(笔记)1.web3学习-区块链技术
1. 简介
1. 区块链是一个很慢的数据库
2. 区块链不等于比特币,基于区块链技术的一种加密货币
3.目前学习是否晚,目前还是一个较为萌芽的阶段,不要以为自己错过了比特币大涨的时刻。学习区块链已经超越很多人
2.比特币
1.比特币密码学原理
1. 比特币中主要用到了密码学中两个功能: 1.哈希 2.签名。密码学中的哈希函数(cryptographtic hash function),
一、哈希函数
哈希函数主要有三个特性:1、碰撞特性(collision resistance);2、隐秘性(Hiding);3、谜题友好(puzzle friendly)。比特币使用的加密函数为SHA-256
1、collision resistance
collision resistance 即为输入两个输入值X,Y,经过哈希函数之后得到H(X)=H(Y),即为哈希碰撞。利用哈希碰撞,可以检测对信息的篡改。假设输入x1,哈希值为H(x1),此时很难找到一个x2,使得H(x1)=H(x2)。
2、Hiding
hiding 意思是哈希函数的计算过程是单向的,不可逆的。但前提要满足输入控件足够大,且分布均匀。通常我们在实际操作中会使用添加随机数的方法。假设给定一个输入值X,可以算出哈希值H(x),但是不能从H(x)推出X。
3、puzzle friendly
- 特指哈希值的计算过程无法被预测或优化,必须通过大量计算才能找到符合条件的输入
- 通常我们限定输出的哈希值在一定范围内,即H(block header + nonce) < target (block header是区块链的链头),这个确定链头范围的过程即为挖矿。.
- 关于目前的target难度可以通过http://blockexplorer.com/q/getdifficulty来得到,下一个难度可以通过http://blockexplorer.com/q/estimate来获得。难度的变化情况可以查看Bitcoin network graphs。
二、签名
签名就相当于每个人的开户行账号。公钥签名,即开户账号,验证签名用私钥,即为账号密码。以此来确保比特币的安全传输。
签名算法是 椭圆曲线数字签名算法 (ECDSA)
2.比特币的数据结构
1. 比特币系统中使用的数据结构主要是以下两种:
- 哈希指针(hash pointers)
- merkle树(merkle tree)(默克尔树)
哈希指针用于区块之间的连接作用,而merkle tree用于每个区块内部交易之间的连接作用。哈希指针与merkle tree的关系如下图所示:
2. 哈希指针(Hash Pointers)
普通指针与Hash指针
普通指针存储的是某个结构体在内存中的地址。假如P是指向一结构体的指针,那么P里面存放的就是该结构体在内存中的起始位置。
哈希指针除了要存地址之外,还要保存该结构体的哈希值H(x) 。这样的好处是:从这个哈希指针,不仅可以找到该结构体的位置,同时还能够检测出该结构体的内容有没有被篡改,因为我们保存了它的哈希值。
3. 区块链和普通的链表
- 比特币中最基本的结构就是区块链,区块链就是一个一个区块组成的链表。区块链和普通的链表相比有什么区别:
- 用哈希指针代替了普通指针(B block chain is a linked list using hash pointers)
- 区块链第一个区块叫作创世纪块(genesis block) ,最后一个区块叫做最近产生的区块(most recent block), 每一个区块都包含指向前一个区块的哈希指针。
- 普通链表可以改变任意一个元素,对链表中其他元素是没有影响的。而区块链是牵一发而动全身,如果区块链中任一块被修改,则后面所有的区块都要发生变动(因为后一个区块头部存储是前面所有区块求H()后的值),所以只需要保存最后一个哈希值,就可以判断区块链有没有改变。针对这一特性,比特币没有要保存所有区块的内容,可以只保留最近的几千个区块。如果要用到以前的区块,可以向系统中其他节点要这个区块。假设整个区块链当中有些节点是有恶意的,它给出块算出它的哈希值,与保留的区块的哈希值对比即可判断是否为异常节点。
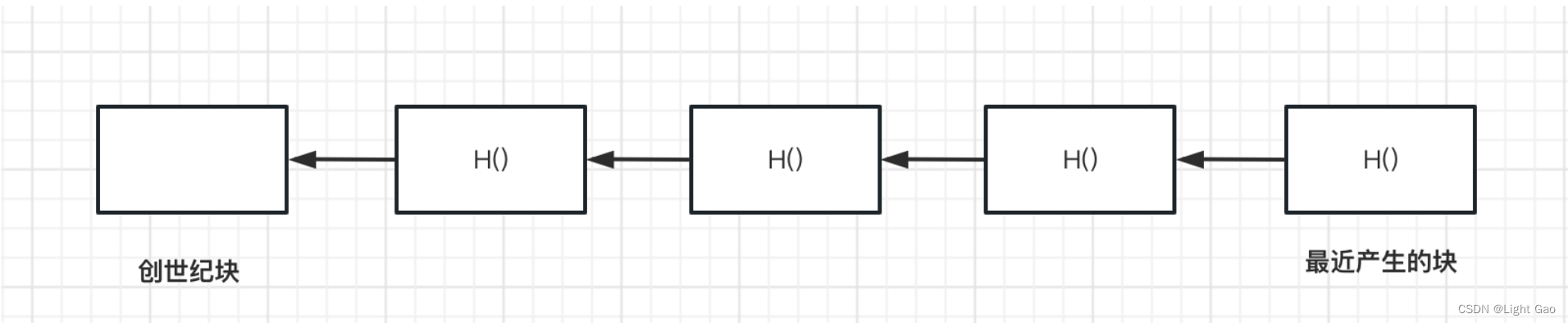
- 由上图可看到,区块链系统中的的每个节点可以获得最近一个区块的哈希值H(recent block),
- 从而就可以追溯到创世纪块。通过哈希指针的链式结构,也可以知道区块内容是否被篡改,因为只要某个区块A被篡改,它的哈希值就会改变,它之后区块B的哈希指针就不会指向A了,这样系统会很快知道A被篡改。或者篡改者从区块A一直改到最新区块,到最后最新区块的哈希值也会改变,跟系统中保存的最近区块哈希值H(recent block)对比,也就很快发现是否被篡改。
2.Merkle Tree(树形结构)(默克尔树)
- Merkle tree跟二叉树很类似,只不过把普通指针同样换成了哈希指针。
- Merkle tree在每个区块内部将各个交易连接起来了,如下图所示:
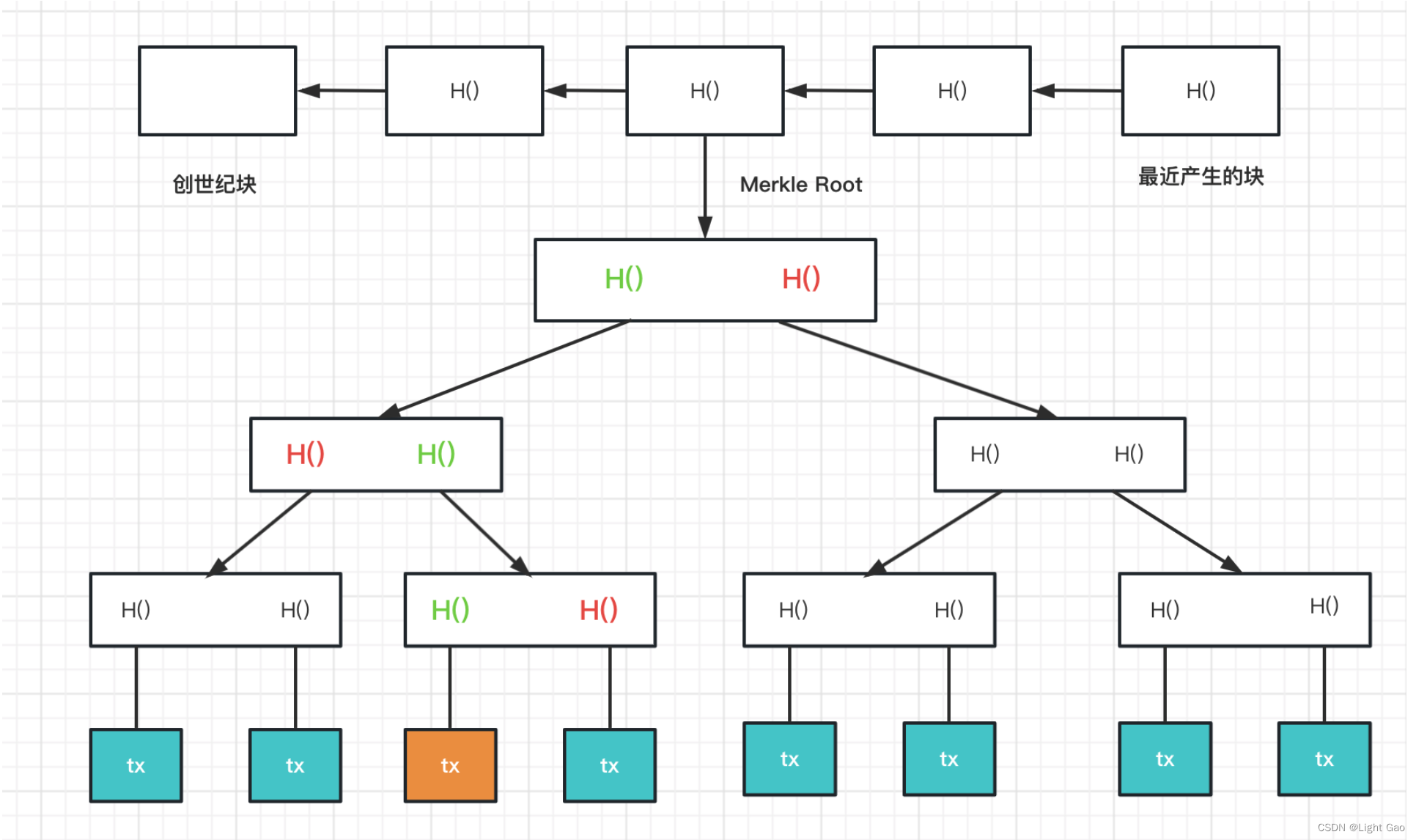
这个树的最下面是的叶子节点是区块体(block body)里的所有交易,每个交易取哈希值,相邻交易的哈希值结合起来一起取哈希,层层往上取哈希,直到得到最后一个哈希值,这个哈希值也就是根哈希值(root hash),并存在区块头(block header)。
从上面分析得到,只要记住了根哈希值(root hash),就可以检测出对树的任何节点的修改。要想改变其他节点的哈希值同时保证根哈希值的不变,就必须人为制造哈希碰撞,但通过哈希的性质知道,这是不可能的。
Merkle tree 的作用:提供Merkle proof
Merkle proof是Merkle tree内的从最底层的某个交易出发到最顶部根哈希的一条路径。如上图中最下面的黄色交易开始到最底部的路径就是一个merkle proof。
在比特币区块链网络中有很多节点,包括计算机、手机、矿机、服务器等等。在所有节点中分为:全节点和轻节点。
全节点(full node):保存了区块的所有内容,区块头和区块体。轻节点(light node):只保存了区块头,比如手机中的比特币钱包。
问题:如何向一个轻节点证明某个交易是写入区块链的?
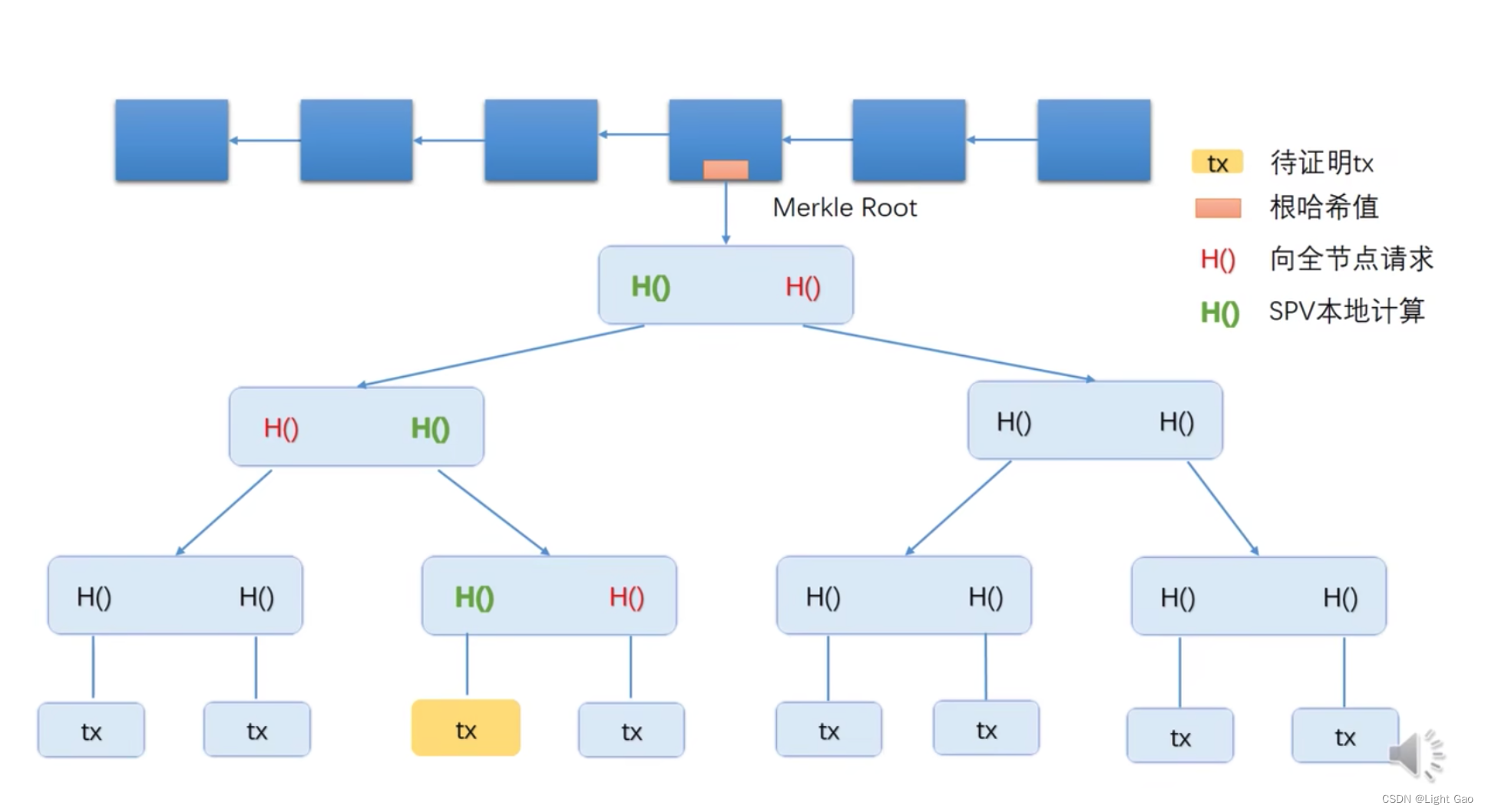
- 假设某个轻节点想知道图中黄色的交易,是否包含在了merkle tree里面。该轻节点没有包含交易列表,没有这颗merkle tree的具体内容,只有一个根哈希值。这时轻节点向一个全节点发出请求,请求证明黄色的交易被包含在这颗merkle tree里面的merkle proof(由交易者提供)。全节点收到这个请求之后,只需要将图中标为红色的这三个哈希值发给轻节点即可。
- 有了这些哈希值之后,轻节点可以在本地计算出图中标为绿色三个哈希值。首先算出黄色交易的哈希值,即它正上方的那个绿的哈希值,然后跟旁边红色的哈希值拼接起来,可以算出上层节点绿色的哈希值。
- 然后再拼接,再算出上层绿色哈希值,再拼接,就可以算出整棵树的根哈希值。
- 轻节点把这个根哈希值和block header里的根哈希值比较一下,就能知道黄色的交易是否在这颗merkle tree里。
- 全节点在merkle proof里提供的这几个哈希值,就是从黄色的交易所在的节点的位置到树根的路径上用到的这些哈希值。轻节点收到这样一个merkle proof之后,只要从下往上验证,沿途的哈希值都是正确的即可。(验证时只能验证该路径的哈希值,其他路径是验证不了的,即该图中红色的哈希值是验证不了的)
- 这样是否不安全呢? 假如黄色交易被篡改,它的哈希值发生了变化,那能不能调整旁边红色的哈希值,使得它们拼接起来的哈希值是不变的呢? 不行,根据collision resistance,这是不可行的。
问题:如何证明merkle tree里面没有包含某个交易?
1.全节点将整个区块所有交易信息发给轻节点,这样可以证明某个交易不在区块中,但这是非常不高效的方法且比较笨的方法。
2.思路还是根据merkle proof计算根哈希值,轻节点向全节点对这个交易发出请求,全节点为了证明此交易不在区块链中。
全节点只需以下这样做即可:
- 对区块中所有交易的哈希值进行排序,然后计算要证明的交易的哈希值,根据二分查找法来确定这个交易哈希值的位置,再将此位置相邻的2个交易merkle proof发送给轻节点。
轻节点只需以下这样做即可:
- 轻节点收到merkle proof后,根据merkle proof计算得到最后的根哈希值(root hash),若计算得到的根哈希值跟本地的区块头中的根哈希值比较一样,则证明此交易一定不在区块链中,因为如果在的话,最后计算出来的根哈希值比较必然是不一样的。
- 可以把整棵树传给轻节点,轻节点收到后验证树的构造都是对的,每一层用到的哈希值都是正确的,说明树里只有这些叶节点,要找的交易不在里面,就证明了proof of non-membership。问题在于,它的复杂度是线性的θ(n),是比较笨的方法。如果对叶节点的排列顺序做一些要求,比如按照交易的哈希值排序。每一个叶节点都是一次交易,对交易的内容取一次哈希,按照哈希值从小到大排列。要查的交易先算出一个哈希值,看看如果它在里面该是哪个位置。比如说在第三个第四个之间,这时提供的proof是第三个第四个叶节点都要往上到根节点。如果其中哈希值都是正确的,最后根节点算出的哈希值也是没有被改过的,说明第三、四个节点在原来的merkle tree里面,确实是相邻的点。要找的交易如果存在的话,应该在这两个节点中间。但是它没有出现,所以就不存在。其复杂度也是log形式,代价是要排序。排好序的叫作sorted merkle tree。比特币中没有用到这种排好序的merkle tree,因为比特币中不需要做不存在证明。
3.比特币协议
比特币协议是一套技术规则,定义了比特币网络如何运作,包括交易的创建、验证和共识机制。它基于密码学和分布式系统,确保去中心化、安全性和不可篡改性。
1.双花攻击(double spending attack)
定义:
- 双花是指同一笔比特币被多次花费的行为,这是传统数字货币面临的核心问题之一。
比特币如何解决双花
- 比特币采用UTXO(详见2 BTC实现)模型,每笔交易都会消耗之前的UTXO,并生成新的UTXO。因此,一旦某个UTXO被用于交易,它就不能再次被使用。比特币网络中的节点会验证交易是否引用了有效且未花费的UTXO,若UTXO已被花费,则交易无效,双花攻击无法成功。 例如,A拥有一个包含5 BTC的UTXO,并将其全部发送给B,该UTXO被标记为已花费,新的UTXO由B持有。此时,如果A试图再用这5 BTC进行另一笔交易,例如转给C,节点会检查A是否仍有可用的UTXO。如果没有足够的UTXO,交易将被拒绝。
2.交易机制
2.1.交易结构
- 输入(Inputs):引用之前的未花费交易输出(UTXO),证明你有权花费这些比特币。
- 输出(Outputs):指定比特币的接收地址和金额。
- 签名:使用私钥对交易签名,确保只有比特币的拥有者可以发起交易。
2.2.交易流程
用户创建交易并用私钥签名 -> 交易被广播到比特币网络 -> 节点验证交易的合法性(签名有效、输入未被双花等)-> 矿工将交易打包进一个新区块,通过PoW添加到区块链 -> 交易确认后,接收方可以看到比特币到达。
3.轻节点(light node)和全节点(full node)
1.3.1.全节点(Full Node):
- 存储整个区块链的完整副本(截至2025年3月,已超过500GB)。
- 独立验证所有交易和区块的合法性,遵循协议规则。
- 增强网络的安全性和去中心化,但需要较高的存储和带宽。
1.3.2.轻节点(Light Node):
- 也称为SPV节点(简单支付验证,Simplified Payment Verification)。
- 只下载区块头(约80字节/区块),不存储完整交易数据。
- 依赖全节点提供相关交易信息来验证支付。
- 优点是占用资源少,适合移动设备;缺点是安全性较低,依赖其他节点。
1.3.3.轻节点与全节点对比:
- 全节点对网络健康至关重要,轻节点则更注重便捷性。
- 轻节点通过检查区块头中的Merkle根验证交易,确认其是否在链上。
4.区块链构成
1. 链式结构:由按时间顺序连接的区块组成,每个区块包含一批交易。
2. 区块链有块头Block header(80字节):包含宏观信息:
-
版本号:标识区块的协议版本。
-
前一个区块的哈希(Parent Block Hash):链接到前一个区块,形成链条。
-
默克尔根(Merkle Root):本区块所有交易的哈希摘要,用于快速验证交易是否存在。
-
时间戳Timestamp:区块的大致生成时间。
-
难度目标(Difficulty Target)(nBits):当前挖矿的难度值。
-
随机数Nonce:矿工调整的随机数,用于满足工作量证明(PoW)。
3.区块链内容Block body:
- 交易列表:包含该区块的所有交易列表(包括Coinbase交易)。
- Merkle 树(Merkle Tree) 用于高效存储和验证交易数据
5.比特币共识(Cousensus in BitCoin)
1.定义
比特币共识是网络中所有节点就区块链的状态(哪些交易有效)达成一致的机制。
2.核心机制
- 工作量证明(PoW):矿工通过算力竞争,解决数学难题以生成新区块。
- 最长合法链规则:节点始终接受工作量最大的合法链(见1.5)。
- 共识规则:交易必须符合协议(如签名有效、无双花);区块必须满足难度目标,且包含有效的前区块哈希;每2016个区块调整一次难度,确保出块时间稳定在10分钟。
- 去中心化特性:没有中央权威,共识由全球节点共同维护。
- 分叉处理:如果网络出现临时分叉(如两个矿工同时挖到区块),节点会选择最长链,分叉的短链将被丢弃。
5.最长合法链(longest valid chain)
1.定义
最长合法链是指累积工作量(Proof of Work)最多的区块链,且符合所有协议规则。
2.作用
解决分叉问题:当网络出现竞争链时,节点选择最长链作为主链。
防止篡改:攻击者若想修改历史交易,需重新计算从目标区块到当前高度的所有工作量,并超过现有链的增长速度。
3.工作原理
每个区块的头部包含前一区块的哈希,形成链式结构。
4.实际案例
如果一个矿工挖到一个区块,但另一个矿工随后挖出一条更长的链,网络会切换到更长链,短链的区块成为“孤块”(Orphan Block),这也是为什么建议等待6个确认,以确保交易所在链足够稳定。
6.比特币如何获取记账权
比特币的区块记账权是通过 工作量证明(PoW, Proof of Work) 竞争获得的,矿工必须完成计算任务以证明自己消耗了足够的算力。整个过程涉及 交易打包、哈希计算、难度调整、区块广播和链上确认,以下是详细步骤:
1. 交易收集与验证
矿工节点 从比特币网络的 内存池(Mempool) 收集未确认的交易,并验证:
-
交易签名是否有效(防止双花)。
-
交易输入(UTXO)是否未被使用。
-
交易手续费是否足够(矿工优先打包高手续费交易)。
示例:
一个区块通常包含 2000~3000笔交易(约1MB~4MB,取决于SegWit使用情况)。
2. 构建候选区块
矿工将交易打包成 候选区块,结构如下:
| 字段 | 说明 |
|---|---|
| 版本号 | 区块协议版本(如0x20000000) |
| 前一个区块哈希 | 父区块的SHA-256哈希(确保链式连接) |
| 默克尔根(Merkle Root) | 本区块所有交易的哈希树根 |
| 时间戳 | 区块生成时间(Unix时间) |
| 难度目标(nBits) | 当前网络难度(压缩格式) |
| Nonce | 初始随机数(从0开始递增) |
关键点:
-
Coinbase交易:区块的第一笔交易,矿工将 区块奖励(6.25 BTC) 和 交易手续费 转入自己的地址。
-
交易排序:矿工可能按手续费率(sat/vB)排序以最大化收益。
3. 工作量证明(PoW)计算
矿工的任务是找到一个 Nonce,使得区块头的双SHA-256哈希值 ≤ 当前目标(Target):
SHA-256(SHA-256(Block Header))≤TargetSHA-256(SHA-256(Block Header))≤Target
计算过程
-
修改Nonce:从0开始递增,计算哈希。
-
穷举尝试:若Nonce遍历完毕仍未找到解,则调整:
-
Coinbase ExtraNonce(扩展Nonce空间)。
-
交易列表(替换高手续费交易)。
-
时间戳(微调以改变哈希)。
-
-
哈希示例:
假设某次计算得到哈希:text
复制
下载
0000000000000000000abc123...(前导19个0)
若符合当前难度(如要求前导18个0),则挖矿成功。
4. 难度调整(Dynamic Difficulty)
比特币每 2016个区块(约两周)调整一次难度,确保平均出块时间维持在 10分钟:
New Target=Old Target×Actual TimeExpected TimeNew Target=Old Target×Expected TimeActual Time
-
Actual Time:过去2016个区块的实际耗时。
-
Expected Time:2016 × 10分钟 = 20160分钟。
调整限制:单次难度变化不超过 ±4倍(防止攻击)。
5. 区块广播与确认
-
广播区块:矿工将新区块发送给相邻节点。
-
节点验证:其他节点验证:
-
PoW是否有效(哈希 ≤ Target)。
-
交易是否合法(无双花、签名有效)。
-
-
链上确认:
-
区块被纳入最长链后,获得 1次确认。
-
每新增一个区块,确认数+1(6次确认后视为最终确认)。
-
6. 矿工收益
-
区块奖励:当前 6.25 BTC(2020年减半后),下次减半在2024年(3.125 BTC)。
-
交易手续费:用户支付的费用(如0.0001 BTC/笔),矿工优先打包高手续费交易。
示例:
若某区块包含 3000笔交易,平均手续费 0.00005 BTC,则矿工额外收益:
3000×0.00005=0.15 BTC3000×0.00005=0.15 BTC
7. 关键代码示例(PoW核心逻辑)
python
复制
下载
import hashlibdef mine_block(header, target):nonce = 0while True:# 更新Nonce(小端序)header_with_nonce = header[:76] + nonce.to_bytes(4, 'little')# 计算双SHA-256hash_result = hashlib.sha256(hashlib.sha256(header_with_nonce).digest()).digest()hash_int = int.from_bytes(hash_result, 'big')# 检查是否≤Targetif hash_int <= target:return nonce, hash_result.hex()nonce += 1# Nonce溢出后调整其他字段if nonce >= 2**32:nonce = 0# 修改Coinbase ExtraNonce或交易顺序
8. 为什么需要PoW?
-
安全性:攻击者需掌握51%算力才能篡改交易,成本极高。
-
去中心化:任何人均可参与挖矿,无需许可。
-
公平性:算力决定记账权,而非身份或资本。
总结
比特币的记账权获取流程:
-
收集交易 → 2. 构建区块 → 3. PoW计算 → 4. 广播验证 → 5. 链上确认。
矿工通过消耗电力(算力)竞争记账权,获得BTC奖励,同时维护网络安全。这一过程是比特币 去中心化、抗审查、安全 的核心基石。
4.比特币的实现
区块链是去中心化的账本,比特币采用的是基于交易的账本模式(transaction-based ledger),只记录了转账交易和铸币交易,并没有直接记录每个账户上有多少钱。如果想知道某个比特币账户上有多少钱,要通过交易记录来推算。
1.UTXO
比特币中的全结点要维护一个叫UTXO(Unspent Transaction Output)的数据结构,即还没有被花出去的交易的输出。一个交易可能有多个输出,被花掉的就不在UTXO里了。如下图中A转账给B和C的交易,B的已经花出去了,也就不在UTXO里了,而C的还没花出去,就在UTXO里。
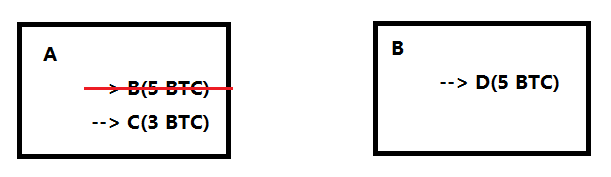
UTXO集合中的每个元素要给出产生这个输出的交易的哈希值,以及它在这个交易中是第几个输出。用这两个信息就可以定位到一个确定的交易中确定的输出。
使用UTXO可以用来快速检测双花攻击,想知道新发布的交易是不是合法的,要查一下全结点存在内存中的UTXO。要花掉的币只有在这个UTXO这个集合里才是合法的,否则要么是不存在的,要么是已经花过了的。随着交易的发布,每个交易会消耗掉一些输出,同时也会产生一些新的输出。例如上图例子中B将5个BTC给D,这消耗掉了前面A把5个BTC给B的输出,但产生了新的B把5个BTC给D的输出,这个输出会保存在UTXO里。
如果一个账户从交易中获得比特币之后,不花出去,那么这些输出就要一直保存在UTXO里。有的人是一直不花,比如中本聪,有的是把密钥丢了没法花,但不论怎样这些没消耗掉的交易输出都要一直存在UTXO里,目前的大小是能保存在一个普通服务器内存中的。
交易中 total inputs=total outputs
每个交易可以有若干输入和若干输出,所有输入的金额之和要等于所有输出的金额之和。
这里可能有些违反直觉,不仅可以有多个输出,也可以有多个输入,甚至这些输入也不必来自同一个地址。每个输入地址都要提供对应的签名,所以一个交易可能有多个签名。
2.第二个激励机制:交易费(transaction fee)
有些交易的总输入可能略微大于总输出,如可能总输出是1个BTC,总输出是0.99个BTC,这之中的差额就作为记账费给了获得记账权的那个结点。
这样设计是因为仅仅为获得记账权的结点给予出块奖励是不够的,获得记账权的结点为什么要把某些交易记下来?这样做对他有什么好处呢?一个结点完全可以只打包自己的交易,记录别人的交易不仅要去验证其合法性,而且一个区块装的交易多了,在网络上传输的带宽也会比较多,在网络上传输的速度也会慢。这里的差额作为记账费就解决了这个给别人记账的动机的问题。
这里0.01个BTC已经是很大的交易费了,也有一些很简单的交易是没有交易费的,也就是完全符合t o t a l i n p u t s = t o t a l o u t p u t s 。
目前来讲矿工挖矿,主要的目的还是为了第一个激励机制——得到出块奖励。因为出块奖励是要逐渐减少的,每隔21万个区块就要减半,比特币系统的平均出块时间是10分钟,大约每隔4年出块奖励就会减半。到很多年之后,出块奖励变得很小,这时候交易费就成为主要动机了。
除了比特币系统这样基于交易的账本模式(transaction-based ledger),还有一些系统是基于账户的模式(account-based ledger),比如后面要学的以太坊。在这种模式中系统要显式的记录每个账户中有多少个币。
比特币系统的这种模式,隐私保护性比较好,但会带来一些代价,如转账交易要说明币的来源(币是从之前的哪个交易的哪个输出中来的)以防止双花攻击。
一个区块的例子
在blockchain.info上截图下来的一个区块:
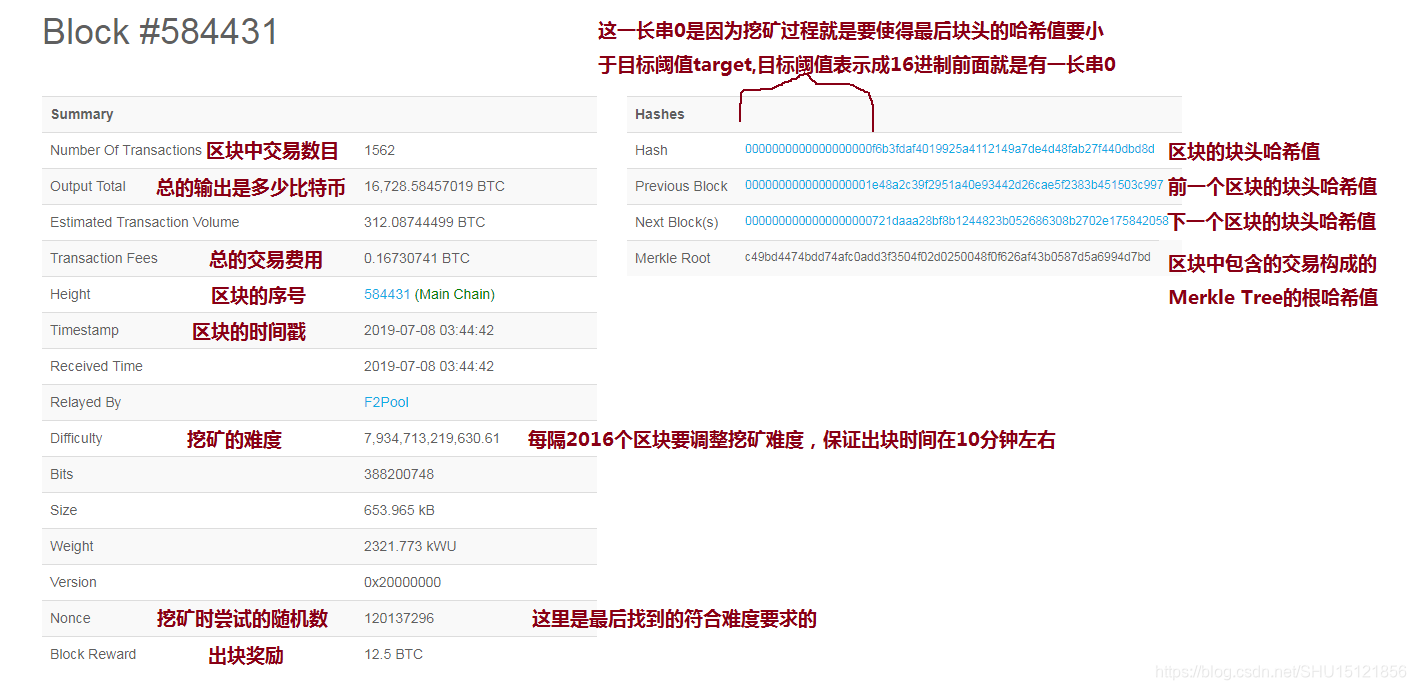
注意,区块中的nonce是4字节即32位整数,也就只2的32次方 种取值。因为比特币近些年太火爆了,挖矿的人数很多,所以挖矿的难度被调整的很高,单纯靠调整nonce是很可能得不到符合难度要求的解的(搜索空间不够大)。所以区块的块头中哪些域可以改?再来回顾一下块头中的域(括号中是占的字节数):
- 版本号(4):不能改
- 前一个区块块头哈希值(32):不能改
- Merkle Tree的根哈希值(32):通过修改Merkle Tree中铸币交易的CoinBase域来调整其根哈希值
- 区块产生的时间(4):有一定的调整余地,比特币系统并不要求非常精确的时间,这个域可以在一定范围内调整
- 挖矿目标阈值编码后的版本(4)
- nonce(4):可以改
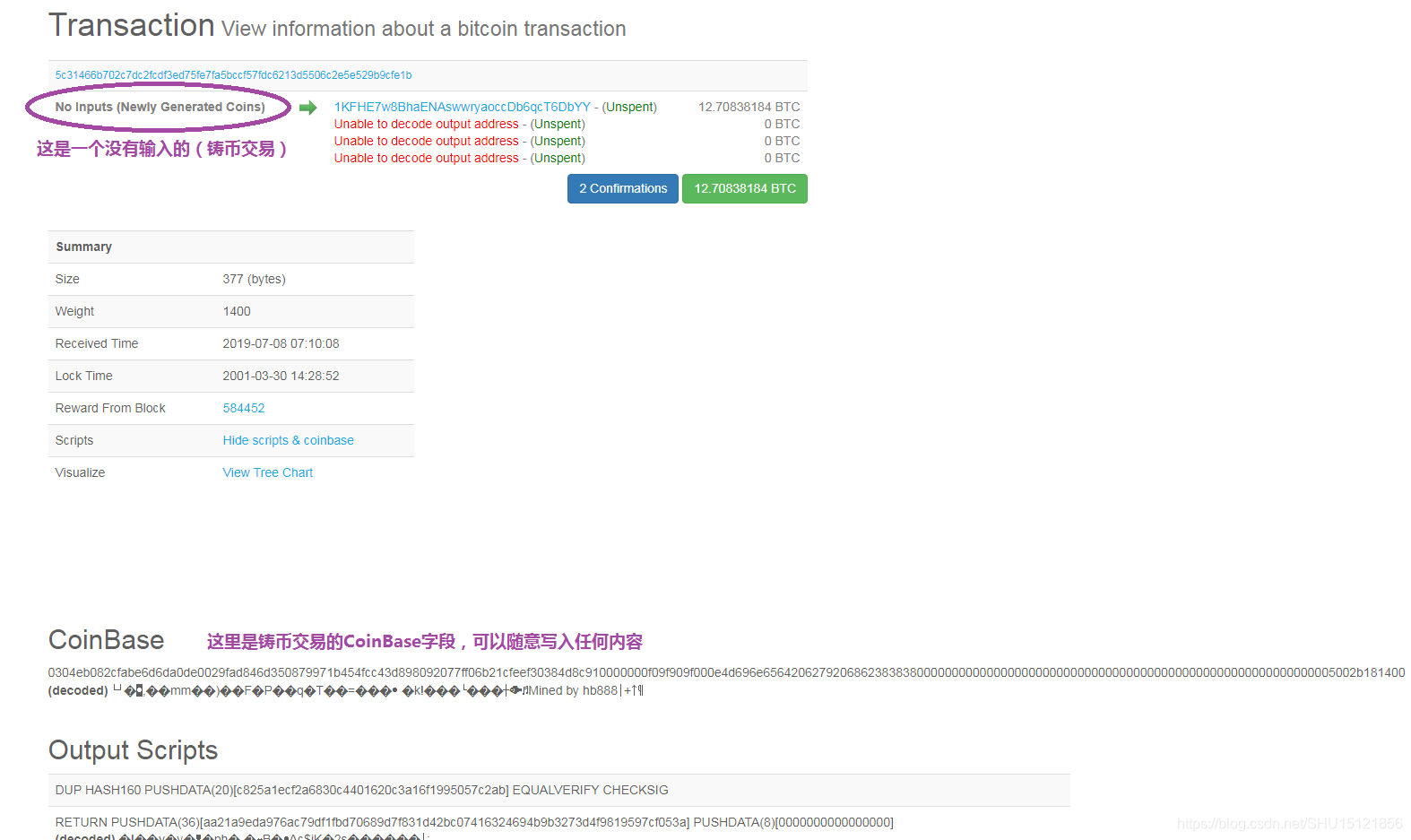
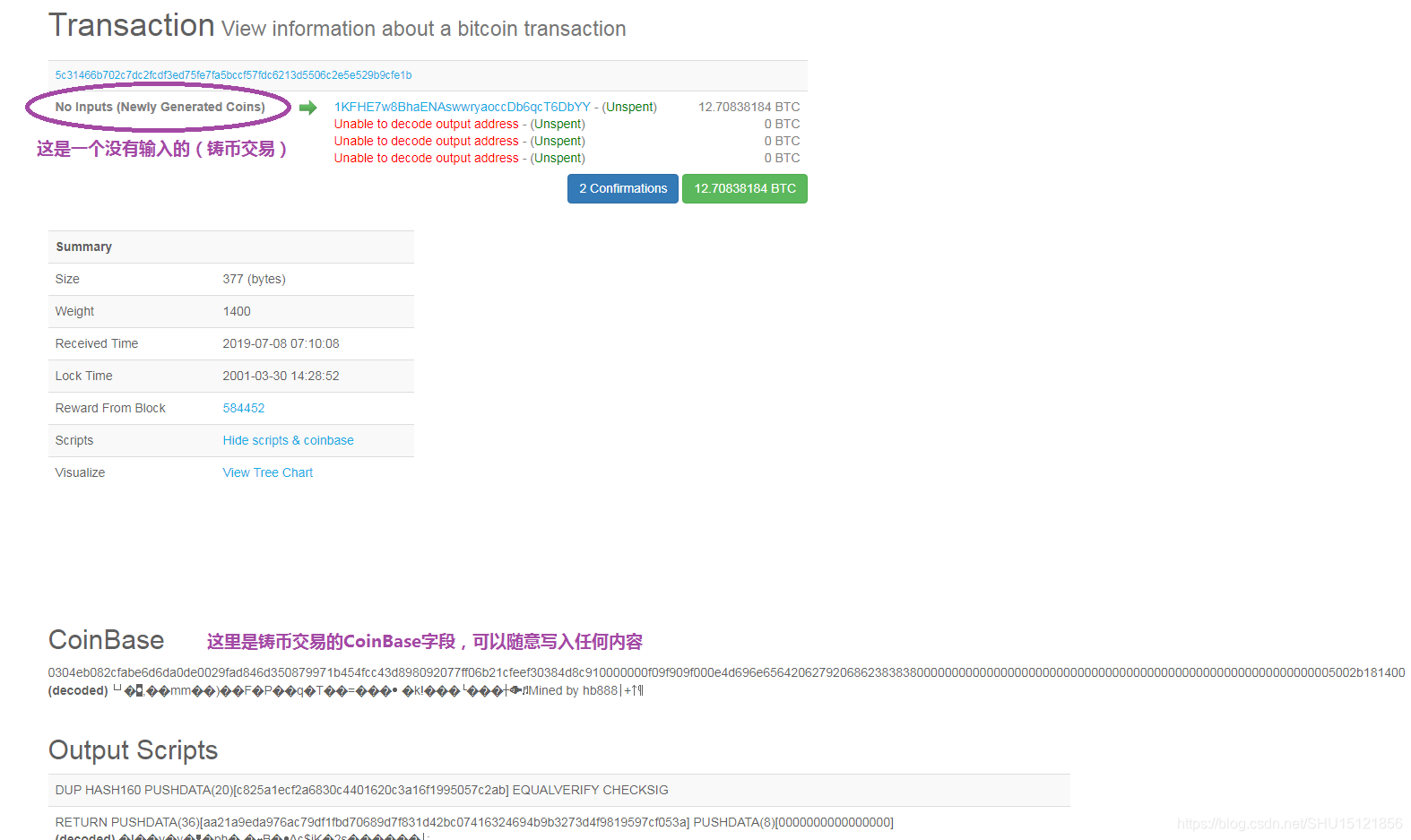
可以看到,因为铸币交易是没有交易来源的,所以可以在其CoinBase域里随便写入内容,铸币交易的变化会使该交易的哈希发生变化,变化沿着Merkle Tree一路向上传递,最终使整棵Merkle Tree的根哈希值发生变化,间接地调整块头的哈希值。
所以可以把这个字段当做一个extra nonce,块头的nonce字段不够用,就再拿着这个域的一部分字节一起调整,就增大了搜索空间。例如,拿出这个域的前8个字节当做extra nonce,则搜索空间一下子就增大到了2的32次方 + 8 ∗ 8 = 2 96 。 2^{32+8*8}=2^{96}。2的32次方
32+8∗8 =2的96次方
实际挖矿时,一般也是为此设计了两层循环,外层循环调整铸币交易的CoinBase域的extra nonce,然后算出Merkle Tree的根哈希值;内层循环调整块头的nonce,计算整个块头的哈希值。
一个转账交易的例子
以这个交易为例。
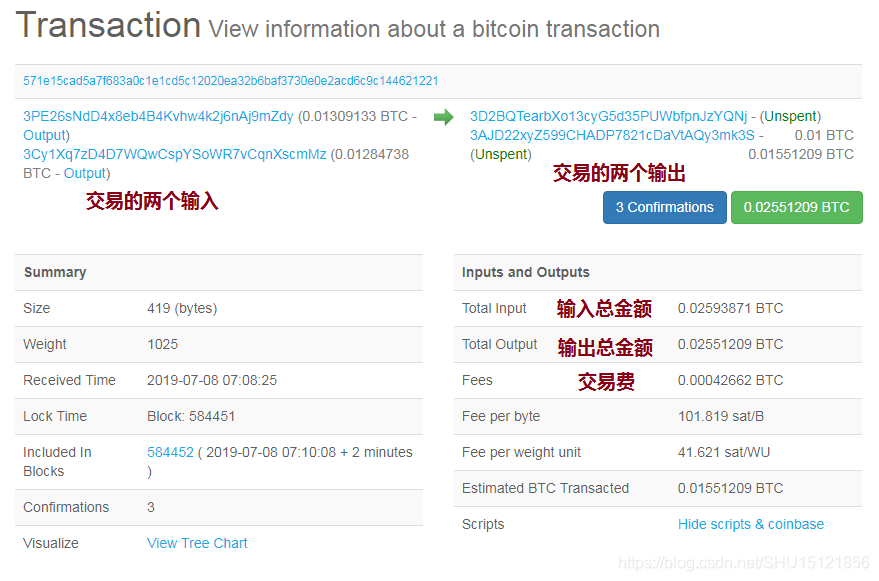
在这个转账交易中,左边是交易的两个输入(虽然旁边写的是Output,这是表示它们花掉的是之前哪个交易的Output);右边是交易的两个输出(从绿色Unspent字样可以看到还没有花出去,所以会保存在UTXO里)。可以看到比特币系统中交易的输入和输出都是用脚本来指定的,验证交易输入输出的过程就是把输入脚本和输出脚本配对执行(不是把同一个交易的输入输出脚本配对执行,而是把这个交易的输入脚本和提供币的来源的那个交易的输出脚本配对执行)。只要配对后都能成功执行,交易验证就是通过的。
挖矿过程的概率分析
- 挖矿的过程就是不断尝试nonce去求解puzzle,每次尝试可以看做一个伯努利试验(Bernoulli trial:a random experiment with binary outcome)。掷硬币就是一个最简单的伯努利试验,要么正面朝上要么反面朝上,这两个概率不必一样大,对于挖矿而言,成功和失败的概率相差非常悬殊,成功的概率很小。
- 当进行了大量的伯努利试验,这些伯努利试验就构成了伯努利过程(Bernoulli process:a sequence of independent Bernoulli trails)。伯努利过程的一个性质是无记忆性(memoryless),即做大量的试验,前面的试验结果对后面没有影响,例如掷硬币很多次都是反面朝上,下一次掷硬币正面朝上的概率也不会增加。
- 当伯努利分布(也即二项分布)的n很大而p很小时(试验次数很多,每次试验成功概率很小),可以近似为泊松分布。这里挖矿就是一个n很大p很小的伯努利过程,所以可以近似为泊松过程(Poisson process)。
- progress free与算力优势——挖矿公平性的保证:出块时间是服从指数分布(exponential distribution) 的,整个系统的出块时间按照比特币协议被调整在10分钟左右,而具体到某个矿工的出块时间,取决于其算力占整个系统中矿工的算力的百分比,这比较好理解,例如某个矿工的算力能占到整个系统总算力的1%,那么平均100个区块有1个是他挖到的,也即平均要等1000分钟能挖到1个区块。
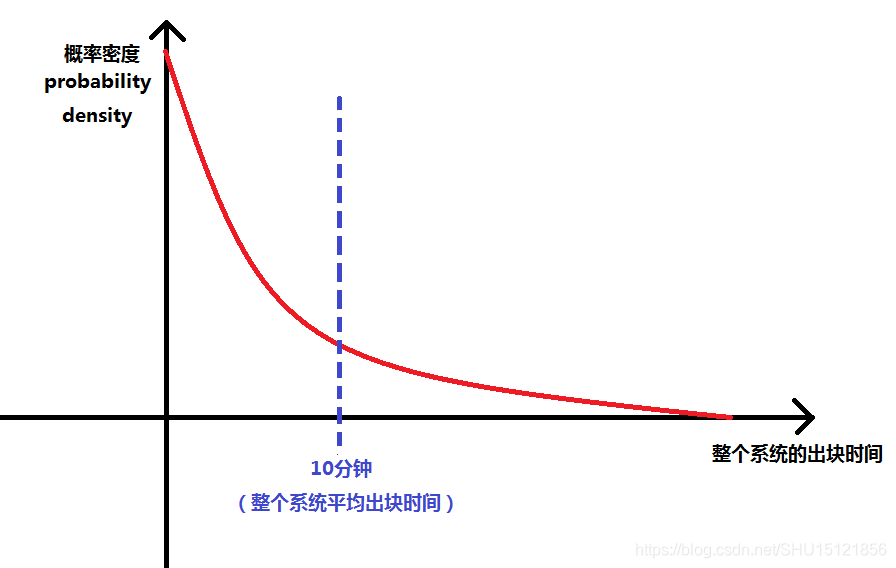
- 这个出块时间服从的指数分布也是无记忆性的, 也就是说从任何一个位置将其截断,剩下的部分仍然是服从指数分布的。“将来还要挖多少时间”和“过去已经挖了多少时间”是没有关系的。体现在比特币系统的挖矿中也就是,不管大家已经挖了多长时间,接下来系统中要出块的平均时间仍然还是10分钟左右。
- 这也就是progress free——过去做了多少工作不会让后续成功的概率变化。这个性质看似无情但是是必要的。假设一个加密货币系统不满足progress free,即过去做的工作越多,后面成功的概率就越大,那么就会造成算力强的矿工会有不成比例的优势,而不能按照算力的比例计算优势。比特币总量的分析
- 出块奖励是系统中产生新的比特币的唯一途径,而出块奖励每隔21万个区块(大约每隔4年)要减半,所以新产生的比特币的总量就形成了一个几何序列(geometric series)。
所以比特币总量为:
21 万 × 50 × 2 = 2100 万 21万 \times 50 \times 2 = 2100万
21万×50×2=2100万
这就是系统中所有比特币的总量。
- 认为比特币挖矿是在解决某种数学难题是错误的观念,求解比特币挖矿的puzzle除了比拼算力之外,没有任何实际意义。比特币越来越难挖只是因为出块奖励人为地被减少了,并且加入的人越来越多而为保持系统中的平均出块时间而提高了挖矿的难度。
- 但要注意,挖矿的过程虽然没有实际意义,但对维护比特币系统的安全性是至关重要的。Bitcoin is security by mining。挖矿提供了一种凭借算力投票的有效手段。
比特币安全性的分析
- 大部分算力掌握在诚实的结点手里,只能说有比较大的概率下一个区块是由诚实的矿工发布的,但是不能保证记账权不会落在有恶意的结点手里。
转走别人的BTC
- 假设一个有恶意的结点M获得了记账权,它想把结点A的钱转走,但因为没法伪造A的签名(没有A的私钥),写个任何不正确的签名上去,都会导致诚实的结点不会接受这个候选区块,而是继续沿着上一个区块扩展。因为这个区块是不合法的,所以多长都不是最长合法链,这样的攻击是无效的。
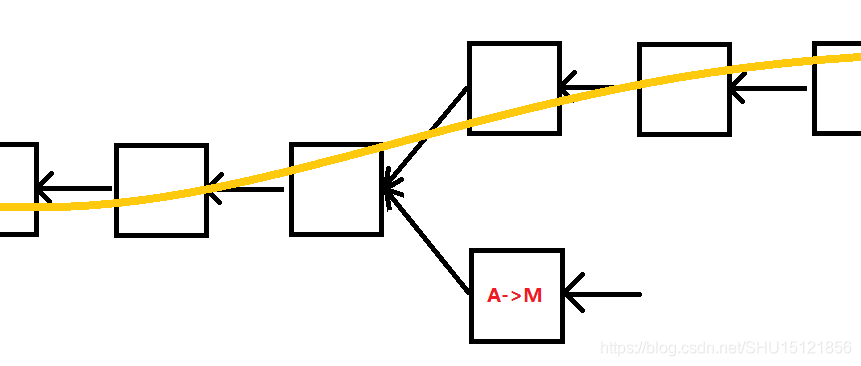
分叉攻击
M把BTC转给A,然后就紧接着挖矿挖到了一个区块,在这里填写了M把BTC转给自己的交易,以希望沿着这个区块成为最长合法链,这样就能将转给A的挤掉,从而将花出去的BTC回滚。这也是双花攻击的一种。
试想A是一个购物网站,允许BTC支付,在M->A这个交易刚写入区块链以后A就认为M支付成功,那确实会出现上述问题。
如果M->A这个交易所在区块后面又跟上一些区块之后呢?这个攻击的难度就会大大增加。因为它最好的方式仍然是在M->A的前一个区块位置插入,但是想让它成为最长合法链却非常难,因为它已经不是最长合法链,诚实的结点只会去扩展最长合法链。
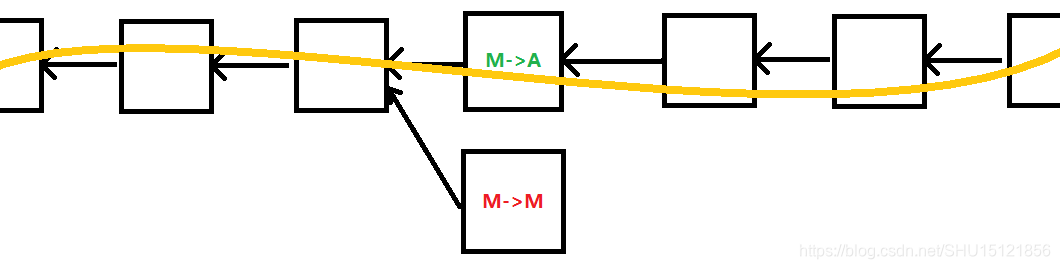
如果大部分结点掌握在诚实结点手里,这样攻击的难度非常大,有恶意的结点要连续获得好多次记账权才可能改变最长合法链。所以一种最简单的防范方法就是多等几个区块,也叫多等几个确认(confirmation)。
zero confirmation
zero confirmation是指交易刚发布出去,还没有写入区块链中的时候,就认为交易已经不可篡改了。
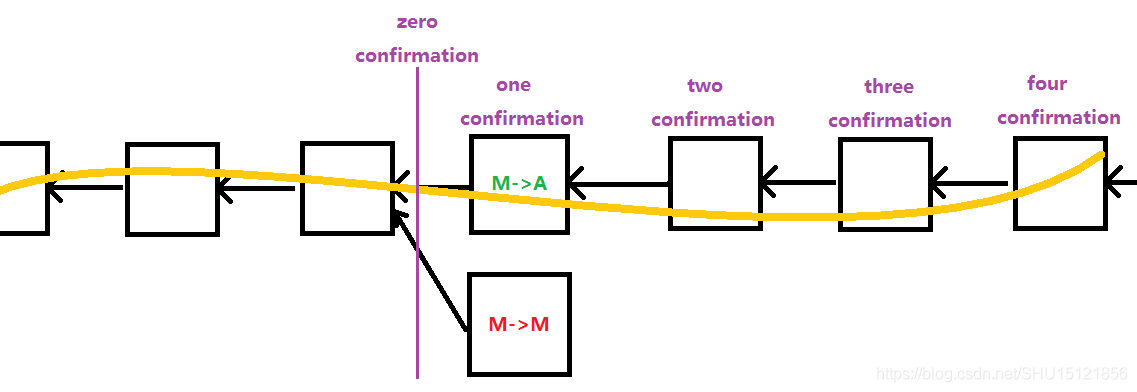
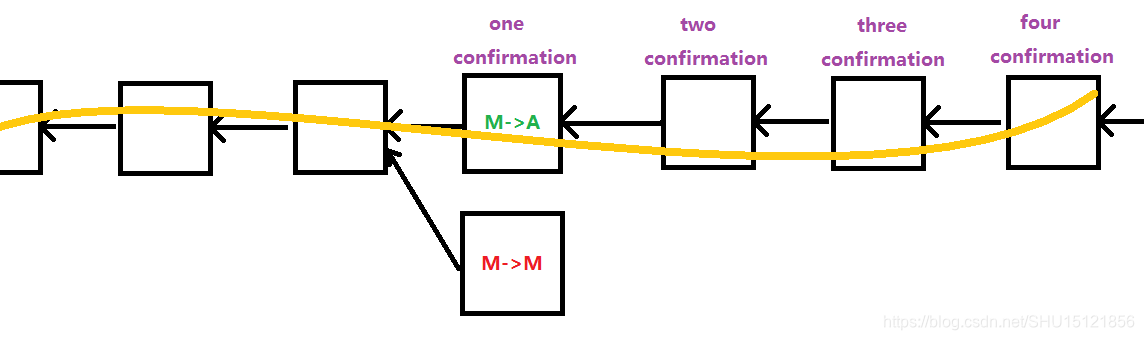
zero confirmation实际使用的比较广泛,有两个原因:
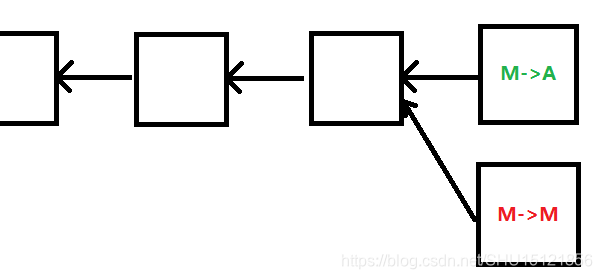
- 两个交易有冲突,结点接收最先听到的交易。上面分叉攻击的例子中M->A后的M->M大多诚实结点会将其拒绝。
- 购物网站委托全结点监听区块链,从支付成功到发货其实还有比较长的处理时间,如果发现这个交易最后没有写到最长合法链,购物网站可以选择取消发货。
故意不发布某些合法交易
这个是没关系的,因为比特币协议也没有规定获得记账权的结点必须发布哪些交易,而且没有写进这个区块也可以写进下一个区块,总有诚实的结点愿意发布这些交易。而且比特币系统在正常工作时候也会出现某些交易被滞后发布的情况,可能就是一段时间内的交易太多了,毕竟一个区块不能超过1M。
selfish mining
- 正常情况下结点挖到一个区块就立即发布,这是为了得到出块奖励和收取交易费。selfish mining就是挖到的区块都留着,这样的动机是,比如在前面的分叉攻击中,一直等到6个confirmation过了,再一口气把算好的很长的分叉发布出去,替换掉最长合法链。
- 实际上这样做的难度还是很大,因为这个恶意结点的算力要超过那些诚实的算力才可能在一定时间后比它长。另外就是大多诚实的结点已经扩展那个M->A的交易所在的区块了,这个恶意结点的同伙结点也要很多才行。
- 即便不是为了做什么攻击,就是为了赚取出块奖励和收取交易费,selfish mining也有好处——能够减少自己的竞争对手。比如下图中大家都在从A挖下一个区块,然后某个结点挖出了B先藏着,这时候别人还在从A挖下一个区块,然后这个结点紧接着挖出了C,将B和C一起发布出去,这样就少了一个结点C的竞争。
- 或者是继续往下挖,当听到有人发布D时,将B和C一起发布出去,这样最长合法链是沿着ABC的,别人挖出的D就作废了。
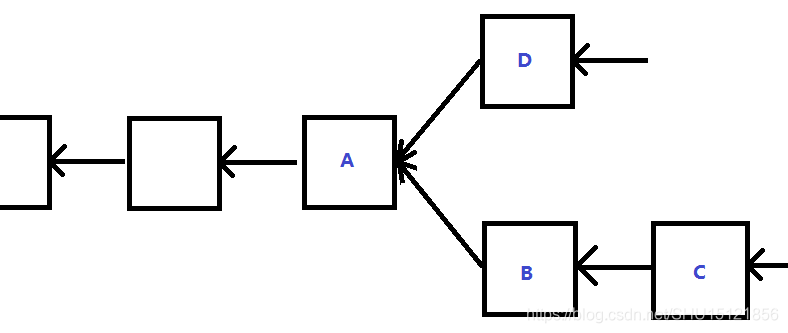
但这样会带来不小的风险,假设在挖出C之前就有人挖出D并且发布了,这时候就只能赶紧把B发布出去,很可能连这个记账权都竞争不到了。
在这个动机下,selfish mining的回报并非很高,只是让别人做了无用功,自己少了些竞争,但风险却是挺大的。
参考地址:【区块链学习笔记】4:比特币系统的实现_比特币的激励机制-CSDN博客
5.比特币网络
新的交易要发布到比特币网络上,矿工将交易打包成的区块也要发布到比特币网络上。
- 应用层:Bitcoin Blockchain
- 网络层:P2P Overlay Network
比特币网络中的P2P网络是很简单的,所有结点之间都是对等的,没有超级结点。要加入这个网络,至少要有一个种子结点(seed node),和种子结点联系,它会告知它所知道的网络中的其它结点(有点像构造路由表的过程)。结点之间通过TCP来通信,有利于穿透防火墙。要离开网络也不必通知其它结点,只需要直接退出应用程序,其它结点一直没有听到你的消息,过一段时间就会将你删除掉。
比特币网络的设计原则是简单、鲁棒(健壮性),而不是高效。每个结点维护一个邻居结点的集合,消息在网络中采用flooding方式传播,结点第一次听到某个消息,会将它传播给所有邻居结点,同时记录一下自己已经收到过这个消息了。
邻居结点的选取是随机的,没有考虑底层的拓扑结构。比如美国的一个结点可能和中国的一个结点是邻居结点。这样设计的好处是增强鲁棒性,牺牲了效率。
新发布的交易的传播
比特币网络中,每个结点要维护一个等待上链的交易的集合,这个集合中的交易都是要写入区块链的合法的交易,结点第一次收到这个交易的时候就会把它写入这个集合,并转发给所有邻居。
如果有两个有冲突的交易,几乎同时发布到网络上,每个结点根据其位置的不同,可能先收到的交易是不同的,那么另一个交易对于这个结点而言就是非法的了,不会被收纳到集合中。
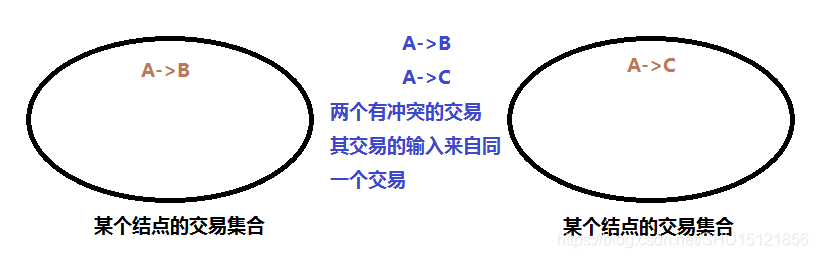
以左边的集合为例,它先听到A->B的交易,将其写入到了自己的交易集合中。接下来它收到了一个新发布的区块,其中包含A->B这个交易,说明这个交易已经被写入区块链了,所以就要在自己的交易集合中将其删除掉。
risk condition
如果这个结点收到的新发布的区块中的交易是被自己丢弃掉的A->C的这个交易呢?这时也要将集合中的A->B删除掉,因为检查可以发现此时集合中的A->B这个交易是非法交易,因为它和新发布的区块中的A->C这个交易冲突了。
也就是说要看接收A->B交易的结点先获得记账权,还是接收A->C交易的结点先获得记账权。
best effort
一个交易发布到比特币网络上,未必所有结点都能收到(有的结点不一定按照比特币协议的要求来转发,可能合法的不转发,不合法的又转发了),而且不同结点收到交易的顺序也很可能是不一样的(网络传输中的延迟可能很大)。这是一个去中心化的系统中要面临的实际问题,只能尽力而为。
新发布的区块的传播
和新发布的交易的传播方式是类似的,不过每个结点除了要检查区块的内容是不是合法的,还要检查区块是不是在最长合法链上。
越大的区块在网络上传播越慢,比特币协议要求区块大小不能超过1M,因为比特币网络的效率比较低,一个1M大小的区块可能要几十秒才能传播给比特币网络上的大多数结点。
6.比特币挖矿难度
挖矿难度
挖矿就是不断尝试区块块头中的nonce和extra nonce的值,使得:

显然目标阈值target越小,则挖矿的难度就越大。所以调整挖矿难度就是在调整target,以调整目标空间在整个输出空间中所占的比例。
比特币中使用的哈希函数是SHA-256,产生的哈希值是256位的,所以整个输出空间是2的256次方
,调整目标空间所占的比例,在这个问题里直观的来看就是最后得到的哈希值前面有多少位0(这只是通俗直观来看的,也许第一个非0位是要小于4也说不定),这个0越多显然值就越小,也就是挖矿难度越大了。
挖矿难度和目标阈值的大小成反比:
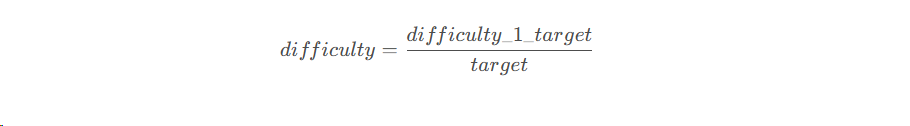
上式中常量difficulty_1_target是指挖矿难度difficulty定义为1时所对应的目标阈值target的值。挖矿难度最小就是1,所以这个常量也就是target允许的最大值。
为什么要调整挖矿难度?
系统中的总算力越来越强,如果挖矿难度保持不变,那么平均出块时间会越来越短,这会造成一些问题。假设平均出块时间减小到了1秒钟,也就是每隔1秒左右就有一个新的区块携带一些列交易被发布到比特币网络上,而在比特币网络上这个区块传播给大多数结点可能就要几十秒。
如果有两个结点几乎同时发布了区块,那么就会出现分叉:
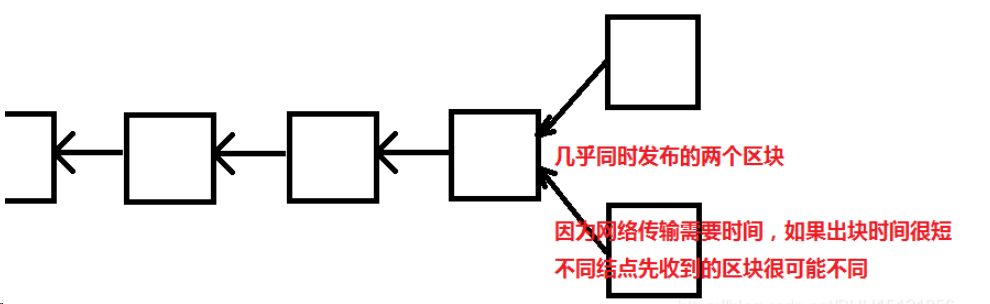
这是一个二分叉的情况,如果出块时间很短,就会导致这种分叉成为常态。而且不仅仅是二分叉,可能会出现很多分叉。
分叉过多对比特币系统达成共识没有好处,并且会危害比特币系统的安全性。例如前面说的分叉攻击,正常情况下,因为大部分结点是诚实的,有恶意的结点想要在6个确认后拿这段时间集中算力算出的新链去覆盖掉最长合法链是很难的,因为诚实结点也都在集中算力扩展最长合法链。如果出块时间很短,就会导致分叉过多(因为相比于出块时间,可以认为网络上传输的时间变长了),这样诚实结点的算力就被分散了,这时恶意结点要进行51% attack很可能就不需要50%以上的算力了,可能百分之十几就足够了,这样大大降低了比特币系统的安全性。
比特币10分钟的平均出块时间也未必是最优的,后面要学的以太坊的出块时间就降低到了15秒。大幅降低了出块时间,所以以太坊就要设计一个新的共识协议——
GHOST。在这个协议中,分叉产生的orphan block不能简单丢弃掉,而是也要给予一些奖励——uncle reward。
总之,在不同的区块链账本系统中,不论出块时间设计成多长,都要设法让其保持稳定,而不能允许它随着系统中总算力的提高而无限减小下去。
怎么调整挖矿难度?
比特币协议中规定,每隔2016个区块(大约每2个星期)要重新调整一下目标阈值target,具体的迭代更新公式是:
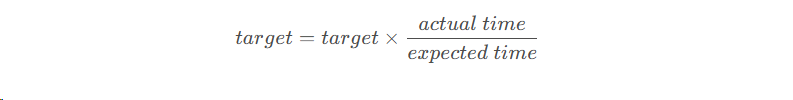

如果恶意的结点不调整target怎么办
target是写在比特币系统的代码里的,代码也都是开源的,如果有结点到了该调整的时候不调整target怎么办。这也是一个大部分结点诚实的问题,如果不调整target,那么发布的区块块头里的4字节nBits域(32字节的target压缩编码后的版本)就不是正确的,诚实的结点不会接收这样的区块。
7.比特币挖矿
1. 比特币系统中有两种节点,一种是全节点,一种是轻节点。
2. 全节点的特征
- 一直在线
- 在本地硬盘上维护完整的区块链信息
- 在内存中维护UTXO集合,以便快速检验交易的正确性
- 监听比特币网络上的交易信息,验证每个交易的合法性
- 监听别的矿工挖出的区块,验证其合法性:
- 区块中的每个交易都要合法(包括铸币交易及其出块奖励)
- 发布的区块是不是符合难度要求、难度目标阈值的设置是否正确、每两周调整的挖矿难度
- 区块是在延伸最长合法链
- 挖矿:
- 决定沿着哪条链挖下去
- 决定哪些交易被打包进区块
- 决定当出现等长分叉时选择哪个分叉(缺省情况是选择最先接收到的区块的分叉)
3.轻节点的特征
- 不是一直在线
- 不用保存完整区块链,只要保存每个区块块头(这样和全节点的大小相差大约1000倍)
- 不用保存全部交易,只需要保存和自己相关的交易
- 没法验证大多数交易的合法性,只能检验与自己相关的交易的合法性
- 无法检测比特币网络上发布的区块的正确性
- 可以验证挖矿的难度(因为挖矿时候计算哈希值只用到了块头信息,而块头信息轻节点是保存了的)
- 只能检测哪个是最长链,不知道哪个是最长合法链(因为无法检测这条链上所包含的交易都是合法的)
轻节点假设矿工(全节点)大多是有理智的,即假设矿工们不会沿着不合法的链一直挖下去。
比特币网络中大部分节点都是轻节点,如果只是想转账,而不是去挖矿的话,只用轻节点就可以了。
挖矿
当在挖矿过程中发现新发布了一个区块,那么应该停止挖矿,重新从UTXO中取出一系列合法交易组成候选区块,在刚发布的这个区块后面开始挖矿。因为一方面这个区块中的交易可能和刚刚在挖的那个区块有重复,另一个本质的原因就是候选区块的块头有指向前一个区块的哈希指针。因为最新的区块已经变了,这个哈希指针也要跟着改变。
那么这样是不是会因为之前的工作都白费了而很可惜?实际上不可惜,因为前面学过挖矿过程的无记忆性(memoryless,progress free),无论是在刚刚的区块上继续挖,还是新组装一个区块继续挖,成功的概率是一样的。
比特币系统安全性的保证:因为别人没法伪造你的私钥,也就没法把你账户上的BTC转走。但这个密码学上的保证是要以“系统中大部分节点是诚实的”为前提,即大家不会接受那些不合法的交易进入区块链。
挖矿的设备
第一代挖矿设备:CPU
最早时候大家都是用普通计算机来挖矿,但如果专门搞一台计算机来挖矿是很不划算的。因为计算机大部分内存是闲置的(挖矿只要用到很少一部分内存),CPU大部分部件是闲置的(计算哈希值的操作只用到通用CPU中的很少一部分指令),硬盘和其它很多资源也都是闲置的。随着挖矿难度提高,用通用计算机上的CPU挖矿很快就无利可图了。
第二代挖矿设备:GPU
GPU主要用来做通用的大规模并行计算,用来挖矿还是会有不少浪费,而且GPU的噪音很大,其中很多部件还是浪费了(如用于浮点数计算的部件)。近些年GPU价格涨得很快,这不仅是DL火热的原因,实际上很多GPU是买来挖矿的。不过现在挖矿的难度已经提高到用GPU也有些划不来了,不会再有那么多人买GPU来挖比特币。
第三代挖矿设备:ASIC芯片
ASIC即Application Specific Integrated Circuit,这之中有专门为了挖矿而设计的芯片,没有多余的电路,干不了别的事,它的性价比是最高的,而且为某一种加密货币设计的ASIC芯片只能挖这一种加密货币的矿,除非两个货币用同一个mining puzzle。
有些加密货币在刚启动的时候,为了吸引更多的人来挖矿,特意用一个和已有的其它加密货币一样的mining puzzle,这种情况叫
merge mining。
研制挖特定加密货币的ASIC芯片需要一定周期,但和研制通用芯片的速度相比已经是非常快的了,如研制比特币挖矿的ASIC芯片大约用一年的时间。不过加密货币的价格变化是比较剧烈的,曾经就发生过比特币价格在几个月内下跌80%,因为加密货币多变的价格,这些挖矿设备的研制风险也是很大的。
挖矿的竞争越来越激烈,定制的ASIC芯片可能用了几个月就过时了,到时候又要买新的ASIC芯片参与竞争。ASIC矿机上市后的大部分利润也就在前几个月,这个设备的迭代也是很块的。
要买ASIC矿机往往要先交钱预定,过一段时间厂商才会发过来。实际上有些黑心厂商在生产出来以后也不交付给用户,声称还没成产好,然后自己在这段黄金时间用矿机挖矿赚取比特币。不过这其实看得出来,比特币系统中算力突然有了大的提高,那一般是某个大的厂商生产出了新的矿机。所以真正赚钱的未必是挖矿的,而是卖矿机的。
ASIC resistance
为了让通用计算机也能参与挖矿过程,抗ASIC芯片化,有些加密货币采用
Alternative mining puzzle,以去对抗那些只为了解决特定mining puzzle而设计出来的ASIC矿机
比特币挖矿的趋势:大型矿池
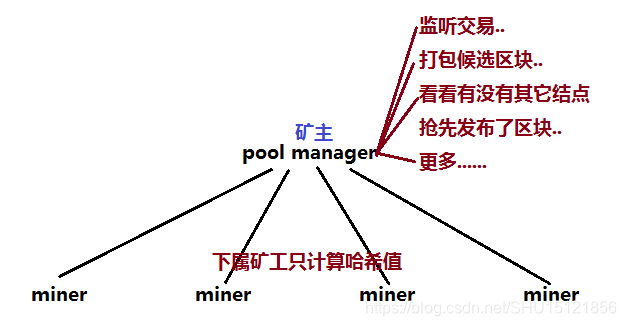
单个矿工挖矿的收益是很不稳定的,平均出块时间10分钟是对于比特币系统中的所有矿工而言的。一个矿工用一个矿机挖出矿的时间可能要很久,并且除了挖矿之外还要承担全结点的其它责任。
矿池将很多矿工组织起来,一般的架构就是一个矿主(pool manager)全结点去驱动很多矿机,下属矿工只负责计算哈希值,全结点的其它职能只由矿主来承担。有了收益以后再大家一起分配。
矿池收益怎么分配?
如果矿池中的矿机都是属于同一个机构的,那怎么分配就只是公司内部怎么发工资的问题了。
如果矿机来自不同机构,这时候矿工很可能分布在世界各地,只是都加入了这个矿池。矿工和矿主联系,矿主将要计算的哈希值的任务分配给他,矿工计算好后将结果发给矿主,最终得到出块奖励后一起参与分红。
能否平均分配?即挖到区块后奖励平分给所有矿工。这样就完全是吃大锅饭的模式了,有的矿工完全可以不干活或者少干活,所以需要按矿工的贡献大小进行分配,所以这里也需要工作量证明,来证明每个矿工所做的工作。
每个矿工单打独斗之所以收入不稳定,是因为挖矿难度太大了(相比比特币系统的平均出块时间),所以可以考虑矿池将挖矿的难度降下来。比如本来要求前面有70个0,现在矿池只要求前面有60个0,这样挖到的是一个share(almost validblock),即这个区块差不多在一定程度上是符合难度要求的。矿工挖到这样的区块之后,将其提交给矿主,矿主拿到这些区块并没有什么用,仅仅是因为目标空间是这个问题的解空间的子集,并且求解两个问题的过程是一样的(都是计算哈希),因此这些区块可以作为证明矿工所做的工作量的证明。等到某个矿工真正挖到矿,获取出块奖励之后,再按照大家提交的share的多少来进行分配。
矿工能否在参与矿池时独吞出块奖励?
是否会有这样的矿工:挖到share提交给矿主,挖到真正的矿自己发布出去以获取出块奖励?这是没法独吞出块奖励的,因为每个矿工的任务是由矿主来分配的,矿主负责组装好区块,然后交给矿工去不断尝试nonce和CoinBase transaction中的extra nonce,有可能就是讲它们划分一下,然后分配给不同的矿工去做,要注意铸币交易CoinBase transaction中的收款人地址是矿主的地址,不是任何一个矿工的地址。
如果自己把铸币交易的地址改成自己的,然后去挖矿,这样提交上去的share矿主是不认可的,所以还是没有用。
矿池之间的竞争
矿池之间是有竞争对手的,一种竞争方式就是到对方的矿池里去捣乱,即派遣一些矿工去加入到对方的矿池里去挖矿,只提交share,但挖到真正的矿就将其丢弃掉,故意不提交。然而如果这个对手矿池仍然获得了出块奖励,这些矿工也能参与分红。
大型矿池带来的危害
如果没有矿池,如果要发动51%攻击,攻击者要花费大量的硬件成本。有了矿池以后,矿池实际上将算力集中了起来,攻击者未必拥有很多算力,只要吸引大量的不明真相的群众将算力集中到自己的矿池就可以。
在2014年的时候GHash矿池的总算力就超过了比特币系统中总算力的一半,引起了恐慌,然后GHash主动减少了算力,以防止大家对比特币失去信心。如今的矿池的算力还算比较分散,有好几家矿池在竞争,但一个集体的算力完全可以潜伏分散在不同矿池中,等到攻击时再集中起来,矿工要转换矿池是很容易的。
这有点类似云计算中ODC(
on demand computing)的概念,平时不需要维护这些节点,需要计算时再召集起来。
矿池要收取管理费,有的收取出块奖励中的一部分,有的收取赚取的交易费。有恶意的矿池可以在发动攻击之前故意将管理费降得很低,吸引大量矿工进入矿池。
假设出现超大型矿池,具体能发动哪些攻击?
假设有矿池占据了半数以上的算力,能够发动下面这些攻击:
[1]分叉攻击
因为算力占了半数以上,并且矿工挖矿任务被分配开并行进行,分叉出来的链的增长速度很快,最终势必成为最长合法链。
[2]Boycott
假设攻击者不喜欢某个账户A,不允许和A有关的所有交易上链。这时如果有人发布了含有和A有关的交易的区块,它可以很快发布一个不包含这些交易的区块,然后不必等候6个确认区块,立即发布到比特币网络上竞争最长合法链。
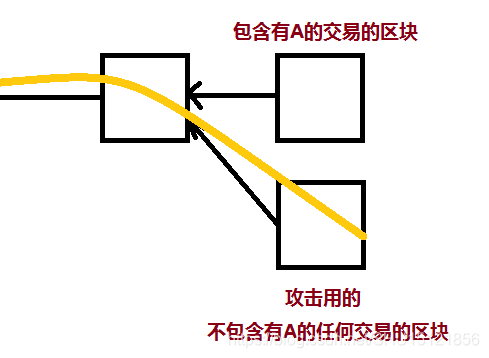
这里不必等候的原因是,之前普通分叉攻击等候几个确认区块只是为了让收款人认为已经没问题了,已经成功收款了,这里没有这种顾虑。
在之前学习共识协议时学过,大部分节点是诚实节点时,记账权也可能落在有恶意的节点手里,它完全可以不发布某些交易,但在那种情形下总有诚实的节点愿意发布这些交易,所以是没关系的。
但当在这种情况下,即有恶意的节点算力很大时,却可以始终让某些交易不上链。即完全可以公开抵制某些交易,这样一来别的矿工也不敢随便打包这些交易了,因为很可能自己辛苦挖的矿最后沦为丢弃的区块。
[3]无法进行盗币
不论算力再强,因为没法伪造别人账户的签名(除非获得其私钥),所以没法伪造交易将别人账户上的BTC转走。即便是仗着自己算力强,强行将不合法的区块发布到区块链上并沿着这条链继续延伸,诚实的节点依然不会沿着这条不合法的长链延伸,所以还是没用的。
8. 比特币脚本
比特币系统中使用的脚本语言很简单,唯一能访问的内存空间就是一个栈,这点和通用脚本语言的区别很大。
在blockchain.info上观察一个交易
以下面这个交易为例:
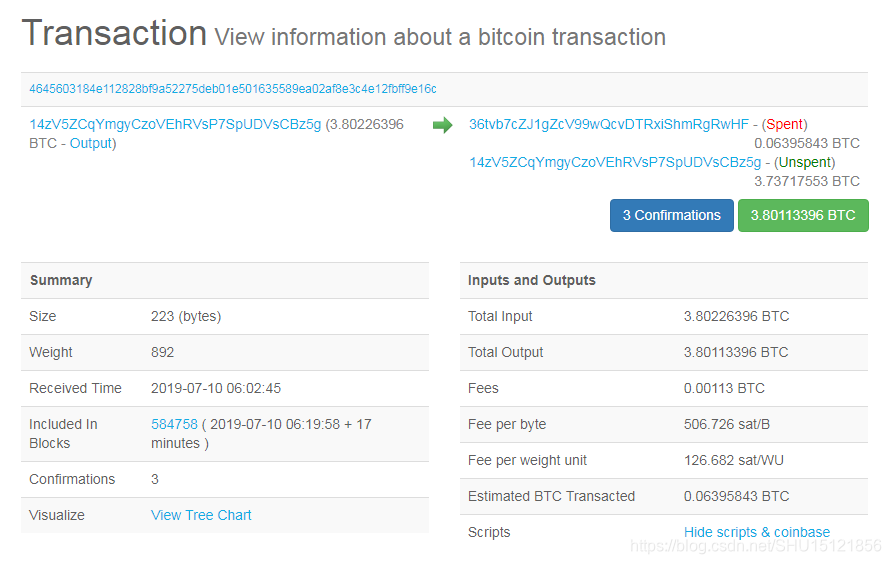
这个交易有一个输入和两个输出,其中一个输出已经被花出去了,另一个没有被花出去。
输入脚本
输入脚本包含两个操作,分别将两个很长的数压入栈中。

输出脚本
输出脚本有两行,分别对应上面的两个输出,即每个输出有自己单独的一段脚本。

交易的结构
这些部分直接截图肖老师的PPT,在PPT上记一下笔记,在blockchain.info上不太好找那个交易的这些详细信息。
交易的整体结构
这里可以看到很多meta data。

交易的输入
交易的输入是一个列表,这个例子中输入只有一个,所以这个列表也就只有一个列表项。

如果一个交易有多个输入,那么每个输入都要指明来源,并给出签名。
交易的输出

交易的输出也可以有多个,形成列表。
一个直观的例子
下图中两个交易分属两个区块,中间隔了两个区块,B转给C的这个交易的BTC的来源是前面A转给B的这个交易。所以右边这个交易中的相应输入的txid是左边这个交易的id,右边这个交易中的vout指向的是左边这个交易的对应输出。
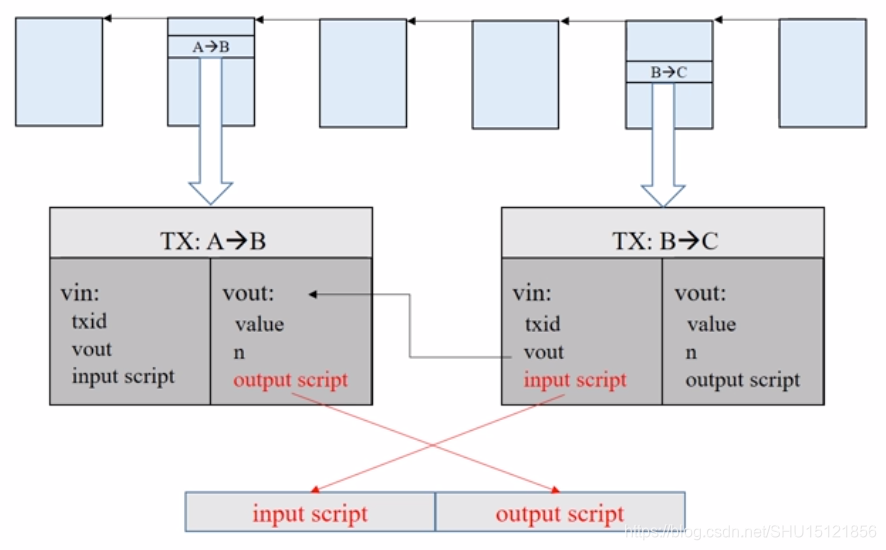
在早期的比特币系统中,要验证这个交易的合法性,就要把B->C这个交易的输入脚本,和A->B这个交易的输出脚本拼在一起执行,看看能不能执行通过。
后来,出于安全因素的考虑,这两个脚本改为分别执行,首先执行输入脚本,如果没有出错,那么再执行输出脚本,如果能顺利执行,并且最后得到非零值(true),那么这个交易就是合法的。
如果一个交易有多个输入,每个输入脚本都要去找到前面特定区块中所对应的输出脚本,匹配之后来进行验证。全部验证通过后,这个交易才是合法的。
输入/输出脚本的几种形式
[1]P2PK(Pay to Public Key)
简述
输入脚本中直接给出付款人的签名(付款人用自己的私钥对输入脚本所在的整个交易的签名),输出脚本中直接给出收款人(注意在这里肯定要是同一个人)的公钥,最后的CHECKSIG是检查签名时用的指令。

这种形式的脚本是最简单的,因为Public Key是直接在输出脚本中给出的。
执行情况
一共三条语句,从上往下执行。
第一条语句,将输入脚本中的签名压入栈:

第二条语句,将输出脚本中的公钥压入栈:

第三条语句,弹出栈顶的两个元素,用公钥PubKey检查一下签名Sig是否正确。如果正确,返回True,说明验证通过:

[2]P2PKH(Pay to Public Key Hash)
简述
P2PKH的输出脚本中没有给出收款人的公钥,给出的是公钥的哈希值。在输入脚本中给出了这个人的公钥(也就是既要给出公钥又要给出签名)。其它的都是一些操作指令,后面详细学习它们是怎么运行的。P2PKH是最常用的一种形式。

执行情况
一共七条语句,从上往下执行。
第一条语句,将输入脚本中的签名压入栈:

第二条语句,将输入脚本中的公钥压入栈:

第三条语句,将栈顶元素复制一遍(所以又压入了一次公钥):

第四条语句,将栈顶元素取出来取哈希,再将得到的哈希值压入栈(也就是将栈顶的公钥变成了其哈希值):

第五条语句,将输出脚本中提供的公钥的哈希值压入栈:

第六条语句,弹出栈顶的两个元素,比较它们是否相等(防止有人用自己的公钥冒充币的来源的交易的收款人的公钥):

第七条语句,弹出栈顶的两个元素,用公钥PubKey检查一下签名Sig是否正确。如果正确,返回True,说明验证通过:

[3]P2SH(Pay to Script Hash)
简述
这是最复杂的一种形式,这种形式下输出脚本给出的不是收款人的公钥的哈希,而是收款人提供的赎回脚本(Redeem Script)的哈希。将来要花这个输出脚本的BTC的时候,相应交易的输入脚本要给出赎回脚本的具体内容,同时还要给出让赎回脚本能正确运行所需要的签名。

两步验证
在验证时,一方面,验证输入脚本给出的赎回脚本内容,是否和对应输出脚本给出的赎回脚本哈希值相匹配;另一方面,反序列化并执行赎回脚本,以验证输入脚本给出的签名是否正确。
赎回脚本的形式
P2PK形式
P2PKH形式
多重签名形式
用P2SH实现P2PK的功能
赎回脚本中给出公钥,输入脚本中给出交易签名和赎回脚本具体内容,输出脚本中给出了赎回脚本的哈希值。

第一阶段的验证,先验证输入脚本和输出脚本在一起执行的结果。
第一步,将输入脚本中的交易签名压入栈:

第二步,将输入脚本中给出的赎回脚本压入栈:

第三步,弹出栈顶元素取哈希再压栈,也就得到了赎回脚本的哈希(Redeem Script Hash):

第四步,将输出脚本中给出的赎回脚本的哈希值压入栈:

第五步,比较栈顶两个元素是否相等,相当于用之前的输出脚本给出的赎回脚本哈希,验证了输入脚本提供的赎回脚本是否是正确的:

第二阶段的验证,是对输入脚本提供的赎回脚本的验证,首先要将其反序列化,得到可以执行的赎回脚本。然后执行这个赎回脚本。
第一步,将脚本中写死的公钥压入栈:

第二步,验证输入脚本中给出的交易签名的正确性。验证通过就会返回True:

P2SH在最初版本的比特币系统中是没有的,后来通过软分叉的形式加进去了,它常用的一个场景就是多重签名。
9.比特币分叉
分叉是指区块链从一条链变成两条或者多条链。
分叉分为:状态分叉和协议分叉。
状态分叉:由于对比特币当前的状态产生分歧而导致的分叉
协议分叉:由于对比特币协议产生分歧而导致的分叉
根据对协议修改的内容不同,协议可以分为硬分叉和软分叉
2、硬分叉
如果区块链软件的共识规则被改变,并且这种规则改变无法向前兼容,旧节点无法认可新节点产生的区块,区块链发生永久性分歧,即为硬分叉
如区块大小的改变。假设新规则从1M变成4M,新规则下的节点都会认可大节点和小节点,会接着大节点来进行扩展,但是旧规则下的节点只会接受小节点,所以只会接着小节点来扩展,这样就会形成两条链。并且区块奖励是否有效也会进行分叉,比如下面这条链中的区块奖励在下面这条链上是被认可的。
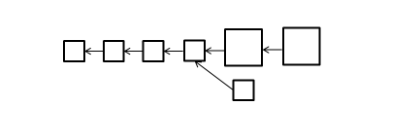
必须要系统中所有节点都更新软件系统才不会出现永久性的分叉
(一般是放宽限制)
如:比特币现金、比特币黄金、比特币钻石、以太坊经典
比特币的分叉币是从比特币区块链上分叉出来的新加密货币,旨在改进或扩展比特币的功能。以下是几种主要的比特币分叉币及其特点:
1. 比特币现金(Bitcoin Cash, BCH)
-
分叉时间:2017年8月1日
-
主要改进:将区块大小从1MB增加到8MB(后升级至32MB),以提高交易速度和降低手续费。每个比特币投资者的账户上将出现与比特币数量等量的比特币现金
-
目标:成为更适合日常支付的数字货币。
2. 比特币黄金(Bitcoin Gold, BTG)
-
分叉时间:2017年10月24日
-
主要改进:采用Equihash算法,使普通用户可用GPU挖矿,减少ASIC矿机的垄断。
-
目标:实现更去中心化的挖矿机制。
3. 比特币SV(Bitcoin SV, BSV)
-
分叉时间:2018年(从BCH分叉)
-
主要改进:将区块大小增至128MB,强调回归中本聪的原始设计。
-
目标:支持大规模商业应用。
4. 比特币钻石(Bitcoin Diamond, BCD)
-
分叉时间:2017年11月24日
-
主要改进:增强隐私保护功能,并提高交易速度。
-
目标:提供更安全的匿名交易。
5. 比特币私人(Bitcoin Private, BTCP)
-
分叉时间:2018年2月28日
-
主要改进:结合比特币和ZClassic的隐私技术(zk-SNARKs),提供匿名交易。
-
目标:增强交易隐私性。
6. 闪电比特币(Lightning Bitcoin, LBTC)
-
分叉时间:2017年12月
-
主要改进:采用DPoS共识机制(类似EOS),提高交易速度。
-
目标:解决比特币的可扩展性问题。
7. 超级比特币(Super Bitcoin, SBTC)
-
分叉时间:2017年12月12日
-
主要改进:计划引入智能合约、闪电网络和零知识证明。
-
争议:预挖21万枚SBTC,引发社区质疑。
其他分叉币
-
比特币黎明(Bitcoin Dawn)
-
比特币星云(Bitcoin Nebula)
-
比特币风暴(Bitcoin Storm)
(部分分叉币已逐渐淡出市场)。
总结
比特币的分叉币主要在扩容、隐私、挖矿去中心化等方面进行改进,其中BCH、BSV、BTG等仍有一定市场影响力,而许多其他分叉币已逐渐消失79。投资者需谨慎评估其技术和社区支持情况。
如需更详细的分叉币列表,可参考相关区块链数据平台或交易所信息。
3、软分叉
如果区块链的共识规则被改变后,这种改变是向前兼容的,旧节点可以兼容新节点产生的区块,就会产生临时性区块,即为软分叉。
通过软件更新增加一些限制,使得原来合法的区块在新协议中不合法。
例如区块大小从1M到0.5M。
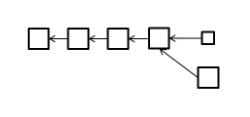
此时,新旧节点都会认可上面那条链,但是只有旧节点会认可下面这一条。所以新节点只会沿着上面的链扩展,旧节点不一定,但是新节点拥有大部分的算力,所以随着上面那条链的长度增加,下面的链就会作废,最终大家都会认可上面那条链。
只要系统中拥有半数算力以上的节点更新了软件,系统就不会出现永久性的分叉,肯能会有临时性的分叉
(一般是增加限制)
4、比特币系统
4.1比特币网络
运行过程:

隐私交易与交易者的连接,类似股票交易
10.比特币匿名性
比特币中的匿名:
用户可以使用公钥产生任意多地址,然后使用不同的地址进行交易。
什么情况可能破坏匿名性:
- 不同地址被关联在一起 网上购物:Input中的addr1、addr2....以及可能存在output中的找零地址(找零的钱肯定是比input中最小的UTXO更小)会被推断为一个人(因为同时拥有这些地址的私钥)
- 和现实产生联系时,存在资金泄露问题: 用来支付的时候 账户就会和实现身份建立联系。如果在交易过程中周围人记住这笔交易,在链上查询,就能通过这个交易查询关联到账户
如何提高匿名性?
网络层匿名性:洋葱路由TOR(只知道上一个节点是谁,而不知道最早发出的节点是谁)
应用层匿名性:Coin mixing 把币混在一起,让人分不出来(把币发给提供Coin mixing服务的网站,再取回来随机抽取的币)
零知识证明:
证明者向验证者证明一个陈述是正确的,但不需要透露除了这个陈述是正确的之外的信息。
例1:证明某个比特币账户的所有权(证明者知道账户私钥) 解决方法:数字签名
同态隐藏:
1. 如果x,y不同,那么它们的加密函数值E(x)和E(y)也不相同。(不同于hash可能会存在碰撞,同时如果E(x)=E(y),说明x=y)
2. 给定E(x)的值,很难反推出x的值。
3. 给定E(x)和E(y)的值,可以很容易地计算出某些关于x,y的加密函数值。
-同态加法:通过E(x)和E(y)计算出E(x+y)的值-同态乘法:通过E(x)和E(y)计算出E(xy)的值
-扩展到多项式
例:证明x+y7,但是不透露x、y的具体值
公开E(x)、E(y),通过同态隐藏的性质3算出E(x+y)的值,再对比E(7)的值,如果相同则验证通过,否则验证失败。
盲签方法:
- 用户A提供SerialNum,银行在不知道SerialNum的情况下返回签名Token,减少A的存款
- 用户A把SerialNum和Token交给B完成交易用户
- B拿SerialNum和Token给银行验证,银行验证通过,增加B的存款
- 银行无法把A和B联系起来。
- 中心化
零币和零钞
零币和零钞在协议层就融合了匿名化处理,其匿名属性来自密码学保证。
零币(zerocoin)系统中存在基础币和零币,通过基础币和零币的来回转换,消除旧地址和新地址的关联性,其原理类似于混币服务。
零钞(zerocash)系统使用zk-SNARKs协议,不依赖一种基础币,区块链中只记录交易的存在性和矿工用来验证系统正常运行所需要关键属性的证明。区块链上既不显示交易地址也不显示交易金额,所有交易通过零知识验证的方式进行。