LLMs之Memory:《LLMs Do Not Have Human-Like Working Memory》翻译与解读
LLMs之Memory:《LLMs Do Not Have Human-Like Working Memory》翻译与解读
导读:该论文通过三个精心设计的实验,证明了当前的大型语言模型(LLMs)缺乏类似人类的工作记忆。实验结果表明,LLMs无法在没有明确外部提示的情况下,内部维持和操作信息,导致不真实的响应和自我矛盾。该研究强调了LLMs在认知能力上的局限性,并鼓励未来的研究将工作记忆机制集成到LLMs中,以提高它们的推理能力和类人程度。
>> 背景痛点
● 人类的工作记忆是一个活跃的认知系统,不仅可以临时存储信息,还可以处理和利用信息。
● 缺乏工作记忆会导致不真实的对话、自我矛盾以及难以完成需要心理推理的任务。
● 现有的大型语言模型(LLMs)在一定程度上表现出类似人类的能力,但它们是否具备人类一样的工作记忆能力仍然未知。
● 之前的研究使用N-back任务来评估LLM的工作记忆,但这些测试的关键信息存在于LLM可以访问的输入上下文中,这与人类测试有显著不同。
● 需要设计新的实验,关键信息不能明确地存在于上下文中,以更准确地评估工作记忆。
>> 具体的解决方案
● 设计了三个实验来验证LLMs是否缺乏类似人类的认知能力,特别是工作记忆:
● 数字猜测游戏(Number Guessing Game)
● 是非游戏(Yes-No Game)
● 数学魔术(Math Magic)
● 这些实验旨在测试LLMs是否可以在没有明确外部化到上下文中的情况下,内部保持信息。
>> 核心思路步骤
* 数字猜测游戏:
● 让LLM“思考”一个1到10之间的数字。
● 询问LLM一系列问题,例如“你正在想的数字是7吗?回答是或否。”
● 记录LLM对每个数字回答“是”的频率,并将其视为概率。
● 如果这些概率之和与1显著偏离,则表明LLM要么没有思考一个特定的数字,要么在说谎。
* 是非游戏:
● 让LLM“想象”一个物体。
● 提出一系列比较问题,涉及该物体和其他参考物体,例如“该物体比大象重吗?”
● 记录LLM在出现自我矛盾之前完成的问题数量。
● 如果LLM在所有问题中都没有出现矛盾,则认为该试验通过。
* 数学魔术:
● 让LLM“思考”四个数字,并执行一系列操作,包括复制、旋转和移除。
● 这些操作经过精心设计,最终只剩下两个数字,并且这两个数字是相同的。
● 测量LLM正确完成任务的试验比例。
模型评估:
● 在多种模型系列(GPT、Qwen、DeepSeek、LLaMA)和推理方法(CoT、o1-like reasoning)上进行实验。
● 分析实验结果,以确定LLMs是否表现出类似人类的认知行为。
>> 优势
● 实验设计巧妙:三个实验都避免了将关键信息明确地放在上下文中,从而更准确地评估了LLM的工作记忆。
● 多样化的模型评估:在多种模型系列和推理方法上进行了实验,从而更全面地了解了LLM的工作记忆能力。
● 结果一致:所有实验的结果都表明,LLMs缺乏类似人类的工作记忆。
● 强调了LLM的局限性:指出了LLM在内部表示和操作瞬时信息方面的不足。
>> 结论和观点
● LLMs不具备类似人类的工作记忆。
● LLMs无法在多个推理步骤中内部表示和操作瞬时信息,而是依赖于即时提示上下文。
● 即使是高级的提示策略,例如CoT提示,也只能在需要内部状态管理的任务上产生微小的改进。
● LLMs的这一局限性会导致不真实的响应、自我矛盾以及无法进行心理操作。
● 未来的研究应该侧重于将工作记忆机制集成到LLMs中,以增强它们的推理能力和类人程度。
● 实验结果表明,较新的模型不一定优于较旧的模型。
● 使用CoT推理并不能提高性能。
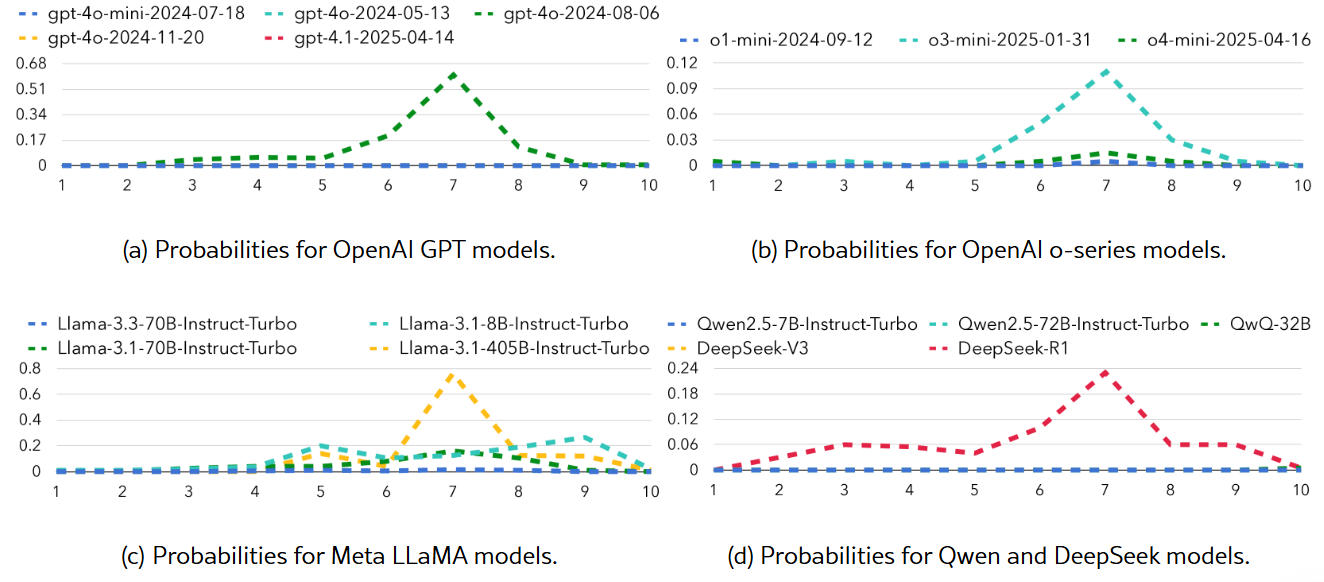
● LLMs在数字选择上存在偏差,倾向于选择数字7。
目录
《LLMs Do Not Have Human-Like Working Memory》翻译与解读
Abstract
1、Introduction
Figure 1:When ChatGPT says it already has a number in mind, and it is not 4, how can we know whether ChatGPT is lying?图 1:当 ChatGPT 说它心里已经有一个数字,而且这个数字不是 4 时,我们怎么知道 ChatGPT 是否在说谎?
Figure 2:Probabilities of model answering “Yes” for each number from one to ten.图 2:模型对从 1 到 10 的每个数字回答“是”的概率。
Conclusion
《LLMs Do Not Have Human-Like Working Memory》翻译与解读
| 地址 | 地址:[2505.10571] LLMs Do Not Have Human-Like Working Memory |
| 时间 | 2025年4月30日 |
| 作者 | Jen-tse Huang Kaiser Sun Wenxuan Wang Mark Dredze |
Abstract
| Human working memory is an active cognitive system that enables not only the temporary storage of information but also its processing and utilization. Without working memory, individuals may produce unreal conversations, exhibit self-contradiction, and struggle with tasks requiring mental reasoning. In this paper, we demonstrate that Large Language Models (LLMs) lack this human-like cognitive ability, posing a significant challenge to achieving artificial general intelligence. We validate this claim through three experiments: (1) Number Guessing Game, (2) Yes or No Game, and (3) Math Magic. Experimental results on several model families indicate that current LLMs fail to exhibit human-like cognitive behaviors in these scenarios. By highlighting this limitation, we aim to encourage further research in developing LLMs with improved working memory capabilities. | 人类的工作记忆是一种活跃的认知系统,它不仅能够暂时存储信息,还能对其进行处理和利用。如果没有工作记忆,个体可能会产生不切实际的对话,表现出自相矛盾,并且难以完成需要进行思维推理的任务。在本文中,我们证明了大型语言模型(LLMs)缺乏这种类似人类的认知能力,这对实现通用人工智能构成了重大挑战。我们通过三个实验来验证这一论断:(1)猜数字游戏,(2)是或否游戏,(3)数学魔术。在多个模型家族上的实验结果表明,当前的 LLMs 在这些场景中未能展现出类似人类的认知行为。通过强调这一局限性,我们旨在鼓励进一步研究,以开发具有改进工作记忆能力的 LLMs。 |
1、Introduction
| Imagine the following scenario: You select a number between one and ten. When ready, you are asked, “Is the number greater than five?” Upon answering, others can infer that the number has likely entered your conscious awareness, as its clear perception is necessary for making the comparison and providing a response. Such conscious awareness is commonly referred to as Working Memory (Atkinson & Shiffrin, 1968). In contrast to long-term memory, working memory is the system required to maintain and manipulate information during complex tasks such as reasoning, comprehension, and learning (Baddeley, 2010). Deficits in working memory can impair information processing and hinder effective communication (Gruszka & Nkecka, 2017; Cowan, 2014). | 想象以下场景:您选择一个 1 到 10 之间的数字。准备好后,有人问您:“这个数字大于 5 吗?”在回答时,其他人可以推断出这个数字很可能已经进入了您的意识,因为清晰地感知到它对于进行比较和给出回答是必要的。 这种意识通常被称为工作记忆(阿特金森和希夫林,1968 年)。与长期记忆不同,工作记忆是完成推理、理解、学习等复杂任务时维持和处理信息所必需的系统(巴德利,2010 年)。工作记忆的缺陷会损害信息处理并妨碍有效沟通(格鲁斯卡和恩凯卡,2017 年;考恩,2014 年)。 |
| In this paper, we demonstrate that, despite exhibiting increasingly human-like abilities (Huang et al., 2024b, a), Large Language Models (LLMs) lack a fundamental aspect of human cognition: working memory. As a result, LLMs generate unrealistic responses, display self-contradictions, and fail in tasks requiring mental manipulation. Previous studies have used the N-back task (Kirchner, 1958) to evaluate the working memory of LLMs (Gong et al., 2024; Zhang et al., 2024). However, a fundamental limitation of these tests is that the critical information needed to answer correctly is in the input context accessible to LLMs. This differs markedly from human testing, where participants cannot view prior steps. LLMs, in contrast, can simply attend to earlier input tokens retained in their context window. To more accurately assess working memory, it is essential to design experiments in which the key information is not explicitly present in the context. The core challenge is to prove that there is actually nothing in LLMs’ mind without knowing what exactly is in their mind. To investigate this limitation, we design three experiments—(1) Number Guessing Game, (2) Yes-No Game, and (3) Math Magic—that test whether LLMs can maintain information internally without explicitly externalizing it in the context. Experimental results reveal that LLMs consistently fail in this capacity, regardless of model family (GPT (Hurst et al., 2024), Qwen (Yang et al., 2024), DeepSeek (Liu et al., 2024; Guo et al., 2025), LLaMA (Grattafiori et al., 2024)) or reasoning approach (Chain-of-Thought (CoT) (Wei et al., 2022) or o1-like reasoning (Jaech et al., 2024)). | 在本文中,我们将证明,尽管大型语言模型(LLMs)展现出越来越接近人类的能力(黄等人,2024 年 b,a),但它们缺乏人类认知的一个基本方面:工作记忆。因此,LLMs 会产生不切实际的回答,表现出自相矛盾,并在需要心理操作的任务中失败。先前的研究使用 N-back 任务(Kirchner,1958 年)来评估大语言模型(LLM)的工作记忆(Gong 等人,2024 年;Zhang 等人,2024 年)。然而,这些测试的一个根本局限在于,正确回答所需的关键信息在大语言模型可访问的输入上下文中。这与人类测试明显不同,在人类测试中,参与者无法查看之前的步骤。相比之下,大语言模型只需关注其上下文窗口中保留的早期输入标记即可。为了更准确地评估工作记忆,设计实验时必须确保关键信息不在上下文中明确呈现。 核心挑战在于,在不了解大语言模型具体思维内容的情况下,证明其内部确实没有某些信息。为了探究这一局限,我们设计了三个实验——(1)数字猜谜游戏,(2)是或否游戏,以及(3)数学魔术——来测试大语言模型是否能够在不将信息明确外显于上下文的情况下在内部保持信息。实验结果表明,无论模型属于哪个家族(GPT(Hurst 等人,2024 年)、Qwen(Yang 等人,2024 年)、DeepSeek(Liu 等人,2024 年;郭等人(2025 年)、LLaMA(格拉塔菲奥里等人,2024 年)或推理方法(链式思维(CoT)(魏等人,2022 年)或类似 o1 的推理(杰奇等人,2024 年))。 |
Figure 1:When ChatGPT says it already has a number in mind, and it is not 4, how can we know whether ChatGPT is lying?图 1:当 ChatGPT 说它心里已经有一个数字,而且这个数字不是 4 时,我们怎么知道 ChatGPT 是否在说谎?
Figure 2:Probabilities of model answering “Yes” for each number from one to ten.图 2:模型对从 1 到 10 的每个数字回答“是”的概率。
Conclusion
| In this study, we present three carefully designed experiments to investigate whether LLMs possess human-like working memory for processing information and generating responses. Across all experiments, the results reveal a consistent pattern: LLMs do not exhibit behavior indicative of a functional working memory. They fail to internally represent and manipulate transient information across multiple reasoning steps, relying instead on the immediate prompt context. Even advanced prompting strategies, such as CoT prompting, yield only marginal improvements on tasks requiring internal state management. This limitation leads to unrealistic responses, self-contradictions, and an inability to perform mental manipulations. We hope these findings encourage future research on integrating working memory mechanisms into LLMs to enhance their reasoning capabilities and human-likeness. | 在本研究中,我们精心设计了三个实验来探究大型语言模型(LLMs)是否具备类似人类的工作记忆来处理信息和生成回应。在所有实验中,结果呈现出一致的模式:LLMs 并未表现出具有功能性的工作记忆的行为特征。它们无法在多个推理步骤中内部表示和操作瞬时信息,而是依赖于即时的提示上下文。即使采用先进的提示策略,如链式思维(CoT)提示,在需要内部状态管理的任务上也仅能带来微小的改进。这种局限性导致了不切实际的回应、自相矛盾以及无法进行心理操作。我们希望这些发现能鼓励未来的研究将工作记忆机制整合到 LLMs 中,以增强其推理能力和类人特性。 |