视觉通才模型:最新综述 [ 2025 IJCV ]
Vision Generalist Model: A Survey
[ arxiv ]

Recently, we have witnessed the great success of the generalist model in natural language processing. The generalist model is a general framework trained with massive data and is able to process various downstream tasks simultaneously. Encouraged by their impressive performance, an increasing number of researchers are venturing into the realm of applying these models to computer vision tasks. However, the inputs and outputs of vision tasks are more diverse, and it is difficult to summarize them as a unified representation. In this paper, we provide a comprehensive overview of the vision generalist models, delving into their characteristics and capabilities within the field. First, we review the background, including the datasets, tasks, and benchmarks. Then, we dig into the design of frameworks that have been proposed in existing research, while also introducing the techniques employed to enhance their performance. To better help the researchers comprehend the area, we take a brief excursion into related domains, shedding light on their interconnections and potential synergies. To conclude, we provide some real-world application scenarios, undertake a thorough examination of the persistent challenges, and offer insights into possible directions for future research endeavors.
近年来,通用模型(generalist model)在自然语言处理领域取得了巨大成功。这类模型通过海量数据训练构建统一框架,能够同时处理多种下游任务。受其卓越性能的鼓舞,越来越多研究者开始探索将此类模型应用于计算机视觉任务。然而,视觉任务的输入与输出形式更为多样,难以归纳为统一表征。本文对视觉通用模型进行了全面综述,深入探讨其特性与能力:首先回顾研究背景(包括数据集、任务与基准),继而剖析现有研究提出的框架设计,并介绍提升性能的关键技术;为帮助研究者更好地理解这一领域,本文还简要探讨了相关领域的关联性与潜在协同效应;最后,通过展示实际应用场景,系统分析当前挑战,并展望未来研究方向。
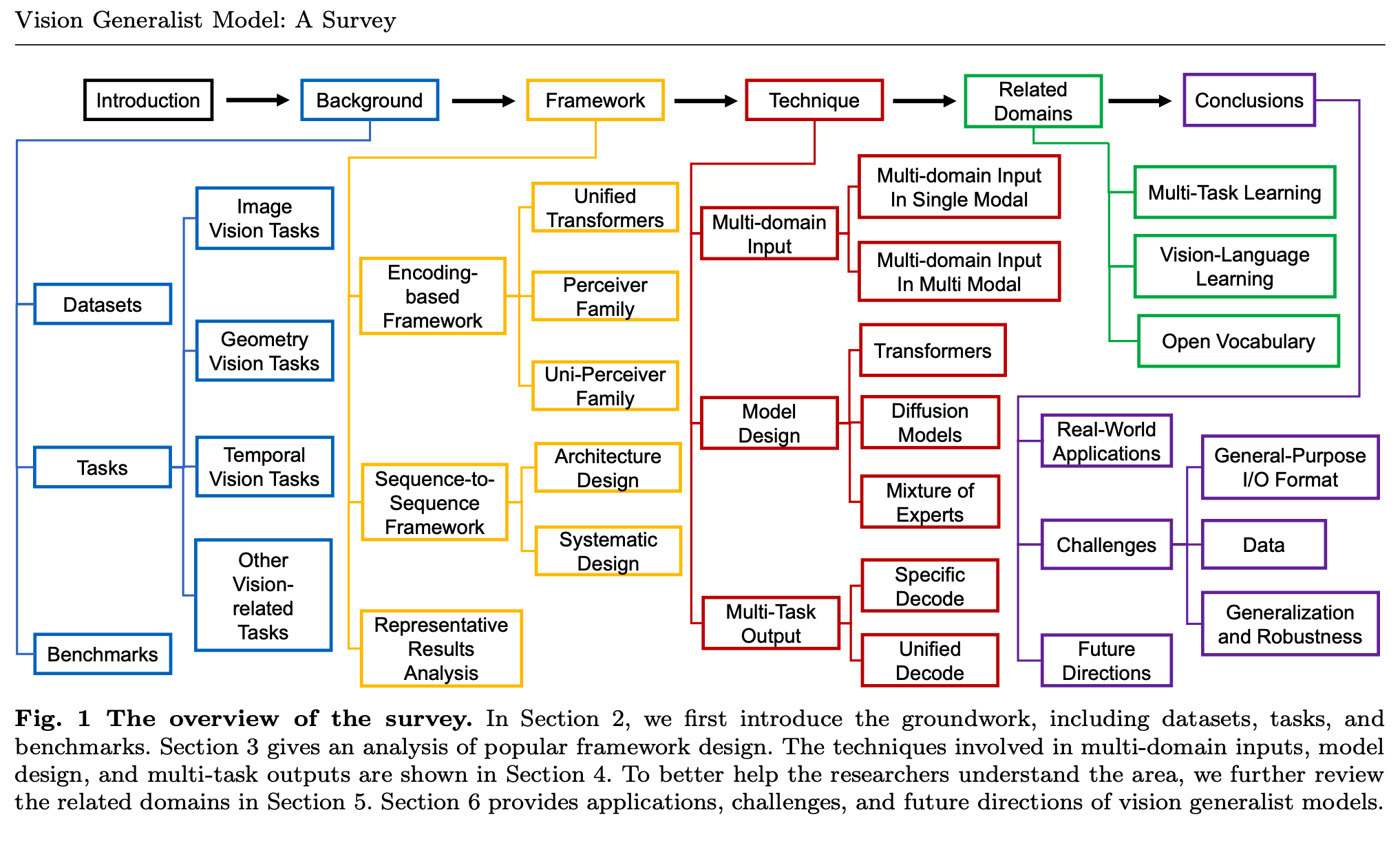
1 Introduction
人类大脑作为智能系统,能够感知多模态输入信息并同步处理多种任务。类似地,深度学习中的通用模型(Bae et al.,2022;Huang et al.,2023b;Jaegle et al.,2021a;Shukor et al.,2023)无需针对特定任务设计,即可处理多样化需求。近年来,得益于大数据的力量,大语言模型(LLM)(Devlin et al.,2018;Ouyang et al.,2022;Peters et al.,2018)在自然语言处理(NLP)领域验证了通用模型的成功。然而,与NLP不同,视觉任务的输出格式复杂多样:传统分类方法(He et al.,2016a;Russakovsky et al.,2015)仅需输出图像或点云类别;目标检测模型需定位物体并输出边界框;分割模型则需生成逐像素语义掩码。因此,视觉通用模型(Hu and Singh,2021;Zhang et al.,2023c;Zhu et al.,2022c)必须构建能适配广泛下游任务的系统。
相比传统神经网络,通用模型具备数十亿参数并通过海量数据训练,拥有传统模型无法比拟的优势:
-
零样本多任务迁移能力
传统计算机视觉方法通常需针对不同任务设计专用框架以处理多样化输入输出。尽管多任务学习方法(Sener and Koltun,2018;Yu et al.,2020;Zhang and Yang,2021)已取得进展,但这些方法无法在不微调的情况下泛化至新数据集。通用模型通过海量任务无关数据预训练,学习到通用表征,可直接扩展至各类下游任务。更重要的是,通用模型具备零样本迁移能力,无需特定适配器微调即可实现通用感知目标。 -
多模态输入兼容性
通用模型的核心特性之一是能接收多模态数据输入。由于不同模态(如图像——规则2D矩阵 vs 点云——无序3D向量)差异巨大,传统方法需分别采用2D卷积与3D稀疏卷积(Graham et al.,2018;Yan et al.,2018)等异构编码器。若进一步加入文本、音频等模态,难度将指数级上升。得益于Transformer架构(Vaswani et al.,2017b),现有工作可将多模态输入统一表示为token序列,突破模态壁垒。 -
超强表征能力
现有通用模型通常具备数十亿参数规模,虽带来较高计算成本,却显著提升了模型表征能力。多任务协同训练与多模态数据互补可形成正向循环,持续增强模型容量。 -
大数据驱动力
大规模数据为模型训练提供丰富知识库。例如,ChatGPT(Ouyang et al.,2022)的训练数据量高达约45TB文本。来自不同模态与领域的海量数据不仅增加样本多样性,更通过覆盖边缘案例(如ImageNet、CIFAR等数据集)显著提升模型在极端场景下的泛化能力(Chen et al.,2015;Krizhevsky et al.,2012)。
尽管视觉通用模型具备诸多优势,当前仍面临以下挑战:
-
框架设计难题
通用模型的核心技术在于设计能处理多任务的统一框架。已有研究(Hu and Singh,2021;Zhang et al.,2023c;Zhu et al.,2022c)尝试解决该问题,但该领域尚未形成标准流程。因此,最紧迫的挑战是建立视觉通用模型的统一范式。 -
数据获取瓶颈
通用模型依赖海量训练数据。在NLP领域,可从网页直接获取大量带标注文本数据;而计算机视觉数据(如网络图片)大多缺乏标注,人工标注成本极高。部分工作(Kirillov et al.,2023b;Ouyang et al.,2022)提出了特定任务的自动标注方案,但跨任务、跨模态数据的自动标注技术仍待探索。 -
伦理风险
与大型语言模型类似,视觉通用模型存在伦理隐患。在生成任务中,模型可能输出包含个人隐私/敏感信息的内容(如Deepfake视频,Güera and Delp,2018;Westerlund,2019);在判别任务中,数据中的隐性偏见会影响模型决策。此外,低质量或违规数据可能导致法律纠纷。
过去两年间,通用模型已在多个深度学习领域取得成功。随着神经网络架构的发展,越来越多研究致力于构建具备通用感知能力的模型。尽管该方向备受关注,目前仍缺乏系统性综述,这促使作者撰写本论文。具体而言,本文目标包括:
- 文献综述:帮助研究者快速掌握该领域进展;
- 挑战分析:阐明现有方法的局限性并指出未来方向;
- 领域关联:总结与其他研究方向的异同。
与相关综述的对比:
Awais et al.(2023)的综述聚焦视觉基础模型(Vision Foundation Models)。虽然基础模型同样通过大规模宽域数据训练,支持多模态输入,但其缺乏通用模型的多任务同步处理能力——基础模型需针对下游任务微调,限制了实际应用。因此,本文在概念上区别于Awais et al.(2023),更专注于通用模态感知与通用任务处理的总结。
相较于Li et al.(2023b)对多模态基础模型(涵盖统一视觉模型、大语言模型及多模态智能体应用)的广谱综述,本文研究范围更集中,深入剖析视觉通用模型的框架设计与关键技术。
2 Background
视觉通用模型能够容纳与处理的任务数量与多样性(及其相关的数据集和基准测试),是衡量该模型泛化能力的一个稳健指标。本节将从三个基本方面:数据集、任务和基准测试,对视觉通用模型的背景进行深入阐述。
......(详细内容略)
3 Framework
本节对现有提出的视觉通用模型框架进行深入调研。依据启发式原则将其划分为两个视角:编码式方法 (encoding-based methods) 和序列到序列框架 (sequence-to-sequence frameworks)。这种系统性分类旨在提供对该领域当前研究格局的全面理解,阐明为应对构建视觉通用模型挑战所采取的多样化策略。
本框架使用 E_X和 D_X分别表示领域特定编码器 (domain-specific encoders) 和任务特定解码器 (task-specific decoders),其中任意模态占位符 X 可替换为 V, L, A, 或 M,分别代表视觉 (vision)、语言 (language)、音频 (audio) 或其他自定义模态 (other custom modalities)。此外,I, O, F, 和 T 用于表示输入数据 (input data)、输出结果 (output results)、中间特征 (intermediate features) 和编码后的标记 (encoded tokens),而 TE 和 TD 则分别表示 Transformer 编码器 (Transformer encoder) 和 Transformer 解码器 (Transformer decoder)。
3.1 基于编码的框架
基于编码的视觉通用模型核心目标是构建统一编码空间,以兼容多模态输入并处理多样化任务。该领域存在三大主流框架:
-
统一Transformer框架(Bachmann et al.,2022;Hu and Singh,2021;Zhang et al.,2023c)
采用共享编码器-解码器结构,通过领域专用token编码器和任务专用输出头解决多模态与多任务挑战。 -
迭代注意力框架(Bae et al.,2022;Carreira et al.,2022;Jaegle et al.,2021a)
基于Perceiver架构(Jaegle et al.,2021b)的迭代注意力机制,扩展通用感知能力。 -
Uni-Perceiver系列(Li et al.,2023d;Zhu et al.,2022a,c)
在共享潜空间内探索输入模态与目标域的最大似然关联。
3.1.1 Unified Transformers
技术基础
Transformer模型(Vaswani et al.,2017b)彻底改变了自然语言处理及其他序列数据处理任务。其核心是自注意力机制,能够并行而非顺序地处理输入数据:
![]()
其中,Q、K、V 分别表示查询、键和值矩阵,softmax 为softmax函数,dk 是键向量的维度。这种独特的注意力机制使Transformer能够有效捕捉长程依赖关系和上下文关联,从而高效处理长输入序列。后续研究将自注意力扩展为交叉注意力,并构建Transformer解码器来处理基于任务特定查询的特征解码。
统一Transformer作为视觉通用模型
统一Transformer模型首先设计领域专用编码器将多领域数据转换为token,然后通过Transformer注意力层进行聚合,最后使用任务专用解码器并行处理多个任务:
![]()
尽管这些模型需要处理多领域和多任务,但它们通过共享的Transformer架构进行联合训练,促进了跨模态和跨任务的协同学习。
受Transformer在特定领域显著成就的启发,UniT(Hu and Singh,2021)率先探索了Transformer在跨领域知识提取和多任务统一处理中的潜力。该框架对图像和文本使用相同的Transformer编码器架构,仅输入投影层和模型权重不同。随后,两个领域的编码序列被拼接,形成领域无关的Transformer解码器中的统一记忆库。UniT解码器的查询输入由任务特定嵌入组成,其输出进一步通过任务专用头导向不同任务。模型在多个数据集和任务上进行联合训练。
UniT仅专注于图像和文本领域,而MetaTransformer(Zhang et al.,2023c)将这一概念大幅扩展,涵盖多达12种不同模态。为实现这一点,它提出了一种元token化方案,将输入数据编码到共享流形空间中的token嵌入。在模态无关学习阶段,预训练的统一Transformer编码器保持冻结,而可学习的分类token持续更新,作为每个领域的概要表征。
预训练策略增强
统一Transformer模型还可以有效利用现成的Transformer预训练方案来增强表征能力。MultiMAE(Bachmann et al.,2022)率先采用这一方法,通过在ImageNet1K上伪标注多种任务来构建多任务数据集。在预训练阶段,领域专用Transformer解码器被引入到统一Transformer编码器之后,用于预测掩码token。在微调阶段,任务专用解码器接管预测任务输出,从而将模型学习适配到每个任务的具体目标。
GenLV (Chen et al. 2024) 提出了一个视觉任务提示框架 (visual task prompting framework),旨在利用预训练视觉模型 (pre-trained visual models) 提升在底层视觉任务 (low-level vision tasks) 上的泛化能力 (generalization)。任务通过配对的提示图像 (paired prompt images)(源图像和目标图像)来指定,这些图像编码了期望的转换 (desired transformation)。然后,这些提示表示 (prompt representations) 通过一种新颖的提示交叉注意力机制 (novel prompt cross-attention mechanism) 与基础模型 (foundation model) 的中层特征 (mid-level features) 融合 (fused)。
总之,Transformer 框架在将不同领域的数据编码到共享流形 (shared manifold) 时,展现出作为统一模型 (unified model) 并有效提取跨领域知识 (extract cross-domain knowledge) 的巨大潜力。这种能力使模型能够借助任务特定的“头”(task-specific heads) 处理广泛的任务 (wide range of tasks),使其成为构建通用视觉模型 (generalist vision models) 的一条有前景的途径 (promising avenue)。
3.1.2 Perceiver Family
初步介绍 (Preliminary)
感知器 (Perceiver) (Jaegle et al., 2021b) 是一个功能强大且通用 (powerful and versatile) 的模型,旨在实现跨不同模态的通用感知能力 (general perception capabilities across different modalities)。它结合了交叉注意力机制 (cross-attention mechanism) 和迭代精炼过程 (iterative refinement process)。交叉注意力形成了一个瓶颈 (bottleneck),使模型能够有效处理长度和模态各异的输入序列 (input sequences of varying lengths and modalities)。精炼过程通过多次迭代的注意力和反馈循环 (multiple iterations of attention and feedback loops) 来提升模型的理解能力 (improves the model’s understanding)。
将感知器扩展为通用模型 (Extending Perceiver as VGM)
虽然原始感知器主要专注于统一输入模态 (unifying input modalities) 且仅限于处理简单输出空间 (limited to handling simple output spaces)(如分类),但 Perceiver-IO (Jaegle et al., 2021a) 迈出了重要一步,将通用感知的概念 (concept of general perception) 扩展到统一输出任务空间 (unify the output task space)。该框架将多模态数据 (multimodal data) 编码为特征 FV, FL 和 FX。首先在视觉和语言特征 (vision and language features) 之间应用交叉注意力 (cross-attention),然后在视觉模态内 (within the vision modality) 应用自注意力 (self-attention) 进行聚合 (aggregation)。当包含自定义模态 (custom modalities) 时,递归应用交叉注意力以实现跨模态交互 (cross-modal interaction):
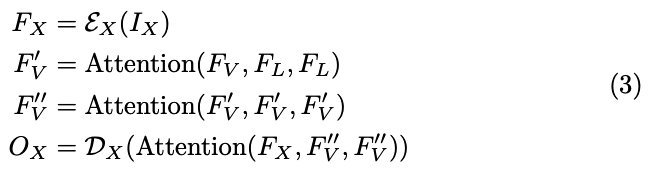
其中 Attention 操作遵循公式 1,F' 和 F'' 代表中间特征 (intermediate features)。
基于上述公式,Perceiver-IO 利用特定于输出的特征 (using output-specific features) 构建查询向量 (queries),并采用交叉注意力机制 (cross-attention mechanism) 生成具有不同语义、针对不同任务定制的输出 (generate outputs with distinct semantics tailored to different tasks)。这一进步使 Perceiver-IO 能够处理更广泛的任务 (broader range of tasks),并进一步增强了其在各领域的适用性 (applicability in various domains)。其后续模型 Graph Perceiver IO (Bae et al., 2022) 在基于图节点特征 (graph node features) 和包含拓扑信息的邻接矩阵 (adjacency matrix that encapsulates topological information) 构建输入数组 (constructing the input array) 方面取得进展,进一步增强了其处理图相关任务 (graph-related tasks) 的能力。感知器模型的另一个著名后继者 (notable successor) 是 分层感知器 (Hierarchical Perceiver, HiP) (Carreira et al., 2022),它通过将输入划分为块 (partitioning the input into blocks) 并构建分层结构 (hierarchical structures) 引入了局部性概念 (concept of locality)。此外,HiP 结合了随机掩码自编码 (random masked auto-encoding, MAE),以促进低维位置嵌入 (low-dimensional positional embeddings) 的学习,这对于处理高分辨率信号 (high-resolution signals) 尤其有益。
总之,感知器风格的框架 (Perceiver-style framework) 展示了将任意长度的输入序列 (input sequences of arbitrary length) 高效压缩 (compress) 为固定长度的潜在特征 (fixed-length latent features) 的能力,确保了有效处理 (effective processing)。此外,它能够准确地将这些潜在特征 (latent features) 解码 (decode) 成长度可变的序列 (sequences of varying lengths),以适应不同任务的特定要求 (specific requirements of different tasks)。这种处理可变长度输入和输出的灵活性 (flexibility in handling variable-length inputs and outputs) 使感知器风格的方法成为跨领域各种应用 (various applications across domains) 的一个强大且适应性强的解决方案 (powerful and adaptable solution)。
3.1.3 Uni-Perceiver Family
Uni-Perceiver
尽管名称相似,Uni-Perceiver(Zhu et al.,2022c)的核心思想与前述Perceiver模型截然不同。该框架通过构建共享表征空间来统一多模态输入与目标,其创新性体现在:
1. 采用轻量级模态专用tokenizer对输入和目标进行编码
2. 使用模态无关的Transformer编码器分析输入与目标token序列的联合概率分布
3. 将不同感知任务统一建模为输入与目标表征相似性最大化问题,形式化表示为:
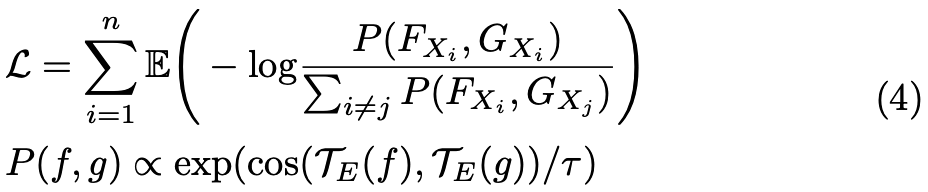
其中,G表示任务特定特征,τ为超参数,P(f,g)衡量多域数据与任务表征的相似度。
Uni-Perceiver的演进
为应对通用模型中任务干扰的挑战,Uni-PerceiverMoE(Zhu et al.,2022a)通过引入条件混合专家系统(MoE)对原模型进行重要改进:
- 加入门控决策向量,根据任务特定条件将输入token分配至不同专家模块
- 探索多种路由策略,优化输入token的专家分配机制以适配不同任务需求
另一方面,Uni-Perceiver v2(Li et al.,2023d)专注于大规模多任务学习:
- 提出任务平衡梯度归一化,解决梯度不稳定问题
- 采用非混合采样策略,支持大批量训练并提升计算资源利用率,使其能高效处理跨领域多任务的大规模训练场景
结论
Uni-Perceiver系列标志着通用感知框架的重大进步,实现了多模态数据无缝整合与跨域大规模任务协同处理的统一框架。
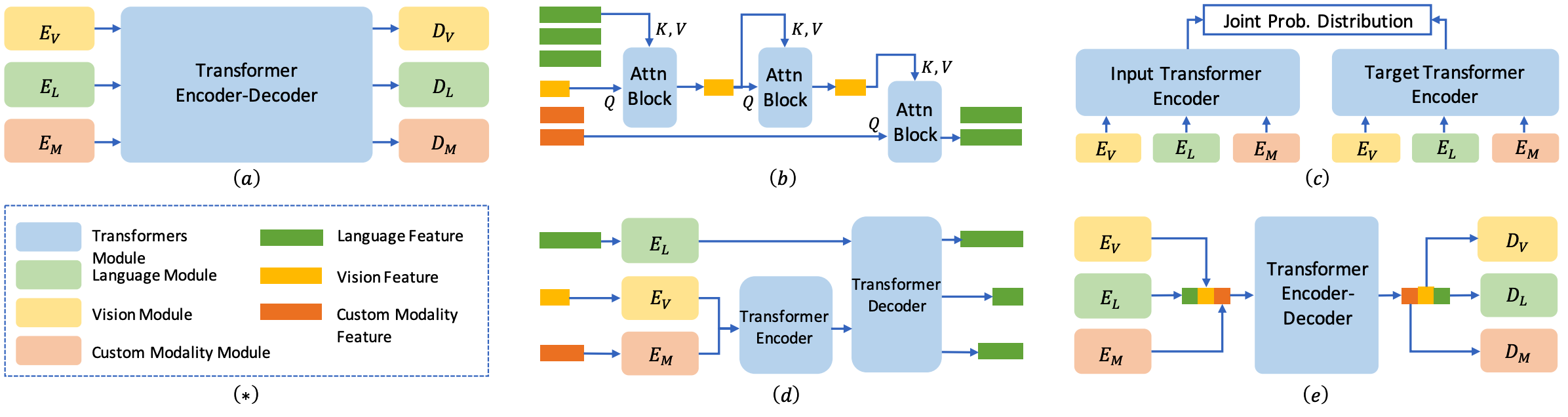

3.2 Sequence-to-Sequence Framework
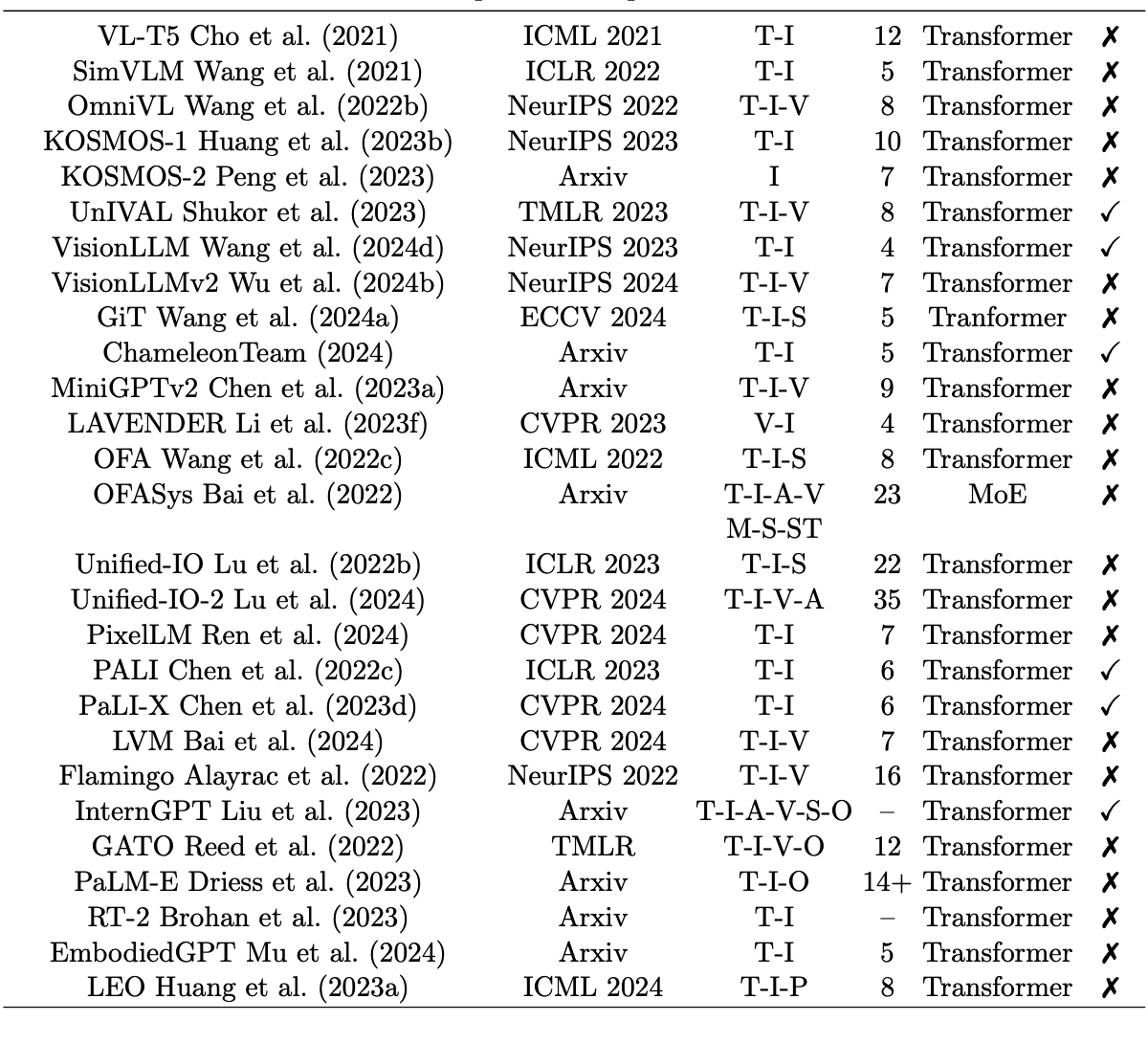
通用模型的概念最初起源于自然语言处理领域,NLP社区已开发出多种成熟的机制来统一跨领域输入并处理多种类型的任务。受这些机制的启发,计算机视觉领域的多篇论文提出了类似的序列到序列框架来设计通用视觉模型。其架构设计策略可分为前缀语言建模 Chen et al. (2023a); Cho et al. (2021); Huang et al. (2023b); Peng et al. (2023); Shukor et al. (2023); Wang et al. (2022b, 2024d, 2021)、掩码语言建模 Li et al. (2023f) 以及更广义的序列生成 Lu et al. (2022c, 2024); Ren et al. (2024); Wang et al. (2022c); Wu et al. (2024b)。此外,研究人员深入探索了通用视觉模型的关键系统设计组件,包括如何扩展模型规模 Bai et al. (2024); Chen et al. (2022c, 2023d)、如何更好地将预训练通用模型迁移到小样本学习 Alayrac et al. (2022)、如何设计复杂系统以实现更友好的人机交互 Bai et al. (2022); Liu et al. (2023),以及如何支持具身智能开发 Brohan et al. (2023); Driess et al. (2023); Huang et al. (2023a); Mu et al. (2024); Reed et al. (2022)。
3.2.1 Architecture Design
前缀语言建模(Prefix Language Modeling)
PrefixLM是一种条件文本生成方法,允许对前缀序列进行双向注意力计算,而自回归分解仅应用于剩余标记。该过程可表述为:
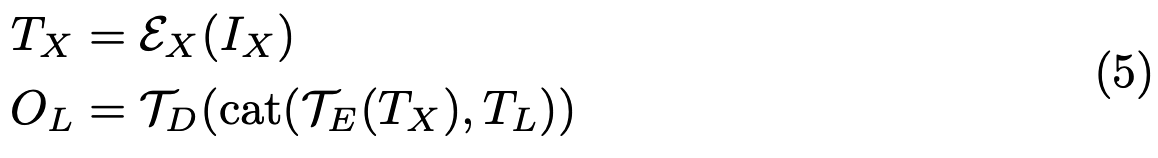
其中,cat表示拼接操作,将模态特定的标记作为前缀堆叠到语言标记序列之前。
受T5(Raffel et al.,2020)启发,VL-T5(Cho et al.,2021)提出通过多模态条件文本生成统一视觉-语言任务。VL-T5采用双向多模态编码器融合任务指令标记和视觉嵌入,其输出作为自回归文本解码器的前缀以生成文本结果。
SimVLM(Wang et al.,2021)同样利用PrefixLM策略实现任务统一。对于图文输入,SimVLM将图像标记作为前缀预测文本标记,促进多模态间有效交互。
基于Florence(Yuan et al.,2021)的思想,OmniVL(Wang et al.,2022b)将统一文本生成任务与对比学习结合,增强跨模态特征的表示能力。
更近期的通用模型Kosmos-1(Huang et al.,2023b)也以下一标记预测为目标任务,并采用更大规模的网络多模态语料和更先进的多模态大语言模型提升性能。
其后续版本Kosmos-2(Peng et al.,2023)进一步实现了感知物体描述和文本-视觉 grounding 的新能力,并将 grounding 能力整合至下游应用。
UnIVAL(Shukor et al.,2023)通过引入多模态课程学习和多模态任务平衡作为预训练流程,增强了条件下一标记预测训练,获得多种任务的统一表示。
VisionLLM(Wang et al.,2024d)将图像视为“外语”,提出基于语言的统一指令范式解决视觉中心任务。该框架采用语言条件化图像标记器与基于大语言模型(LLM)的任务解码器,支持自然语言指令驱动的开放任务。
MiniGPTv2(Chen et al.,2023a)通过引入独特任务标识符提升任务区分度,构建了多视觉-语言任务的统一接口,同时整合空间位置表示(将坐标编码为文本格式以优化处理)。
Chameleon(Team,2024)将多模态统一为混合模态自回归语言模型架构中的离散标记,并利用图像解标记器重建视觉输出。该模型通过架构改进和训练策略,实现了早期融合标记模型的稳定可扩展训练。
Masked Language Modeling.
LAVENDER (Li et al. 2023f) 对统一视频-语言模型进行了全面探索,其中MLM(掩码语言建模)作为多样化任务的统一接口。在输入统一方面,LAVENDER除了模态专用编码器外,还引入了多模态融合编码器来计算跨模态表征。预训练阶段包含MLM和视频文本匹配任务,两者均设计用于预测文本中的掩码标记。在下游任务适配中,LAVENDER通过插入或替换掩码标记,实现对下游任务的交叉熵监督一致性。
广义序列生成方法
虽然语言建模主要关注文本序列,但更广义的序列生成方法将任何数据格式或跨模态任务视为序列。其架构主要由两个核心组件构成:编码器与解码器。编码器接收输入序列并将其转换为固定长度的标记序列(通常称为上下文向量),解码器则以自回归方式利用该上下文向量逐步生成输出序列:

其中SI和SO分别表示输入与输出序列。cat操作将不同模态的标记拼接为统一序列,split操作则将SO拆分为模态专用标记序列。Seq2Seq模型擅长处理可变长度输入输出序列,其适应性与远距离依赖建模能力已获得广泛认可。
OFA(One For All) (Wang et al. 2022c) 如其名称所示,设计了一种与模态和任务无关的通用框架。它建立了通用序列到序列架构,并在预训练和微调阶段采用基于指令的学习,从而无需为下游任务添加额外任务专用层。具体而言,OFA使用图像块序列标记编码输入图像,并采用字节对编码处理文本输入;目标图像通过图像量化离散化,目标物体则用边界框位置标记与类别标记共同表示。精心设计的指令引导学习过程,使框架能涵盖多种跨领域任务。
Unified-IO (Lu et al. 2022c) 进一步扩展了序列到序列框架,以涵盖更广泛的任务范围,并同时在更庞大的多领域数据集集合上开展联合训练。为了更好地编码图像的离散表示,该模型采用了预训练的VQ-GAN (Esser et al. 2021),提升了框架的表征能力和有效性。其继任者Unified-IO v2 (Lu et al. 2024) 扩展了模态范围,以编码文本、图像、音频、视频以及交错序列(interleaved sequences),同时生成诸如文本、动作、音频、图像以及稀疏或稠密标签等输出。该模型最初使用多样化的多模态数据从头开始构建,随后通过在大规模语料库上进行指令驱动学习进行微调。
VisionLLMv2 (Wu et al. 2024b) 建立在VisionLLM Wang et al. (2024d)的基础上,显著拓宽了其应用范围,使之涵盖数百种视觉语言任务,克服了视觉问答(VQA)的限制。这一进步得益于新引入的称为“超链接(super link)”的信息传输机制,该机制利用路由令牌(Routing Tokens)定义视觉任务,并使用超链接查询(Super-Link Queries)提取任务特定信息。
与先前研究中常见的序列建模方法不同,PixelLM (Ren et al. 2024) 侧重于增强大语言模型(LLM)在像素级视觉感知任务上的能力。它引入了轻量化像素解码器和一个全面的分割码本作为关键创新。该分割码本是框架的核心,它在各种视觉尺度上编码像素级知识,从而消除了对外部分割模型的依赖。
最近将大语言模型中的自回归解码扩展到多样化视觉任务的另一个努力是GiT (Wang et al. 2024a)。它引入了统一的语言接口,将视觉目标(如分割掩码和边界框)表示为标记序列(token sequences)。GiT还提出了一个灵活的多任务提示模板来统一任务格式。整个多层Transformer模型是从头开始训练的,无需依赖任务特定头部(task-specific heads)。
3.2.2 Systematic Design
可扩展性探讨
PALI (Chen et al. 2022c) 和 PALI-X (Chen et al. 2023d) 专注于研究通过统一文本生成任务训练的通用视觉模型的可扩展性。PALI 强调了联合扩展视觉和语言组件的关键性。他们利用新引入的WebLI数据集(包含100多种语言的100亿张图像和文本)开发了一个大型多语言混合训练集,包含八个预训练任务。随后,PALI-X 进一步扩展了 PALI 的视觉和语言组件,并观察到其在多样化任务上的性能显著提升。通过融合前缀补全(prefix completion)和掩码标记预测(masked-token prediction)任务,改进后的训练策略增强了整体可扩展性和效能。
LVM (Bai et al. 2024) 通过将原始视觉数据和标注组织成“视觉句子(visual sentences)”,创建了统一视觉数据集 v1 (UVDv1),从而推进了通用视觉模型的可扩展性。这些视觉句子通过一个大型视觉标记器(visual tokenizer)处理,并使用一个自回归Transformer模型进行分析。这种统一格式化方法使 LVM 能够充分发挥无监督视觉数据的潜力和重要性。
面向小样本学习的提示调优
Flamingo (Alayrac et al. 2022) 致力于解决将在文本生成任务上训练的通用模型适配到小样本场景下的下游任务的挑战。他们引入了基于文本的提示调优(text-based prompt tuning)概念,其中小样本的文本-图像示例被视为自回归生成的前缀条件(prefix condition)。该论文提出新颖的感知重采样器(perceiver resampler)和门控注意力层(gated attention layer)作为提示调优参数。这些参数使冻结权重(frozen weights)的预训练大语言模型能够有效适配于各种下游应用,从而促进其在小样本学习范式下的多功能性和性能。
系统设计
OFASys (Bai et al. 2022) 引入了一个称为多模态指令(multimodal instruction)的简洁通用用户接口。它提出了一种模块化且可复用的系统设计,以简化多模态多任务学习的研究流程。通过采用该指令接口,用户只需一行代码即可轻松声明新任务,或轻松自定义任务特定处理并集成新模态。这种用户友好的设计使研究人员能够高效地进行多模态多任务学习的实验,简化了将新任务和新模态集成到框架中的过程。OFASys 在通用视觉模型的系统性探索方面迈出了重要一步。
InternGPT (Liu et al. 2023) 支持增强了指点等非语言信号的基于聊天的交互方式,便于用户直接控制屏幕上显示的图像和视频。该系统包含三个主要组件:一个感知模块(如 SAM Kirillov et al. (2023a))用于处理用户的指点指令;一个 LLM 控制器(如 LLaMa Touvron et al. (2023) 或 GPT-4 Achiam et al. (2023))负责基于语言的交互;以及一个开放世界工具包(包含 ControlNet Zhang et al. (2023a) 或 InternVideo Wang et al. (2022d) 等选项),用于有效执行多模态任务。
具身智能(Embodied AI)
除了之前讨论的视觉系统,部分研究专注于通过序列到序列的通用视觉模型开发具身智能系统。
GATO (Reed et al. 2022) 提出了首个多模态、多任务、多具身(multiembodiment)的通用策略模型。该模型将来自多个来源的输入数据编码为标记,并训练一个自回归Transformer模型,使用前置的任务特定提示(task-specific prompts) 来定义具身任务并推导出相应的动作。在部署时,模型利用历史观测来预测未来的动作,这些动作被发送到环境中,从而产生新的观测结果。
PaLM-E (Driess et al. 2023) 基于这一思想,利用预训练的大语言模型(LLM)来感知多模态输入并预测自然语言形式的序列决策,这些决策随后由具身代理解释为动作。
RT-2 (Brohan et al. 2023) 引入了视觉-语言-动作(Vision-Language-Action, VLA)模型的概念,其中动作被视为文本标记,并与语言和图像标记直接整合,从而允许一个统一的模型同时处理感知和动作预测。
EmbodiedGPT (Mu et al. 2024) 提出了一个大规模的具身规划数据集 EgoCOT,并在预训练大语言模型上应用前缀调优(prefix tuning)。该模型还从大语言模型中提取任务相关特征,以促进高层规划与低层控制,增强了代理执行复杂任务的能力。
LEO (Huang et al. 2023a) 进一步将通用视觉模型的应用扩展到 3D 领域的具身代理。他们的方法首先确保强大的 3D 视觉-语言对齐,然后应用 3D 视觉-语言-动作指令调优。他们还引入了两个新数据集 LEO-align 和 LEO-instruct,分别对应于这两个不同的训练阶段,从而提升了具身代理在空间复杂环境中的能力。
3.3 代表性结果分析
鉴于现有通用视觉模型使用的基准测试范围广泛且实验设置各不相同,在所有基准测试上进行全面比较并不可行。在该研究领域统一评估标准将非常有价值,有助于对现有模型进行彻底且公平的比较。在本小节中,本文进行了一项代表性分析,在图 3 中展示了 10 个通用视觉模型在 22 个基准测试上的比较结果。
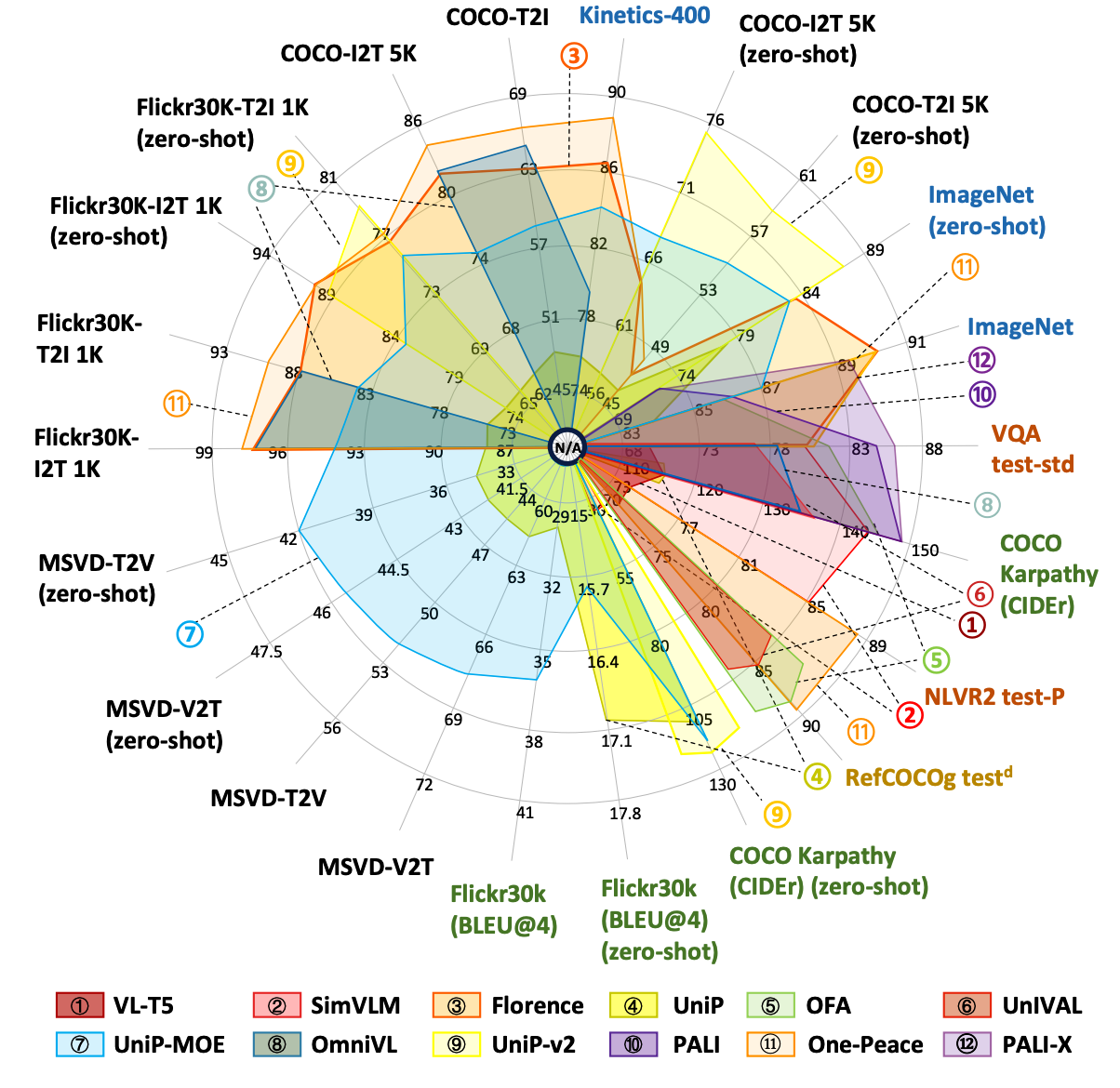

这 22 个基准测试分为五类,每类用不同颜色表示:(1) 多模态检索,包括在 COCO、Flickr30K 和 MSVD 数据集上的图像到文本(image-to-text)、文本到图像(text-to-image)、视频到文本(video-to-text)和文本到视频(text-to-video)检索任务;(2) 纯视觉感知,包含在 ImageNet 上的图像分类任务和在 Kinetics-400 上的视频分类任务;(3) 其他视觉语言推理任务,例如在 COCO Karpathy 和 Flickr30K 数据集上的图像描述生成(image captioning)、在 VQA 数据集上的视觉问答(visual question answering)、在 NLVR2 数据集上的视觉推理(visual reasoning),以及在 RefCOCOg 数据集上的指称表达理解(referring expression comprehension)。
在本工作收集的基准测试中,One-Peace 和 UniPerceiver-v2 在图文检索任务上表现出相对较高的性能,而 Uni-Perceiver-MoE 在视频-文本检索任务中表现优异。Florence 在纯视觉感知任务中表现突出,而 PALI 和 PALI-X 在 VQA 任务上提供了卓越的结果。虽然所有模型都能够同时应对多种基准测试,但目前尚未出现一个能在所有任务中都表现最优的通用视觉模型。
4 Technique
构建通用视觉模型的一个突出障碍在于如何将多种模态数据和多种任务集成到一个核心模型中。具体而言,模型需要能够同时处理所有模态和任务的输入与输出。数据必须被整合到一个共享且统一的空间中,以使模型能够以一致的方式处理它们。在本节中,将探讨几种应对多领域输入、模型设计和多任务输出相关复杂性的策略。需要注意的是,本节讨论的一些模型可能与第 3 节中介绍的模型存在重叠。然而,区别在于各节的重点:第 3 节侧重于更广泛的架构概述,而本节则着重阐述使这些模型兼具创新性并代表当前技术前沿的具体、开创性技术。
4.1 Multi-Domain Input
首先需要理解的关键概念是:尽管不同领域(文本、视觉、听觉或其他)存在表面差异,但将它们转化为统一的特征表示至关重要且充满挑战。这个共享特征空间是视觉通用模型执行数据处理、分析和理解的基础。
输入的模态多种多样,范围从静态图像到动态视频序列,从单幅 RGB 图像到多模态组合。此外,计算机视觉任务的层级也差异显著。例如,在图像级别,任务包括图像分类和图像描述;而在区域级别和像素级别,任务则分别涵盖目标检测和语义分割。因此,统一的数据编码技术也需要能够充分挖掘具有不同层级的多模态数据中的知识。
4.1.1 Multi-domain Input in Single Modal
基于Transformer的方法
MulT (Bhattacharjee et al., 2022) 使用一个统一的基于Transformer的编码器,将来自多个领域的输入图像编码到一个共享的表示空间中,适用于所有任务。
EQ范式 (Yang et al., 2022) 为 3D 理解任务(包括检测、分割和分类)提出了嵌入-查询范式 (Embedding-Querying Paradigm)。EQ范式将输入点云统一映射到相同的特征空间,并添加特定的查询位置嵌入 (query position embeddings) 以适应不同的任务需求。
视觉提示 (Visual Prompt)
受自然语言处理(NLP)中基于提示的学习 (prompt-based learning) 的启发,Bar et al. (2022) 提出的视觉提示 (Visual Prompting) 将这一概念扩展到了视觉领域 (visual domain)。它的工作原理是:在测试时,为一个新任务提供一个参考输入-输出图像对 (reference input-output image pair) 和一个新的输入图像,目标是自动生成一个与给定示例一致 (aligns with) 的输出图像。视觉提示采用了一种简单的图像修复 (image inpainting) 方法来处理这个问题,该方法通过填充视觉提示组合图像中的一个空洞(hole)来工作。只要修复算法在正确的数据上进行了训练,这种方法效果就很好。Wang et al. (2023b) 提出的 Painter 模型,通过对联合的输入-输出图像对 (joint input-output image pairs) 进行掩码图像建模 (masked image modeling, MIM),实现了基于部分视觉信息 (conditioned on partial visual information) 的任务执行。这使得模型能够在推理时根据提供的输入-输出示例推断任务 (infer the task)。
4.1.2 Multi-domain Input in Multimodal
特定编码 (Specific Encode)
Florence (Yuan et al., 2021) 采用了双塔架构 (dual-tower design),包含独立的视觉编码器 (visual encoder) 和文本编码器 (textual encoder)。图像编码器使用分层视觉 Transformer (hierarchical vision Transformers),而文本编码器基于传统的 Transformer 架构 (conventional Transformer-based architectures)。为了训练模型,Florence 采用了 统一对比学习 (Unified Contrastive Learning, UniCL) (Yang et al., 2022)。UniCL 扩展了标准的对比学习,允许多个图像对应同一文本 (allowing multiple images to correspond to the same text),并将所有这些图像-文本对视为正样本 (treating all such pairs as positives)。
Data2vec (Baevski et al., 2022) 引入了一种模态无关的学习范式 (modality-agnostic learning paradigm),可应用于语音、语言和视觉。它不再预测局部的或特定模态的目标,而是学习生成能概括整个输入信息的上下文潜在表示 (contextualized latent representations that summarize the entire input)。这是通过一个自蒸馏框架 (self-distillation framework) 实现的:使用一个掩码的输入视图 (masked input view) 来预测完整输入的潜在表示,该过程使用共享的 Transformer 骨干网络 (shared Transformer backbone)。每种模态都有自己的输入编码方式:图像被分解成图像块序列 (patch sequences);音频通过一维卷积前端 (1D convolutional front-end) 处理生成波形表示;文本被分词 (tokenized) 成子词嵌入。
OFASYS (Bai et al., 2022) 设计了模态特定的编码器 (modality-specific encoders),并通过适配器模块 (adapter modules) 将它们集成到统一架构中。它将文本分词 (tokenizes) 并将图像输入离散化 (discretizes) 为代码表示。一个内置调度器 (built-in scheduler) 根据输入类型和模态,动态地将数据分配给 (dynamically assigns data to) 合适的预处理模块和编码器。
LaVIT (Jin et al., 2023) 引入了一个视觉分词器 (visual tokenizer),可将图像转换为可变长度的离散标记序列 (discrete token sequences of variable lengths)。这些标记化表示 (tokenized representations) 使得大语言模型 (large language models, LLMs) 能够有效地解释和推理视觉信息 (interpret and reason over visual information),从而促进统一的多模态理解 (unified multimodal understanding)。
统一编码 (Unified Encode)
UNITER (Chen et al., 2020b) 是一个在四个大规模视觉-语言数据集上训练的统一图像-文本表示模型 (unified image-text representation model)。它使用四个预训练目标将多模态输入对齐 (aligns) 到一个共享嵌入空间 (shared embedding space) 中:掩码语言建模 (masked language modeling)、掩码区域建模 (masked region modeling)、图文匹配 (image-text matching) 和词-区域对齐 (word-region alignment)。它还采用了条件掩码 (conditional masking) 来提高学习效率。
UFC-BERT (Zhang et al., 2021) 将控制指令 (control instructions) 和合成视觉元素 (synthetic visuals) 都表示为离散标记序列 (discrete token sequences),并输入到一个 Transformer 模型中。
Codebook (Duan et al., 2022) 提出了一种使用可学习码本 (learnable codebook) 来对齐不同模态信号的方法。Codebook 将图像和文本视为同一实体的两种“视图 (views)”,并将它们编码到一个由聚类中心字典 (cluster-centric dictionaries) 张成的联合视觉-语言编码空间 (joint visual-linguistic encoding space) 中。
Unified-IO (Lu et al., 2022b) 将支持的每种输入和输出都同质化 (homogenizes) 为离散词汇标记序列 (sequence of discrete lexical tokens),从而为所有任务提供通用表示 (common representation)。文本输入使用 SentencePiece 进行分词。图像输入则使用 VQVAE (Van Den Oord et al., 2017) 编码为离散标记 (discrete tokens)。为了编码稀疏结构 (sparse structures)(如边界框和关键点),它在词汇表中添加了 1000 个额外的标记来表示量化后的图像坐标 (quantized image coordinates)。
OMNIVORE (Girdhar et al., 2022) 通过将图像、视频和单视角 3D 数据编码到一个共享嵌入空间 (shared embedding space) 来统一视觉模态。它将图像转换为图像块 (patches),将视频转换为时空管 (spatio-temporal tubes),将 3D 视图转换为配对的 RGB 和深度图像块 (RGB and depth patches),所有这些都由一个 Transformer 处理。
M2-Mix (So et al., 2022) 通过在超球面空间 (hyperspherical embedding space) 中混合图像和文本特征 (mixing image and text features) 来改进表示学习。这种方法能跨数据集生成困难负样本 (generates hard negatives across datasets),从而增强特征对齐 (feature alignment)、分布均匀性 (distribution uniformity) 以及向下游任务的可迁移性 (transferability to downstream tasks)。超球面内的角距离 (Angular distances within the hypersphere) 引导模型学习更鲁棒的跨模态表示 (robust cross-modal representations)。
GPNA (Rahaman et al., 2022) 观察到,不同模态数据的主要差异在于位置 (location)、时间 (time) 和光谱信息 (spectral information),因此设计了一个通用序列分词器模块 (general sequence tokenizer module)。每个标记是通过将傅里叶编码的空间-时间位置 (Fourier-encoded spatial-temporal location) 与归一化的多光谱图像块 (normalized multi-spectral image patch) 拼接形成的。编码后的位置和时间提供了序列中每个标记的位置信息 (positional information)。归一化的多光谱图像块包含了观测所捕获的光谱波段信息 (information about the spectral bands),从而能够高效处理地理空间系统 (Geospatial Systems) 中的多样化数据模态 (diverse data modalities)。
Uni-Perceivers (Li et al., 2023d; Zhu et al., 2022b) 通过采用一个模态无关的 Transformer 编码器 (modality-agnostic Transformer encoder),配合轻量级的、模态特定的分词器 (lightweight, modality-specific tokenizers)(将数据投影 (project) 到共享表示空间),来统一来自不同模态的输入和输出。这使得模型能够以统一编码 (unified encoding) 处理来自不同模态的输入,实现任务间的高效协作 (efficient collaboration between tasks)。
Perceiver-IO (Jaegle et al., 2021b) 通过多次使用跨注意力 (using cross-attention multiple times),在一个领域无关的过程 (domain-independent process) 中将任意输入数组 (arbitrary input arrays) 映射到任意输出数组 (arbitrary output arrays)。大部分计算发生在潜空间 (latent space) 中,其大小通常小于输入和输出,这使得该过程即使在处理非常大的输入和输出时也在计算上可行 (computationally tractable)。
ONE-PEACE (Wang et al., 2023a) 为视觉、音频和语言分别使用模态特定的适配器 (modality-specific adapters) 来统一特征,然后使用一个共享的自注意力机制 (shared self-attention mechanism),以及每个模态独立的前馈网络 (distinct feed-forward networks, FFNs)。这种“分离-共享-分离 (separated-sharing-separated)”的设计使得模型能够为多模态任务提供灵活的分支 (flexible branching)。
4.2 Model Design
4.2.1 Transformer
Transformer (Vaswani et al., 2017b) 架构最初作为自然语言处理 (NLP) 领域的突破性技术被提出,现已超越其语言学起源,成为计算机视觉 (CV) 领域的变革者。Transformer架构的出现标志着NLP领域的范式转变,它取代了循环网络和卷积网络,成为语言模型的支柱。Transformer的核心创新在于其自注意力机制 (self-attention mechanism),该机制能够高效地捕捉输入标记 (tokens) 之间的全局依赖关系。
Transformer架构的成功源于其创新性设计,特别是其自注意力机制,该机制使其能够高效地捕捉输入数据中的局部和全局依赖关系。本节将深入探讨构成Transformer的关键组件及其在计算机视觉中的相关性 (Dosovitskiy et al., 2020; Liu et al., 2021, 2022; Touvron et al., 2021)。
自注意力机制 (Self-Attention Mechanism)
自注意力机制是Transformer架构的核心,它使模型能够动态权衡不同输入元素的相关性。在计算机视觉中,该机制通过两个关键组件体现:
-
多头注意力 (Multi-Head Attention):该组件利用学习到的投影,在多个子空间中并行应用自注意力,使模型能够捕捉多样化的上下文关系。
-
缩放点积注意力 (Scaled Dot-Product Attention):该组件通过查询向量 (query) 和键向量 (key) 之间的点积计算注意力分数,并通过键向量维度平方根进行缩放,以在训练过程中稳定梯度。
位置编码 (Positional Encoding)
与循环神经网络或卷积神经网络不同,Transformer缺乏对输入顺序的固有认知。为解决此问题,位置编码被添加到输入嵌入 (embeddings) 中,以注入序列信息。在计算机视觉中,位置编码 (Chu et al., 2021; Wu et al., 2021) 用于感知图像内的空间关系,例如像素的邻近性或物体的排列方式。
前馈神经网络 (Feedforward Networks)
在自注意力机制之后,Transformer采用前馈神经网络进行进一步处理。这些前馈网络由全连接层和激活函数(如 ReLU (Agarap, 2018))组成。它们在使Transformer能够捕捉输入数据中复杂的非线性关系方面发挥着至关重要的作用。
层归一化与残差连接 (Layer Normalization and Residual Connections)
层归一化 (Ba, 2016) 和残差连接 (He et al., 2016b) 对于稳定Transformer的训练至关重要。层归一化应用于每个子层(包括自注意力层和前馈层)之前,对激活值进行归一化。残差连接允许梯度在训练过程中更有效地流动,从而解决了梯度消失问题。
序列到序列架构 (Sequence-to-Sequence Architecture)
虽然Transformer最初是为NLP中的序列到序列 (Sequence-to-Sequence, Sutskever, 2014) 任务设计的,但其序列到序列架构在计算机视觉中也找到了相关性。它支持对序列进行端到端处理,在诸如图像描述或视频分析等输入数据本身具有序列特性的任务中表现出色。
Transformer模型的一个引人入胜的特性在于其处理广泛序列到序列任务的多功能性。这种适应性源于Transformer的基础架构,该架构依赖于自注意力机制来处理序列数据。本质上,大多数任务,无论其复杂性或领域如何,都可以转化为序列到序列的格式。通过使用专用的子模块将多样化的数据类型转换为统一的序列结构,Transformer框架在处理这些任务时获得了显著优势。这种固有的模块化允许无缝集成专用组件,使其极其适合各种应用。
4.2.2 Diffusion Models
扩散模型 (Diffusion models) (Ho et al., 2020) 曾一度处于机器学习的边缘,但最近已成为一类通用且强大 (versatile and powerful) 的生成模型而声名鹊起。它们最初作为一种新颖的去噪框架 (novel framework for denoising) 被提出,如今已发展成为一种变革性的范式 (transformative paradigm),其应用涵盖图像生成 (image generation)、数据补全 (data completion) 等多个领域。
扩散模型最初是作为数据去噪 (denoising data) 问题的解决方案出现的。多年来,它们经历了显著的改进 (significant refinement) (Ho and Salimans, 2022; Lu et al., 2022a; Nichol et al., 2021; Nichol and Dhariwal, 2021; Rombach et al., 2022b),从最初的基本形式演变成了今天所见的复杂模型。这一演变的核心在于扩散过程 (diffusion processes) 的概念:即逐步向图像或数据点添加噪声 (gradually adding noise to an image or data point),然后模型学习迭代地恢复 (iteratively recover) 原始的、无噪声的数据。这一精妙的思想催生了既高效又有效 (both effective and efficient) 的最先进生成模型 (state-of-the-art generative models) 的发展。
扩散模型的核心在于通过扩散过程 (diffusion processes) 进行概率建模 (probabilistic modeling)。其核心原理 (core principles) 包含以下关键要素:
-
扩散过程 (Diffusion Process):逐步向数据引入噪声 (gradual introduction of noise into data) 是一个基本概念。扩散模型利用这个过程来学习强大的似然函数 (powerful likelihood function)。
-
推断网络 (Inference Networks):扩散模型通常使用神经网络 (neural networks) 来执行推断 (inference),使它们能够估计噪声水平 (estimate the noise levels) 并生成高质量样本 (high-quality samples)。
-
采样 (Sampling):扩散模型擅长从复杂数据分布 (complex data distributions) 中生成样本。通过迭代去噪 (iterative denoising),它们能生成逼真且高保真 (realistic and high-fidelity) 的样本。
扩散模型的通用性 (versatility) 延伸到了广泛的机器学习任务中。它们在多个领域做出了重大贡献,包括:
-
图像生成 (Image Generation) (Rombach et al., 2022b; Zhang et al., 2023a):扩散模型已成为图像生成领域强大的竞争者 (formidable contenders),能够从有限数据中创建逼真的图像 (photorealistic images)。
-
数据填补 (Data Imputation) (Kotelnikov et al., 2023; Zheng and Charoenphakdee, 2022):它们在数据填补 (data imputation) 任务中表现出色,能够高精度地恢复 (restore with high accuracy) 缺失或损坏的数据。
-
异常检测 (Anomaly Detection) (Wolleb et al., 2022; Wyatt et al., 2022):扩散模型越来越多地被用于异常检测 (anomaly detection),以发现数据中的异常值或异常情况 (outliers or irregularities)。
-
半监督学习 (Semi-Supervised Learning) (You et al., 2024):它们已在半监督学习 (semi-supervised learning) 中得到应用,使模型能够高效地利用标注和未标注数据 (labeled and unlabeled data) 进行学习。
-
表示学习 (Representation Learning) (Zhong et al., 2023):扩散模型促进了有效的特征学习 (effective feature learning),能够从复杂数据分布中捕获有意义的潜在特征 (meaningful latent features)。
扩散模型使用概率建模 (probabilistic modeling) 来评估数据在不同噪声水平 (different levels of noise) 下出现的可能性。这种概率方法 (probabilistic approach) 能够捕捉复杂的数据模式 (intricate data patterns),并赋能扩散模型在多样化的数据集和任务 (diverse datasets and tasks) 中揭示洞察,展现了它们在跨模态任务 (cross-modal assignments) 中的卓越潜力 (remarkable potential)。
4.2.3 Mixture of Experts, MoE
近年来,计算机视觉领域日益复杂的任务要求对复杂数据分布进行建模,并捕捉视觉数据中的细粒度模式。传统的神经网络虽然强大,但往往难以有效处理这些复杂性。这为 MoE (Gormley & Fr¨uhwirth-Schnatter, 2019) 框架作为计算机视觉中一个引人注目的范式的出现奠定了基础。在计算机视觉中采用 MoE 的动机源于解决这些复杂性的需求。MoE 模型提供了一种解决方案,它将任务分解为子任务,每个子任务由一个专家网络管理。该范式利用专家群体的集体智慧做出明智的预测,使其有望同时应对各种挑战。
混合专家模型 (Mixture of Experts, MoE) 框架的核心在于一个明确定义的数学公式。将输入数据表示为 x,专家网络表示为 E₁, E₂, . . . , Ek,其中 k 代表专家数量。其主要思想是基于输入数据创建专家网络预测的加权混合。这可以表示为 Mᵢ(x) = Eᵢ(x),其中 Mᵢ(x) 代表第 i 个专家网络对输入 x 的输出。这些输出通过加权求和组合成最终预测 P(x):
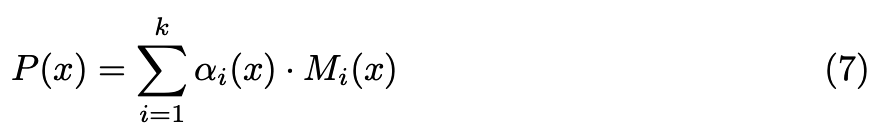
混合权重 αᵢ(x) 由混合门 (mixture gates) 或开关 (switches) 决定,可以建模为在门控逻辑值 (gating logits) 上的 softmax 操作:

门控逻辑值 gᵢ(x) 通常从输入数据中学习得到,并控制每个专家对最终预测的贡献。训练 MoE 模型涉及优化专家网络和门控机制的参数,以最小化特定任务合适的损失函数。该公式巧妙地利用专业专家的混合来基于输入数据进行预测。
混合专家模型 (MoE) 的固有特性使其成为一个强大的范式,尤其非常适合多任务学习场景。通过建模多个专家分支,MoE 模型展现出专注于不同任务的独特能力。这种专业化不仅能实现显著的参数和计算节省,还引入了一种更原则性的建模方法。MoE 框架本质上承认不同任务可能需要专业化的知识,这种认识与多任务学习的实际需求相吻合。与传统的单任务模型相比,MoE 的设计在通用多任务模型领域中具有显著优势。专业的专家分支不仅提升了任务特定性能,还促进了跨任务的高效知识迁移。这种固有的模块化允许在每个专家内部融入领域特定知识或架构变体,从而进一步增强 MoE 模型的适应性。此外,MoE 模型天生具备处理不同复杂性和数据分布任务的能力。这种灵活性在任务跨越多个领域(从自然语言处理到计算机视觉及其他领域)的应用中尤其宝贵。通过参数共享实现的效率提升以及专业知识专业化的原则性方法,突显了 MoE 模型在多任务学习场景中的变革潜力。
总之,MoE 模型 (Du et al., 2022; Fedus et al., 2022; Lewis et al., 2021; Riquelme et al., 2021) 的独特特性,植根于对多个专家分支的建模,使其能够在多任务学习环境中表现出色。其高效分配资源、专注于任务以及适应不同领域的能力,使 MoE 模型成为开发通用多任务模型的一个引人注目的选择,既提供了实际优势,也符合合理的建模原则。
4.3 Multi-Task Output
视觉任务的输出也具有不同的格式。这些输出可能是空间数据 (spatial data)(例如边缘 (edges)、边界框 (bounding boxes) 和掩码 (masks)),也可能代表语义内容 (semantic content)(例如分类标签 (categorizing labels) 或描述 (descriptions))。
最初,只有特定的模型 (specific models) 执行特定的任务。因此,最直接的方法是直接联合训练多个模型 (directly train multiple models together),以获得一个模型能完成多个任务的要求。但这类模型的计算量和参数量 (amount of calculation and parameters) 非常大,训练成本 (training cost) 令人难以接受。后来,研究人员发现可以设计一个表达能力更强 (stronger expressive ability) 的模型来学习多个任务,共享同一个模型 (share the same model),并仅使用特定的“头”(heads) (only use specific heads) 来解码 (decode) 不同的任务。在后续章节 (following section),将深入探讨这些通用特征 (universal features) 如何被转换 (transmuted) 成符合不同任务要求的格式。
4.3.1 Specific Decode
Mask R-CNN (He et al., 2017) 是一个开创性的统一模型 (pioneering unified model),它实现了视觉中的多任务处理 (multi-tasking),包括实例分割 (instance segmentation) 和目标检测 (object detection)。Mask R-CNN 首先执行目标检测 (object detection) 以获得对应的锚框 (anchor box),然后对框内的特征进行二元分类 (binary classification) 以获得对应的掩码 (mask)。
Mask DINO (Li et al., 2023c) 为共享模型 (one shared model) 设计了不同的解码器 (different decoders),分别用于语义分割 (semantic segmentation)、实例分割和目标检测。
AiT (Ning et al., 2023) 为了支持多任务,对深度图 (depth) 和实例分割使用了独立的 VQ-VAE 模型 (separate VQ-VAE models),根据输入的任务令牌 (input task token) 预测条件化的标记序列 (predicting token sequences conditioned on)。
MultiMAE (Bachmann et al., 2022) 支持如图像分类、语义分割和深度估计等任务。对于不同任务,它使用独立的解码器 (separate decoders) 来根据可见的标记 (visible markers) 重建被掩码的标记 (reconstruct masked markers)。每个任务都需要一个对应的解码器,模型的计算成本 (computational cost) 随任务数量线性增长 (scales linearly)。
MulT (Bhattacharjee et al., 2022) 采用了架构相同但参数集不同的任务特定解码器 (task-specific decoders with identical architectures but distinct parameter sets),并为每个解码器附加任务特定的“头”(appending task-specific heads)。例如,一个同时训练用于语义分割和深度预测的模型会有两个头:一个用于语义分割(具有 K 个通道和 softmax 激活),另一个用于深度估计(具有单个通道和 sigmoid 激活)。
MetaTransformer (Zhang et al., 2023c) 从输入数据中学习表征 (representations),然后将这些表征输入主要由多层感知机 (MLPs) 组成的任务特定“头”(task-specific heads)。其任务特定“头”会根据涉及的模态和任务而变化 (vary with the modalities and tasks involved)。
OFASYS (Bai et al., 2022) 为不同模态设计了不同的解码方法 (different decoding methods),并将所有解码器作为适配器 (adapters) 添加到通用网络中。这通常是编码器的逆过程 (reverse process of encoders),例如将标记 (tokens) 转换为文本,将代码 (code) 转换为图像等。OFASYS 系统包含一个调度器 (scheduler),它根据槽位类型或模式 (slot type or mode) 自动将数据路由 (automatically routes the data) 到合适的后处理器 (postprocessors) 和适配器。
UniT (Hu and Singh, 2021) 将任务特定的预测“头”(task-specific prediction heads) 应用于每个任务的不同解码器状态 (different decoder states for each task),并将任务分为三种“头”来实现:分类头 (class head)、边界框头 (box head) 和属性头 (attribute head)。
12-in-1 (Lu et al., 2020) 整合了多种任务 (groups a variety of tasks)(基于词汇的VQA、图像检索、指代表达式、多模态验证),每个任务都有一个任务特定的“头”(each task having a task-specific head)。对齐的图像-描述对分数 hIMG 和 hCLS 可以通过共享模型 (shared model) 获得:
![]()
其中 Wi ∈ R d×1 在 COCO 和 Flickr30k 图像检索任务 (image retrieval tasks) 中共享 (shared)。
4.3.2 Unified Decode
Maskformer
Cheng et al. (2021) 和 Mask2Former (Cheng et al., 2022) 使用通用的 Transformer 框架,将语义分割和实例分割任务统一到一个任务查询 (task query) 中,以获得不同的掩码表达 (mask expressions)。
OneFormer (Jain et al., 2023) 引入了一个基于 Transformer 的统一框架来处理多样化的图像分割任务。该模型采用任务令牌 (task tokens) 来指定不同任务并促进动态任务推断 (dynamic task inference)。此外,它还结合了任务条件化的查询构建 (task-conditioned query formulation) 和查询-文本对比损失 (query-text contrastive loss),从而实现更精确的任务间 (inter-task) 和类间 (inter-class) 区分。
Pix2Seq-D (Chen et al., 2022a) 将图像和视频的全景分割 (panoptic segmentation) 转化为掩码生成任务,并使用扩散模型 (diffusion model) 来实现这一生成过程。
Pix2seq v2 (Chen et al., 2022b) 使用提示学习 (prompt learning) 来指定任务,通过将提示输入网络。通过标准化每个任务的输出格式,序列输出能够适应提示,从而根据提供的描述生成任务特定的结果。
OFA (Wang et al., 2022c) 受到 Pix2Seq v2 的启发,使用一个统一的词汇表将文本、图像和对象离散化为标记 (tokens),该词汇表包含量化图像标记 (quantized image tokens) 和稀疏视觉表示 (sparse visual representations) 等组件。
UNINEXT (Yan et al., 2023) 将多个实例感知任务整合到一个统一的对象发现与检索框架中,每个任务通过特定提示 (specific prompts) 进行区分。获取结果的过程被构建为基于提出的实例-提示匹配分数 (instance-prompt matching scores) 的检索任务 (retrieval task)。
OMGSeg (Li et al., 2024) 进一步扩展了这种统一性,涵盖了广泛的分割任务,处理各种视觉模态 (visual modalities)、不同的感知粒度 (perception granularities) 以及具有挑战性的交互式或开放词汇 (interactive or open-vocabulary) 场景。所有任务输出被统一为单一的查询表示 (single query representation),并采用共享的 Transformer 解码器 (shared Transformer decoder) 来利用任务查询 (task queries) 与视觉特征 (visual features) 之间的关系。
Uni-Perceivers
Li et al. (2023d) 和 Zhu et al. (2022b) 将不同任务表述为一个统一的最大似然估计问题 (unified maximum likelihood estimation problem)。给定输入 x ∈ X 和候选目标集 Y,目标是识别具有最大似然值的 ŷ ∈ Y:
![]()
其中 P(x, y) 是联合概率分布 (joint probability distribution)。该联合概率是 x 和 y 表示之间的余弦相似度 (cosine similarity):
![]()
其中 f(·) 是 Transformer 编码器 (Transformer encoder),τ > 0 是一个可学习的温度参数 (learnable temperature parameter)。
对于具有多任务或多模态结构 (multi-task or multimodal structure) 的输出,Perceiver-IO (Jaegle et al., 2021b) 为每个任务或模态学习一个查询 (query)。该信息使网络能够区分不同的任务或模态查询,就像位置编码 (positional encoding) 允许注意力区分不同位置一样。
Unified-IO (Lu et al., 2022b) 将特征转换为离散标记序列 (discrete token sequences),并根据不同的任务表示 (task representations) 运行不同的解码模块 (decoding modules),例如用于图像分割的 VQVAE 解码器,以及用于 VQA 或目标检测的 SentPiece 解码器。
最近,InstructDiffusion (Geng et al., 2024) 提出了一种新颖的通用模型接口 (generalist modeling interface),将各种感知 (perception) 和生成 (generation) 任务整合到一个直观的图像编辑过程 (image manipulation process) 中。该模型充分利用了扩散模型 (Diffusion, Rombach et al., 2022b) 框架的潜力,在连续像素空间 (continuous pixel space) 中直接生成结果,其生成过程受控于 (conditioned on) 特别设计的任务指令 (task instructions)。这项工作通过将泛化 (generalization) 构建为一个统一的任务 (unified task),为未来视觉通用模型 (vision generalist models) 的研究铺平了道路。


参考文献:https://arxiv.org/pdf/2506.09954#pdfjs.action=download