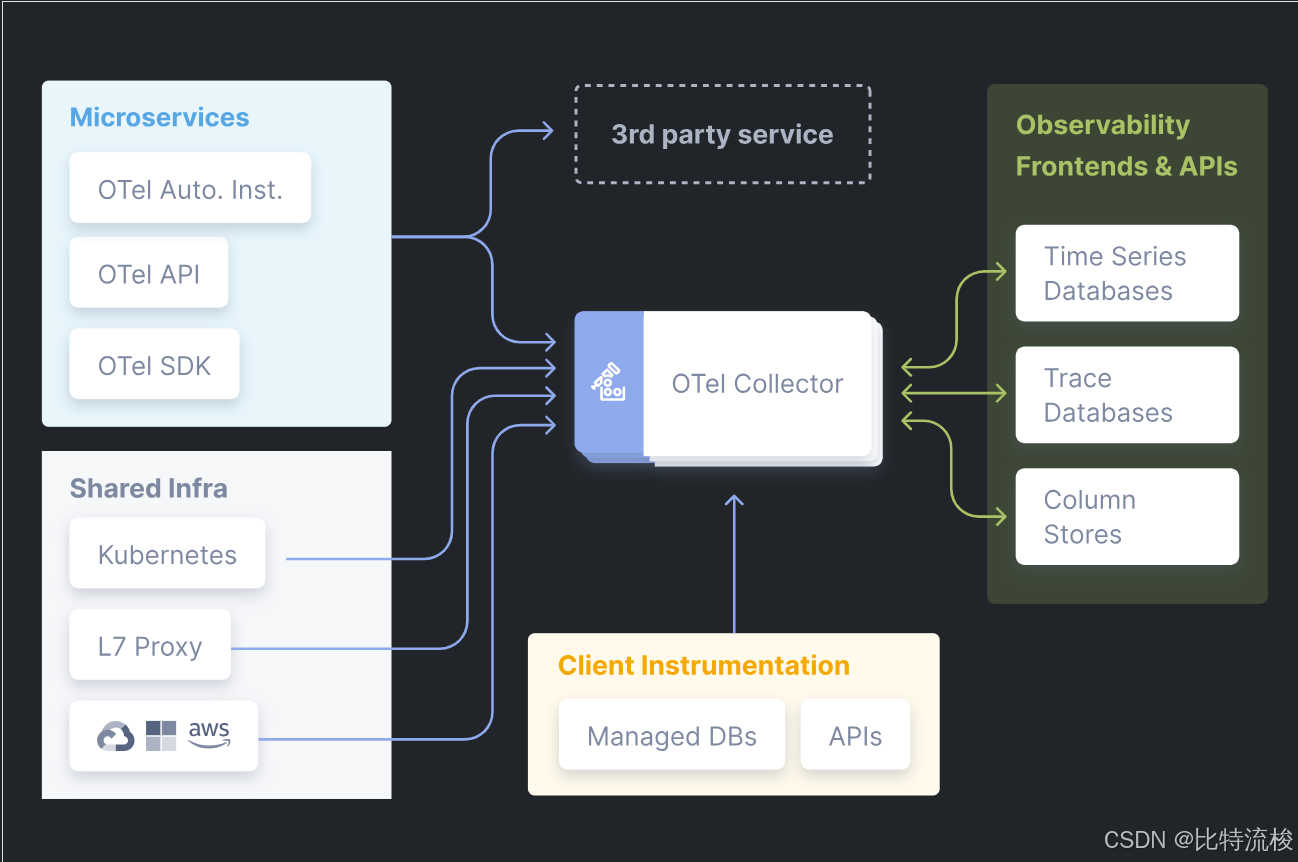
核心概念
可观测性
可观测性是一种从系统外部理解系统的方法,它允许你在不了解内部细节的情况下提出问题,并能排查未知问题(即“未知的未知”)。它还能帮助你回答“为什么会发生这个问题?”。
要实现这些能力,应用需要进行正确的埋点,也就是让代码主动生成追踪(traces)、指标(metrics)和日志(logs)等信号。只有当应用已经具备足够的这些信号,开发者在排查问题时无需再补充埋点,才算埋点完善。
OTel就是用于给应用代码做这些埋点的工具,从而让系统具备可观测性。
可靠性和指标
- 遥测:指的是系统及其行为发出的数据,主要包括 追踪(traces)、指标(metrics) 和 日志(logs)。
- 可靠性*:回答的问题是:“这个服务是否按用户期望工作?”即使系统始终在线,如果用户点击“加入购物车”时并不总是正确添加了黑色鞋子,那它依然是不可靠的。
- 指标:是对系统或应用在一段时间内的数值数据汇总,例如系统错误率、CPU 使用率、某服务的请求速率等。OTel可以用于采集和导出这些指标。
- SLI:是对服务行为的量化衡量,最好从用户视角出发,比如网页加载时间。
- SLO:是组织或团队间用于传达服务可靠性的方式,通常通过将一个或多个 SLI 绑定到业务价值上来实现。
理解分布式链路追踪
分布式追踪可以让你观察请求在复杂的分布式系统中的传播过程。它能提升系统运行状况的可见性,帮助你排查那些本地难以复现的问题。对于问题具有非确定性或结构复杂、难以复现的分布式系统来说,分布式追踪是必不可少的。
要理解分布式追踪,首先需要了解它的几个核心组成部分:
- 日志(Logs):记录系统中发生的事件,提供上下文信息。
- 跨度(Spans):表示一次操作的时间片段,包含开始时间、持续时间和元数据,是追踪的基本单位。
- 链路(Traces):由多个相关的 span 组成,表示一次完整的请求链路,跨越多个服务或组件。
日志
日志是服务或组件输出的带有时间戳的消息。与追踪不同,日志不一定关联某个具体的用户请求或事务,几乎在所有软件中都能看到。
I, [2021-02-23T13:26:23.505892 #22473] INFO -- : [6459ffe1-ea53-4044-aaa3-bf902868f730] Started GET "/" for ::1 at 2021-02-23 13:26:23 -0800
日志一直是开发和运维理解系统行为的重要工具,但日志本身往往缺乏上下文信息(比如它在哪段代码中产生的),因此难以完整追踪代码执行过程。当日志被关联到某个 Span 或 Trace 中时,它的价值会大大提升,能提供更完整的调用上下文。
跨度
跨度表示一个具体的操作或工作单元。它用于记录某个请求执行过程中的一个操作,帮助还原该操作发生时的具体情况。一个 Span 包含以下信息:
- 名称:标识操作的类型或名称(如 HTTP GET /users)
- 时间数据:开始时间和持续时间
- 结构化日志:操作过程中记录的日志信息
- 元数据(Attributes):如状态码、方法名、线程信息等,用于补充描述这个操作的上下文
通过多个 Span 的组合,可以构建出完整的请求链路(Trace)。
链路
分布式链路记录了请求(来自用户或应用)在多服务架构中(如微服务或无服务器架构)传播的路径。一个 Trace 由一个或多个 Span 组成:
- 第一个 Span 是根 Span,代表整个请求的起点和生命周期。
- 其下的子 Span 描述请求过程中各个步骤的详细信息,提供更丰富的上下文。
没有链路,定位分布式系统中的性能瓶颈会非常困难。追踪通过将请求流程拆解成多个可观察的步骤,使调试和理解分布式系统变得更简单、更直观。很多可观测性平台会将 Trace 可视化为 瀑布图,清晰展现请求的执行顺序与耗时:
瀑布图展示了根 Span 与其子 Span 之间的父子关系。当一个 Span 包含另一个 Span 时,表示两者存在嵌套关系。
上下文传播
通过上下文传播(context propagation),不同位置生成的信号可以互相关联。虽然上下文传播不限于追踪,但它使得追踪能够跨进程和网络边界,在分布式服务间建立因果关系。要理解上下文传播,需先理解两个核心概念:上下文(context) 和传播(propagation)。
上下文
上下文是一个对象,包含发送方和接收方服务(或执行单元)用于关联信号的信息。例如:如果服务 A 调用服务 B,A 中的 Span 会将其 Span ID 和 Trace ID 传递到上下文中。服务 B 接收到这个上下文后,创建的新 Span 会:
- 以 A 的 Span 作为父级 Span
- 使用相同的 Trace ID,从而将两者归入同一条追踪链(Trace)
这样,不同服务间的操作就可以被串联起来,形成完整的请求链路。
传播
传播是一种在服务或进程之间传递上下文的机制。它会对上下文对象进行序列化和反序列化,使关键信息能够从一个服务传递到另一个服务。传播通常由自动埋点库负责,用户无需手动干预。但在需要手动传递上下文的情况下,可以使用 OTel 的 Propagators API。OTel提供了多个官方传播器,默认使用的是基于 W3C TraceContext 规范 的 HTTP 请求头格式。
信号
OpenTelemetry 的目标是采集、处理并导出信号(signals)。信号是操作系统和应用程序的输出,用于描述其内部活动。它可以是某个时刻你希望监测的指标(如温度、内存使用),也可以是分布式系统中流经各组件的事件(用于追踪)。通过将不同类型的信号组合在一起,可以从多个角度观察同一个系统的内部运行状态。目前 OTel支持以下信号类型:
- Traces(链路)
- Metrics(指标)
- Logs(日志)
- Baggage(上下文携带的数据)
正在开发或提出中的包括:
- Events(事件):一种特殊类型的日志
- Profiles(性能剖析):由 Profiling 工作组推进中
日志
日志是一种带时间戳的文本记录,可以是结构化(推荐)或非结构化的,并可附带元数据。在所有遥测信号中,日志历史最悠久。几乎所有编程语言都内建日志功能,或有广泛使用的第三方日志库。
OTel日志
OTel并不定义专门的日志 API 或 SDK。相反,OTel日志指的就是你现有的日志——来自现有日志框架或系统组件的输出。OTel的 SDK 和自动埋点工具会使用一些组件,自动将日志与追踪进行关联。其日志支持的设计目标是:与现有日志系统完全兼容,并提供以下能力:
- 给现有日志添加上下文信息(如 trace ID、span ID)
- 提供统一工具,将来自不同来源的日志解析并转换为统一格式,便于集中处理和分析
在 OTel Collector 中的 OTel日志
OTel Collector 提供了一套强大工具来处理日志数据:
- 接收器(Receivers):支持从特定的日志来源中解析日志。
- filelogreceiver:可从任意文件读取日志,并支持多种格式解析或使用正则表达式提取内容。
- 处理器(Processors):如
transformprocessor,可用于解析嵌套数据、扁平化结构、添加/删除/修改字段等。 - 导出器(Exporters):支持将日志以非 OpenTelemetry 格式输出,便于对接现有系统。
实际使用中,部署 Collector 作为通用日志代理,通常是引入 OTel的第一步。
应用程序的OTel日志
在应用中,OTel的日志是通过任何日志库或内置日志功能产生的。开启自动埋点或激活 SDK 后,OTel会自动将现有日志与当前活跃的 Trace 和 Span 关联起来,并在日志内容中附加它们的 ID。换句话说,OTel会自动帮你关联日志和追踪信息。
结构化、非结构化和半结构化日志
OTel 技术上不区分结构化日志和非结构化日志,你可以使用任何类型的日志。但并非所有日志格式的价值一样高!尤其推荐在生产环境使用结构化日志,因为它们便于大规模解析和分析。下面将介绍结构化、非结构化和半结构化日志的区别。
结构化日志
结构化日志是指采用一致且机器可读格式的日志文本。常见格式包括:
- 应用层日志:多采用 JSON 格式,例如:
{"timestamp": "2024-08-04T12:34:56.789Z","level": "INFO","service": "user-authentication","environment": "production","message": "User login successful","context": {"userId": "12345","username": "johndoe","ipAddress": "192.168.1.1","userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36..."},"transactionId": "abcd-efgh-ijkl-mnop","duration": 200,"request": {"method": "POST","url": "/api/v1/login","headers": {"Content-Type": "application/json","Accept": "application/json"},"body": {"username": "johndoe","password": "******"}},"response": {"statusCode": 200,"body": {"success": true,"token": "jwt-token-here"}}
}
- 基础设施日志:常见格式是 Common Log Format (CLF),如:
127.0.0.1 - johndoe [04/Aug/2024:12:34:56 -0400] "POST /api/v1/login HTTP/1.1" 200 1234
还有混合格式,比如 Extended Log Format (ELF),它会把 JSON 与 CLF 的空格分隔数据结合:
192.168.1.1 - johndoe [04/Aug/2024:12:34:56 -0400] "POST /api/v1/login HTTP/1.1" 200 1234 "http://example.com" "Mozilla/5.0 ..." {"transactionId": "abcd-efgh-ijkl-mnop", "responseTime": 150, "requestBody": {"username": "johndoe"}, "responseHeaders": {"Content-Type": "application/json"}}
为了高效利用此类日志,需同时解析 JSON 与 ELF 相关部分,将它们转换为统一格式,便于后续在观测平台分析。OTel Collector 的 filelogreceiver 支持标准化解析这类日志。结构化日志是首选,因为它们格式统一,解析简单,方便在 Collector 中预处理,便于与其他数据关联,最终利于在观测后台深入分析。
非结构化日志
非结构化日志指没有固定格式的日志,通常更便于人类阅读,常见于开发阶段。但在生产环境的观测中不推荐使用,因为它们难以大规模解析和分析。示例:
[ERROR] 2024-08-04 12:45:23 - Failed to connect to database. Exception: java.sql.SQLException: Timeout expired. Attempted reconnect 3 times. Server: db.example.com, Port: 5432System reboot initiated at 2024-08-04 03:00:00 by user: admin. Reason: Scheduled maintenance. Services stopped: web-server, database, cache. Estimated downtime: 15 minutes.DEBUG - 2024-08-04 09:30:15 - User johndoe performed action: file_upload. Filename: report_Q3_2024.pdf, Size: 2.3 MB, Duration: 5.2 seconds. Result: Success
虽然非结构化日志能用于生产,但通常需要大量正则表达式和自定义解析器,来提取时间戳和日志内容,才能让日志系统正确排序和管理。相较之下,采用结构化日志会更高效,减少解析复杂度。
半结构化日志
半结构化日志使用一定的固定模式来区分数据,使其可被机器读取,但不同系统之间的格式和分隔符可能不统一。示例:
2024-08-04T12:45:23Z level=ERROR service=user-authentication userId=12345 action=login message="Failed login attempt" error="Invalid password" ipAddress=192.168.1.1 userAgent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
虽然可被机器读取,但半结构化日志通常需要多种解析器才能支持大规模分析。
OTel日志组件
以下是 OpenTelemetry 日志支持的关键概念和组件:
- 日志追加器 / 桥接器
- 面向日志库作者,用于构建日志追加器或桥接器,普通开发者无需直接调用。
- 你只需使用喜欢的日志库,并配置一个能输出到 OTel
LogRecordExporter的追加器。 - OTel 各语言 SDK 提供了相关功能。
- Logger Provider(日志提供者)
- Logs Bridge API 的一部分,仅供日志库作者使用。
- 是 Logger 的工厂,通常初始化一次,生命周期与应用一致。初始化时会配置资源和导出器。
- Logger(日志记录器)
- Logs Bridge API 的一部分,仅供日志库作者使用。
- 由 Logger Provider 创建,用于生成日志记录。
- Log Record Exporter(日志记录导出器)
- 负责将日志记录发送给消费者,消费者可以是调试时的标准输出、OTel Collector,或任意开源/厂商后端。
- Log Record(日志记录)
- 表示一次事件的记录,包含两类字段:
- 顶层具名字段(有具体类型和含义)
- 资源和属性字段(任意类型和值)
- 表示一次事件的记录,包含两类字段:
顶层字段说明:
| 字段名 | 含义 |
|---|---|
| Timestamp | 事件发生时间 |
| ObservedTimestamp | 事件被观测时间 |
| TraceId | 请求的 Trace ID |
| SpanId | 请求的 Span ID |
| TraceFlags | W3C 追踪标志 |
| SeverityText | 严重级别文本(日志等级) |
| SeverityNumber | 严重级别数值 |
| Body | 日志正文 |
| Resource | 日志来源描述 |
| InstrumentationScope | 产生日志的作用域描述 |
| Attributes | 事件的额外信息 |
指标
Metrics(指标)是运行时捕获的测量值。捕获指标的时刻称为指标事件,不仅包含测量的数值,还包括捕获时间和相关的元数据。指标对于服务的可用性和性能监控非常关键:
- 应用指标和请求指标能反映系统的运行状态。
- 自定义指标帮助洞察可用性如何影响用户体验和业务。
- 收集的指标数据可以用于触发告警,或者自动触发扩缩容等调度决策。
指标提供器
Meter Provider是用于创建 Meter 的工厂。
- 在大多数应用中,Meter Provider 通常只初始化一次,其生命周期与应用程序的生命周期相同。
- 初始化 Meter Provider 时,也会一并初始化 Resource(资源信息)和 Exporter(导出器)。
- 这通常是使用 OTel 进行指标采集的第一步。
- 在某些语言的 SDK 中,已经为你初始化了一个全局的 Meter Provider,方便直接使用。
简单来说,Meter Provider 是指标采集的入口,负责管理和提供具体的 Meter 实例,用于采集和记录指标数据。
指标导出器
Metric Exporters(指标导出器)负责将收集到的指标数据发送给消费者。这个消费者可以是:
- 开发时用于调试的标准输出(比如控制台),
- OTel Collector,
- 或者任何你选择的开源或商业的后端系统。
简单来说,指标导出器就是把数据“搬运”到你想要分析或存储的地方。
指标仪器
在 OTel 中,测量值是由指标仪器捕获的。一个指标仪器由以下几个部分定义:
- 名称
- 类型(Kind)
- 单位(可选)
- 描述(可选)
名称、单位和描述通常由开发者选择,或者对于常见指标(比如请求数、进程指标)采用语义约定来定义。指标仪器的类型包括以下几种:
- 计数器(Counter):一个随时间累积的数值——可以把它想象成汽车的里程表,只会递增,不会减少。
- 异步计数器(Asynchronous Counter):与计数器类似,但每次导出时采集一次。适合没有连续增量数据,只能获得聚合值的情况。
- 增减计数器(UpDownCounter):一个随时间累积但也可以减少的数值。例如队列长度,随着队列中工作项的增加或减少而变化。
- 异步增减计数器(Asynchronous UpDownCounter):类似于增减计数器,每次导出时采集一次。适合没有连续变化数据,只能获得聚合值的情况(例如当前队列大小)。
- 仪表(Gauge):测量读取时的当前值。例如车辆上的油量表。仪表是同步的。
- 异步仪表(Asynchronous Gauge):类似于仪表,但每次导出时采集一次。适合没有连续变化数据,只能获得聚合值的情况。
- 直方图(Histogram):客户端聚合值的统计,比如请求延迟分布。如果你关心数值的统计情况,直方图是一个不错的选择。例如:有多少请求耗时少于 1 秒?
聚合
除了指标仪器,聚合的概念也是非常重要的。聚合是一种技术,它将大量的测量值合并为关于某个时间窗口内发生的指标事件的精确或估算统计数据。OTLP 协议负责传输这些聚合后的指标数据。OTel API 为每种指标仪器提供了默认的聚合方式,但你可以通过视图功能进行覆盖。OTel 项目的目标是提供被可视化工具和遥测后端广泛支持的默认聚合方式。与用于捕捉请求生命周期、提供请求各个环节上下文的请求追踪不同,指标主要用于提供汇总的统计信息。以下是一些指标的典型使用场景:
- 按协议类型统计服务读取的总字节数。
- 报告读取的总字节数以及每个请求的字节数。
- 报告系统调用的持续时间。
- 报告请求大小,以识别趋势。
- 报告进程的 CPU 或内存使用情况。
- 报告账户的平均余额值。
- 报告当前处理的活跃请求数。
视图
视图(View)为 SDK 用户提供了灵活性,允许他们自定义 SDK 输出的指标数据。通过视图,你可以:
- 自定义哪些指标仪器(Metric Instruments)需要被处理或忽略。
- 自定义指标的聚合方式。
- 自定义你希望在指标中报告哪些属性(Attributes)。
简单来说,视图就像一个过滤器和转换器,帮助你根据需求调整和优化指标的收集与输出内容。
链路
链路让我们看到请求发出后发生了什么整体情况。无论你的应用是单体结构只有一个数据库,还是由多个复杂服务组成的服务网格,链路都是理解请求在应用中“完整路径”的关键。下面,我们用三个工作单元(Span)来具体说明:
- hello span:
{"name": "hello","context": {"trace_id": "5b8aa5a2d2c872e8321cf37308d69df2","span_id": "051581bf3cb55c13"},"parent_id": null,"start_time": "2022-04-29T18:52:58.114201Z","end_time": "2022-04-29T18:52:58.114687Z","attributes": {"http.route": "some_route1"},"events": [{"name": "Guten Tag!","timestamp": "2022-04-29T18:52:58.114561Z","attributes": {"event_attributes": 1}}]
}
这是根 Span,表示整个操作的开始和结束。注意它包含 trace_id 字段,用于表示它属于哪个 Trace,但没有 parent_id,这就是我们知道它是根 Span 的原因。
- hello-greetings span:
{"name": "hello-greetings","context": {"trace_id": "5b8aa5a2d2c872e8321cf37308d69df2","span_id": "5fb397be34d26b51"},"parent_id": "051581bf3cb55c13","start_time": "2022-04-29T18:52:58.114304Z","end_time": "2022-04-29T22:52:58.114561Z","attributes": {"http.route": "some_route2"},"events": [{"name": "hey there!","timestamp": "2022-04-29T18:52:58.114561Z","attributes": {"event_attributes": 1}},{"name": "bye now!","timestamp": "2022-04-29T18:52:58.114585Z","attributes": {"event_attributes": 1}}]
}
这个 Span 封装了一个特定的任务,比如打招呼。它的父级是 hello span。注意它和根 Span 有相同的 trace_id,表示它属于同一个 Trace。同时,它的 parent_id 与 hello 的 span_id 一致。
- hello-salutations span:
{"name": "hello-salutations","context": {"trace_id": "5b8aa5a2d2c872e8321cf37308d69df2","span_id": "93564f51e1abe1c2"},"parent_id": "051581bf3cb55c13","start_time": "2022-04-29T18:52:58.114492Z","end_time": "2022-04-29T18:52:58.114631Z","attributes": {"http.route": "some_route3"},"events": [{"name": "hey there!","timestamp": "2022-04-29T18:52:58.114561Z","attributes": {"event_attributes": 1}}]
}
这个 Span 表示 Trace 中的第三个操作,和前一个一样,它是 hello span 的子级,也就是 hello-greetings span 的兄弟。
这三个 JSON 区块都具有相同的 trace_id,而 parent_id 字段表示它们之间的层级关系。它们构成了一个完整的 Trace!
你可能还注意到每个 Span 看起来像是一条结构化日志。其实它确实有点像!可以把 Trace 看作是一组具有上下文、关联性、层级结构等信息的结构化日志的集合。不过这些“结构化日志”可能来自不同的进程、服务、虚拟机或数据中心。这就是为什么 tracing 能够代表系统的端到端视图。
为了理解 OTel中 tracing 是如何工作的,我们可以来看一下在代码中实现追踪时会涉及到的组件列表。
链路提供器
Tracer 提供器(有时称为 TracerProvider)是用于创建 Tracer 的工厂。在大多数应用中,Tracer 提供器只初始化一次,它的生命周期与应用程序的生命周期一致。初始化 Tracer 提供器时,也会一并初始化 资源 和 导出器。这通常是使用 OTel进行追踪的第一步。在某些语言的 SDK 中,系统已经为你自动初始化了一个全局的 Tracer 提供器。
链路导出器
Trace 导出器(Trace Exporters) 将追踪数据发送给某个消费端。这个消费端可以是:
- 用于调试和开发时查看的标准输出(standard output),
- OTel Collector,
- 或你选择的任何开源或商业后端系统。
上下文传播
上下文传播(Context Propagation)是实现分布式链路追踪的核心概念。借助上下文传播,不同位置生成的 Span 之间可以相互关联,并组装成一个完整的 Trace(追踪链)。
跨度
一个 Span(跨度) 表示一个工作单元或操作。Span 是 Trace(追踪)的基本构建块。在 OTel中,Span 包含以下信息:
- 名称(Name)
- 父 Span ID(对于根 Span 为空)
- 开始和结束时间戳(Start and End Timestamps)
- Span 上下文(Span Context)
- 属性(Attributes)
- 事件(Span Events)
- 链接(Span Links)
- 状态(Span Status)
下面是一个示例 Span:
{"name": "/v1/sys/health","context": {"trace_id": "7bba9f33312b3dbb8b2c2c62bb7abe2d","span_id": "086e83747d0e381e"},"parent_id": "","start_time": "2021-10-22 16:04:01.209458162 +0000 UTC","end_time": "2021-10-22 16:04:01.209514132 +0000 UTC","status_code": "STATUS_CODE_OK","status_message": "","attributes": {"net.transport": "IP.TCP","net.peer.ip": "172.17.0.1","net.peer.port": "51820","net.host.ip": "10.177.2.152","net.host.port": "26040","http.method": "GET","http.target": "/v1/sys/health","http.server_name": "mortar-gateway","http.route": "/v1/sys/health","http.user_agent": "Consul Health Check","http.scheme": "http","http.host": "10.177.2.152:26040","http.flavor": "1.1"},"events": [{"name": "","message": "OK","timestamp": "2021-10-22 16:04:01.209512872 +0000 UTC"}]
}
Span 可以嵌套存在,这从存在的 父 Span ID 就可以看出。子 Span 表示子操作,这样可以更准确地捕捉应用程序中执行的工作。
跨度上下文
Span 上下文(Span Context)是每个 Span 上的一个不可变对象,包含以下内容:
- Trace ID:标识该 Span 所属的整个追踪(Trace)
- Span ID:该 Span 自己的唯一标识
- Trace Flags:一种二进制编码,用于携带有关该追踪的信息(如是否采样)
- Trace State:一组键值对,可以携带厂商相关的追踪信息
Span Context 是分布式上下文和 Baggage(额外携带的数据)一起进行序列化并传播的部分。由于 Span Context 中包含 Trace ID,因此它也被用于创建 Span 链接(Span Links)。
属性
属性(Attributes)是键值对形式的元数据,用于为 Span 添加注解,从而携带该操作的相关信息。例如,如果一个 Span 表示的是在电商系统中添加商品到购物车的操作,你可以为它添加如下属性:
- 用户 ID
- 商品 ID
- 购物车 ID
你可以在 Span 创建时 或 创建后 添加属性。建议在创建 Span 时添加属性,这样它们能被 SDK 的采样逻辑考虑进去。如果必须在之后添加,也可以通过更新 Span 实现。属性需遵循以下规则(所有语言的 SDK 都一致):
- 键(Key)必须是非空字符串
- 值(Value)必须是非空的字符串、布尔值、浮点数、整数,或它们的数组
此外还有语义属性(Semantic Attributes),它们是针对常见操作的标准化命名。例如 HTTP 请求相关属性、数据库操作属性等。推荐尽量使用语义属性命名,以在不同系统中实现元数据的统一。
跨度事件
Span Event 可以看作是在 Span 上的结构化日志或标注,表示 Span 期间某个有意义的单一时间点。举例来说,浏览器中:
- 页面加载过程用 Span 表示(有开始和结束)
- 页面变得可交互用 Span Event 表示(单一时间点)
何时用 Span Event,何时用 Span 属性:
- 如果某个时间点很重要,数据就附加到 Span Event(带时间戳)
- 如果时间点不重要,数据就作为 Span 属性附加(无时间戳)
跨度链接
Links 用来把一个 Span 和一个或多个 Span 关联起来,表示它们之间有因果关系。比如,在分布式系统中:
- 一个操作有对应的 trace,
- 后续异步执行的操作也有自己的 trace,
- 因为不知道后续操作什么时候开始,无法用普通方式关联,
- 这时用 span link 把第一个 trace 的最后一个 span 和第二个 trace 的第一个 span 连接起来,
- 这样两个 trace 就建立了因果关联。
Links 是可选的,但能有效关联不同 trace 中的 spans。
跨度状态
每个 Span 有三种状态:
- Unset(默认):表示操作成功完成,没有错误。
- Error:表示操作中发生了错误,比如服务器返回 HTTP 500。
- Ok:表示开发者明确标记该 Span 无错误,表明“明确成功”。
通常不用显式设置为 Ok,因为 Unset 已表示成功。Ok 只是开发者想明确无歧义地标记成功时使用。
跨度种类
创建 Span 时,会指定类型(kind):Client、Server、Internal、Producer 或 Consumer。这个类型帮助追踪系统理解如何组装 trace。
- Client:表示同步发起的远程调用,如 HTTP 请求或数据库访问,这里的“同步”指不是排队等待执行。
- Server:表示同步接收的远程调用,如收到的 HTTP 请求或远程过程调用。
- Internal:表示不跨进程的操作,比如函数调用或 Express 中间件的监控。
- Producer:表示创建一个后续可能异步处理的任务,比如加入任务队列或本地事件监听的任务。
- Consumer:表示处理 Producer 创建的任务,可能在 Producer 结束很久后才开始执行。
根据 OTel规范:
- Server Span 的父通常是远程 Client Span,
- Client Span 的子通常是 Server Span,
- Consumer Span 的父总是 Producer Span,
- Producer Span 的子总是 Consumer Span。
如果不指定,默认类型是 Internal。
上下文携带的数据
在 OTel中,Baggage 是紧跟上下文的一组键值对。它允许你在上下文中携带任意数据。这样,Baggage 可以跨服务和进程传递数据,方便在不同服务中添加到追踪(trace)、指标(metrics)或日志(logs)中。
示例
Baggage 常用于在分布式追踪中跨服务传递额外数据。举个例子,假设请求开始时有一个 clientId,你希望这个 ID 在整个 trace 的所有 span、另一个服务的部分指标和日志中都能使用。由于 trace 可能跨多个服务,不能把 clientId 复制到代码各处。通过 Context Propagation 传递 baggage,clientId 就能自动传到所有相关的 span、指标和日志中。很多自动监控工具也会帮你自动传递 baggage。
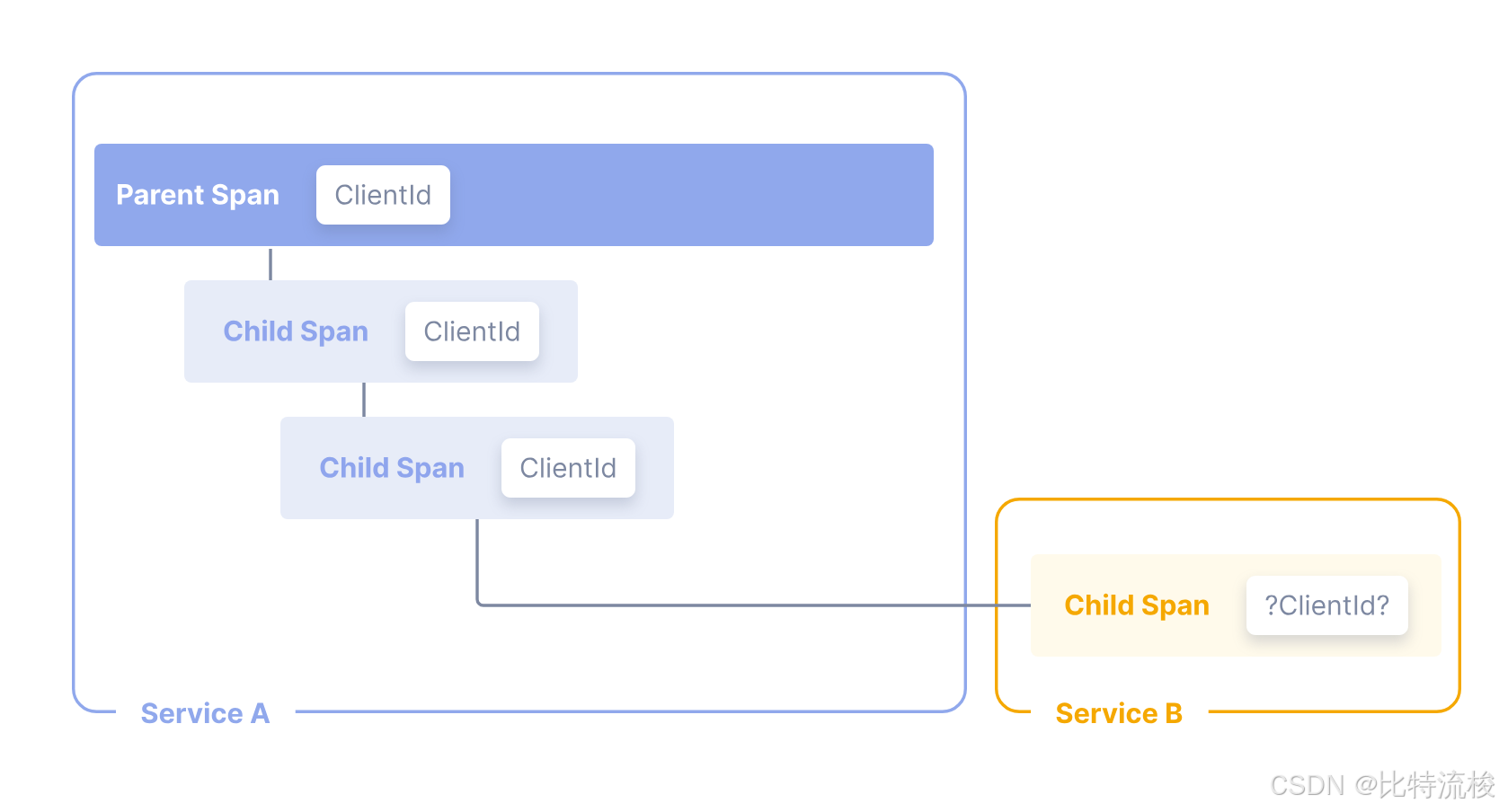
OTel Baggage 的用途
适合传递通常只有请求开始时才有的信息,如账号ID、用户ID、产品ID、来源 IP 等。这样后台可以更深入分析遥测数据,比如查询哪个用户的数据库调用最慢,或者在日志中包含同样的用户ID。
安全注意
- 敏感的 baggage 可能被第三方接口或外部资源看到,因为它会随大部分网络请求自动发送,通常通过 HTTP 头部传递,暴露在网络流量中。
- 如果网络受限风险较小,但下游服务可能会继续传播 baggage。
- 没有内置的完整性校验,读取时需谨慎。
Baggage 与 Attributes 不同
Baggage 是独立的键值存储,默认不会自动关联到 span、metric 或日志的 attributes 上。要把 baggage 数据加到 attributes,必须显式读取并添加。很多语言支持“Baggage Span Processor”,在创建 span 时自动将 baggage 数据作为属性添加,方便统一管理。
监控埋点
一个系统要具备可观测性,必须进行监控埋点,即系统代码需要产生信号,如追踪(traces)、指标(metrics)和日志(logs)。使用 OTel,主要有两种埋点方式:
- 代码埋点:通过官方 API 和 SDK 在大多数语言中直接写代码采集,能获得更深入、丰富的应用内部数据,是对零代码方案的重要补充。
- 零代码方案:适合快速入门或无法修改应用时使用,通过监控应用所用库或运行环境自动采集丰富数据,主要反映应用边缘的活动。
这两种方案可以同时使用,互为补充。
详情请阅读官方文档。
资源
资源表示产生遥测数据的实体,通过资源属性来描述。例如,在 Kubernetes 容器中运行的进程,它有进程名、Pod 名称、命名空间、部署名等属性,这些都能作为资源属性包含进去。在观测后台,这些资源信息有助于定位问题,比如系统延迟时,可以缩小到具体的容器、Pod 或部署。如果用 Jaeger 作为后台,资源属性会显示在“Process”标签页中。资源在初始化时添加到 TracerProvider 或 MetricProvider,添加后不可更改。之后该提供者产生的所有 span 和指标都会自动关联该资源。
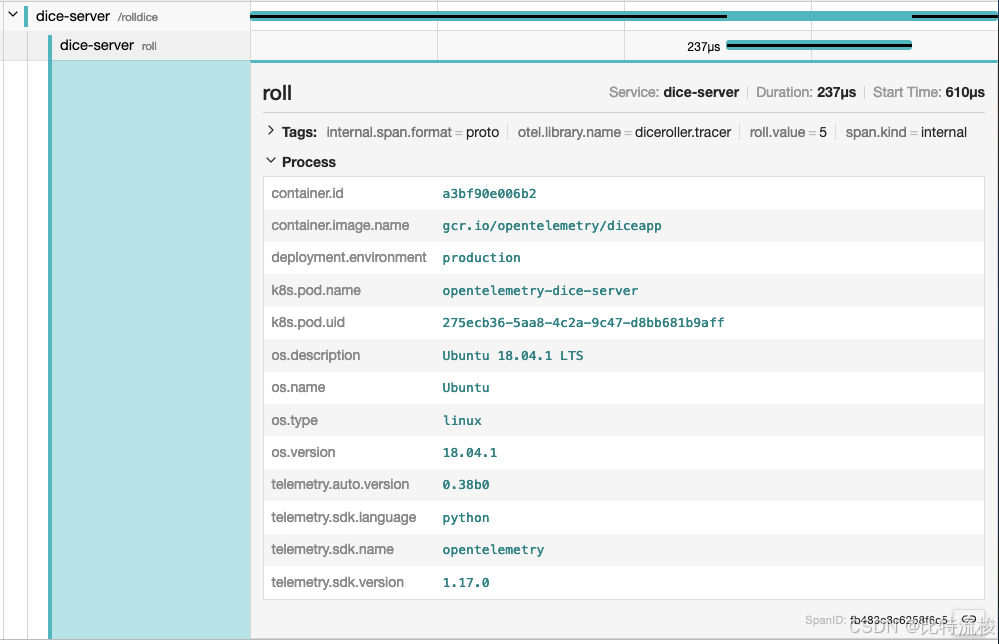
OTel SDK 提供了一些默认的语义属性,其中 service.name 表示服务的逻辑名称,默认值是 unknown_service。建议在代码中或通过环境变量 OTEL_SERVICE_NAME 显式设置该值。SDK 还会自动添加以下资源属性来标识自身:telemetry.sdk.name、telemetry.sdk.language 和 telemetry.sdk.version。大多数语言的 SDK 还内置了一些资源探测器,用于自动检测环境信息,常见的有:
- 操作系统
- 主机
- 进程及运行时
- 容器
- Kubernetes
- 云服务相关属性
- 以及更多
你也可以自定义资源属性,通过代码设置或环境变量 OTEL_RESOURCE_ATTRIBUTES 配置,建议使用语义规范的命名。例如:
env OTEL_RESOURCE_ATTRIBUTES=deployment.environment.name=production yourApp
监控范围
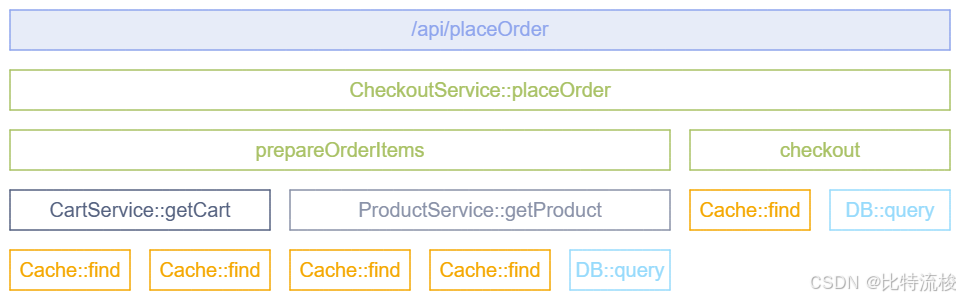
Instrumentation Scope(监控范围) 表示应用代码中的一个逻辑单元,用于关联产生的遥测数据。开发者可以自由定义合理的监控范围,比如一个模块、包或类。对于库或框架,通常使用唯一标识符(如完整的库名和版本号)作为监控范围。如果库本身没有内置 Otel监控,而是使用了第三方监控库,则用该监控库的名称和版本作为监控范围。监控范围由名称和版本组成,当从提供者获取 tracer、meter 或 logger 实例时确定。该实例创建的所有 span、指标和日志都会关联到这个监控范围。在观测后台,监控范围方便你按范围细分遥测数据,比如分析不同用户使用库的版本及性能,或定位应用的具体模块问题。
示例说明:
/api/placeOrderspan 来自 HTTP 框架(一个监控范围)。- 绿色的 spans(如
CheckoutService::placeOrder、prepareOrderItems、checkout)属于应用代码,归为CheckoutService类监控范围。 CartService::getCart和ProductService::getProduct也是应用代码,分别归属于对应类的监控范围。- 橙色的
Cache::find和浅蓝色的DB::query是库代码,按库名和版本分组。
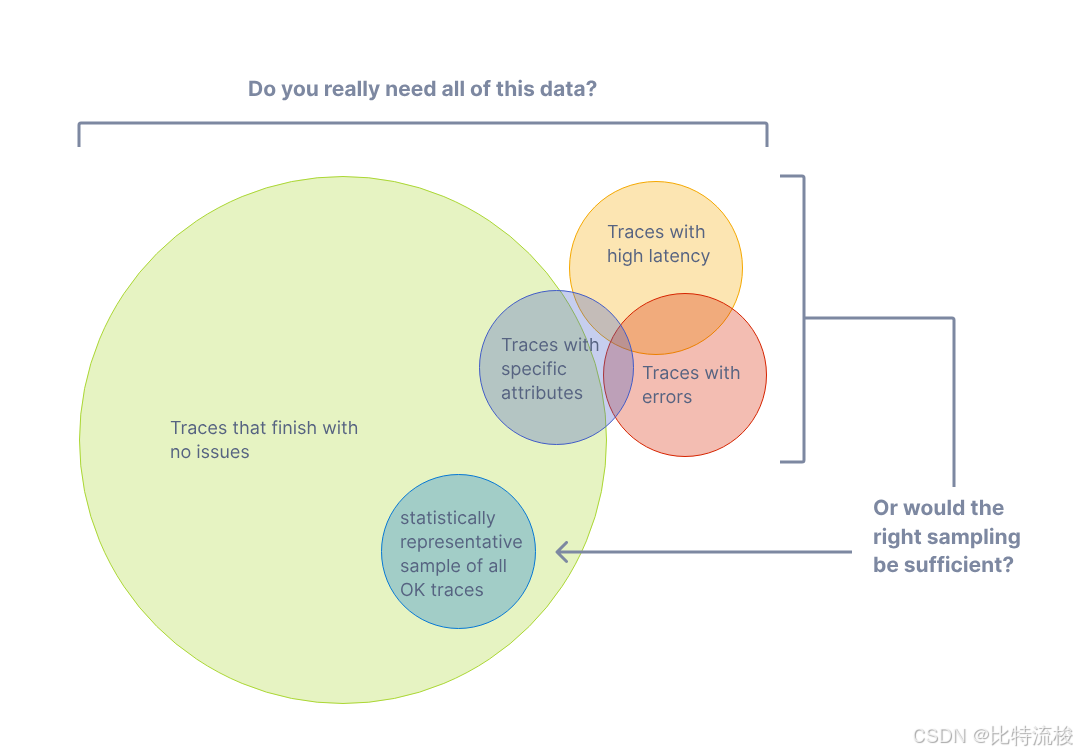
采样
通过追踪(traces),你可以观察分布式系统中请求从一个服务传递到另一个服务的全过程,便于进行整体和深入的系统分析。但如果绝大多数请求都成功且响应时间正常,无错误发生,就没必要采集所有请求的追踪数据,只需合理采样即可有效观察应用和系统表现。
采样的重要性
采样是降低观测成本同时保持可视性的有效手段。与过滤或聚合不同,采样保证了数据的代表性(即小样本能准确反映整体),且这种代表性可以用数学方法验证。高流量系统中,1% 或更低的采样率通常能很好代表剩余99%的数据。
- 何时采样
- 每秒生成1000条或以上追踪。
- 大部分数据为健康请求,波动小。
- 有明确错误或高延迟等异常指标。
- 有领域特定标准判断哪些数据更重要。
- 能制定明确规则判断是否采样或丢弃数据。
- 可区分不同服务,对高低流量服务分别采样。
- 能将未采样数据发送到低成本存储备份。
- 预算有限,愿意花时间实现有效采样。
- 何时不采样:
- 数据量极少(每秒几十条或更少)。
- 只需使用汇总数据,可先行预聚合。
- 受法规限制,不能丢弃数据且无法备份未采样数据。
- 采样成本考虑:
- 计算成本:实现有效采样(如尾采样代理)的资源消耗。
- 工程成本:维护采样策略的时间和人力。
- 机会成本:采样不当可能遗漏关键信息。
头采样
Head Sampling(头采样)是一种尽早做采样决策的技术,它不是基于对整个 trace 的检查来决定是否采样某个 span 或 trace。典型的头采样方式是 一致概率采样(Consistent Probability Sampling),也称为 确定性采样(Deterministic Sampling)。它根据 trace ID 和预设采样率(比如采样 5% 的 trace)来决定是否采样,从而保证采样的是完整的 trace,没有缺失的 span。头采样的优点:
- 简单易懂
- 配置方便
- 高效
- 可在追踪数据收集流程的任意阶段进行
头采样的主要缺点:
- 无法基于整个 trace 的内容做采样决策,比如不能保证采样所有包含错误的 trace。
- 针对需要根据完整 trace 结果做采样的情况(例如错误或异常采样),需要采用尾采样(Tail Sampling)。
尾采样
Tail Sampling(尾采样)是一种采样决策方式,它基于对整个 trace 或其中大部分 spans 的分析后,决定是否采样该 trace。与 Head Sampling 不同,Tail Sampling 能根据 trace 中不同部分的数据和条件做出更灵活、更复杂的采样决策。
- Tail Sampling 工作流程
- Trace 生成的所有 span 完成后,Tail Sampling 组件会接收这些数据,分析整个 trace,基于预设的策略来决定是否采样该 trace。
- Tail Sampling 的常见使用场景示例
- 始终采样包含错误(error)的 trace。
- 根据整体延迟(latency)采样 trace。
- 根据 trace 中一个或多个 span 上特定属性的存在或值采样,例如对新部署服务产生的 trace 增加采样率。
- 对不同服务或场景应用不同采样率,比如低流量服务与高流量服务分别采样不同百分比。
- Tail Sampling 的优点
- 允许根据丰富的上下文和多个条件做采样决策,采样策略更精细。
- 对于大型复杂系统,需要平衡采样率和数据价值时,Tail Sampling 几乎是必需的。
- Tail Sampling 的缺点
- 实现复杂:需要维护状态,采样策略随系统变化可能需要不断调整,配置复杂。
- 运行成本高:需要状态存储和计算资源,尤其在高流量场景可能需要大量计算节点,并且需要监控采样组件的健康状况。
- 供应商绑定:目前很多 Tail Sampling 技术是特定监控供应商提供的专有方案,限制了可移植性和灵活性。
- 头尾采样结合使用
- 在一些系统中,先用 Head Sampling 过滤掉大部分 trace,降低初始数据量,然后用 Tail Sampling 对剩余数据做更细致的判断,确保关键 trace 被采样,同时减轻系统压力。