Leetcode 刷题记录 12 —— 二叉树第三弹
本系列为笔者的 Leetcode 刷题记录,顺序为 Hot 100 题官方顺序,根据标签命名,记录笔者总结的做题思路,附部分代码解释和疑问解答,01~07为C++语言,08及以后为Java语言。
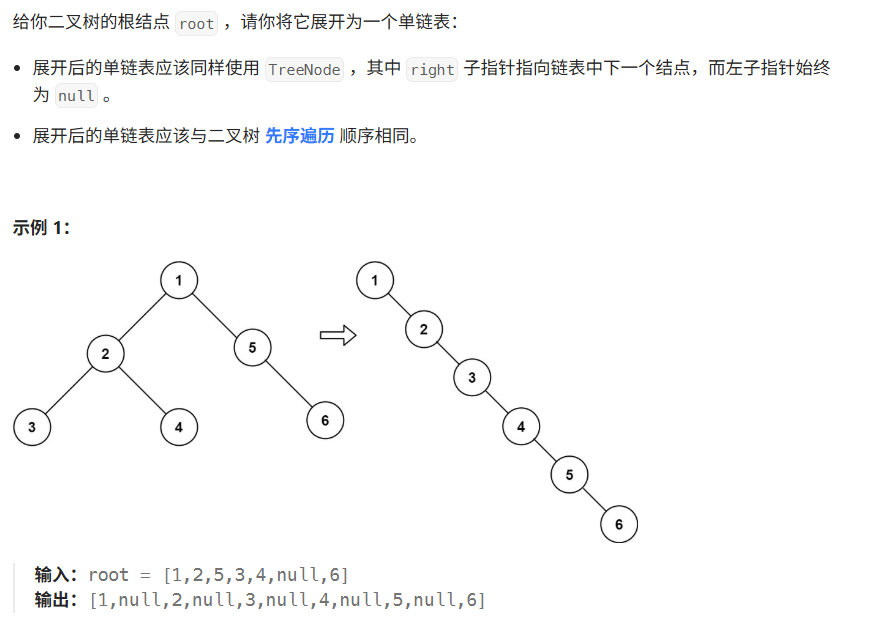
01 二叉树展开为链表

/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public void flatten(TreeNode root) {}
}
方法一:递归
class Solution {public void flatten(TreeNode root) {List<TreeNode> list = new ArrayList<>();preOrder(root, list);//⭐int size = list.size();for(int i=1; i<size; i++){TreeNode prev = list.get(i-1);TreeNode curr = list.get(i);prev.left = null;prev.right = curr;}}public void preOrder(TreeNode root, List<TreeNode> list){if(root == null){return;}list.add(root);preOrder(root.left, list);preOrder(root.right, list);}
}
方法二:栈
class Solution {public void flatten(TreeNode root) {List<TreeNode> list = new ArrayList<>();Deque<TreeNode> stack = new LinkedList<>();while(root != null || !stack.isEmpty()){while(root != null){list.add(root);stack.push(root);root = root.left;}root = stack.pop();root = root.right;}//⭐int size = list.size();for(int i=1; i<size; i++){TreeNode prev = list.get(i-1);TreeNode curr = list.get(i);prev.left = null;prev.right = curr;}}
}
方法三:改良版栈
class Solution {public void flatten(TreeNode root) {if(root == null){return;}Deque<TreeNode> stack = new LinkedList<>();stack.push(root);TreeNode prev = null;while(!stack.isEmpty()){TreeNode curr = stack.pop();if(prev != null){prev.left = null;prev.right = curr;}TreeNode left = curr.left;TreeNode right = curr.right;if(right != null){stack.push(right);}if(left != null){stack.push(left);}prev = curr;}}
}
方法四:寻找前驱结点
class Solution {public void flatten(TreeNode root) {TreeNode curr = root;while(curr != null){if(curr.left != null){TreeNode prev = curr.left;while(prev.right != null){prev = prev.right;}prev.right = curr.right;curr.right = curr.left;curr.left = null;}curr = curr.right;}}
}
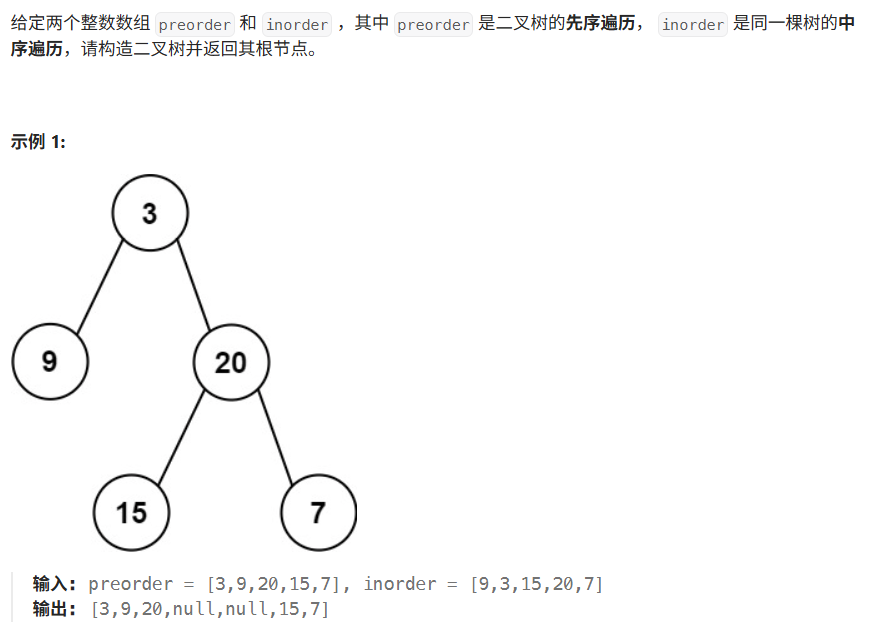
02 从前序与中序遍历序列构造二叉树
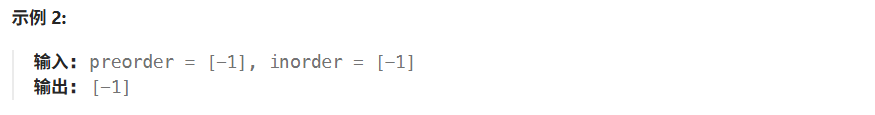
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder) {}
}
方法一:递归
class Solution {Map<Integer, Integer> indexMap; //值,下标public TreeNode myBuildTree(int[] preorder, int[] inorder, int prel, int prer, int inl, int inr){if(prel > prer){return null;}int pre_root = prel; //前序根节点下标int in_root = indexMap.get(preorder[prel]); //中序根节点下标TreeNode root = new TreeNode(preorder[prel]); //⭐int size = in_root - inl;root.left = myBuildTree(preorder, inorder, prel+1, prel+size, inl, in_root-1);root.right = myBuildTree(preorder, inorder, prel+size+1, prer, in_root+1, inr);return root;}public TreeNode buildTree(int[] preorder, int[] inorder) {int n = preorder.length;indexMap = new HashMap<>();for(int i=0; i<n; i++){indexMap.put(inorder[i], i);}return myBuildTree(preorder, inorder, 0, n-1, 0, n-1);}
}
| 问题 | 答案简述 |
|---|---|
| 1. 为什么要建立哈希表? | 为了快速定位根节点在中序数组的位置,避免线性查找,提高时间效率。 |
2. 为什么 indexMap 要全局定义? | 递归层层调用都需要访问,定义为全局成员变量方便统一管理,避免反复传参或创建。 |
3. 为什么比较 prel 和 prer 判断递归结束? | 递归分割以前序序列区域为准,prel > prer时表示无节点,终止递归更准确。 |
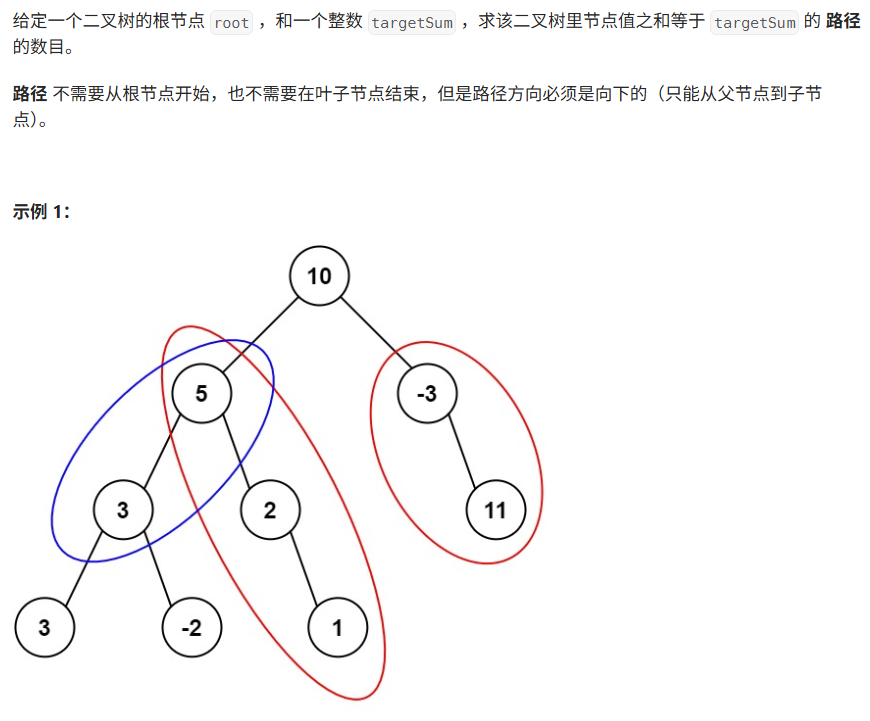
03 路径总和 Ⅲ

/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public int pathSum(TreeNode root, int targetSum) {}
}
方法一:递归
class Solution {public int pathSum(TreeNode root, long targetSum) {if(root == null){return 0;}int ret = rootSum(root, targetSum);ret += pathSum(root.left, targetSum);ret += pathSum(root.right, targetSum);return ret;}public int rootSum(TreeNode root, long targetSum){if(root == null){return 0;}int ret = 0;int val = root.val;if(val == targetSum){ret++;}ret += rootSum(root.left, targetSum - val);ret += rootSum(root.right, targetSum - val);return ret;}
}
方法二:前缀和
class Solution {public int pathSum(TreeNode root, long targetSum) {Map<Long, Integer> prefix = new HashMap<>(); //当前路径总和,出现次数prefix.put(0L, 1);return dfs(root, prefix, 0, targetSum);}public int dfs(TreeNode root, Map<Long, Integer> prefix, long curr, long targetSum){if(root == null){return 0;}int ret = 0;curr += root.val;ret = prefix.getOrDefault(curr-targetSum, 0);prefix.put(curr, prefix.getOrDefault(curr, 0) + 1); ret += dfs(root.left, prefix, curr, targetSum);ret += dfs(root.right, prefix, curr, targetSum);prefix.put(curr, prefix.getOrDefault(curr, 0) - 1);return ret;}
}
① prefix.getOrDefault(curr, 0) 为啥是0啊
prefix.getOrDefault(curr, 0)的作用是取出当前前缀和curr在哈希表里出现的次数。- 如果这个
curr第一次出现,prefix里就没有对应的key,因此用getOrDefault(curr, 0)返回默认值0,表示之前没有出现过这个前缀和。
② prefix.put(curr, prefix.get(curr) - 1);为啥呀?
当左、右子树递归完成后,递归函数就要回退到父节点继续处理父节点的其他分支 / 返回父节点。
如果不将当前路径和 curr 的出现次数 -1,那么在返回父节点后,哈希表会错误地保留了当前路径的状态,导致其他路径的统计被污染,出现错误的计数。
③ prefix.put(curr, prefix.getOrDefault(curr, 0) + 1);这里是不断更新吗?
是的,
prefix.put(curr, prefix.getOrDefault(curr, 0) + 1);
这行代码是在递归过程中不断更新当前路径和 curr 出现的次数。
04 二叉树的最近公共祖先
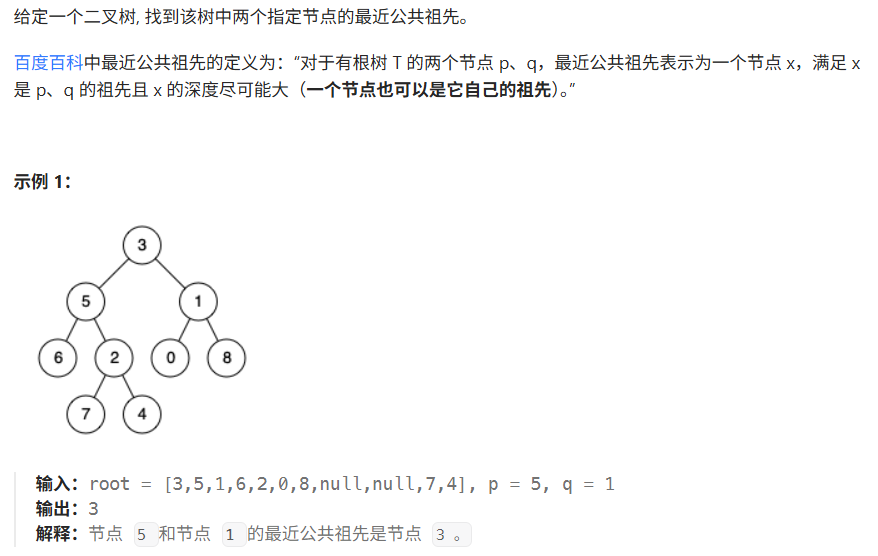

/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {}
}
方法一:递归
class Solution {private TreeNode ans;public Solution(){this.ans = null;}//1.创建递归方法dfspublic boolean dfs(TreeNode root, TreeNode p, TreeNode q){if(root == null){return false;}//2.左右孩子结点boolean lson = dfs(root.left, p, q);boolean rson = dfs(root.right, p, q);//⭐if((lson && rson) || ((root.val == p.val || root.val == q.val) && (lson || rson))){ans = root;}//3.return包含递归式return lson || rson || (root.val == p.val || root.val == q.val);}public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {this.dfs(root, p, q);return this.ans;}
}
① ans 和 dfs 为啥都是 private?
把实现细节隐藏起来,不希望外部代码直接访问递归实现细节和存储结果的变量,避免外部误用或者干扰。ans 是实现变量,dfs 是实现细节的递归函数,外部只需调用公开接口 lowestCommonAncestor。
② 为啥ans一旦赋值,不会改变
dfs 从树的根节点开始,递归访问左右子树后回到根节点。这是一种自底向上的查找方式——当递归顺序回溯到某个节点时,说明这个节点是中间某一层的节点。并且,最近公共祖先是“最低”的公共祖先,即离 p 和 q 最近的那个节点。
05 二叉树中的最大路径和
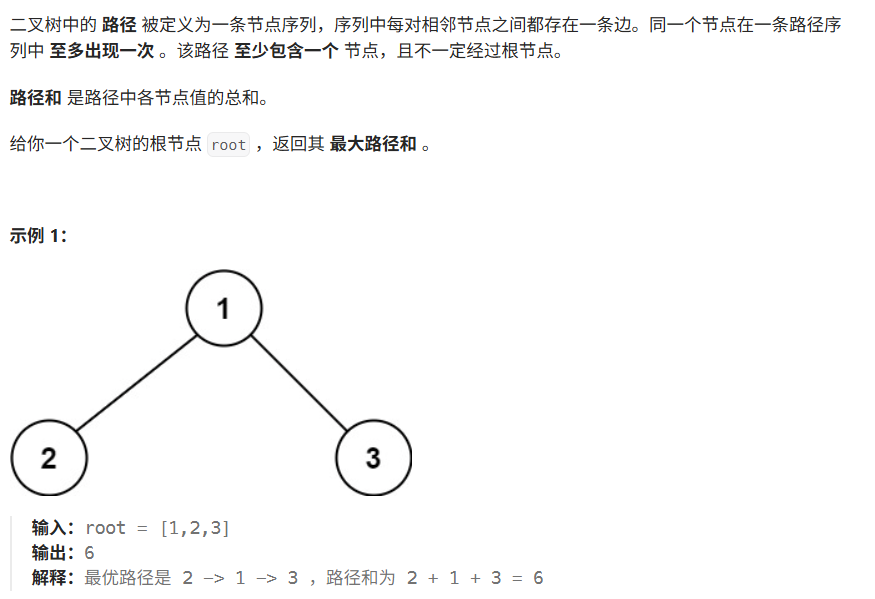
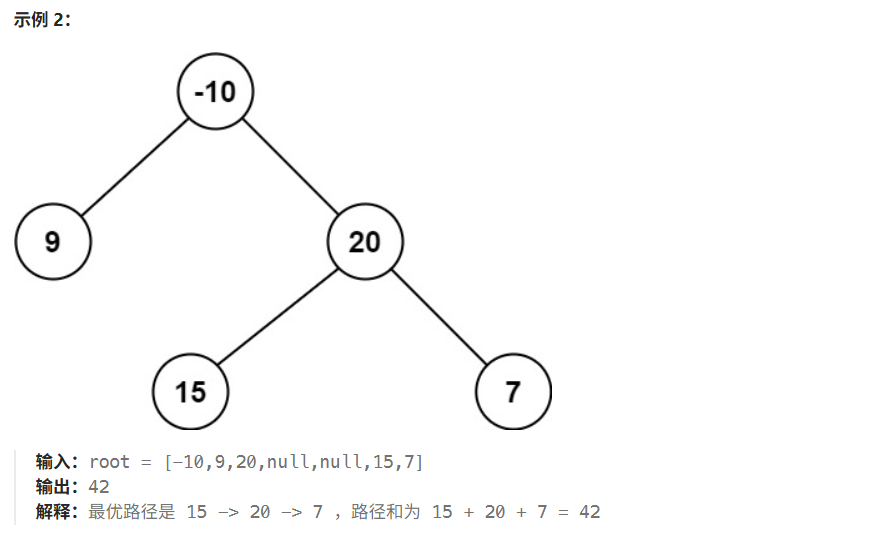
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public int maxPathSum(TreeNode root) {}
}
方法:递归
class Solution {int max = Integer.MIN_VALUE;public int maxPathSum(TreeNode root) {myFunction(root);return max;}public int myFunction(TreeNode root){if(root == null){return 0;}int L = Math.max(0, myFunction(root.left));int R = Math.max(0, myFunction(root.right));//⭐max = Math.max(max, L + R + root.val);return Math.max(L, R) + root.val;}
}
万一 root.val 是负的怎么办?
如果 root.val 是负数我们也必须加上它!因为这是这个路径的「根」,路径中必须包含它(因为题目定义路径一定是一个起点到终点连续的节点链),所以这个 L + R + root.val 是整条路径必须包含的值。